

文章目录
前言
最近在复盘一些机器学习项目时发现,在一些案例中对于离散特征转码方案的选择存在一些问题。故在此记录一些重要的点,以防止遗忘。对于想要了解详细内容的同学,推荐去看这一篇博客离散数据编码方式总结
一、转码方案的选择
在之前的一些数据分析以及数据挖掘案例中,常将离散特征转码分为0-1编码和哑变量两种,在选择方案时忽略了一些细节。
在这里将离散特征进行转码的方案分为以下两种:
进行数值编码
适用准则:离散特征的取值之间存在大小、层级的关系,比如收入:[高、中、低];机票的仓位等级:[头等舱、经济舱】等。
进行OneHot编码
适用准则:离散特征的取值之间不存在大小、层级等可进行数值比较的关系,比如性别:[男、女];是否有女朋友:[N,Y]等。
二、如何实现
这里仅对sklearn和Python中的常用实现方案进行记录:
1 进行数值编码
- sklearn.preprocessing.LabelEncoder()
- sklearn.preprocessing.OrdinalEncoder()
- map函数映射
2 OneHot编码
- sklearn.preprocessing.OneHotEncoder()
- pd.get_dummies()
下面通过pandas创建一些数据来演示一下操作,具体原理就不这里记录了:
import numpy as np
import pandas as pd
demo = pd.DataFrame(data=
{'Sex':['male','female','male','female','male'],
'Salary':['high','low','median','high','low'],
'Target':[1,0,1,0,1] })
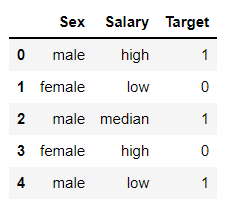

这里的Sex代表性别,Salary代表工资,Target代表标签
通过前面转码方案的描述需要对Sex进行Onehot编码,对收入进行数值编码,这里的Target主要是用来说明LabelEncoder的用法
Sex: Onehot编码
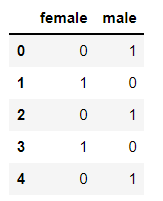
pd.get_dummies()的方法:
from sklearn.preprocessing import OrdinalEncoder,OneHotEncoder,LabelEncoder
res1 = pd.get_dummies(demo['Sex'],columns = np.unique(demo['Sex'].values))
res1
转码后的结果:
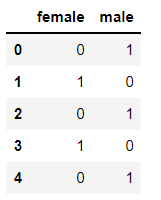
OneHotEncoder()的方法:
onehot = OneHotEncoder(sparse=False)
res2 = onehot.fit_transform(demo['Sex'].values.reshape(-1,1))
res2 = pd.DataFrame(res2,columns=['female','male'])
res2
转码后的结果:
Salary:数值编码
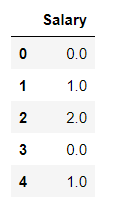
OrdinalEncoder():
res3 = OrdinalEncoder().fit_transform(demo['Salary'].values.reshape(-1, 1))
res3 = pd.DataFrame(res3,columns = ['Salary'])
res3
转码后的结果:
Target:标签转码
LabelEncoder()
这个例子中的Target其实无需进行转码,但是需要记住的是如果需要对label(非特征)进行编码,使用LabelEncoder(),编码后的值为0 and n_classes-1
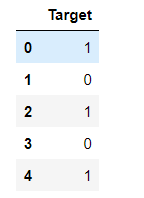
res4 = LabelEncoder().fit_transform(demo['Target'].values.reshape(-1,1))
res4 = pd.DataFrame(res4,columns=['Target'])
res4
转码后的结果:
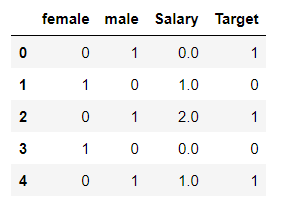
最后将转码后的特征进行合并就可以了
demo = pd.concat([res1,res3,res4],axis = 1)
demo
结果如下:
总结
以上是对离散特征的转码选择的一些个人总结。
Original: https://blog.csdn.net/weixin_43819931/article/details/124278253
Author: Simon Toxic
Title: 离散特征的转码选择【OneHotEncoder、LabelEncoder、OrdinalEncoder、get_dummies】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/696822/
转载文章受原作者版权保护。转载请注明原作者出处!