

目的:针对银行客户行为和统计数据实现客户流失预测任务。
一. 数据准备
1. 数据集:
“select-data.csv”作为训练样本,数据预处理方式:归一化、数值化。
CreditScore:信用分数
EB:存贷款情况
EstimatedSalary:估计收入
Gender:性别(0,1)
Geography:用户所在国家/地区
HasCrCard:是否具有本行信用卡
IsActiveMember:是否活跃用户
NumOfProducts:使用产品数量
Tenure:当了本银行多少年用户
Exited:是否已流失,这将作为我们的标签数据
2. 导入库
- XGBoost有一个很有用的函数”cv”,这个函数可以在每一次迭代中使用交叉验证,并返回理想的决策树数量。
- xgboost的正则化参数的调优。(lambda, alpha)。这些参数可以降低模型的复杂度,从而提高模型的表现。
- 使用方法其中一个是:estimator = xgb.XGBClassifier()/xgb.XGBRegressor()
- from sklearn.metrics import 评价指标函数名称
- _from sklearn.preprocessing import StandardScaler数据标准化,_常用的标准化方式是,减去平均值,然后通过标准差映射到均至为0的空间内。系统会记录每个输入参数的平均数和标准差,以便数据可以还原。很多ML的算法要求训练的输入参数的平均值是0并且有相同阶数的方差例如:RBF核的SVM,L1和L2正则的线性回归。
- from sklearn.externals import joblib Joblib是一组在Python中提供轻量级管道的工具。特别是:函数的透明磁盘缓存和延迟重新计算(记忆模式),简单并行计算。Joblib经过了优化,特别是在处理大型数据时速度更快、更健壮,并且对numpy数组进行了特定的优化。保存或加载模型时用得到。
分类指标
(1)accuracy_score(y_true,y_pre) : 精度
(2)auc(x, y, reorder=False) : ROC曲线下的面积;较大的AUC代表了较好的performance。
(3)average_precision_score(y_true, y_score, average=’macro’, sample_weight=None):根据预测得分计算平均精度(AP)
(4)brier_score_loss(y_true, y_prob, sample_weight=None, pos_label=None):The smaller the Brier score, the better.
(5)confusion_matrix(y_true, y_pred, labels=None, sample_weight=None):通过计算混淆矩阵来评估分类的准确性 返回混淆矩阵
(6)f1_score(y_true, y_pred, labels=None, pos_label=1, average=’binary’, sample_weight=None): F1值 F1 = 2 * (precision * recall) / (precision + recall) precision(查准率)=TP/(TP+FP) recall(查全率)=TP/(TP+FN)
(7)log_loss(y_true, y_pred, eps=1e-15, normalize=True, sample_weight=None, labels=None):对数损耗,又称逻辑损耗或交叉熵损耗
(8)precision_score(y_true, y_pred, labels=None, pos_label=1, average=’binary’,) :查准率或者精度; precision(查准率)=TP/(TP+FP)
(9)recall_score(y_true, y_pred, labels=None, pos_label=1, average=’binary’, sample_weight=None):查全率 ;recall(查全率)=TP/(TP+FN)
(10)roc_auc_score(y_true, y_score, average=’macro’, sample_weight=None):计算ROC曲线下的面积就是AUC的值,the larger the better
(11)roc_curve(y_true, y_score, pos_label=None, sample_weight=None, drop_intermediate=True);计算ROC曲线的横纵坐标值,TPR,FPR
TPR = TP/(TP+FN) = recall(真正例率,敏感度) FPR = FP/(FP+TN)(假正例率,1-特异性)
import pandas as pd
import xgboost as xgb
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix
from sklearn.externals import joblib
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_curve, precision_recall_curve, auc, make_scorer, recall_score, accuracy_score, precision_score, confusion_matrix
import matplotlib.pyplot as plt
3.加载数据
- delimiter定界符
- Python 使用特定符号或符号组合作为表达式、列表、字典、各种语句的字符串中的定界符,以及其他用途。
(1)Python 定界符的作用就是按照原样,包括换行格式什么的,输出在其内部的东西;
(2)在 Python 定界符中的任何特殊字符都不需要转义;
(3)Python 定界符中的 Python 变量会被正常的用其值来替换。
load data
dataset = pd.read_csv('select-data.csv', delimiter=",")
- 简单地查看数据——dataset.head( )
- 审查数据的维度——dataset.shape
- 审查数据的类型和属性——dataset.dtypes
- 总结查看数据分类的分布情况——dataset.groupby(‘Target’).size()
- 通过描述性统计分析数据——dataset.describe()
- 理解数据属性的相关性——dataset.corr(method=’pearson’)
- 审查数据的分布状况——dataset.skew()
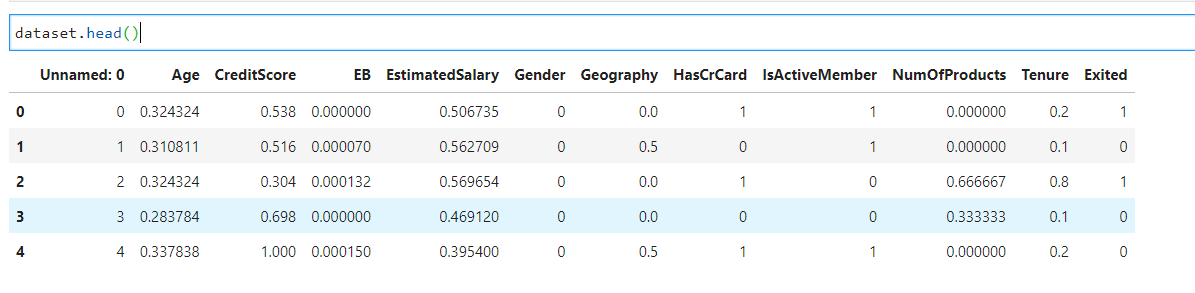
dataset.head()

4.查看数据情况
#查看数据情况
dataset.info()
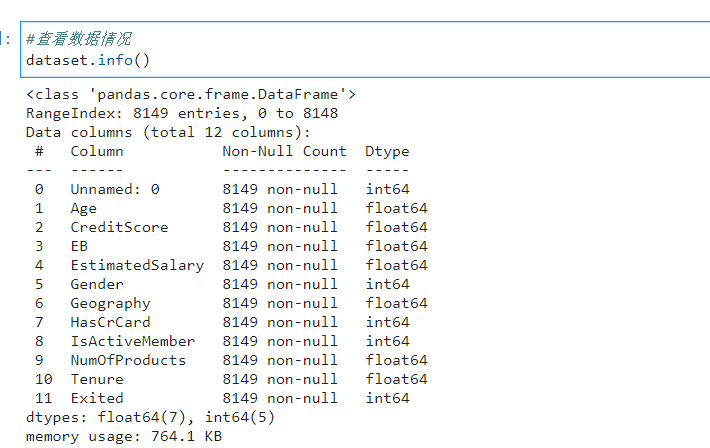
一共8149行,12列。
5.数据可视化
用 matplotlib能够完成一些基本的图表操作,而 Seaborn 库可以让这些图的表现更加丰富。
通过观察数据,我们对’age’进行直方图展示。但在绘图之前,我们观测到’age’字段中存在缺失值,需要先用 dropna() 方法删掉存在缺失值的数据,否则无法绘制出图形。
‘kde’ 是控制密度估计曲线的参数,默认为 True,不设置会默认显示,如果我们将其设为 False,则不显示密度曲线。
‘bins’是控制分布矩形数量的参数,通常我们可以增加其数量,来看到更为丰富的信息。
import seaborn as sns
with sns.plotting_context("notebook",font_scale=1.5):
sns.set_style("whitegrid")
sns.distplot(dataset["Age"].dropna(),
bins=20,
kde=False,
color="green")
plt.ylabel("Count")
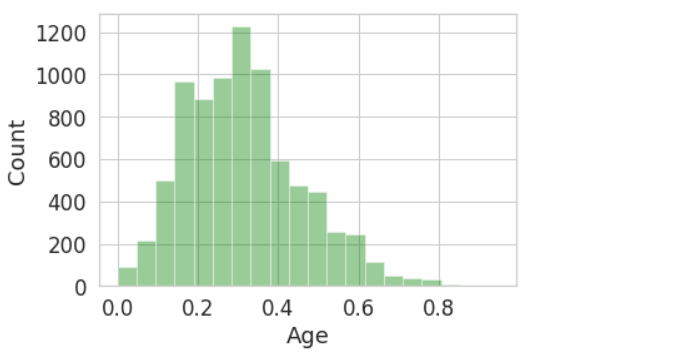
通过直方图可以看到,年龄在30岁左右的人居多。
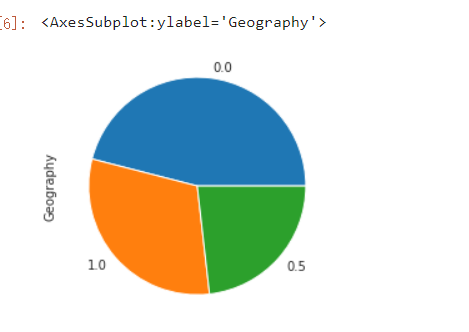
6.饼图
如果数据包含任何NaN,则它们将自动填充为0。 如果数据中有任何负数,则会引发ValueError。饼图:数值必须为正值,需指定Y轴或者subplots=True。
饼图其他参数设置可以参考这篇博客,链接:https://blog.csdn.net/weixin_48615832/article/details/107883609
dataset["Geography"].value_counts().plot(x=None, y=None, kind='pie')
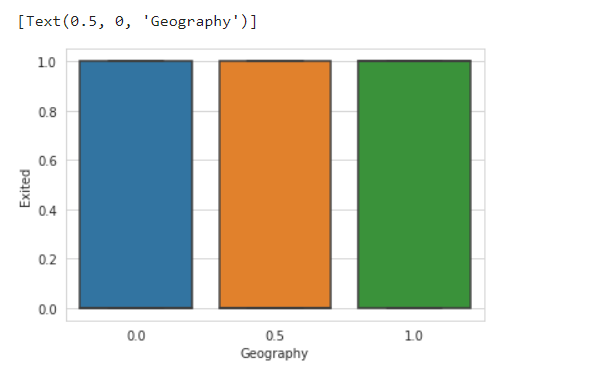
7.箱线图(地区,流失)
箱线图,是一种用作显示一组数据分散情况资料的统计图。它能显示出一组数据的最大值、最小值、中位数及上下四分位数。
具体设置参考博客sns.boxplot()简单用法_DDxuexi的博客-CSDN博客_sns.boxplot
boxplot1=sns.boxplot(x='Geography', y='Exited', data=dataset)
boxplot1.set(xlabel='Geography')
8.箱线图(性别,估计收入)
一个boxplot主要包含六个数据节点,将一组数据从大到小排列,分别计算出他的 上边缘(上限), 上四分位数Q3, 中位数, 下四分位数Q1, 下边缘(下限),还有一个 异常值。
boxplot1=sns.boxplot(x='Gender', y='EstimatedSalary', data=dataset)
boxplot1.set(xlabel='Gender')
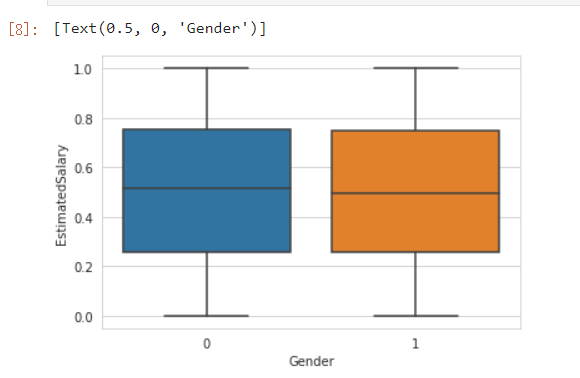
上限1.0,下限0.0,中位数:0.5,上四分位数 Q3:0.75,下四分位数 Q1:0.25。
9.数据集
DataFrame的describe()方法来查看描述性统计的内容。这个方法给我们展示了八方面的信息: 数据记录数、平均值、标准方差、最小值、下四分位数、中位数、上四分位数、最大值。这些信息主要用来描述数据的分布情况。
数据集数值分析
dataset.describe()
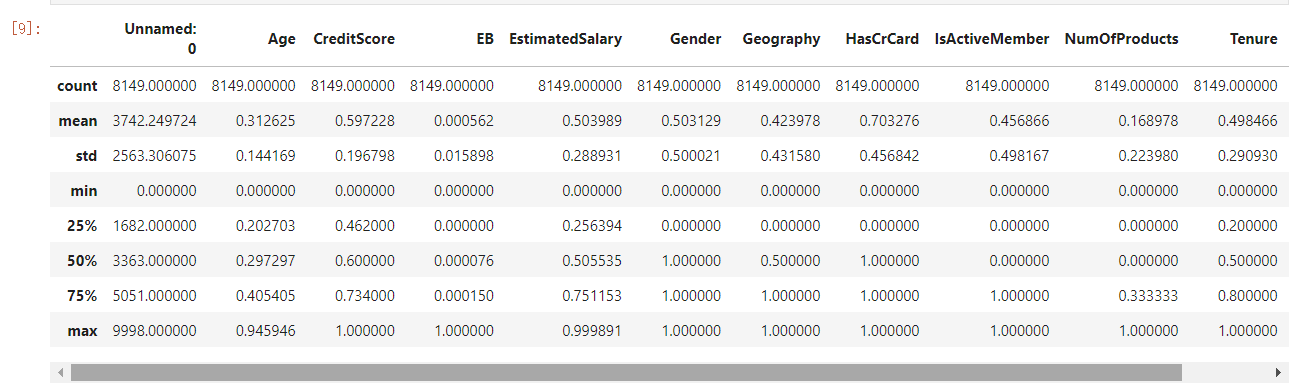
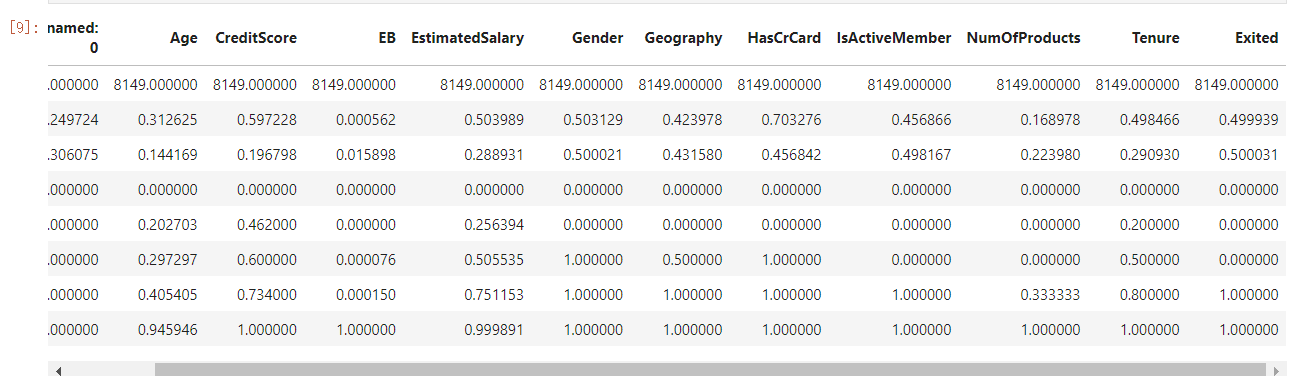
10.行列
一共8149行
审查数据的维度——dataset.shape
#total rows count
print("total rows:",dataset.shape[0])
#Detect null values
null_columns=dataset.columns[dataset.isnull().any()]
print(dataset[dataset.isnull().any(axis=1)][null_columns].count())

11.去掉无用
drop([]),默认情况下删除某一行;如果要删除某列,需要axis=1;参数inplace 默认情况下为False,表示保持原来的数据不变,True 则表示在原来的数据上改变。
#去掉无用字段
dataset.drop(dataset.columns[0], inplace=True, axis=1)
dataset.head()

12.查看
.value_counts()的其他用法可以参考博客python:pandas数值统计,.value_counts()的用法,全DataFrame数据计数__养乐多_的博客-CSDN博客_dataframe计数
查看是否已流失两类标签的数量,没流失0有4075人,流失1有4074人。
#查看两类标签的分类数量
dataset.Exited.value_counts()

13.训练集
iloc[ : , : ] 行列切片以”,”隔开,前面的冒号就是取行数,后面的冒号是取列数,索引为左闭右开。
#构建训练集
X = dataset.iloc[:,0:len(dataset.columns.tolist())-1].values
y = dataset.iloc[:,len(dataset.columns.tolist())-1].values
split data into train and test sets
seed = 7
test_size = 0.20
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=seed)
随机划分训练集:测试集=8:2
#标准化数据(可选)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
二. XGBOOST模型训练
Xgboost是Boosting算法的其中一种,Boosting算法的思想是将许多弱分类器集成在一起,形成一个强分类器。因为Xgboost是一种提升树模型,所以它是将许多树模型集成在一起,形成一个很强的分类器。
Xgboost一般和sklearn一起使用,但是由于sklearn中没有集成Xgboost,所以才需要单独下载安装。优点:正则化、并行处理、灵活性、缺失值处理、剪枝、内置交叉验证。
具体可参考博客Python机器学习笔记:XgBoost算法 – 战争热诚 – 博客园
1.训练
base_score [ default=0.5 ]:所有实例的初始预测分数,全局偏差。
booster [default=gbtree] :有两种模型可以选择gbtree和gblinear。gbtree使用基于树的模型进行提升计算,gblinear使用线性模型进行提升计算。
gamma [default=0]:模型在默认情况下,对于一个节点的划分只有在其loss function 得到结果大于0的情况下才进行,而gamma 给定了所需的最低loss function的值
max_depth [default=6]:树的最大深度,树的深度越大,则对数据的拟合程度越高(过拟合程度也越高)。即该参数也是控制过拟合。
min_child_weight [default=1]:孩子节点中最小的样本权重和。如果一个叶子节点的样本权重和小于min_child_weight则拆分过程结束。
subsample [default=1]:用于训练模型的子样本占整个样本集合的比例。如果设置为0.5则意味着XGBoost将随机的从整个样本集合中抽取出50%的子样本建立树模型,这能够防止过拟合。
colsample_bytree [default=1] :在建立树时对特征随机采样的比例。
objective=’binary:logistic’:输出逻辑回归的概率值。
‘lambda’:控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
‘silent’:0 ,设置成1则没有运行信息输出,最好是设置为0
‘nthread’: cpu 线程数
fit model no training data
#训练
model = XGBClassifier()
model.fit(X_train, y_train)
2.模型测试
分类准确率为77.91%。
模型测试
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))

3.模型可视化
model.predict_proba:此函数得到的结果是一个多维数组,如果是二分类,则是二维数组,第一列为样本预测为0的概率,第二列为样本预测为1的概率。
dtest_predprob = model.predict_proba(X_test)[:,1]
#XGBOOST模型可视化
from xgboost import plot_tree
fig, ax = plt.subplots(figsize=(20, 16))
plot_tree(model, num_trees=0, rankdir='LR',ax=ax)
plt.show()
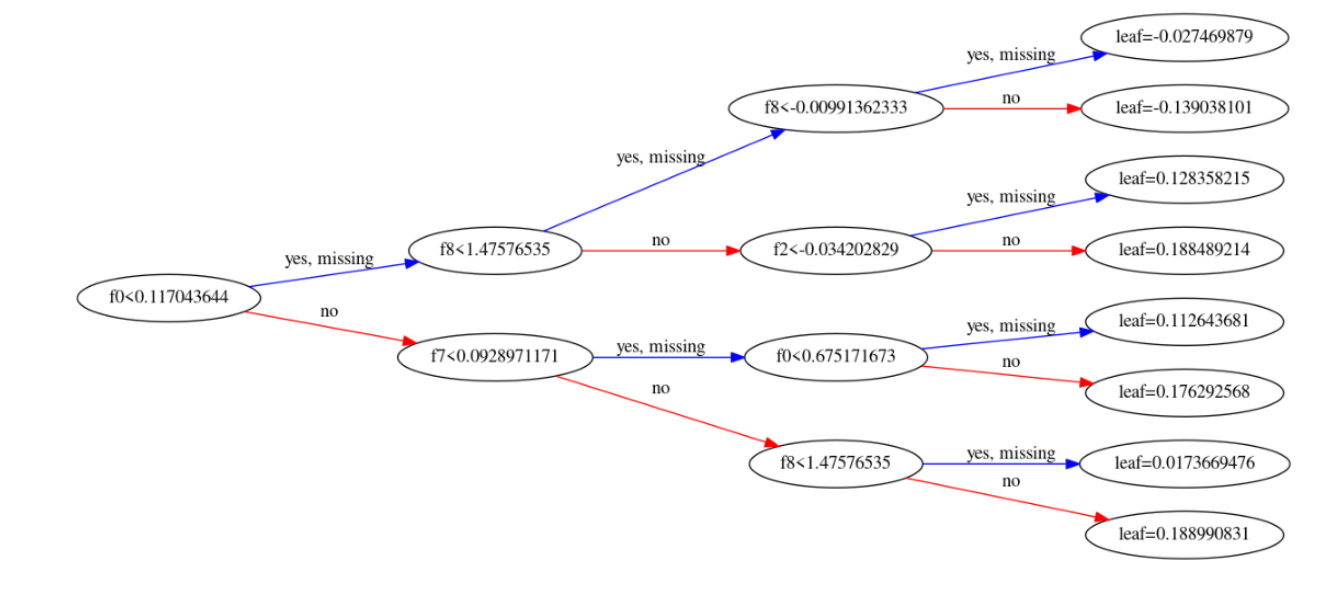
4.模型分析
只有当树模型作为基学习器时Feature importance才被定义(booster=gbtree)。如果想要知道哪些变量比较重要的话。可以通过模型的feature_importances_方法来获取特征重要性。xgboost的feature_importances_可以通过特征的分裂次数或利用该特征分裂后的增益来衡量。
模型重要特征分析
from matplotlib import pyplot
plot
pyplot.bar(range(len(model.feature_importances_)), model.feature_importances_)
pyplot.show()
三.逻辑回归算法
1.对比
逻辑回归虽然名字有回归,但是实际上是分类模型,常用于二分类。在二维空间中找到一条最佳拟合直线去拟合数据点;在多维空间中找到最佳拟合超平面去拟合数据点,这个寻找拟合的过程就叫做回归。逻辑回归假设数据服从伯努利分布,通过极大似然函数的方法,运用梯度下降来求解参数,最终达到数据二分类的目的。
逻辑回归原理:y = w_1x_1 + w_2x_2 + … + w_n*x_n +bias —(1)
bias为偏置,可以理解为一元函数的y=ax+b中的b。
#对比逻辑回归算法
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
model_lg = LogisticRegression()
model_lg.fit(X_train, y_train)

2.测试
模型测试
y_pred = model_lg.predict(X_test)
print(accuracy_score(y_test, y_pred))

分类准确率为69.09%。
四. SVM算法
1.对比
支撑向量机SVM是一种非常重要和广泛的机器学习算法,它的算法出发点是尽可能找到最优的决策边界,使得模型的泛化能力尽可能地好,因此SVM对未来数据的预测也是更加准确的。
SVM既可以解决分类问题,又可以解决回归问题。SVM算法具体介绍与其他应用可以参考博客https://www.csdn.net/tags/Ntzacg5sNjg4NTctYmxvZwO0O0OO0O0O.html
#对比SVM算法
import sklearn.svm
import sklearn.metrics
from matplotlib import pyplot as plt
clf_svm = sklearn.svm.LinearSVC().fit(X_train, y_train)
decision_values = clf_svm.decision_function(X_train)
precision, recall, thresholds = sklearn.metrics.precision_recall_curve(y_train, decision_values)
plt.plot(precision,recall)
plt.legend(loc="lower right")
plt.show()
2.测试
模型测试
y_pred_svm = clf_svm.predict(X_test)
print(pd.crosstab(y_test, y_pred_svm, rownames=['Actual'], colnames=['Predicted']))
print(accuracy_score(y_test, y_pred_svm))
print(recall_score(y_test, y_pred_svm))
print(sklearn.metrics.roc_auc_score(y_test, y_pred_svm))
print(sklearn.metrics.f1_score(y_test, y_pred_svm))

分类准确率为68.327%
五. AdaBoost算法
1.对比
Adaboost算法是一种提升方法,将多个弱分类器,组合成强分类器。用于二分类或多分类,特征选择,分类人物的baseline。精度很高的分类器,提供的是框架,可以使用各种方法构建弱分类器,简单,不需要做特征筛选,不用担心过度拟合。算法原理可以看数据挖掘领域十大经典算法之—AdaBoost算法(超详细附代码)_fuqiuai的博客-CSDN博客_adaboost算法
#对比adaboost
from sklearn.externals.six.moves import zip
import matplotlib.pyplot as plt
from sklearn.datasets import make_gaussian_quantiles
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
模型定义
bdt_discrete = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=3),
n_estimators=500,
learning_rate=.5,
algorithm="SAMME")
bdt_discrete.fit(X_train, y_train)
discrete_test_errors = []
for discrete_train_predict in bdt_discrete.staged_predict(X_test):
discrete_test_errors.append(1. - recall_score(discrete_train_predict, y_test))
n_trees_discrete = len(bdt_discrete)
Boosting might terminate early, but the following arrays are always
n_estimators long. We crop them to the actual number of trees here:
discrete_estimator_errors = bdt_discrete.estimator_errors_[:n_trees_discrete]
discrete_estimator_weights = bdt_discrete.estimator_weights_[:n_trees_discrete]
plt.figure(figsize=(15, 5))
plt.subplot(131)
plt.plot(range(1, n_trees_discrete + 1),
discrete_test_errors, c='black', label='SAMME')
plt.legend()
plt.ylim(0.18, 0.62)
plt.ylabel('Test Error')
plt.xlabel('Number of Trees')
plt.subplot(132)
plt.plot(range(1, n_trees_discrete + 1), discrete_estimator_errors,
"b", label='SAMME', alpha=.5)
plt.legend()
plt.ylabel('Error')
plt.xlabel('Number of Trees')
plt.ylim((.2,discrete_estimator_errors.max() * 1.2))
plt.xlim((-20, len(bdt_discrete) + 20))
plt.subplot(133)
plt.plot(range(1, n_trees_discrete + 1), discrete_estimator_weights,
"b", label='SAMME')
plt.legend()
plt.ylabel('Weight')
plt.xlabel('Number of Trees')
plt.ylim((0, discrete_estimator_weights.max() * 1.2))
plt.xlim((-20, n_trees_discrete + 20))
prevent overlapping y-axis labels
plt.subplots_adjust(wspace=0.25)
plt.show()
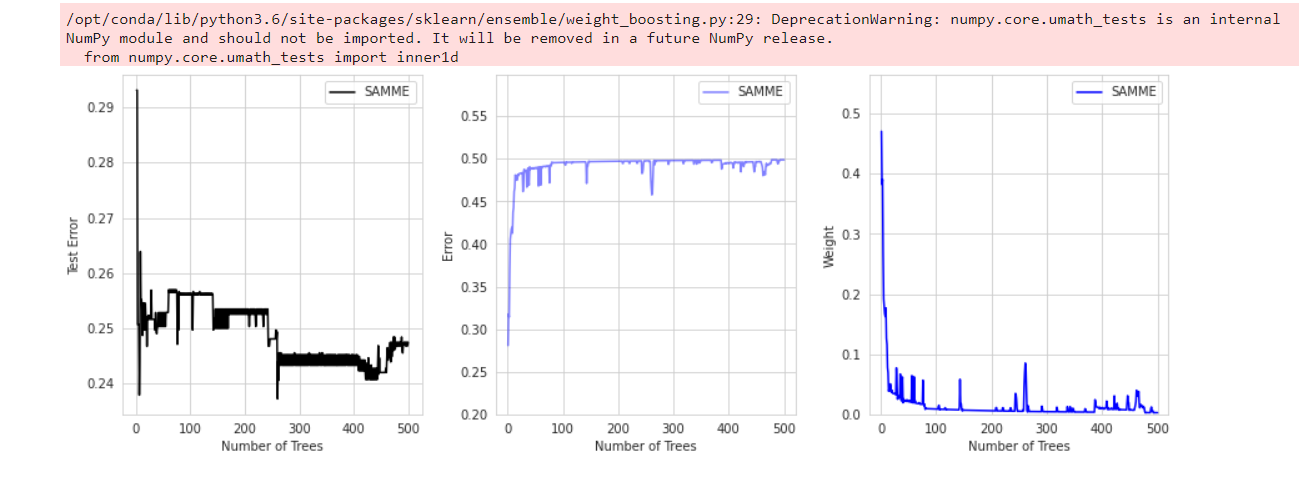
三个图分别是测试的错误率,训练过程中错误率,不同子树的权重值。
2.测试
#模型测试
y_pred_adaboost = bdt_discrete.predict(X_test)
print(accuracy_score(y_test, y_pred_adaboost))
print(recall_score(y_test, y_pred_adaboost))
print(sklearn.metrics.roc_auc_score(y_test, bdt_discrete.predict_proba(X_test)[:,1]))
print(sklearn.metrics.f1_score(y_test, y_pred_adaboost))

分类准确率为76.38%。
六. 随机森林
1.对比
将多个决策树结合在一起,每次数据集是随机有放回的选出,同时随机选出部分特征作为输入,所以该算法被称为随机森林算法。可以看到随机森林算法是以决策树为估计器的Bagging算法。具体原理参考博客机器学习算法系列(十八)-随机森林算法(Random Forest Algorithm)_Saisimonzs的博客-CSDN博客_随机森林算法
遍历随机森林的大小 K 次:
从训练集 T 中有放回抽样的方式,取样N 次形成一个新子训练集 D
随机选择 m 个特征,其中 m < M
使用新的训练集 D 和 m 个特征,学习出一个完整的决策树
得到随机森林
#随机森林
from sklearn.ensemble import RandomForestClassifier
classifier_rf = RandomForestClassifier(n_estimators = 10, max_depth = 8, criterion = 'entropy',random_state = 42)
classifier_rf.fit(X_train, y_train)

2.测试
模型测试
y_pred_rf = classifier_rf.predict(X_test)
print(pd.crosstab(y_test, y_pred_rf, rownames=['Actual Class'], colnames=['Predicted Class']))
print(accuracy_score(y_test, y_pred_rf))
print(recall_score(y_test, y_pred_rf))
print(f1_score(y_test, y_pred_rf))
print(sklearn.metrics.roc_auc_score(y_test, y_pred_rf))

分类准确率为77.73%。
七. 机器学习算法性能对比
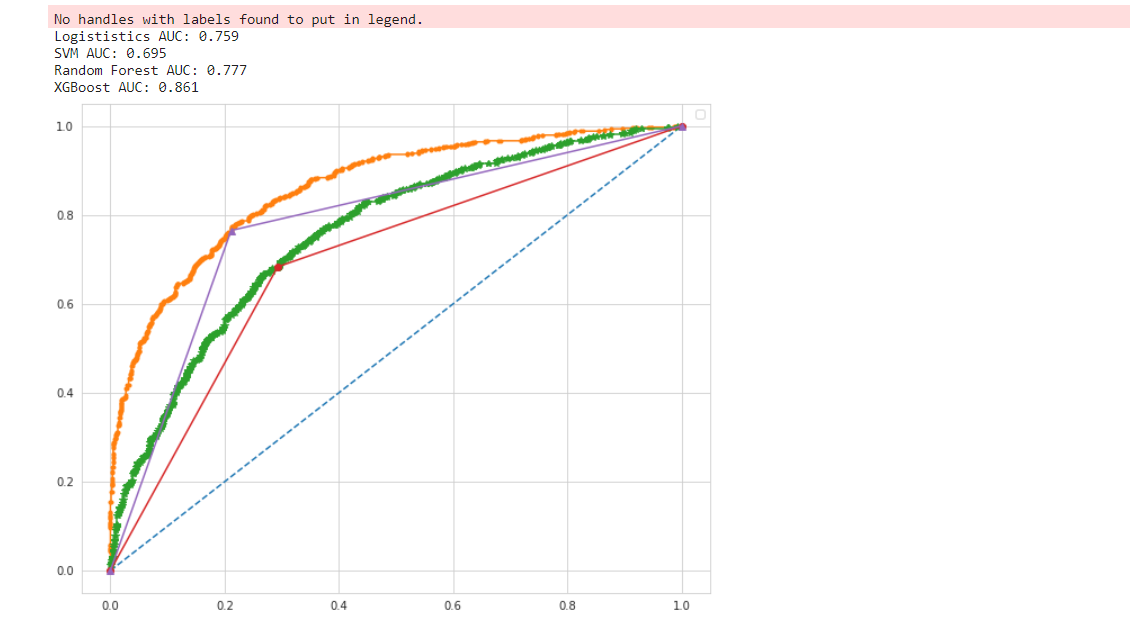
将XGBOOST、逻辑回归、SVM和随机森林进行AUC对比,AUC越大,分类器分类效果越好。
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
from matplotlib import pyplot
fig, ax = plt.subplots(figsize=(10, 8))
probs_lg = model_lg.predict_proba(X_test)[:,1]
auc_lg = roc_auc_score(y_test, probs_lg)
print('Logististics AUC: %.3f' % auc_lg)
fpr_lg, tpr_lg, thresholds_lg = roc_curve(y_test, probs_lg)
probs_svm = y_pred_svm
auc_svm = roc_auc_score(y_test, probs_svm)
print('SVM AUC: %.3f' % auc_svm)
fpr_svm, tpr_svm, thresholds_svm = roc_curve(y_test, probs_svm)
probs_rf = y_pred_rf
auc_rf = roc_auc_score(y_test, probs_rf)
print('Random Forest AUC: %.3f' % auc_rf)
fpr_rf, tpr_rf, thresholds_rf = roc_curve(y_test, probs_rf)
probs_xgb = dtest_predprob
calculate AUC
auc_xgb = roc_auc_score(y_test, probs_xgb)
print('XGBoost AUC: %.3f' % auc_xgb)
calculate roc curve
fpr_xgb, tpr_xgb, thresholds = roc_curve(y_test, probs_xgb)
pyplot.plot([0, 1], [0, 1], linestyle='--')
plot the roc curve for models
pyplot.plot(fpr_xgb, tpr_xgb, marker='.')
pyplot.plot(fpr_lg, tpr_lg, marker='*')
pyplot.plot(fpr_svm, tpr_svm, marker='o')
pyplot.plot(fpr_rf, tpr_rf, marker='^')
pyplot.legend(loc="best")
pyplot.show()
八. 基于神经网络的客户流失分析
1.导入库
os.environ[‘TF_CPP_MIN_LOG_LEVEL’] = ‘2’:设置log输出信息,值为2,说明不显示警告。
tf.disable_v2_behavior():这种方法是将tf v2 版本的功能屏蔽了,使用v1版本的代码,这种操作适合在升级tf的同时,维护以前代码。
shuffle打乱样本的顺序,它只会打乱样本的顺序,每个样本的数据维持不变。
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import pandas as pd
import numpy as np
from sklearn.utils import shuffle
from sklearn.preprocessing import OneHotEncoder
import matplotlib.pyplot as plt

2. 对目标标签编码
one-hot是比较常用的文本特征特征提取的方法。One-Hot 编码,又称一位有效编码。其方法是使用 N 位状态寄存器来对 N 个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中 只有一位有效。具体原理可以看一下这篇博客 独热(One-Hot)编码简述_辰chen的博客-CSDN博客_one-hot 编码
target = y_train.reshape(-1, 1)
test_target = y_test.reshape(-1, 1)
One-Hot编码 输出确定
enc = OneHotEncoder()
enc.fit(test_target)
test_target = enc.transform(test_target).toarray()
enc.fit(target)
target = enc.transform(target).toarray()
3.定义网络结构
tf.placeholder() 就有些像普通函数中的形式参数,在定义函数时的参数只是形式上的参数,目的是通过指代的方式表达清楚运算流程,实际上并没有分配值空间(函数定义时),只有在函数执行时才传入真实值(真正占用内存空间的值)进行运算。有了tf.placeholder(),我们每次可以将 一个minibatch传入到x = tf.placeholder(tf.float32,[None,32])上,下一次传入的x都替换掉上一次传入的x,这样就对于所有传入的minibatch x就只会产生一个op,不会产生其他多余的op,进而减少了graph的开销。
定义输入占位符 通常用来获取模型的输入数据
x = tf.placeholder(tf.float32, shape=(None, 10))
# 二分类问题 [0,1]
y = tf.placeholder(tf.float32, shape=(None, 2))
keep = tf.placeholder(tf.float32)
BP神经网络是传统的神经网络,只有输入层、隐藏层、输出层,其中隐藏层的层数根据需要而定。
- BP神经网络也是前馈神经网络,只是它的参数权重值是由反向传播学习算法进行调整的。
- BP神经网络模型拓扑结构包括输入层、隐层和输出层,利用激活函数来实现从输入到输出的任意非线性映射,从而模拟各层神经元之间的交互
- 激活函数须满足处处可导的条件。例如,Sigmoid函数连续可微,求导合适,单调递增,输出值是0~1之间的连续量,这些特点使其适合作为神经网络的激活函数。

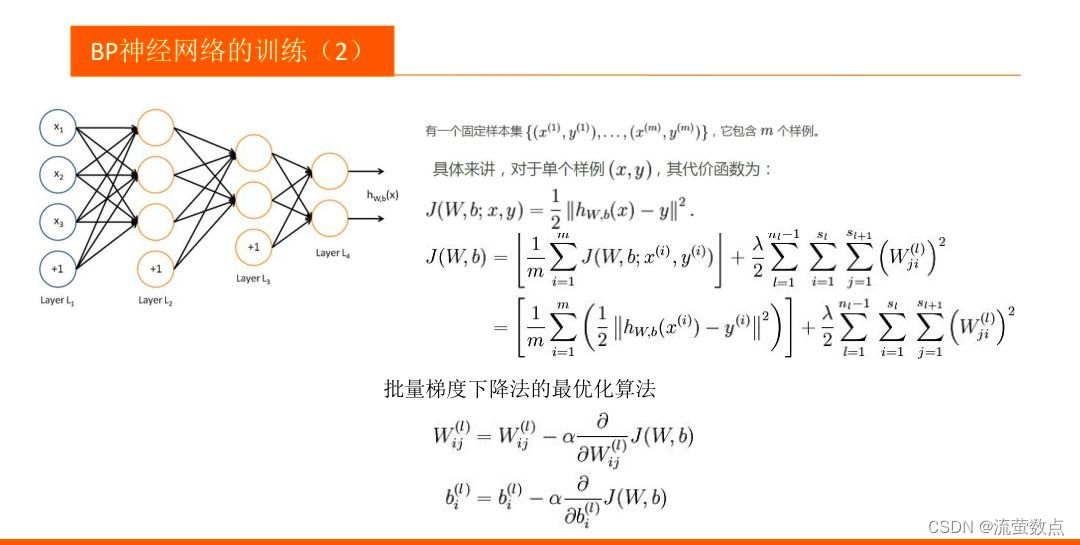




定义网络结构
layer1 隐层
var1 = tf.Variable(tf.truncated_normal([10, 128], stddev=0.1)) #输入的属性是10个,128自己设定的(输入的个数,神经元个数)
bias1 = tf.Variable(tf.zeros([128])) #对128结点的偏置做初始化
hc1 = tf.add(tf.matmul(x, var1), bias1) #全连接网络 x*var1+bias1
h1 = tf.sigmoid(hc1) #定义隐层的输出,使用激活函数sigmoid
h1 = tf.nn.dropout(h1, keep_prob=keep) #为了避免过拟合
layer2 第二个隐层
var2 = tf.Variable(tf.truncated_normal([128, 128], stddev=0.1))
bias2 = tf.Variable(tf.zeros([128]))
hc2 = tf.add(tf.matmul(h1, var2), bias2)
h2 = tf.sigmoid(hc2)
h2 = tf.nn.dropout(h2, keep_prob=keep)
layer3 输出层
var3 = tf.Variable(tf.truncated_normal([128, 2], stddev=0.1)) #预测银行流失只有两种情况
bias3 = tf.Variable(tf.zeros([2]))
hc3 = tf.add(tf.matmul(h2, var3), bias3)
h3 = tf.nn.softmax(hc3) #使每一个输出落在0,1之间,输出加和等于1
定义损失
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=h3, labels=y)) #交叉熵函数
tf.summary.scalar('loss', loss)
定义正确率
ac = tf.cast(tf.equal(tf.argmax(h3, 1), tf.argmax(y, 1)), tf.float32)
acc = tf.reduce_mean(ac) #算出来的和实际的比较
tf.summary.scalar('accuracy', acc)
定义优化器
optimzer = tf.train.AdamOptimizer(1e-3).minimize(loss) #学习率 动态的方法
merge_summary = tf.summary.merge_all()

4.日志
#创建日志和模型存放路径
!mkdir logs model
5.训练
append()函数用于在列表末尾添加新的对象。
训练 梯度下降法
print("正在训练.....")
saver = tf.train.Saver(max_to_keep=1)
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
summary_writer = tf.summary.FileWriter('./logs/', sess.graph)
nepoch=[]
trainacc=[]
testacc=[]
loss1=[]
#训练500次
for i in range(0, 501):
sess.run(optimzer, feed_dict={x: X_train, y: target, keep: 0.6})
train_summary = sess.run(merge_summary, feed_dict={x: X_train, y: target, keep: 1.0})#梯度下降法训练
summary_writer.add_summary(train_summary, i)
if i % 50 == 0:
#每隔50次算一下
accu = sess.run(acc, feed_dict={x: X_train, y: target, keep: 1.0})
accuT = sess.run(acc, feed_dict={x: X_test, y: test_target, keep: 1.0})
losss = sess.run(loss, feed_dict={x: X_train, y: target, keep: 1.0})
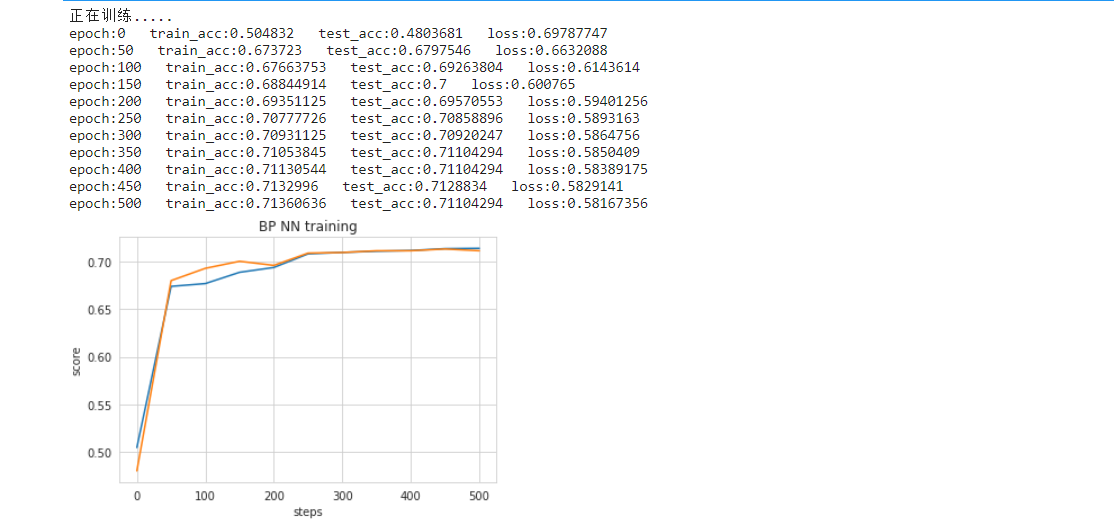
print("epoch:" + str(i) + " train_acc:" + str(accu) + " test_acc:" + str(accuT) + " loss:" + str(
losss))
nepoch.append(i)
trainacc.append(accu)
testacc.append(accuT)
loss1.append(losss)
#训练过程可视化
plt.title("BP NN training")
plt.xlabel('steps')
plt.ylabel('score')
plt.plot(nepoch,trainacc,nepoch,testacc)
plt.show()
#模型保存
saver.save(sess, './model/bank.ckpt', global_step=i)
sess.close()
测试过程待补充。
Original: https://blog.csdn.net/liuyingshudian/article/details/125875010
Author: 流萤数点
Title: 深度学习(1):BP神经网络实现银行客户流失预测
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/697272/
转载文章受原作者版权保护。转载请注明原作者出处!