

BI数据分析笔试题
- 一、华为音乐外包
* - 1.数据仓库测试
- 2.可视化时间空间数据
- 3.信息与熵的计算
- 4.基本数据的元数据
- 5.数据粒度
- 6.数据预处理
- 7.非对称二元属性
- 8.特征工程
- 9.KDD
- 10.无数据标签适合:聚类算法
- 11.抽样方法
- 12.聚类算法
- 13.分类器
- 14.非频繁模式
- 15.离群点
- 二、数据分析笔试题(选择题)
* - 1. 单选题
- 2. 多选题
- 三、参考文章
一、华为音乐外包
1.数据仓库测试
ETL测试是为了确保从源到目的数据经过业务转换完成后是准确的。
同时它还涉及数据的验证,及从源头到目的地数据各个不同阶段验证数据。
测试流程:
分析业务和需求---测试计划和评估---设计测试用例及准备测试数据---执行测试报告bug及回归测试---生成测试报告、并对结果进行分析---测试完成
五大阶段:
分析需求、业务和源数据
获取数据
实现业务逻辑和维度建模
构建和填充数据
生成报告
测试类型:
production validation testing
source to target testing (validation testing)
application upgrades--升级测试
metadata testing--元数据测试
data completeness testing--数据完整性测试
data accuracy testing--数据准确性测试
data transformation testing--数据转换测试
data quality testing--数据质量测试
incremental ETL testing--增量ETL测试
GUI/navigation testing
2.可视化时间空间数据
空间场数据:通过空间维度与属性的特征共同命名
场数据大多与时间、空间、地理位置有关
等高线图、曲面图、矢量场图都是可视化空间数据的技术
时间概念为我们所定义,本质可以描述为物质连续运动的过程
参考文章地址
3.信息与熵的计算
符号 Xi 的信息定义为:
I ( X i ) = − l o g 2 p ( X i ) I(X_i) = -log_2p(X_i)I (X i )=−l o g 2 p (X i )
其中 p(Xi) 是选择该分类的概率
信息永远大于等于0,确定事件p=1,信息 Xi = 0;
4.基本数据的元数据
基本元数据包括关于装载、更新处理、分析处理、及管理方面的信息
举例:下载的一首歌,歌曲文件是一种数据,而描述这首歌的相关信息就是该数据的数据,术语称为元数据。
5.数据粒度
粒度是指数据仓库小数据单元的详细程度和级别
数据越详细,粒度越小,级别越高
粒度的具体划分将直接影响数据仓库中的数据量及查询质量
6.数据预处理
数据预处理的常用流程为:去除唯一属性、处理缺失值、属性编码、数据标准化正则化、特征选择、主成分分析。
数据清洗
缺失值处理:删除变量、统计量填充、哑变量填充
离群值处理
噪声处理
数据集成
实体识别问题
冗余问题
数据值的冲突和处理
数据规约
维度规约
维度变换:主成分分析、因子分析、奇异值分解、聚类、线性组合、流行学习
数据变换
规范化处理
离散化处理
稀疏化处理
估计遗漏值一般在调研或者取样初期确定,数据处理阶段应该是对遗漏值进行插补,有疑问,待后续求证!?
7.非对称二元属性
二元属性:取值为0或者1的属性,所以也成为布尔属性
对称二元属性:属性的两个状态的权重相同,例如:”性别”这一属性的取值”男性”,”女性”。
非对称二元属性:即状态的权重不相同,例如:”HIV”有”阴性”和”阳性”,阳性比较稀少,更重要。
因此,只有非零值才重要的二元属性被称作非对称二元属性。
8.特征工程
下面不属于创建新属性的相关方法的是 :特征修改
特征提取:是指从原始数据抽取新特征(一般会通过降维的方式进行)
特征构造:是从原始数据构造新特征的处理过程
映射数据到新的空间:新空间即新的维度,也就是产生了新的特征属性
9.KDD
Knowledge Discovery in Database–数据挖掘与知识发现
10.无数据标签适合:聚类算法
11.抽样方法
简单抽样(有放回和无放回)
分层抽样
渐进抽样
在数据挖掘中,抽样是一种有效的数据压缩工具。基于抽样的挖掘方法可显著减少挖掘的输入/输出开销和计算代价,而且基于抽样挖掘算法只需要处理初始数据库中的一个小的数据集,达到很好的精确度、极少的计算开销。但是如何选择一个合适的样本尺寸,往往很难确定。这时我们可以通过渐进式抽样,找出最佳样本大小。渐进式抽样过程是从数据的初始样本开始,然后渐进式地增加样本的大小,直到获得一个可接收的精度。
系统抽样
簇抽样
蓄水池抽样
在抽样方法中,当合适的样本容量很难确定时,可以使用的抽样方法是渐进抽样。
12.聚类算法
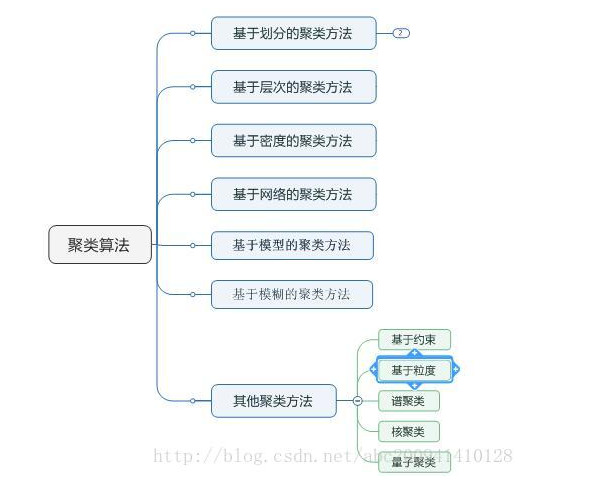

K-Means–K均值聚类算法
均值漂移聚类
DBSCAN–基于密度的算法
用高斯混合模型(GMM)的最大期望(EM)聚类
凝聚层次聚类
图团体检测(graph community detection)
二分K均值,MST 都属于分裂的层次聚类算法。
聚类算法:K均值,DBSCAN,Jarvis-Patrick
Ward方法:将两个簇的邻近度定义为两个簇合并时导致的平方误差的增量,它是一种凝聚层次聚类技术。
组平均:将两个簇的邻近度定义为不同簇的所有点对的平均逐对邻近度,它是一种凝聚层次聚类技术。
聚类分析中 min(单链)、Chameleon等技术可以处理任意形状的簇
簇有效性的面向相似性的度量包括:Rand统计量,Jaccard系数
; 13.分类器
14.非频繁模式
15.离群点
离群点检测方法:
基于统计学方法:
参数方法:一元正态分布、马哈拉诺比斯距离(检测多元离群点)
非参数法:直方图
基于邻近性的方法:
基于距离的离群点检测
基于密度的离群点检测
基于聚类的方法:通过考察对象与簇之间的关系检测离群点
基于分类的方法:
。。。
一个对象的离群点得分是该对象周围密度的逆。这是基于 密度 的离群点定义。
检测一元正态分布中的离群点,属于异常检测中的基于 统计方法 的离群点检测。
二、数据分析笔试题(选择题)
1. 单选题
- 用户有一种感兴趣的模式并且希望在数据集中找到相似的模式,属于数据挖掘哪一类任务?(A)
A. 根据内容检索
B. 建模描述
C. 预测建模
D. 寻找模式和规则
- 下面哪个不属于数据的属性类型:(D),属于定量的属性类型是:©
A 标称
B 序数
C 区间
D相异 - 以下哪种方法不属于特征选择的标准方法: (D)
A 嵌入
B 过滤
C 包装
D 抽样 - 考虑值集{1、2、3、4、5、90},其截断均值(p=20%)是 ©
A 2
B 3
C 3.5
D 5
解析:截断均值计算:题中给出的p=20%,那么丢弃掉高低端20%/2=10%的数据,题中共有6个数据,就截掉6*10%约等于1个,截掉前1个后1个,剩下求平均,结果为3.5;
- 下面哪个属于映射数据到新的空间的方法? (A)
A 傅立叶变换
B 特征加权
C 渐进抽样
D 维归约 - 关于OLAP的特性,下面正确的是: (D)
(1)快速性 (2)可分析性 (3)多维性 (4)信息性 (5)共享性
A. (1) (2) (3)
B. (2) (3) (4)
C. (1) (2) (3) (4)
D. (1) (2) (3) (4) (5) - 关于OLAP和OLTP的区别描述,不正确的是: ©
A. OLAP主要是关于如何理解聚集的大量不同的数据.它与OTAP应用程序不同.
B. 与OLAP应用程序不同,OLTP应用程序包含大量相对简单的事务.
C. OLAP的特点在于事务量大,但事务内容比较简单且重复率高.
D. OLAP是以数据仓库为基础的,但其最终数据来源与OLTP一样均来自底层的数据库系统,两者面对的用户是相同的.
- OLAM技术一般简称为”数据联机分析挖掘”,下面说法正确的是: (D)
A. OLAP和OLAM都基于客户机/服务器模式,只有后者有与用户的交互性;
B. 由于OLAM的立方体和用于OLAP的立方体有本质的区别.
C. 基于WEB的OLAM是WEB技术与OLAM技术的结合.
D. OLAM服务器通过用户图形接口接收用户的分析指令,在元数据知道的情况 下,对超级立方体作一定的操作.
- 设X={1,2,3}是频繁项集,则可由X产生__©__个关联规则。
A、4
B、5
C、6
D、7 - 概念分层图是__(B)__图。
A、无向无环
B、有向无环
C、有向有环
D、无向有环 - 频繁项集、频繁闭项集、最大频繁项集之间的关系是: ©
A、频繁项集 频繁闭项集 =最大频繁项集
B、频繁项集 = 频繁闭项集 最大频繁项集
C、频繁项集 频繁闭项集 最大频繁项集
D、频繁项集 = 频繁闭项集 = 最大频繁项集 - 考虑下面的频繁3-项集的集合:{1,2,3},{1,2,4},{1,2,5},{1,3,4},{1,3,5},{2,3,4},{2,3,5},{3,4,5}假定数据集中只有5个项,采用 合并策略,由候选产生过程得到4-项集不包含(C)
A、1,2,3,4
B、1,2,3,5
C、1,2,4,5
D、1,3,4,5
根据数据挖掘Apriori算法的性质之一:判定是否可作为K项频繁集是通过K项集分裂为K个K-1项集,考察K-1项集是否为Lk-1,要生成4-项集,{1,2,4,5}分裂后为{1,2,4}{2,4,5}{1,2,5}{1,4,5}其中,{1,4,5}不属于频繁3项集,所以{1,2,4,5}不能作为4项集,因为有性质为:任何非频繁的K-1项集都不可能是频繁项集K项集的子集.
- 下面选项中t不是s的子序列的是 ( C )
A、s= - 在图集合中发现一组公共子结构,这样的任务称为 ( B )
A、频繁子集挖掘
B、频繁子图挖掘
C、频繁数据项挖掘
D、频繁模式挖掘 - 下列度量不具有反演性的是 (D)
A、系数
B、几率
C、Cohen度量
D、兴趣因子 - 下列__(A)__不是将主观信息加入到模式发现任务中的方法。
A、与同一时期其他数据对比
B、可视化
C、基于模板的方法
D、主观兴趣度量 - 下面购物篮能够提取的3-项集的最大数量是多少(C)
ID 购买项
1 牛奶,啤酒,尿布
2 面包,黄油,牛奶
3 牛奶,尿布,饼干
4 面包,黄油,饼干
5 啤酒,饼干,尿布
6 牛奶,尿布,面包,黄油
7 面包,黄油,尿布
8 啤酒,尿布
9 牛奶,尿布,面包,黄油
10 啤酒,饼干
A、1
B、2
C、3
D、4
- 以下哪些算法是分类算法,(B)
A,DBSCAN
B,C4.5
C,K-Mean
D,EM - 以下哪些分类方法可以较好地避免样本的不平衡问题, (A)
A,KNN
B,SVM
C,Bayes
D,神经网络
- 决策树中不包含一下哪种结点, ©
A,根结点(root node)
B,内部结点(internal node)
C,外部结点(external node)
D,叶结点(leaf node)
- 以下哪项关于决策树的说法是错误的 ©
A. 冗余属性不会对决策树的准确率造成不利的影响
B. 子树可能在决策树中重复多次
C. 决策树算法对于噪声的干扰非常敏感
D. 寻找最佳决策树是NP完全问题 - 在基于规则分类器的中,依据规则质量的某种度量对规则排序,保证每一个测试记录都是由覆盖它的”最好的”规格来分类,这种方案称为 (B)
A. 基于类的排序方案
B. 基于规则的排序方案
C. 基于度量的排序方案
D. 基于规格的排序方案。 - 以下哪些算法是基于规则的分类器 (A)
A. C4.5
B. KNN
C. Na?ve Bayes
D. ANN - 如果规则集R中不存在两条规则被同一条记录触发,则称规则集R中的规则为(C);
A, 无序规则
B,穷举规则
C, 互斥规则
D,有序规则 - 如果对属性值的任一组合,R中都存在一条规则加以覆盖,则称规则集R中的规则为(B)
A, 无序规则
B,穷举规则
C, 互斥规则
D,有序规则 - 如果规则集中的规则按照优先级降序排列,则称规则集是 (D)
A, 无序规则
B,穷举规则
C, 互斥规则
D,有序规则 - 如果允许一条记录触发多条分类规则,把每条被触发规则的后件看作是对相应类的一次投票,然后计票确定测试记录的类标号,称为(A)
A, 无序规则
B,穷举规则
C, 互斥规则
D,有序规则 - 考虑两队之间的足球比赛:队0和队1。假设65%的比赛队0胜出,剩余的比赛队1获胜。队0获胜的比赛中只有30%是在队1的主场,而队1取胜的比赛中75%是主场获胜。如果下一场比赛在队1的主场进行队1获胜的概率为 ©
A,0.75
B,0.35
C,0.4678
D, 0.5738
答案貌似错误的,根据贝叶斯公式计算应该是0.5738;假设踢了100场,队0赢了65场,队1赢了35场;队1的主场,队0赢了65 _0.3 = 19.5场,队1赢了35_0.75 = 26.25场;则队1在在自己主场赢得概率:26.25/(19.5+26.25)= 0.5738
- 以下关于人工神经网络(ANN)的描述错误的有 (A)
A,神经网络对训练数据中的噪声非常鲁棒
B,可以处理冗余特征
C,训练ANN是一个很耗时的过程
D,至少含有一个隐藏层的多层神经网络 - 通过聚集多个分类器的预测来提高分类准确率的技术称为 (A)
A,组合(ensemble)
B,聚集(aggregate)
C,合并(combination)
D,投票(voting) - 简单地将数据对象集划分成不重叠的子集,使得每个数据对象恰在一个子集中,这种聚类类型称作( B )
A、层次聚类
B、划分聚类
C、非互斥聚类
D、模糊聚类 - 在基本K均值算法里,当邻近度函数采用( A )的时候,合适的质心是簇中各点的中位数。
A、曼哈顿距离
B、平方欧几里德距离
C、余弦距离
D、Bregman散度 - BIRCH是一种( B )。
A、分类器
B、聚类算法
C、关联分析算法
D、特征选择算法 - 检测一元正态分布中的离群点,属于异常检测中的基于( A )的离群点检测。
A、统计方法
B、邻近度
C、密度
D、聚类技术
68.( C )将两个簇的邻近度定义为不同簇的所有点对的平均逐对邻近度,它是一种凝聚层次聚类技术。
A、MIN(单链)
B、MAX(全链)
C、组平均
D、Ward方法
69.( D )将两个簇的邻近度定义为两个簇合并时导致的平方误差的增量,它是一种凝聚层次聚类技术。
A、MIN(单链)
B、MAX(全链)
C、组平均
D、Ward方法
- DBSCAN在最坏情况下的时间复杂度是( B )。
A、O(m)
B、O(m2)
C、O(log m)
D、O(m*log m) - 在基于图的簇评估度量表里面,如果簇度量为proximity(Ci , C),簇权值为mi ,那么它的类型是( C )。
A、基于图的凝聚度
B、基于原型的凝聚度
C、基于原型的分离度
D、基于图的凝聚度和分离度 - 关于K均值和DBSCAN的比较,以下说法不正确的是( A )。
A、K均值丢弃被它识别为噪声的对象,而DBSCAN一般聚类所有对象。
B、K均值使用簇的基于原型的概念,而DBSCAN使用基于密度的概念。
C、K均值很难处理非球形的簇和不同大小的簇,DBSCAN可以处理不同大小和不同形状的簇。
D、K均值可以发现不是明显分离的簇,即便簇有重叠也可以发现,但是DBSCAN会合并有重叠的簇。 - 以下是哪一个聚类算法的算法流程:①构造k-最近邻图。②使用多层图划分算法划分图。③repeat:合并关于相对互连性和相对接近性而言,最好地保持簇的自相似性的簇。④until:不再有可以合并的簇。( C )。
A、MST
B、OPOSSUM
C、Chameleon
D、Jarvis-Patrick(JP) - 考虑这么一种情况:一个对象碰巧与另一个对象相对接近,但属于不同的类,因为这两个对象一般不会共享许多近邻,所以应该选择( D )的相似度计算方法。
A、平方欧几里德距离
B、余弦距离
C、直接相似度
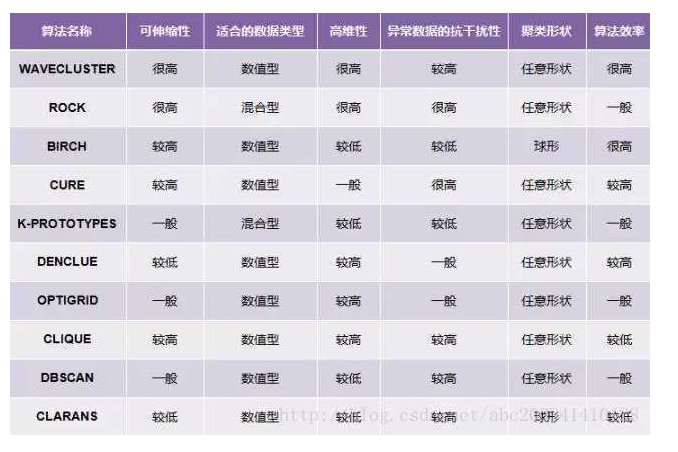
D、共享最近邻 - 以下属于可伸缩聚类算法的是( A )。
A、CURE
B、DENCLUE
C、CLIQUE
D、OPOSSUM - 以下哪个聚类算法不是属于基于原型的聚类( D )。
A、模糊c均值
B、EM算法
C、SOM
D、CLIQUE - 关于混合模型聚类算法的优缺点,下面说法正确的是( B )。
A、当簇只包含少量数据点,或者数据点近似协线性时,混合模型也能很好地处理。
B、混合模型比K均值或模糊c均值更一般,因为它可以使用各种类型的分布。
C、混合模型很难发现不同大小和椭球形状的簇。
D、混合模型在有噪声和离群点时不会存在问题。 - 以下哪个聚类算法不属于基于网格的聚类算法( D )。
A、STING
B、WaveCluster
C、MAFIA
D、BIRCH - 下面关于Jarvis-Patrick(JP)聚类算法的说法不正确的是( D )。
A、JP聚类擅长处理噪声和离群点,并且能够处理不同大小、形状和密度的簇。
B、JP算法对高维数据效果良好,尤其擅长发现强相关对象的紧致簇。
C、JP聚类是基于SNN相似度的概念。
D、JP聚类的基本时间复杂度为O(m)。
2. 多选题
- 寻找数据集中的关系是为了寻找精确、方便并且有价值地总结了数据的某一特征的表示,这个过程包括了以下哪些步骤? (A B C D)
A. 决定要使用的表示的特征和结构
B. 决定如何量化和比较不同表示拟合数据的好坏
C. 选择一个算法过程使评分函数最优
D. 决定用什么样的数据管理原则以高效地实现算法。 - 数据挖掘的预测建模任务主要包括哪几大类问题? (A B)
A. 分类
B. 回归
C. 模式发现
D. 模式匹配 - 数据挖掘算法的组件包括:(A B C D)
A. 模型或模型结构
B. 评分函数
C. 优化和搜索方法
D. 数据管理策略 - 在现实世界的数据中,元组在某些属性上缺少值是常有的。描述处理该问题的各种方法有: (ABCDE)
A忽略元组
B使用属性的平均值填充空缺值
C使用一个全局常量填充空缺值
D使用与给定元组属同一类的所有样本的平均值
E使用最可能的值填充空缺值 - 下面哪些属于可视化高维数据技术 (ABCE)
A 矩阵
B 平行坐标系
C星形坐标 D散布图
E Chernoff脸 - 下面属于数据集的一般特性的有:( B C D)
A 连续性
B 维度
C 稀疏性
D 分辨率
E 相异性 - 以下各项均是针对数据仓库的不同说法,你认为正确的有(BDE )。
A.数据仓库就是数据库
B.数据仓库是一切商业智能系统的基础
C.数据仓库是面向业务的,支持联机事务处理(OLTP)
D.数据仓库支持决策而非事务处理
E.数据仓库的主要目标就是帮助分析,做长期性的战略制定 - 数据仓库在技术上的工作过程是: (ABCD)
A. 数据的抽取
B. 存储和管理
C. 数据的表现
D. 数据仓库设计 - 利用Apriori算法计算频繁项集可以有效降低计算频繁集的时间复杂度。在以下的购物篮中产生支持度不小于3的候选3-项集,在候选2-项集中需要剪枝的是(BD)
ID 项集
1 面包、牛奶
2 面包、尿布、啤酒、鸡蛋
3 牛奶、尿布、啤酒、可乐
4 面包、牛奶、尿布、啤酒
5 面包、牛奶、尿布、可乐
A、啤酒、尿布
B、啤酒、面包
C、面包、尿布
D、啤酒、牛奶
解析:面包:,4,牛奶:4,尿布:4,啤酒:3,鸡蛋:1,可乐:2
python数据分析笔试题-pandas
D)
A 连续性
B 维度
C 稀疏性
D 分辨率
E 相异性
- 以下各项均是针对数据仓库的不同说法,你认为正确的有(BDE )。
A.数据仓库就是数据库
B.数据仓库是一切商业智能系统的基础
C.数据仓库是面向业务的,支持联机事务处理(OLTP)
D.数据仓库支持决策而非事务处理
E.数据仓库的主要目标就是帮助分析,做长期性的战略制定 - 数据仓库在技术上的工作过程是: (ABCD)
A. 数据的抽取
B. 存储和管理
C. 数据的表现
D. 数据仓库设计 - 利用Apriori算法计算频繁项集可以有效降低计算频繁集的时间复杂度。在以下的购物篮中产生支持度不小于3的候选3-项集,在候选2-项集中需要剪枝的是(BD)
ID 项集
1 面包、牛奶
2 面包、尿布、啤酒、鸡蛋
3 牛奶、尿布、啤酒、可乐
4 面包、牛奶、尿布、啤酒
5 面包、牛奶、尿布、可乐
A、啤酒、尿布
B、啤酒、面包
C、面包、尿布
D、啤酒、牛奶
解析:面包:,4,牛奶:4,尿布:4,啤酒:3,鸡蛋:1,可乐:2
三、参考文章
https://blog.csdn.net/zxd1754771465/article/details/73506169?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
https://blog.csdn.net/weixin_43751243/article/details/102499674?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-4.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-4.nonecase
https://blog.csdn.net/YYIverson/article/details/100163387
https://www.zybuluo.com/rianusr/note/1156011
https://wenku.baidu.com/view/c408af8abe1e650e52ea99d0.html
https://blog.csdn.net/abc200941410128/article/details/78541273?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
https://blog.csdn.net/weixin_42056745/article/details/101287231
https://blog.csdn.net/mw21501050/article/details/75389267
Original: https://blog.csdn.net/Artificial_idiots/article/details/122925051
Author: 若如初见kk
Title: BI数据分析笔试题及答案(华为音乐外包)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/696709/
转载文章受原作者版权保护。转载请注明原作者出处!