

1.插补用户用电量数据缺失值。
用户用电量数据呈现一定的周期性关系,missing_data.csv表中存放了用户A、用户B和用户C的用电量数据,其中存在缺失值,需要进行缺失值插补才能进行下一步分析。
(1)读取missing_data.csv表中的数据。
(2)查询缺失值所在位置。
(3)使用SciPy库中interpolate模块中的lagrange对数据进行拉格朗日插值。
(4)查看数据中是否存在缺失值,若不存在则说明插值成功。
源程序
import pandas as pd
import numpy as np
arr=np.array([0,1,2])
missing_data=pd.read_csv('C:/Users/Administrator/Desktop/上机3/missing_data.csv',names=arr)
print('missing_data每个特征缺失的数目为:\n',missing_data.notnull())#查询缺失值所在位置
from scipy.interpolate import lagrange#拉格朗日插值
for i in range(0,3):
la=lagrange(missing_data.loc[:,i].dropna().index,missing_data.loc[:,i].dropna().values)#训练lagrange模型
list_d=list(set(np.arange(0,21)).difference(set(missing_data.loc[:,i].dropna().index)))#记录当前列缺失值所在行
missing_data.loc[list_d,i]=la(list_d)#缺失值带入
print('第%d列缺失值的个数为:%d' %(i,missing_data.loc[:,i].isnull().sum()))
print('missing_data拉格朗日插值后每个特征缺失的数目为:','\n',missing_data.notnull())#查询缺失值所在位置
结果截屏


- 合并线损、用电量趋势与线路告警数据。
线路线损数据、线路用电量趋势下降数据和线路警告数据是识别用户窃漏电与否的3个重要特征,需要对由线路线路编号(ID)和时间(data)两个键值构成的主键进行合并。
(1)读取ele_loss.csv和alarm.csv表。
(2)查看两个表的形状。
(3)以ID和date两个键值作为主键进行内连接。
(4)查看合并后的数据。
源程序
import pandas as pd
ele_loss=pd.read_csv('C:/Users/Administrator/Desktop/上机3/ele_loss.csv',encoding='gbk')
alarm=pd.read_csv('C:/Users/Administrator/Desktop/上机3/alarm.csv',encoding='gbk')
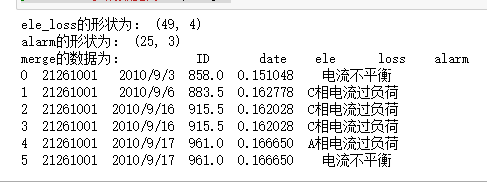
print('ele_loss的形状为:',ele_loss.shape)
print('alarm的形状为:',alarm.shape)
merge=pd.merge(ele_loss,alarm,how='inner',left_on=['ID','date'],right_on=['ID','date'])
print('merge的数据为:',merge)
运行截图
3.对菜品数据去重及异常值处理。
菜品数据存在重复的现象,所以需要对菜品销售数据分别进行记录去重和特征去重,并将异常值进行处理。
(1)读取detail.csv表。
(2)对订单详情表的样本去重与特征去重。
(3)订单详情表异常值检测与处理。
源程序
import pandas as pd
detail=pd.read_csv('C:/Users/Administrator/Desktop/上机3/detail.csv',encoding='gbk')
print('进行去重操作前菜品数据的的形状为:',detail.shape)
#样本去重
detail.drop_duplicates(inplace = True)
#特征去重
def FeatureEquals(df):
dfEquals=pd.DataFrame([],columns=df.columns,index=df.columns)
for i in df.columns:
for j in df.columns:
dfEquals.loc[i,j]=df.loc[:,i].equals(df.loc[:,j])
return dfEquals
detEquals=FeatureEquals(detail)#应用上述函数
lenDet = detEquals.shape[0]
dupCol=[]
for k in range(lenDet):
for l in range(k+1,lenDet):
if detEquals.iloc[k,1] & \
(detEquals.columns[1] not in dupCol):
detail.drop(dupCol,axis=1,inplace=True)
print('进行去重操作后订单详情表的形状为:',detail.shape)
运行截图

4.对菜品数据标准化,对部分数据进行转换。
(1)对订单详情表中的数值型数据做标准差标准化。
(2)对菜品dishes_name特征进行哑变量处理。
(3)对菜品售价使用等频法离散化。
源程序
#自定义标准差标准化函数
def StandardScaler(data):
data=(data-data.mean())/data.std()
return data
#对菜品订单表售价和销售量做标准化
data4=StandardScaler(detail['counts'])
data5=StandardScaler(detail['amounts'])
data6=pd.concat([data4,data5],axis=1)
print('标准差标准化之后销量和销量数据为:','\n',data6.head(10))
#哑变量处理
detail=pd.read_csv('C:/Users/Administrator/Desktop/上机3/detail.csv',encoding='gbk')
data=detail.loc[0:5,'dishes_name']
print('哑变量处理前的数据为:\n',data)
print('哑变量处理后的数据为:\n',pd.get_dummies(data))
#等频法散化
def SaneRateCut(data,k):
w=data.quantile(np.arange(0,1+1.0/k,1.0/k))
data=pd.cut(data,w)
return data
result=SaneRateCut(detail['amounts'],5).value_counts()
print('菜品数据等频法离散化后各个类别数目分布情况为:','\n',result)
运行截图

Original: https://blog.csdn.net/m0_55685573/article/details/122696205
Author: 泠泠七弦上@静听松风寒
Title: pandas数据分析与处理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/697230/
转载文章受原作者版权保护。转载请注明原作者出处!