

目录
- 一、pandas入门
* - 1.pandas的安装
- 2.数据结构
– - 3.数据查看
- 4.数据输入和输出
– - 5.数据选择
– - 6.训练场
–- 6.1 创建1000条语、数、外、Python的考试成绩DataFrame,范围是0~150包含150,分别将数据保存到csv文件以及Excel文件,保存时不保存行索引。
- 6.2 创建使用字典创建DataFrame,行索引是a~z,列索引是:身高(160-185)、体重(50-90)、学历(无、本科、硕士、博士)。身高、体重数据使用NumPy随机数生成,学历数据先创建数组 edu =np.array([‘无’,’本科’,’硕士’,’博士’]),然后使用花式索引从四个数据中选择26个数据。
- 6.3 使用题目二中的数据,进行数据筛选。
+ - 6.3.1 筛选索引大于 ‘t’ 的所有数据
- 6.3.2 筛选学历是博士,身高大于170或者体重小于80的学生
- 6.4 使用题目二中数据,开始学生们开始减肥
+ - 6.4.1 本科生减肥,减掉的体重统一是10
- 6.4.2 博士生减肥,减掉体重范围是5~10
- 二、pandas高级
* - 1.数据集成
– - 2.数据清洗
– - 3.数据转换
– - 4.训练场
– - 三、pandas进阶
* - 1.数据重塑
– - 2.数学和统计方法
– - 3.数据排序
– - 4.分箱操作
– - 5.分组聚合
– - 6.数据可视化
– - 7.训练场
– - 总结:pandas库的亮点
一、pandas入门


- Python在数据处理和准备方面一直做得很好,但在数据分析和建模方面就差一些。pandas帮助填补了这一空白,使您能够在Python中执行整个数据分析工作流程,而不必切换到更特定于领域的语言,如R。
- 与出色的 jupyter工具包和其他库相结合,Python中用于进行数据分析的环境在性能、生产率和协作能力方面都是卓越的。
- pandas是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。pandas是Python进行数据分析的必备高级工具。
- pandas的主要数据结构是 Series(一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数案例
- 处理数据一般分为几个阶段:数据整理与清洗、数据分析与建模、数据可视化与制表,Pandas 是处理数据的理想工具。
🌟 学习本文之前,需要先自修:NumPy从入门到进阶 ,本文中很多的操作在NumPy从入门到进阶 一文中有详细的介绍,包含一些软件以及扩展库,图片的安装和下载流程,本文会直接进行使用。
; 1.pandas的安装
🚩Windows + R,输入 cmd,输入 pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple 下载 pandas,如果你曾跟着NumPy从入门到进阶进行学习,这一步可以省略【已经安装好了 pandas】
安装好后,进入 jupyter,运行如下代码,没有报错证明安装成功:

; 2.数据结构
2.1 一维结构(Series)
import pandas as pd
s = pd.Series(data = [9, 8, 7, 6], index = ['a', 'b', 'c', 'd'])
display(s)
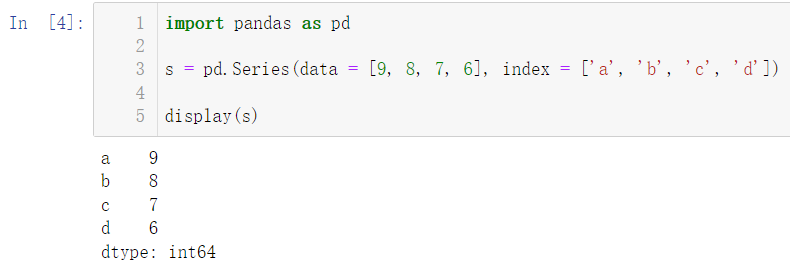
可以看到,我们创建了索引(index)为
'a' 'b' 'c' 'd',data 为 9 8 7 6的一维结构,我们还可以不指定索引(index),那么就会默认为 0 1 2 ...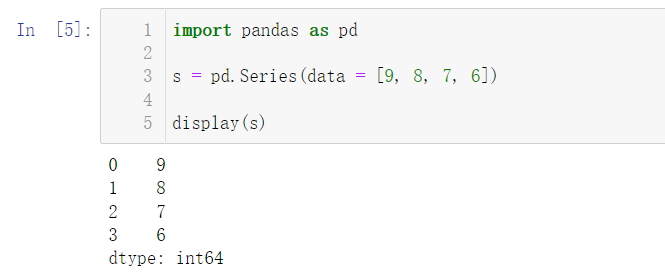
一维Series和之前NumPy有何不同呢?
区别在于索引,是一一对应的,即索引也可以拥有自己的”名字”,而NumPy则是:自然索引(0 ~ n)
2.2 二维结构(DataFrame)
import pandas as pd
import numpy as np
pd.DataFrame(data = np.random.randint(0, 150, size = (5, 3)))
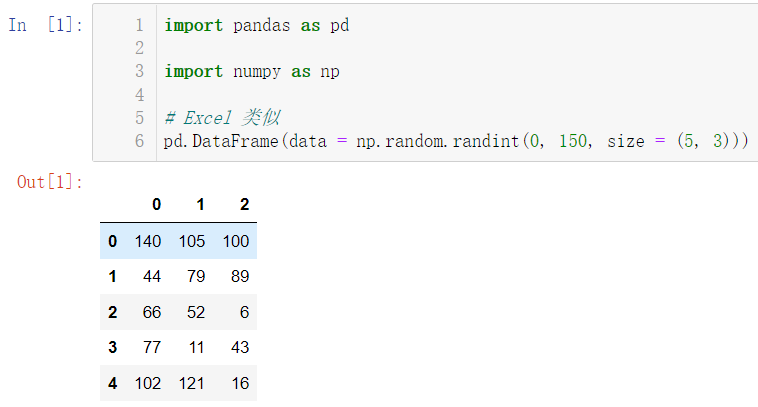
默认的行索引和列索引也都是从0开始的,我们说过,pandas可以自己定义我们的索引:
import pandas as pd
import numpy as np
pd.DataFrame(data = np.random.randint(0, 150, size = (5, 3)),
columns = ['Python', 'English', 'Math'], index = list('ABCDE'))
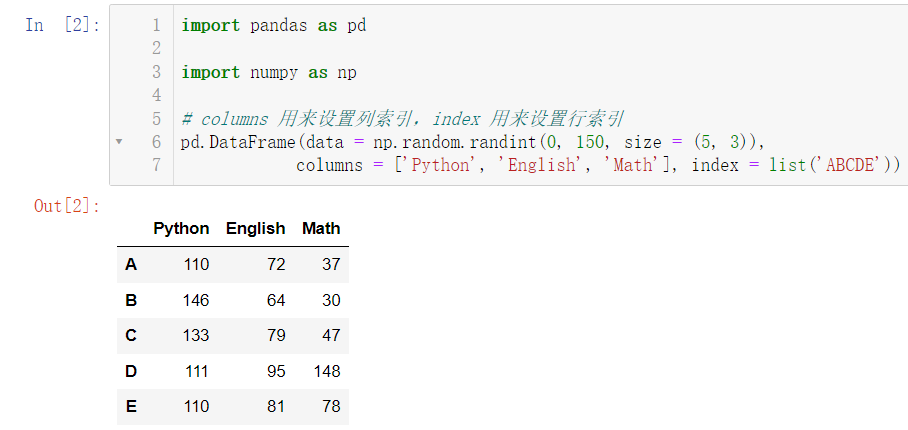
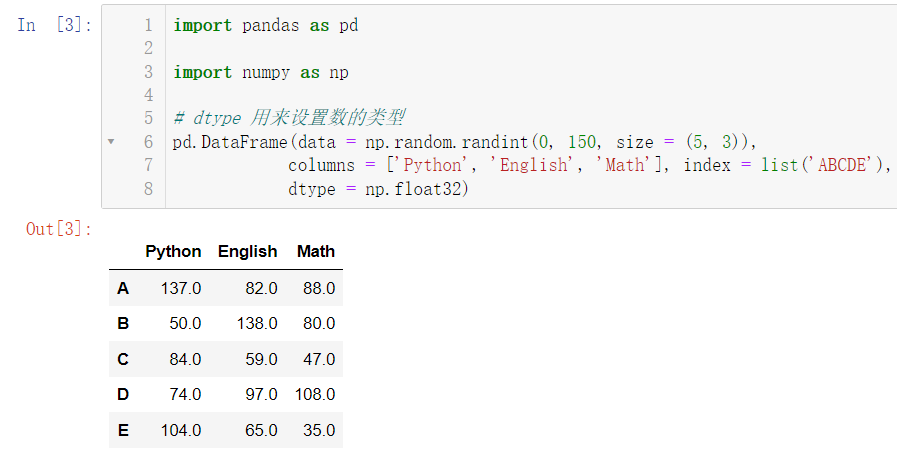
我们发现,表格中的数都是正数,我们可以用 dtype 属性设置为小数或者其他:
import pandas as pd
import numpy as np
pd.DataFrame(data = np.random.randint(0, 150, size = (5, 3)),
columns = ['Python', 'English', 'Math'], index = list('ABCDE'),
dtype = np.float32)
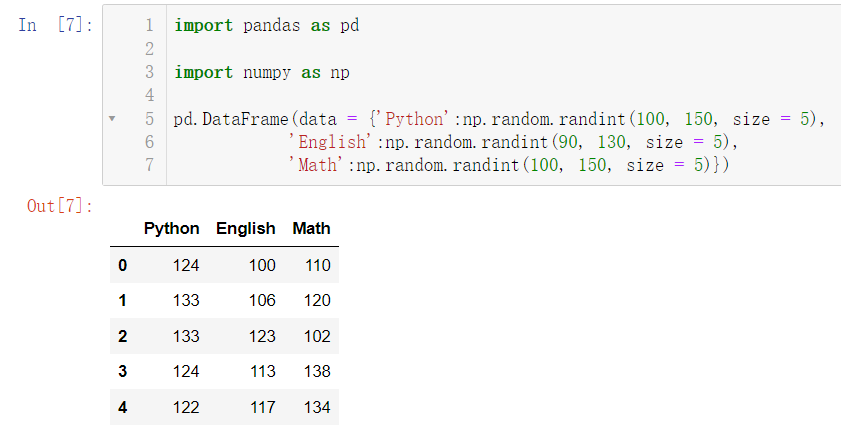
下面介绍另一种创建的方法:我们学过 Python 后,你可能会发现,在 Python 中的字典这种数据类型好像和这个特别像,故我们可以使用字典去进行创建:
import pandas as pd
import numpy as np
pd.DataFrame(data = {'Python':np.random.randint(100, 150, size = 5),
'English':np.random.randint(90, 130, size = 5),
'Math':np.random.randint(100, 150, size = 5)})
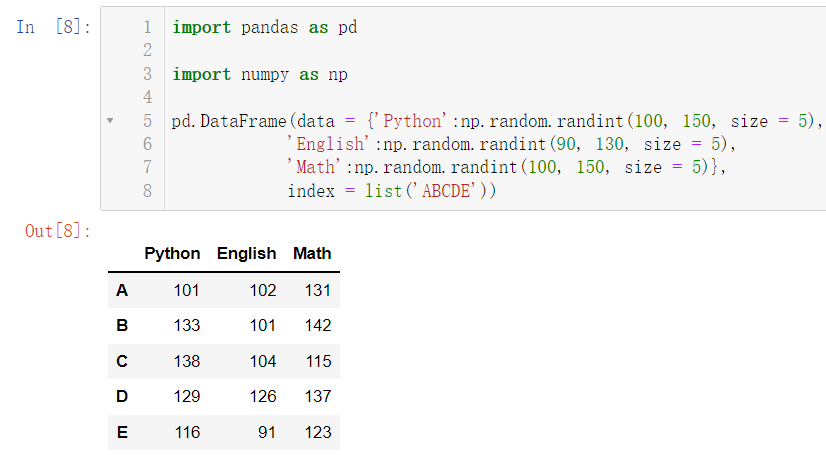
我们设置了列索引,接下来我们来设置行索引:
import pandas as pd
import numpy as np
pd.DataFrame(data = {'Python':np.random.randint(100, 150, size = 5),
'English':np.random.randint(90, 130, size = 5),
'Math':np.random.randint(100, 150, size = 5)},
index = list('ABCDE'))
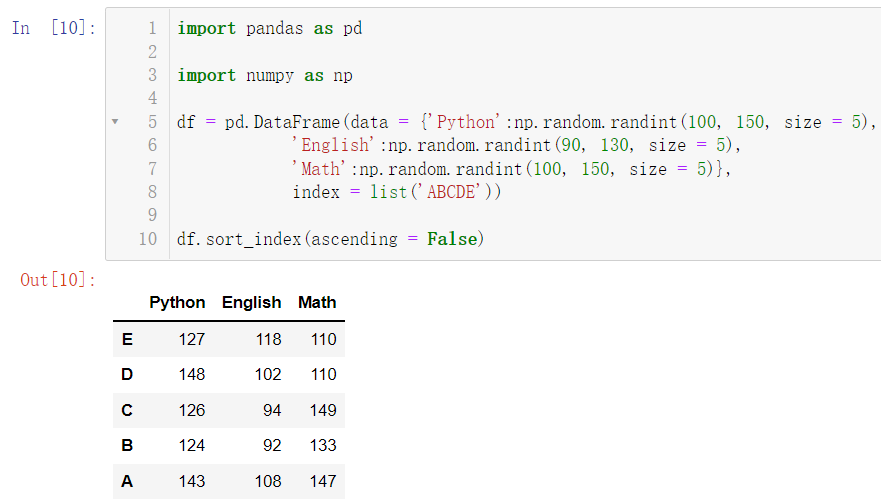
我们当然可以对其进行排序,比如我们按照行索引的大小进行降序:
import pandas as pd
import numpy as np
df = pd.DataFrame(data = {'Python':np.random.randint(100, 150, size = 5),
'English':np.random.randint(90, 130, size = 5),
'Math':np.random.randint(100, 150, size = 5)},
index = list('ABCDE'))
df.sort_index(ascending = False)
3.数据查看
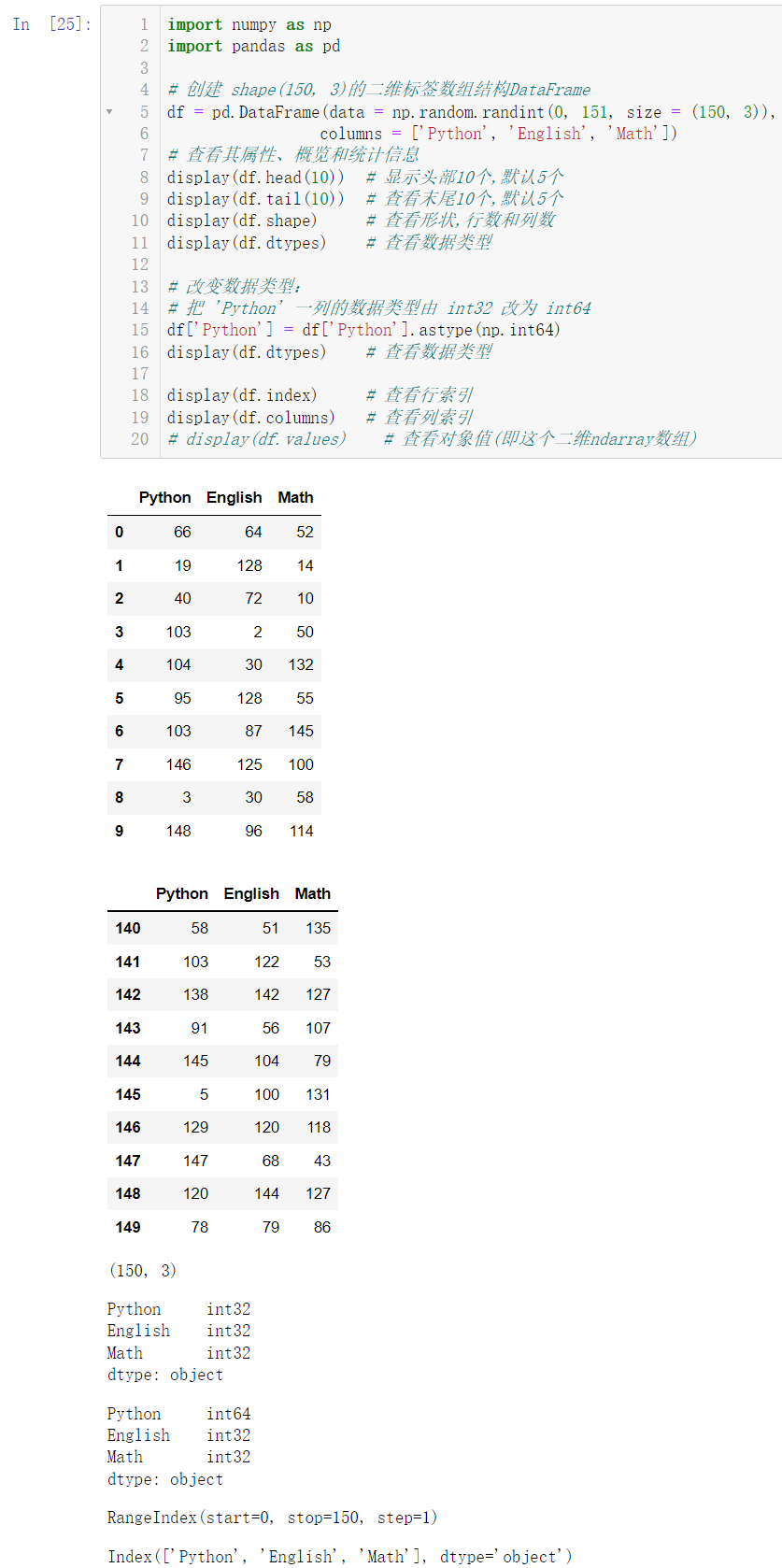
🚩接下来来介绍一些查看数据的方法:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 151, size = (150, 3)),
columns = ['Python', 'English', 'Math'])
display(df.head(10))
display(df.tail(10))
display(df.shape)
display(df.dtypes)
df['Python'] = df['Python'].astype(np.int64)
display(df.dtypes)
display(df.index)
display(df.columns)
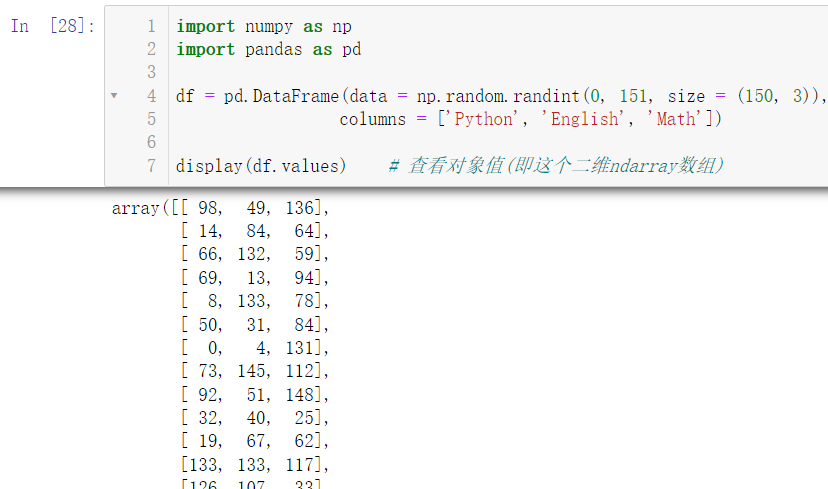
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 151, size = (150, 3)),
columns = ['Python', 'English', 'Math'])
display(df.values)
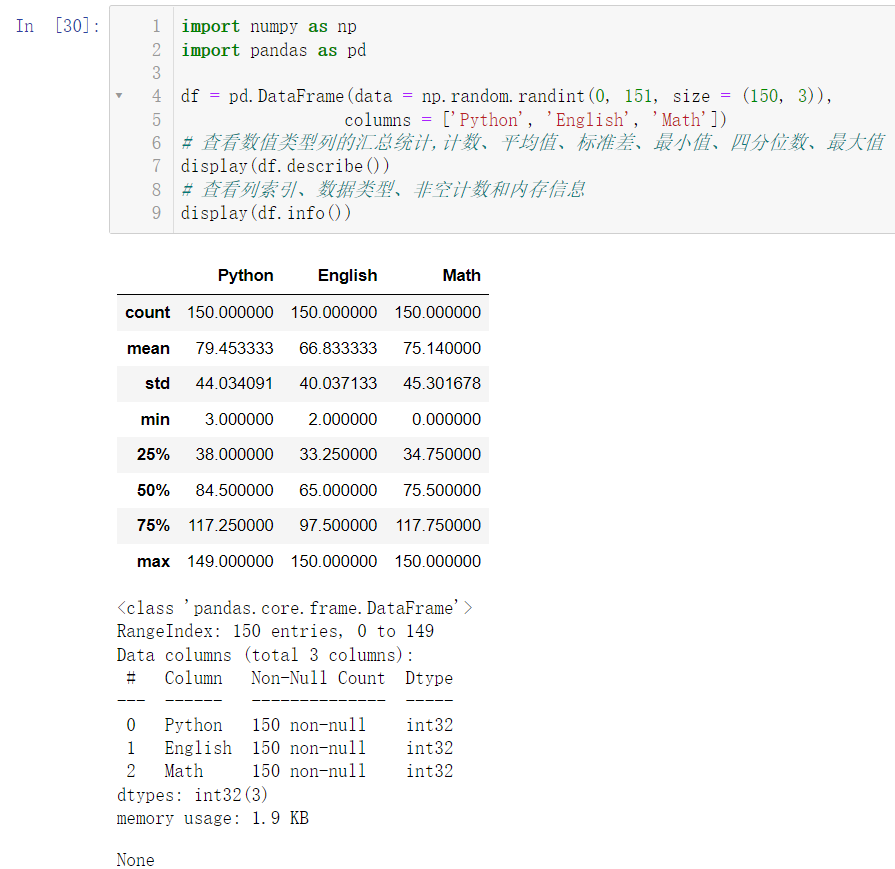
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 151, size = (150, 3)),
columns = ['Python', 'English', 'Math'])
display(df.describe())
display(df.info())
4.数据输入和输出
4.1 csv
🚩我们想要存储数据,首先要创建数据:
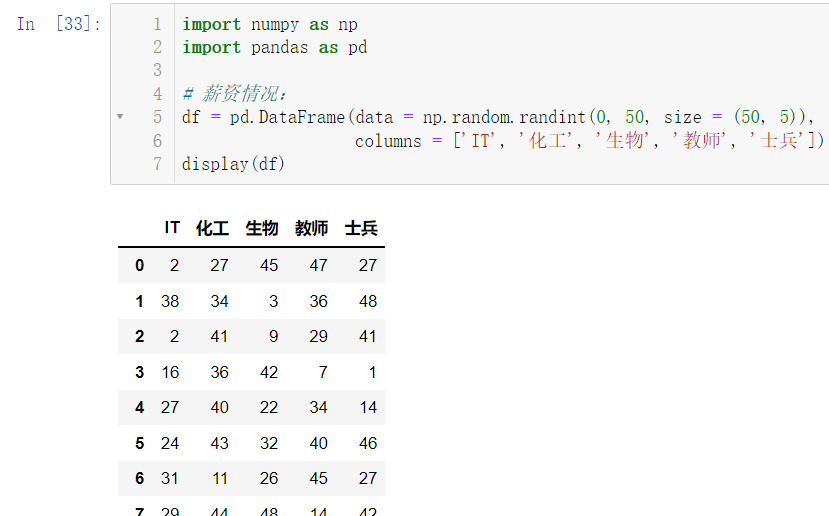
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 50, size = (50, 5)),
columns = ['IT', '化工', '生物', '教师', '士兵'])
display(df)
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 50, size = (50, 5)),
columns = ['IT', '化工', '生物', '教师', '士兵'])
display(df)
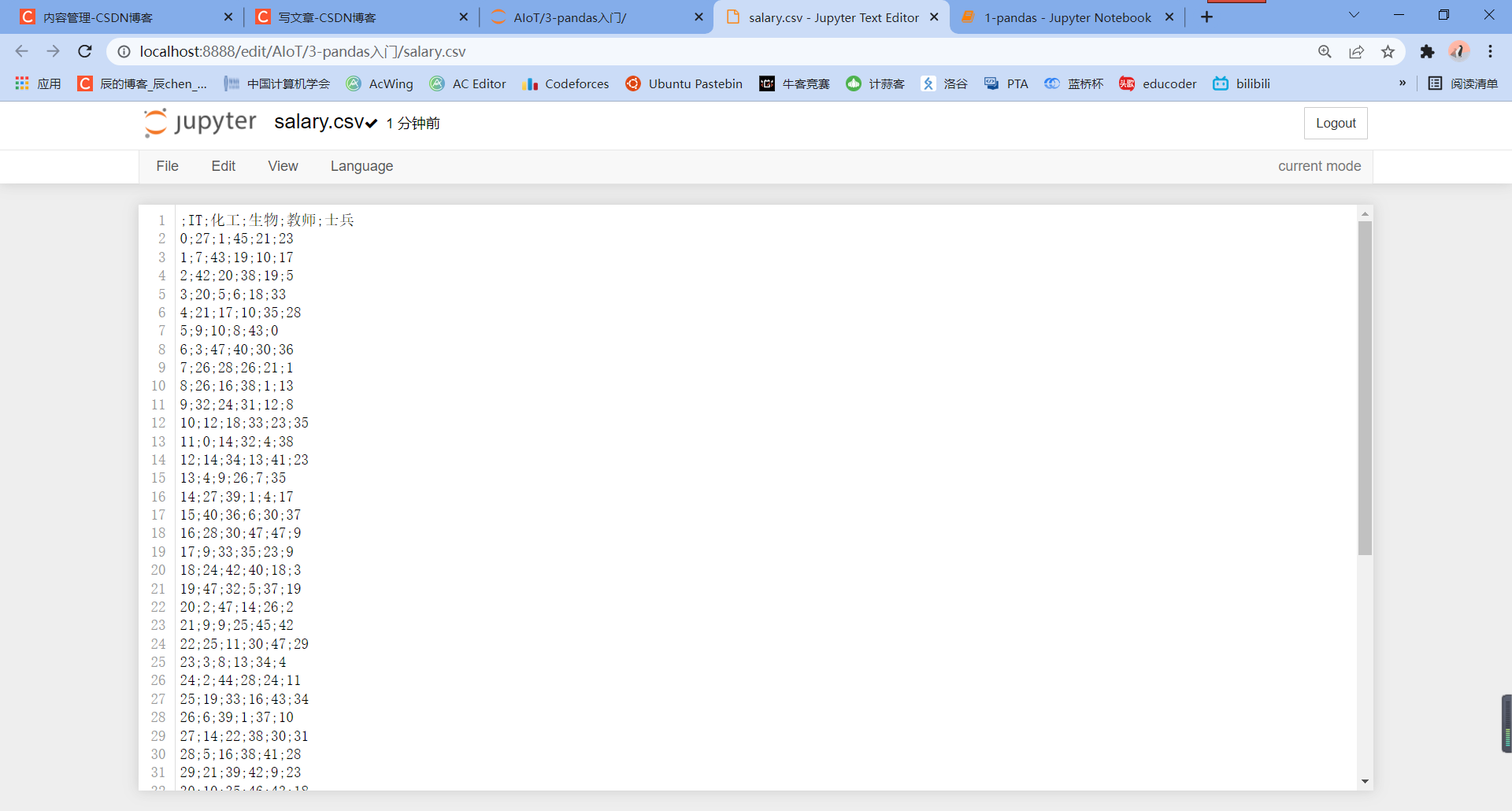
df.to_csv('./salary.csv',
sep = ';',
header = True,
index = True)
点击该文件就可以查看保存的数据信息:
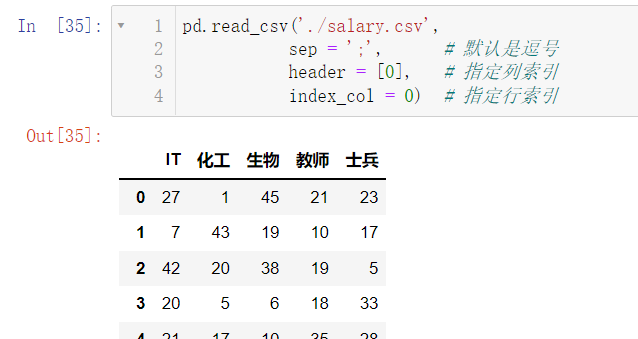
能保存数据自然就有加载数据的操作:
pd.read_csv('./salary.csv',
sep = ';',
header = [0],
index_col = 0)
4.2 Excel
🚩如果要保存为 Excel 文件,我们需要装两个库:
pip install xlrd -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install xlwt -i https://pypi.tuna.tsinghua.edu.cn/simple
按下 Windows + R,输入 cmd,然后输入上述两行,如果你曾跟着NumPy从入门到进阶进行学习,这一步可以省略
import numpy as np
import pandas as pd
df1 = pd.DataFrame(data = np.random.randint(0, 50, size = [50,5]),
columns = ['IT', '化工', '生物', '教师', '士兵'])
df1.to_excel('./salary.xlsx',
sheet_name = 'salary',
header = True,
index = False)
这样我们就保存了 df1 的数据,并把文件存到了当前目录下:
注意这个文件我们在 jupyter 上是无法打开的,但是我们可以在文件管理中找到并打开:
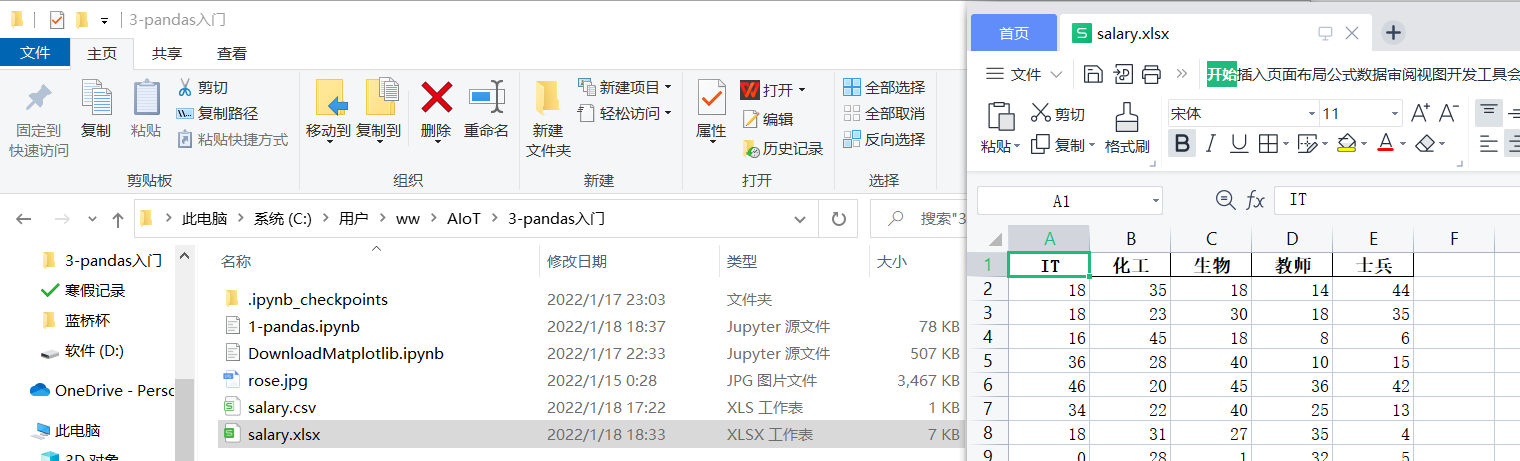
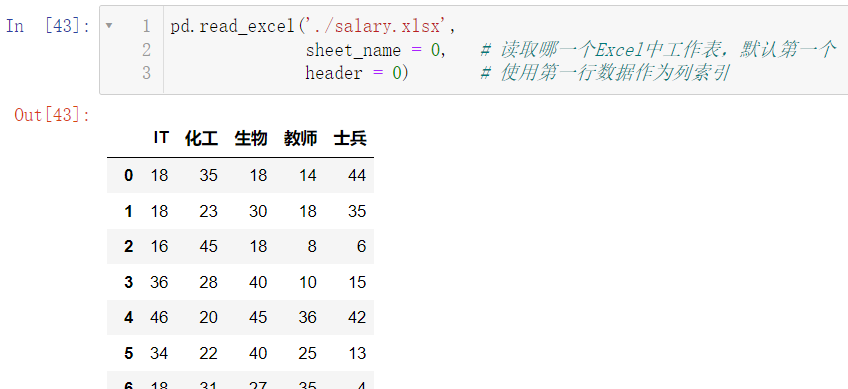
接下来我们来读取这个文件:
pd.read_excel('./salary.xlsx',
sheet_name = 0,
header = 0)
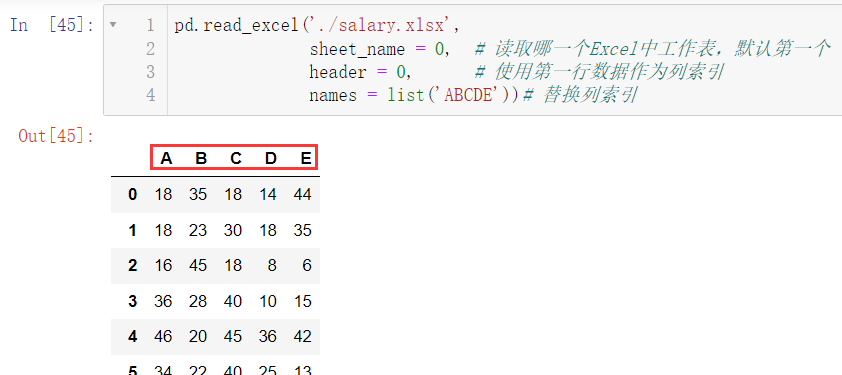
我们还可以替换列索引,比如我们把列索引替换为
ABCDE
pd.read_excel('./salary.xlsx',
sheet_name = 0,
header = 0,
names = list('ABCDE'))
我们还可以指定行索引:
pd.read_excel('./salary.xlsx',
sheet_name = 0,
header = 0,
names = list('ABCDE'),
index_col = 1)

我们打开我们的 Excel 表格:
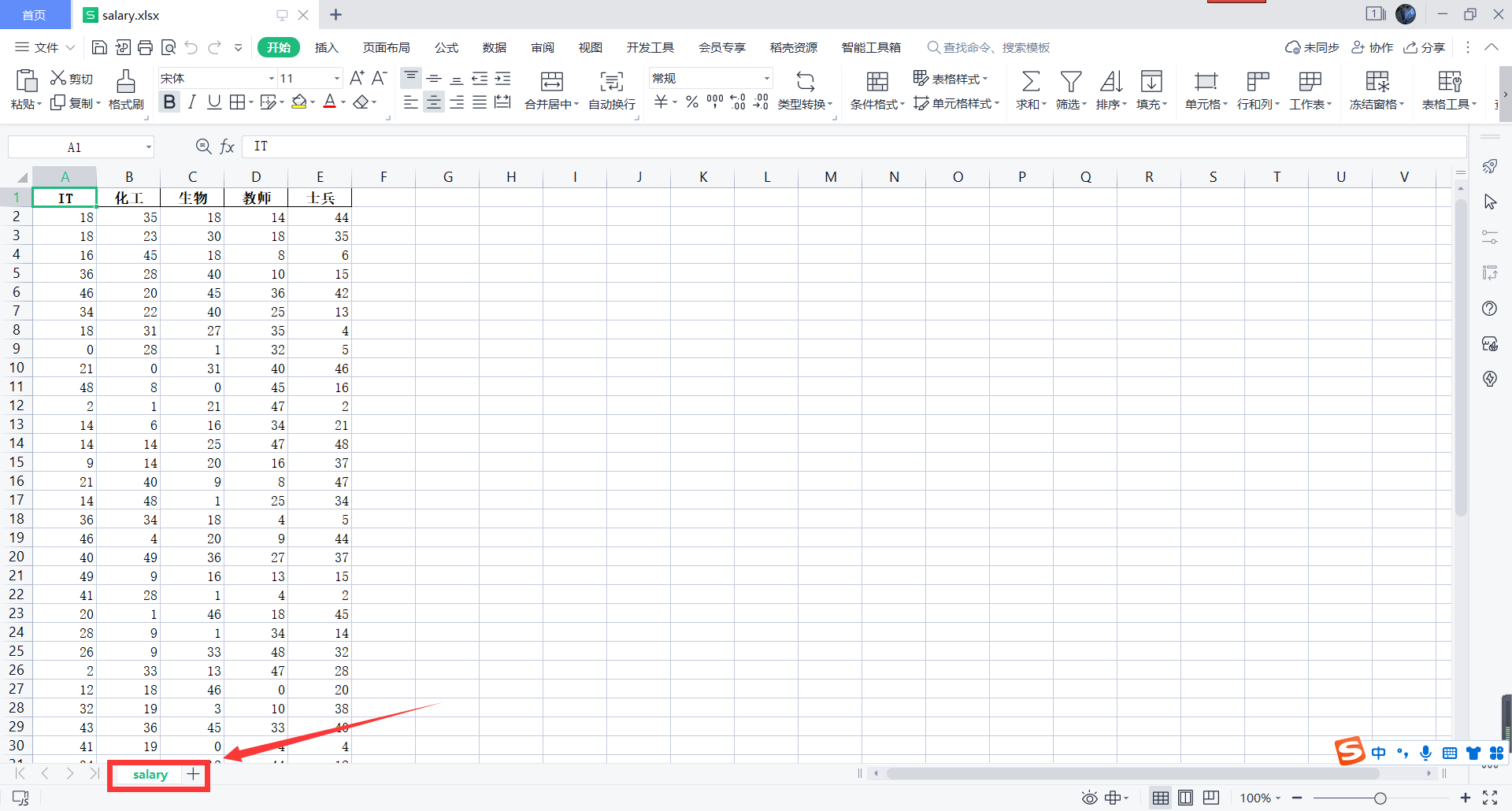
可以看到只有一个工作表,我们如果现在想再创建一个工作表用来存储其他数据,可以按下述操作:
df2 = pd.DataFrame(data = np.random.randint(0, 50, size = [150, 3]),
columns=['Python', 'Tensorflow', 'Keras'])
df2.to_excel('./salary.xlsx',
sheet_name = 'test',
header = True,
index = False)
我们再来查看一下我们的文件:
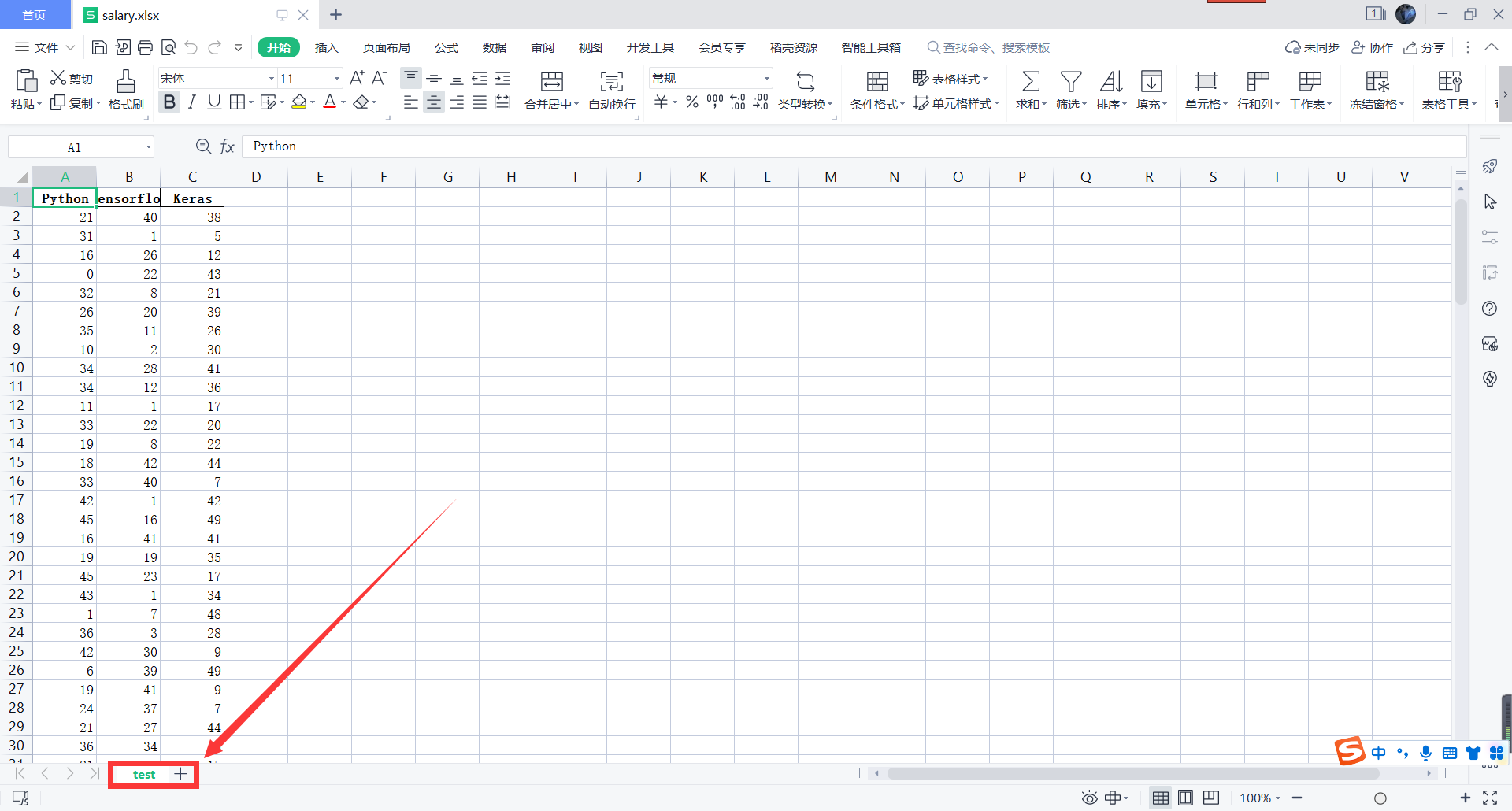
发现并没有实现我们预期的结果,下面来正式介绍一下如何操作:
with pd.ExcelWriter('./data.xlsx') as writer:
df1.to_excel(writer,sheet_name = 'salary', index = False)
df2.to_excel(writer,sheet_name = 'score', index = False)
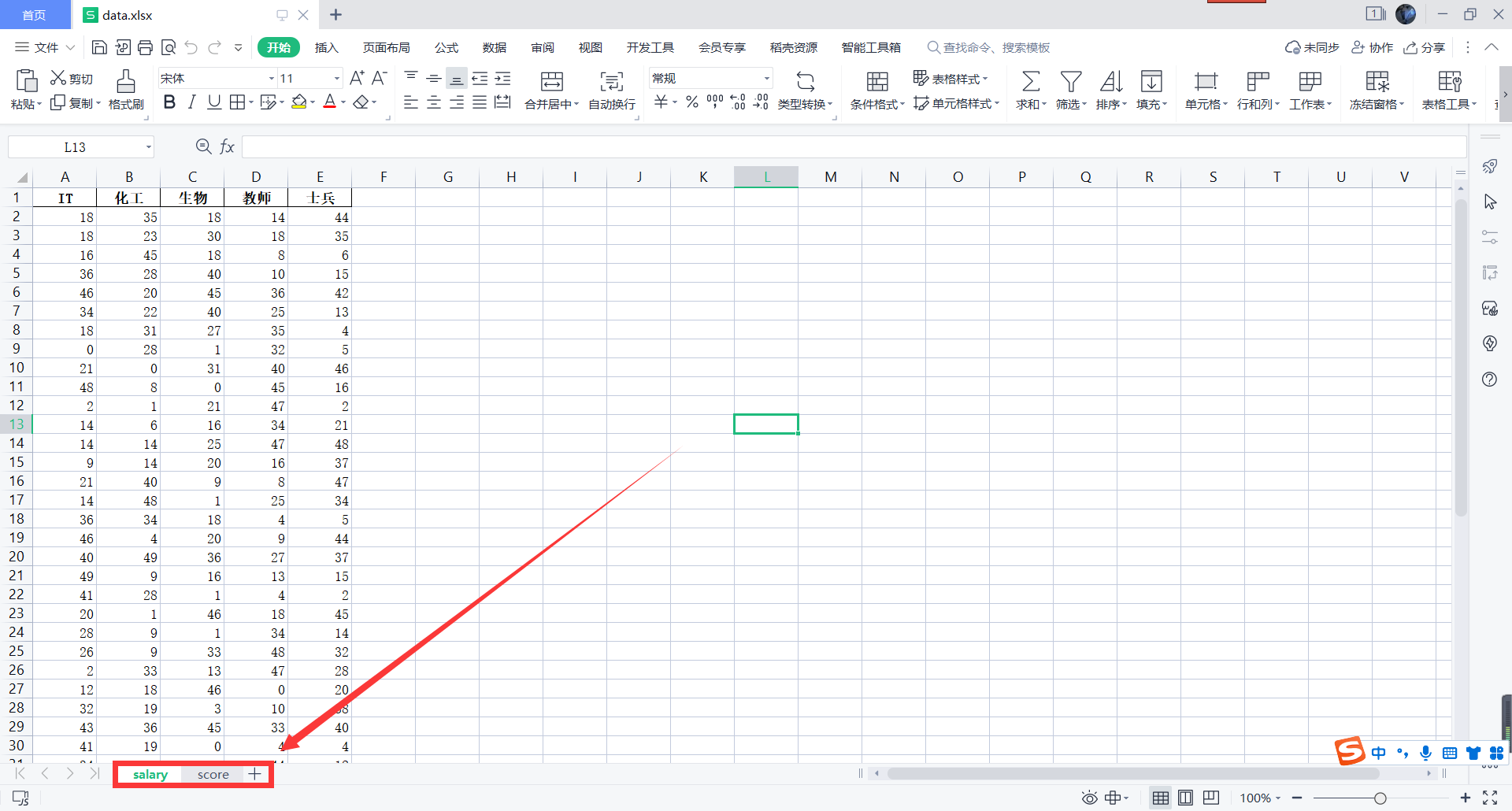
这样就实现了我们的存入操作,接下来还是读取的操作:
读取 salary:
pd.read_excel('./data.xlsx',
sheet_name='salary')
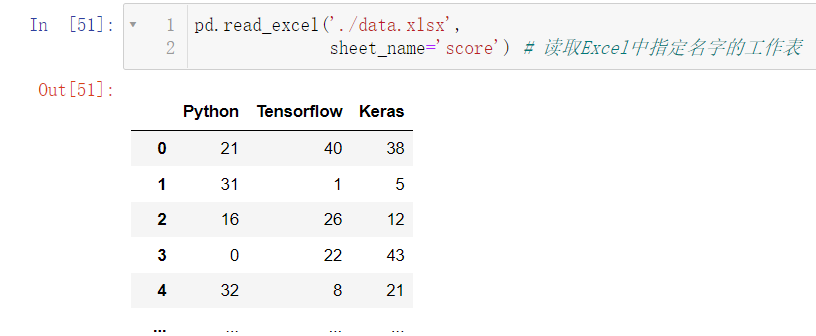
读取 score:
pd.read_excel('./data.xlsx',
sheet_name='score')
5.数据选择
5.1 字段数据
5.1.1 列的获取
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0, 150, size = (1000, 3)),
columns = ['Python', 'English', 'Math'])
display(df)
display(df['Python'])
display(df.Python)
display(df[['Python', 'Math']])

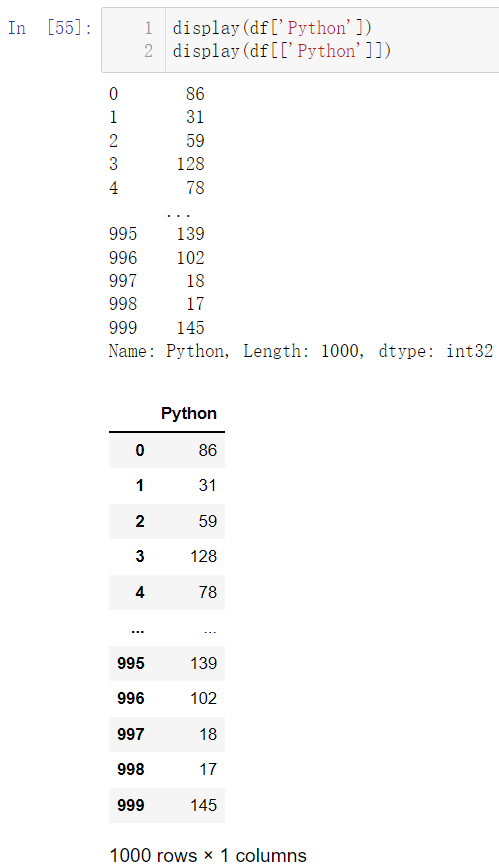
再来对比两个写法:同样是获得一列的数据,不同的写法对应的运行表现不同:
display(df['Python'])
display(df[['Python']])
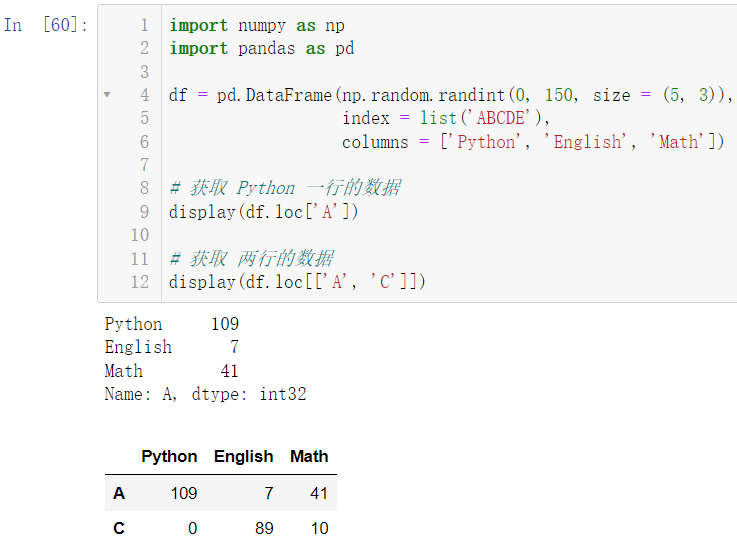
5.1.2 行的获取
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0, 150, size = (5, 3)),
index = list('ABCDE'),
columns = ['Python', 'English', 'Math'])
display(df.loc['A'])
display(df.loc[['A', 'C']])
还有一种获取方法:
display(df.iloc[0])
display(df.iloc[[0, 2]])

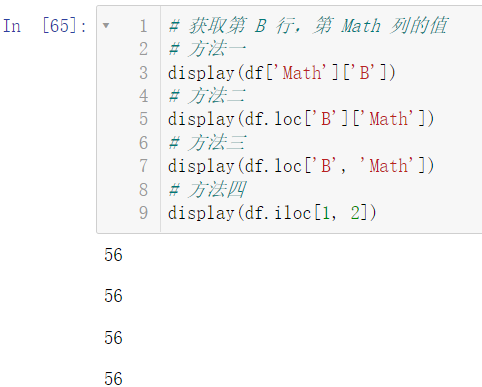
5.1.3 数值的获取
我们介绍了获取行和获取列,现在我们来介绍获取固定行固定列的元素:
display(df['Math']['B'])
display(df.loc['B']['Math'])
display(df.loc['B', 'Math'])
display(df.iloc[1, 2])
5.1.4 切片操作
切片的概念和表达都和 Python 的传统切片无差别,和 NumPy 也特别相似:
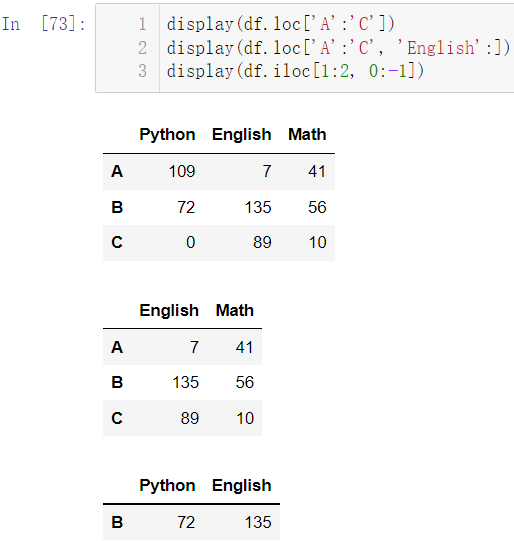
display(df.loc['A':'C'])
display(df.loc['A':'C', 'English':])
display(df.iloc[1:2, 0:-1])
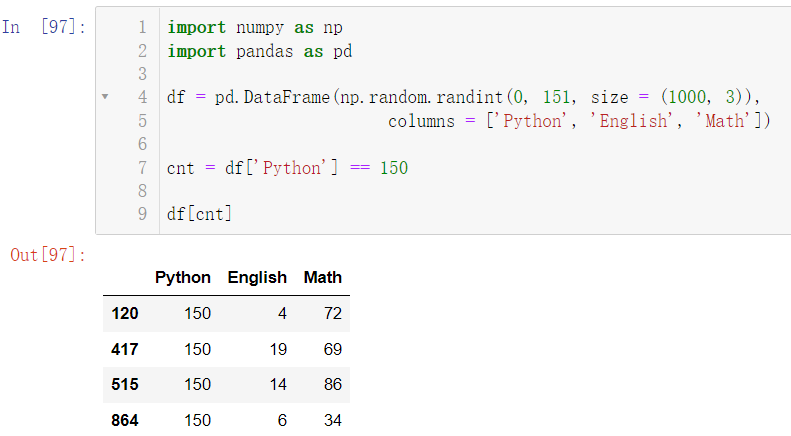
5.2 boolean索引
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0, 151, size = (1000, 3)),
columns = ['Python', 'English', 'Math'])
cnt = df['Python'] == 150
df[cnt]
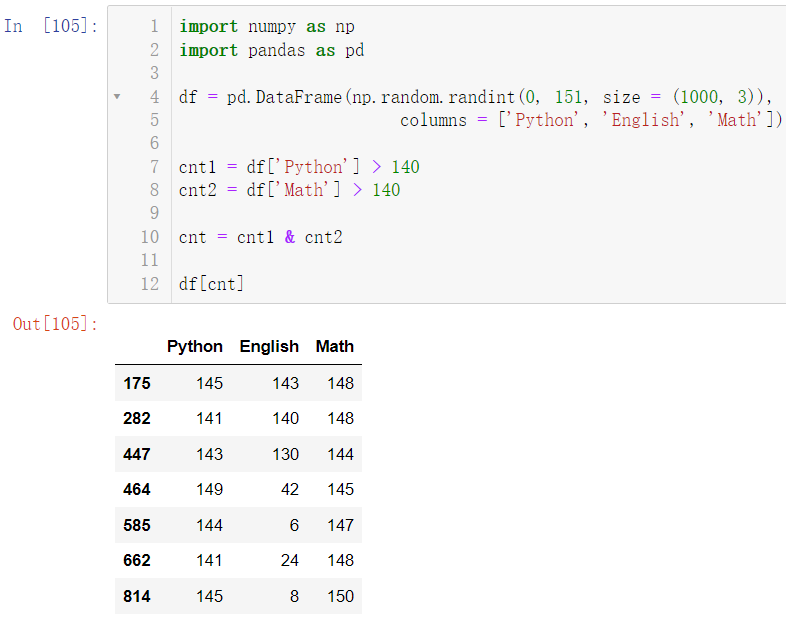
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0, 151, size = (1000, 3)),
columns = ['Python', 'English', 'Math'])
cnt1 = df['Python'] > 140
cnt2 = df['Math'] > 140
cnt = cnt1 & cnt2
df[cnt]
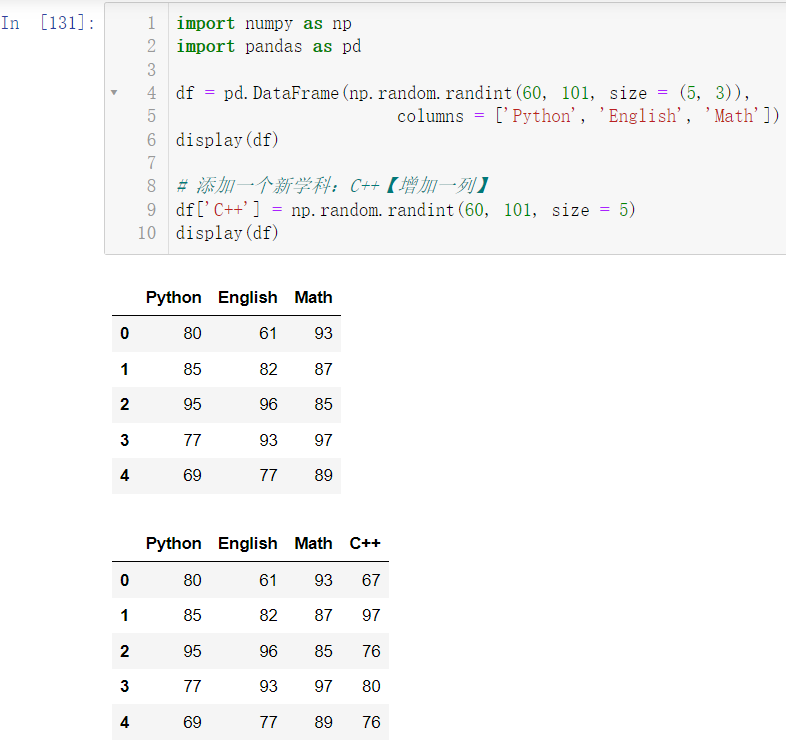
5.3 赋值操作
5.3.1 新增一列
🚩我们在原有的三学科基础上增加一门 C++ 的成绩
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(60, 101, size = (5, 3)),
columns = ['Python', 'English', 'Math'])
display(df)
df['C++'] = np.random.randint(60, 101, size = 5)
display(df)
5.3.2 整列的变化
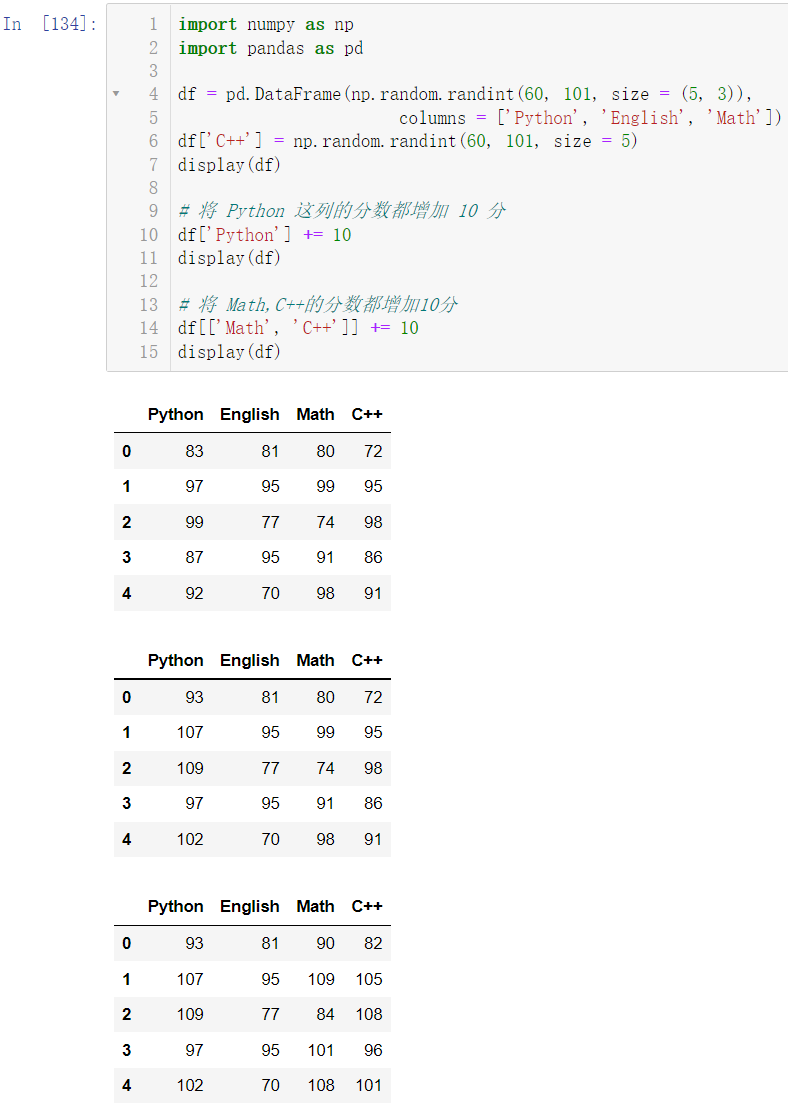
🚩我们让 Python 这门课的所有学生的分数都增加 10 分,再将 Math,C++的分数都增加10分
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(60, 101, size = (5, 3)),
columns = ['Python', 'English', 'Math'])
df['C++'] = np.random.randint(60, 101, size = 5)
display(df)
df['Python'] += 10
display(df)
df[['Math', 'C++']] += 10
display(df)
5.3.3 列上元素的变化
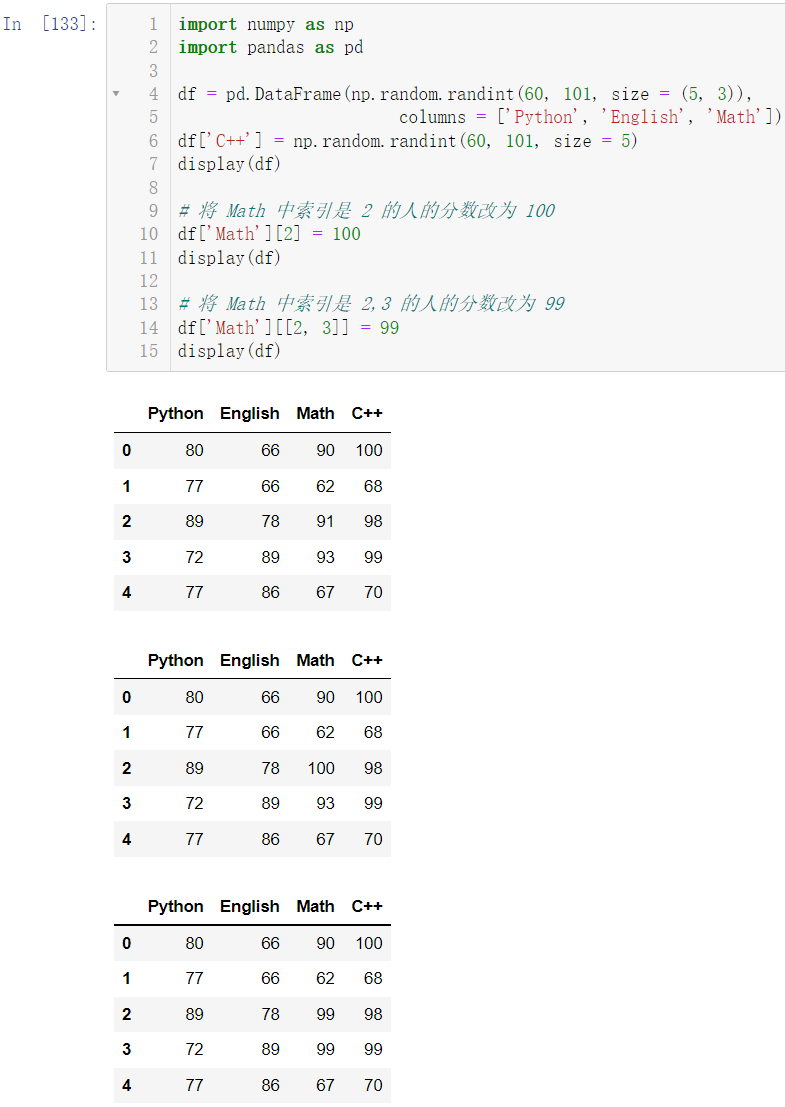
🚩我们将 Math 中索引是 2 的人的分数改为 100,再将 Math 中索引是 2,3 的人的分数改为 99
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(60, 101, size = (5, 3)),
columns = ['Python', 'English', 'Math'])
df['C++'] = np.random.randint(60, 101, size = 5)
display(df)
df['Math'][2] = 100
display(df)
df['Math'][[2, 3]] = 99
display(df)
5.3.4 批量操作多个数据
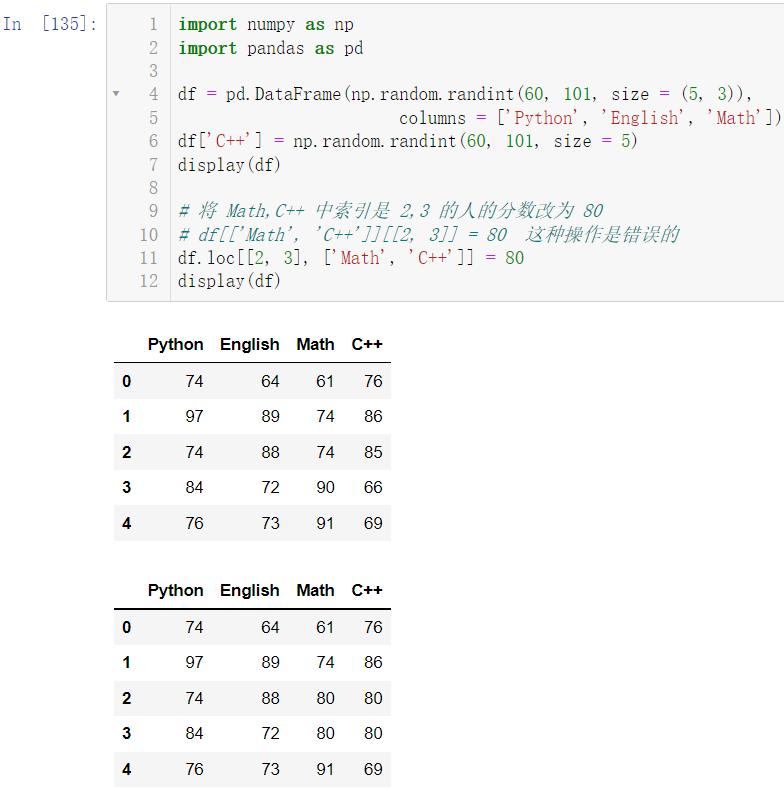
🚩将 Math,C++ 中索引是 2,3 的人的分数改为 80
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(60, 101, size = (5, 3)),
columns = ['Python', 'English', 'Math'])
df['C++'] = np.random.randint(60, 101, size = 5)
display(df)
df.loc[[2, 3], ['Math', 'C++']] = 80
display(df)
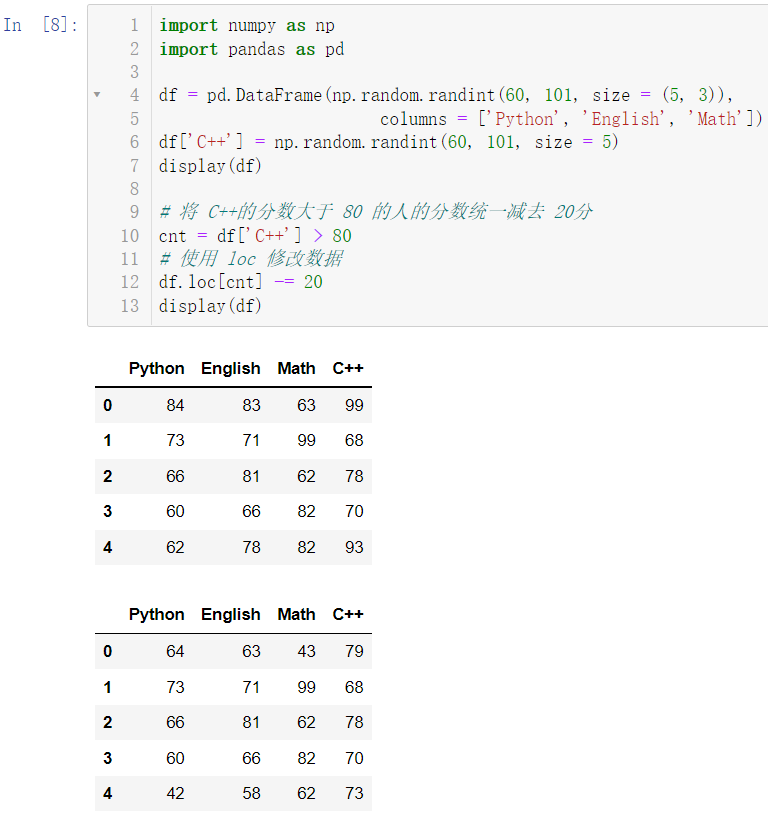
在条件的情况下修改多个值,必须使用 loc:
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(60, 101, size = (5, 3)),
columns = ['Python', 'English', 'Math'])
df['C++'] = np.random.randint(60, 101, size = 5)
display(df)
cnt = df['C++'] > 80
df.loc[cnt] -= 20
display(df)
6.训练场
6.1 创建1000条语、数、外、Python的考试成绩DataFrame,范围是0~150包含150,分别将数据保存到csv文件以及Excel文件,保存时不保存行索引。
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0, 151, size = (1000, 4)),
columns = ['语', '数', '英', 'Python'])
df.to_csv('./score.csv', index = False)
df.to_excel('./score.xlsx', index = False)
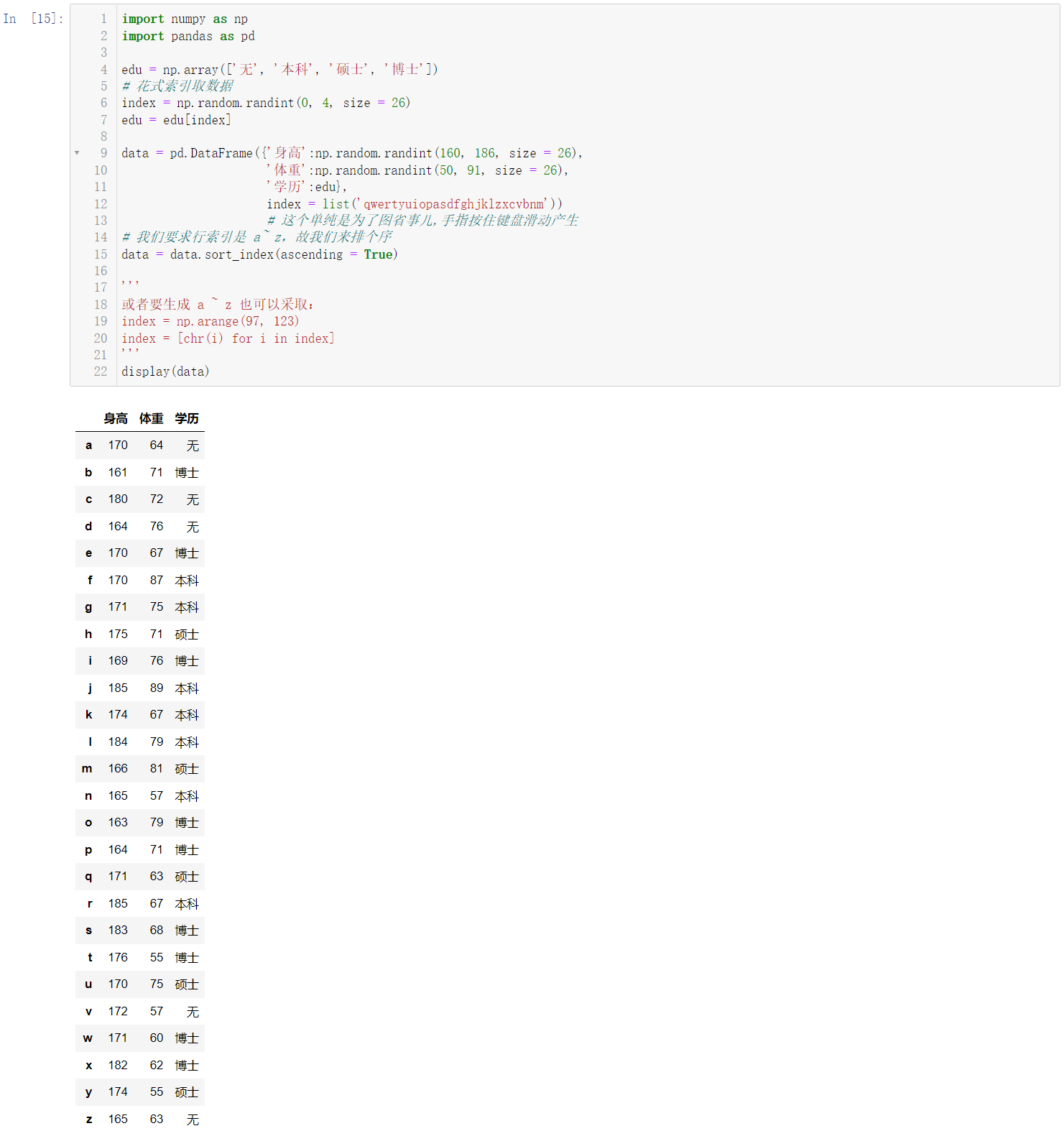
6.2 创建使用字典创建DataFrame,行索引是a~z,列索引是:身高(160-185)、体重(50-90)、学历(无、本科、硕士、博士)。身高、体重数据使用NumPy随机数生成,学历数据先创建数组 edu =np.array([‘无’,’本科’,’硕士’,’博士’]),然后使用花式索引从四个数据中选择26个数据。
import numpy as np
import pandas as pd
edu = np.array(['无', '本科', '硕士', '博士'])
index = np.random.randint(0, 4, size = 26)
edu = edu[index]
data = pd.DataFrame({'身高':np.random.randint(160, 186, size = 26),
'体重':np.random.randint(50, 91, size = 26),
'学历':edu},
index = list('qwertyuiopasdfghjklzxcvbnm'))
data = data.sort_index(ascending = True)
'''
或者要生成 a ~ z 也可以采取:
index = np.arange(97, 123)
index = [chr(i) for i in index]
'''
display(data)
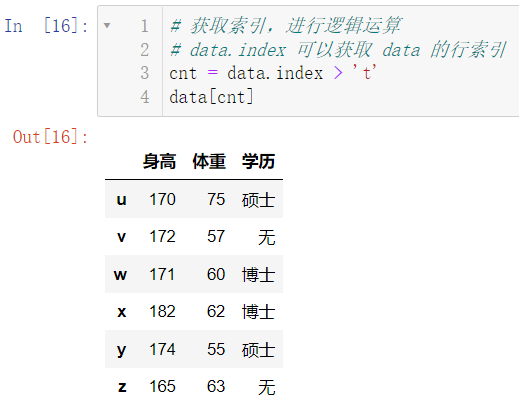
6.3 使用题目二中的数据,进行数据筛选。
6.3.1 筛选索引大于 ‘t’ 的所有数据
cnt = data.index > 't'
data[cnt]
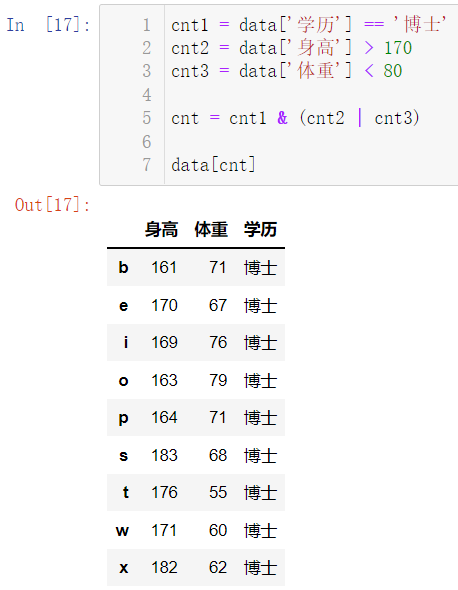
6.3.2 筛选学历是博士,身高大于170或者体重小于80的学生
cnt1 = data['学历'] == '博士'
cnt2 = data['身高'] > 170
cnt3 = data['体重'] < 80
cnt = cnt1 & (cnt2 | cnt3)
data[cnt]
6.4 使用题目二中数据,开始学生们开始减肥
6.4.1 本科生减肥,减掉的体重统一是10
cnt = data['学历'] == '本科'
display(data[cnt])
data.loc[cnt,'体重'] -= 10
display(data[cnt])

6.4.2 博士生减肥,减掉体重范围是5~10
cnt = data['学历'] == '博士'
display(data[cnt])
'''
data[cnt].shape 运行结果为(8, 3)
data[cnt].shape[0] 运行结果为 8
'''
data.loc[cnt, '体重'] -= np.random.randint(5, 11,
size = data[cnt].shape[0])
display(data[cnt])

二、pandas高级
1.数据集成
🚩pandas 提供了多种将 Series、DataFrame 对象组合在一起的功能
1.1 concat数据串联
🚩使用 concat 可以把数据进行合并,分别用 axis = 0 代表行合并, axis = 1 代表列合并
import pandas as pd
import numpy as np
df1 = pd.DataFrame(data = np.random.randint(0, 150, size = (10, 3)),
index = list('ABCDEFGHIJ'),
columns = ['Python', 'Tensorflow', 'Keras'])
df2 = pd.DataFrame(data = np.random.randint(0, 150, size = (10,3)),
index = list('KLMNOPQRST'),
columns = ['Python', 'Tensorflow', 'Keras'])
df3 = pd.DataFrame(data = np.random.randint(0, 150, size = (10,2)),
index = list('ABCDEFGHIJ'),
columns = ['PyTorch', 'Paddle'])
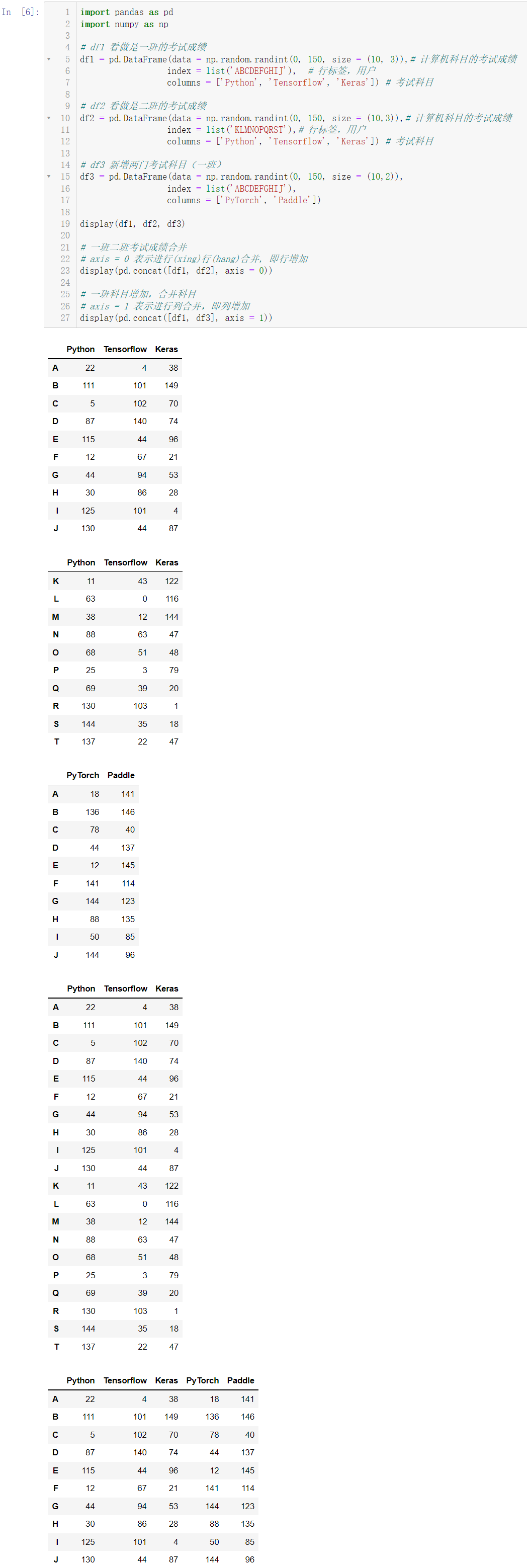
display(df1, df2, df3)
display(pd.concat([df1, df2], axis = 0))
display(pd.concat([df1, df3], axis = 1))
1.2 插入
🚩使用 insert 可以在任意位置进行插入
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 151, size = (10, 3)),
index = list('ABCDEFGHIJ'),
columns = ['Python', 'Keras', 'Tensorflow'])
display(df)
df.insert(loc = 2, column = 'Math', value = 150)
'''
获取列索引
df.columns 运行结果:Index(['Python', 'Pytorch', 'Math', 'Keras', 'Tensorflow'],
dtype='object')
把列索引转换为列表
list(df.columns) 运行结果:['Python', 'Pytorch', 'Math', 'Keras', 'Tensorflow']
调用index函数,获取列表中特定字段的位置
list(df.columns).index('Python') 运行结果:0
'''
index = list(df.columns).index('Python') + 1
df.insert(loc = index, column = 'English', value = np.random.randint(0, 151, size = 10))
display(df)

1.3 Join SQL风格合并
🚩数据集的合并(merge)或连接(join)运算是通过一个或者多个键将数据链接起来的。这些运算是关系型数据库的核心操作。pandas的merge函数是数据集进行join运算的主要切入点。
先来创建数据:
import pandas as pd
import numpy as np
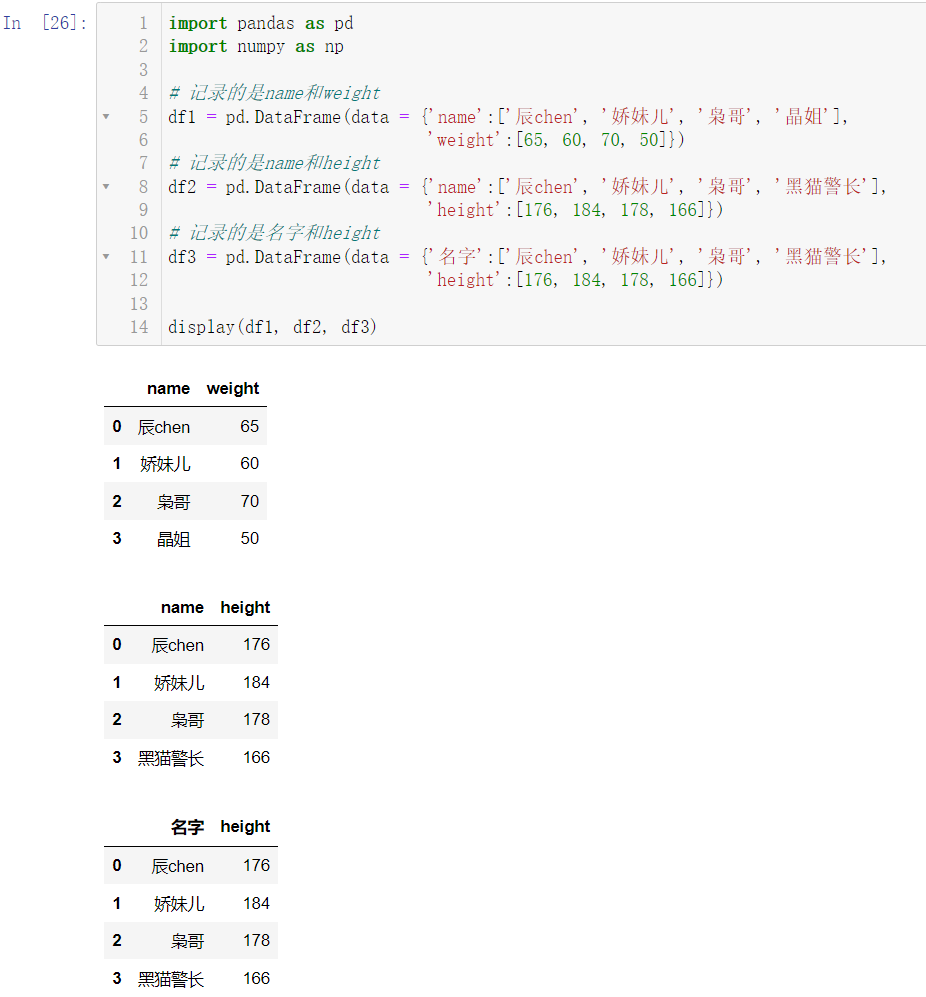
df1 = pd.DataFrame(data = {'name':['辰chen', '娇妹儿', '枭哥', '晶姐'],
'weight':[65, 60, 70, 50]})
df2 = pd.DataFrame(data = {'name':['辰chen', '娇妹儿', '枭哥', '黑猫警长'],
'height':[176, 184, 178, 166]})
df3 = pd.DataFrame(data = {'名字':['辰chen', '娇妹儿', '枭哥', '黑猫警长'],
'height':[176, 184, 178, 166]})
display(df1, df2, df3)
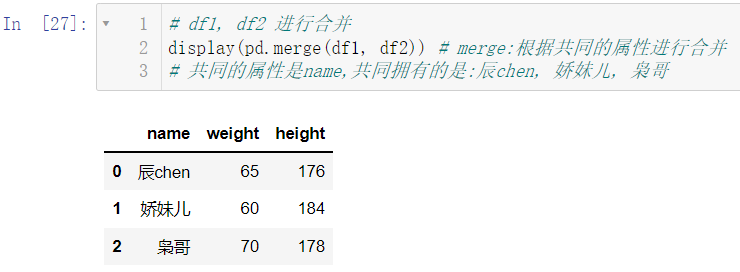
利用 merge 对数据进行合并:
display(pd.merge(df1, df2))
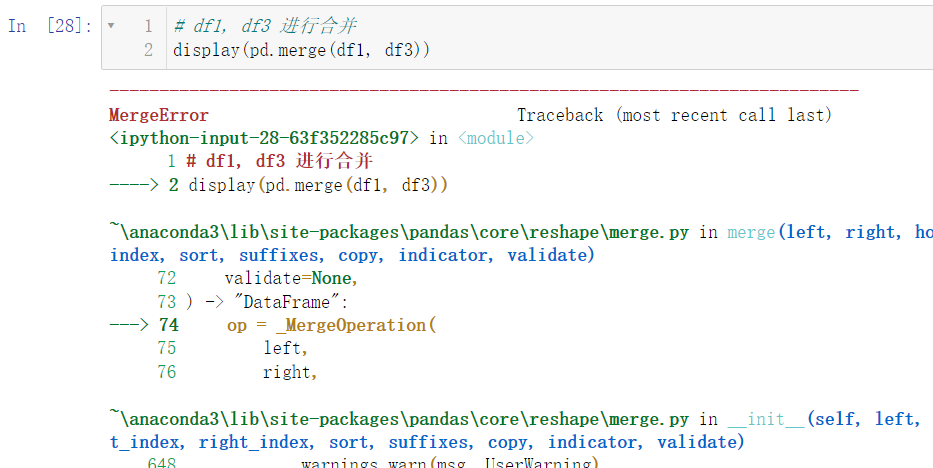
df1 和 df3 是不能直接进行合并的:
display(pd.merge(df1, df3))
当然啦,我们 pandas 是十分强大滴,按照如下代码可以进行合并:
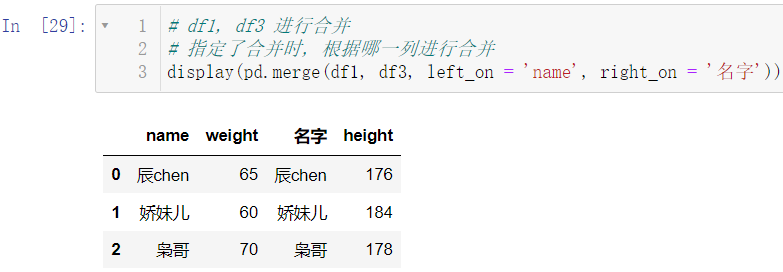
display(pd.merge(df1, df3, left_on = 'name', right_on = '名字'))
创建 10 名同学,计算每个人的平均分,并合并:
创建数据:
df4 = pd.DataFrame(data = np.random.randint(0, 151, size = (10, 3)),
index = list('ABCDEFHIJK'),
columns = ['Python', 'Keras', 'Tensorflow'])
display(df4)

计算平均分:
df4.mean()

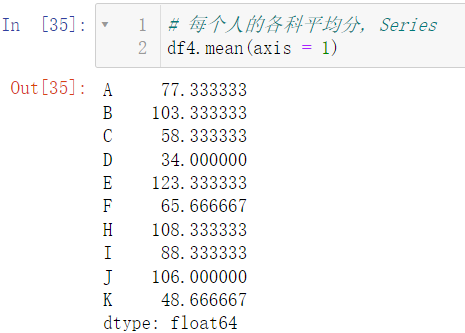
我们要计算的不是列的平均分,而是每位同学的平均分:
axis = 1:
df4.mean(axis = 1)
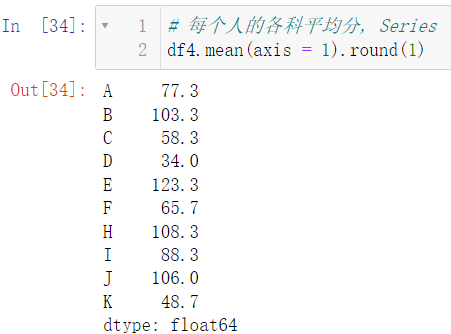
数据看起来不舒服,我们可以使用之前讲过的 round(1) 去保留一位小数:
df4.mean(axis = 1).round(1)
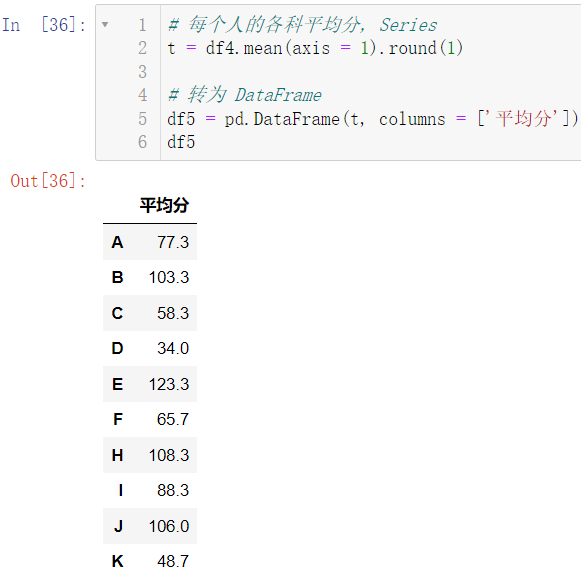
看着是不是不是很舒服?我们可以把它变成 DataFrame
t = df4.mean(axis = 1).round(1)
df5 = pd.DataFrame(t, columns = ['平均分'])
df5
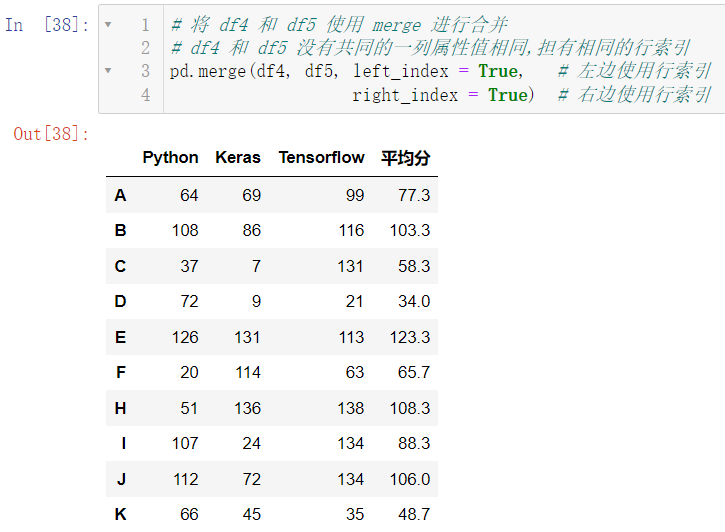
将 df4 和 df5 使用 merge 进行合并
pd.merge(df4, df5, left_index = True,
right_index = True)
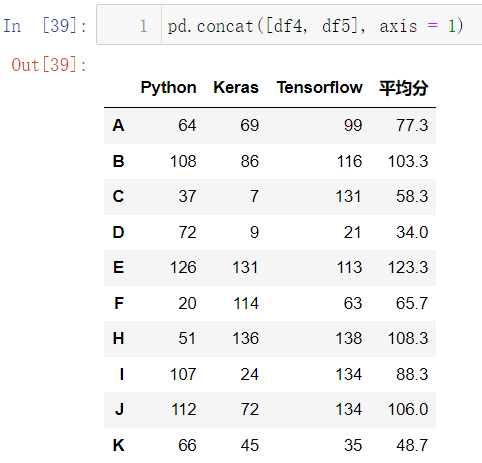
上述代码同样可以用 concat 和 insert 实现:
pd.concat([df4, df5], axis = 1)
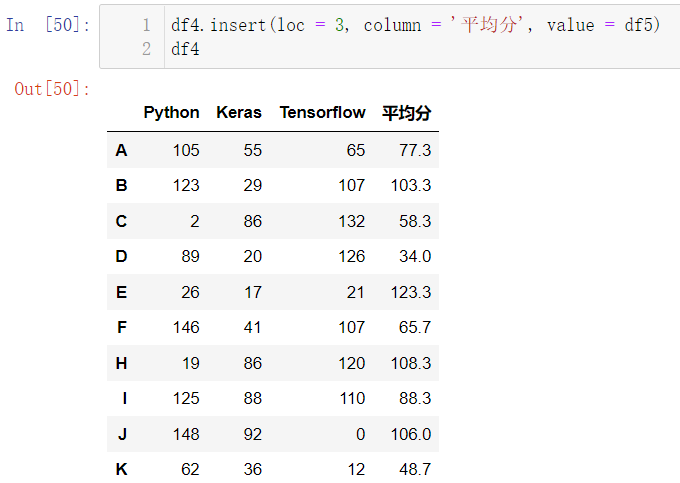
df4.insert(loc = 3, column = '平均分', value = df5)
df4
2.数据清洗
🚩所谓数据清洗,其实就是把重复的数据,或者是空数据,异常数据进行一些操作,比如替换,填充,删除等操作,关于异常值的定义需要根据实际情况去自行规定。
2.1 重复数据过滤
import numpy as np
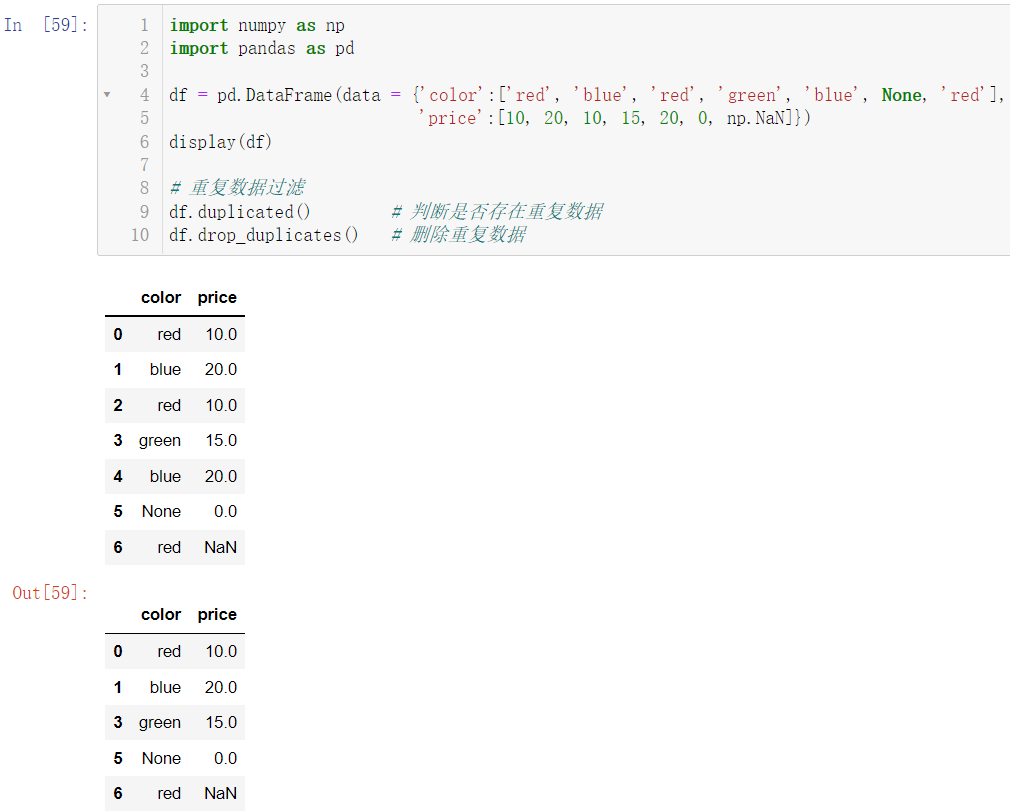
import pandas as pd
df = pd.DataFrame(data = {'color':['red', 'blue', 'red', 'green', 'blue', None, 'red'],
'price':[10, 20, 10, 15, 20, 0, np.NaN]})
display(df)
df.duplicated()
df.drop_duplicates()
2.2 空数据过滤
None 和 NaN 都表示空数据,计算时没有区别
None 是 Python 的数据类型
NaN 是 Numpy 的数据类型
import numpy as np
import pandas as pd
df = pd.DataFrame(data = {'color':['red', 'blue', 'red', 'green', 'blue', None, 'red'],
'price':[10, 20, 10, 15, 20, 0, np.NaN]})
display(df)
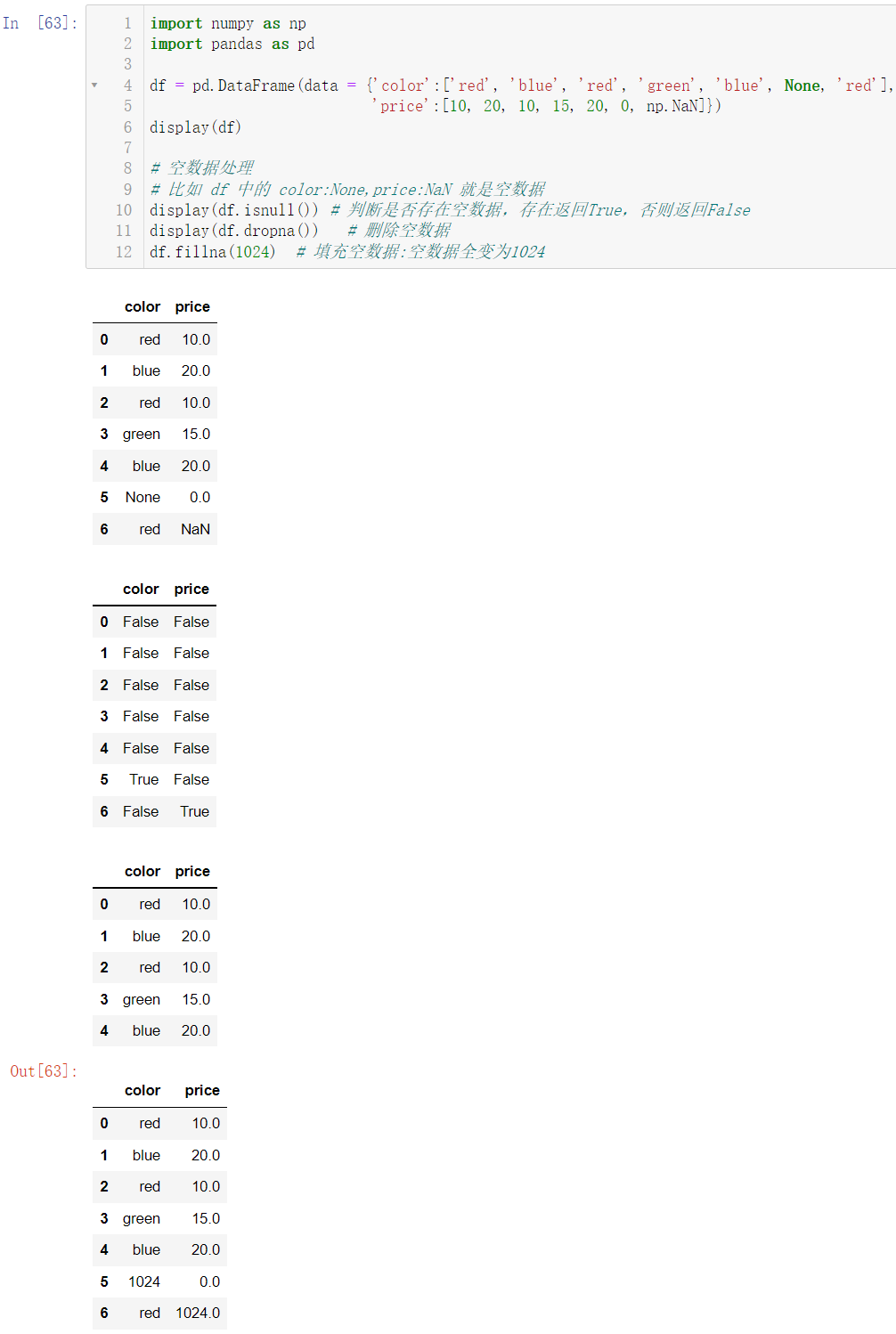
display(df.isnull())
display(df.dropna())
df.fillna(1024)
2.3 指定行或者列进行删除
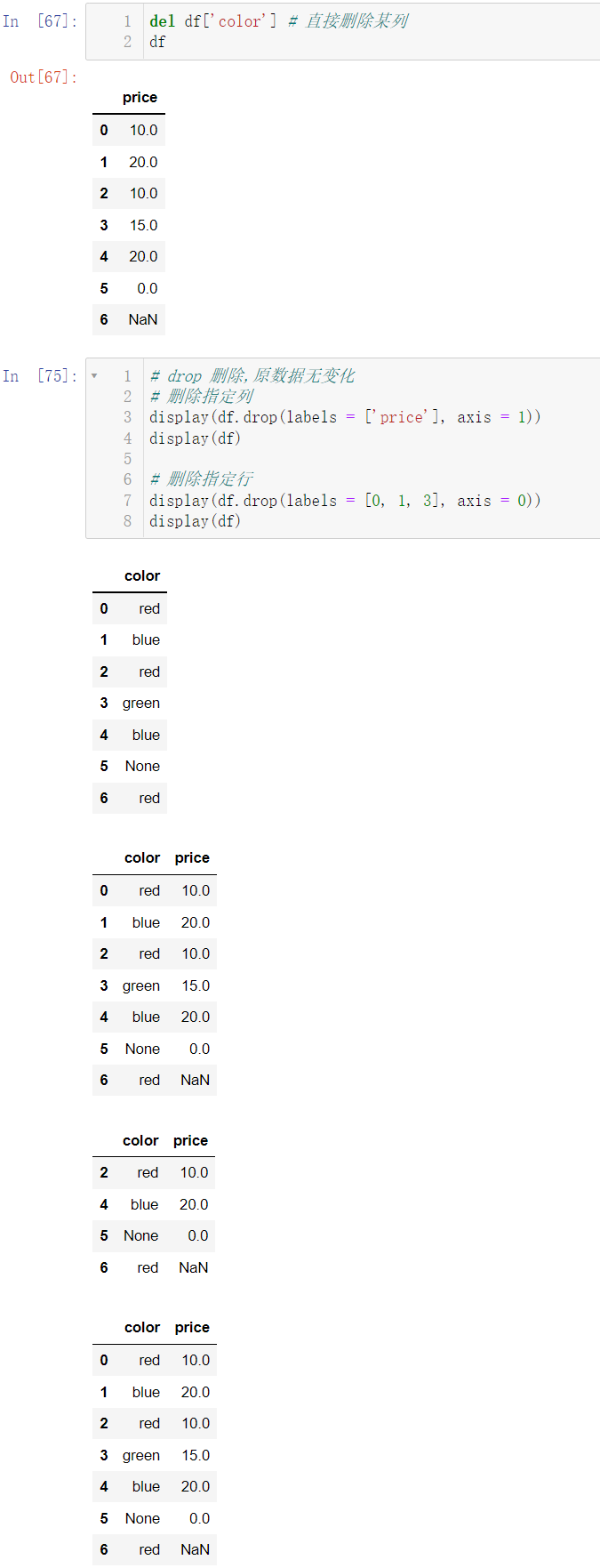
del df['color']
df

display(df.drop(labels = ['price'], axis = 1))
display(df)
display(df.drop(labels = [0, 1, 3], axis = 0))
display(df)
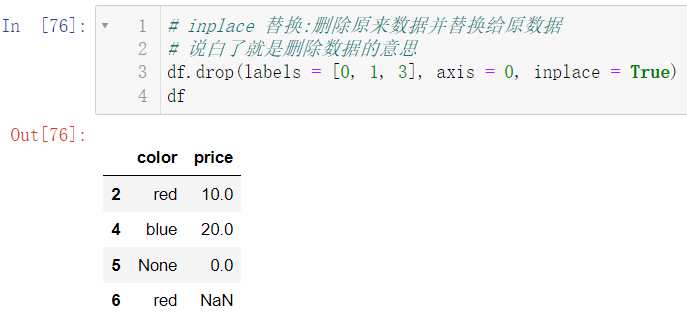
当然,我们也可以设置使得在原数据上直接进行修改:
df.drop(labels = [0, 1, 3], axis = 0, inplace = True)
df
2.4 异常值
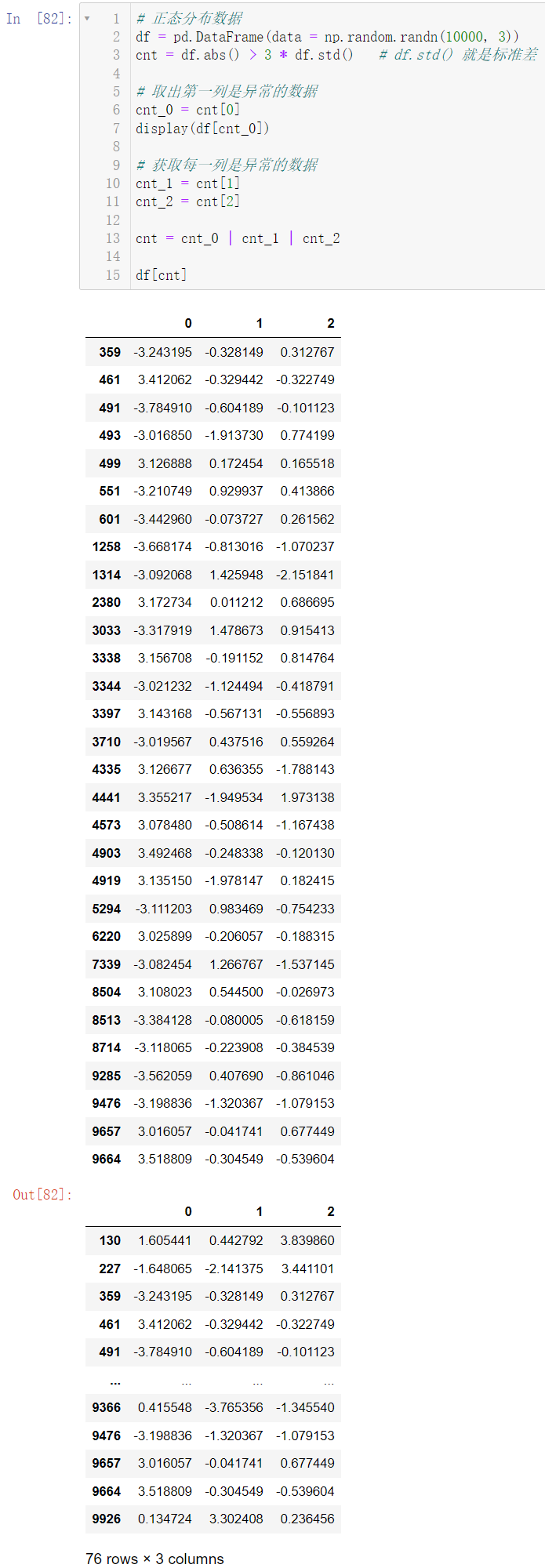
🚩对于一个正态分布的数据,我们认定 > 3 σ >3\sigma >3 σ 就是异常值,σ \sigma σ表示标准差
df = pd.DataFrame(data = np.random.randn(10000, 3))
cnt = df.abs() > 3 * df.std()
cnt_0 = cnt[0]
display(df[cnt_0])
cnt_1 = cnt[1]
cnt_2 = cnt[2]
cnt = cnt_0 | cnt_1 | cnt_2
df[cnt]
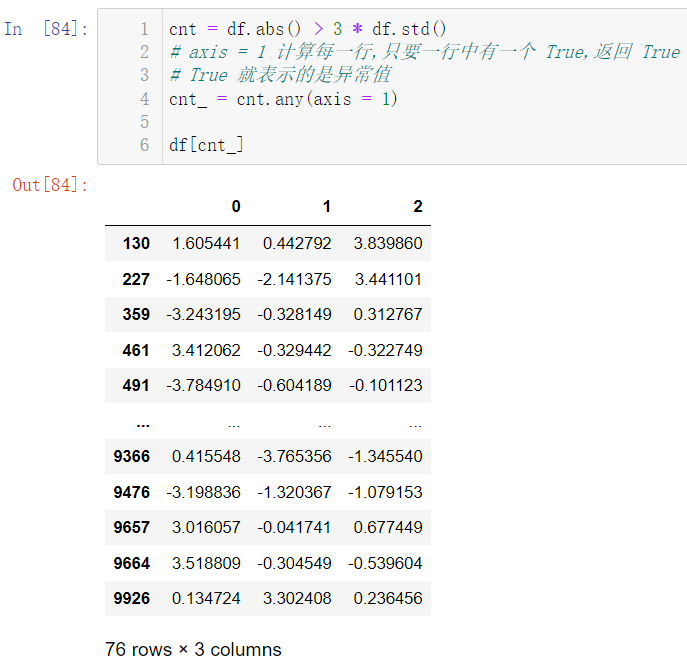
还有一种比较简单的方式取出异常值:
cnt = df.abs() > 3 * df.std()
cnt_ = cnt.any(axis = 1)
df[cnt_]
3.数据转换
3.1 轴和元素替换
3.1.1 轴的替换
🚩替换轴使用的是函数 rename():
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 10, size = (10, 3)),
index = list('ABCDEFHIJK'),
columns = ['Python', 'Tensorflow', 'Keras'])
display(df)
df.rename(index = {'A':'AA', 'B':'BB'}, columns = {'Python':'AI'})
display(df)

3.1.2 元素的替换
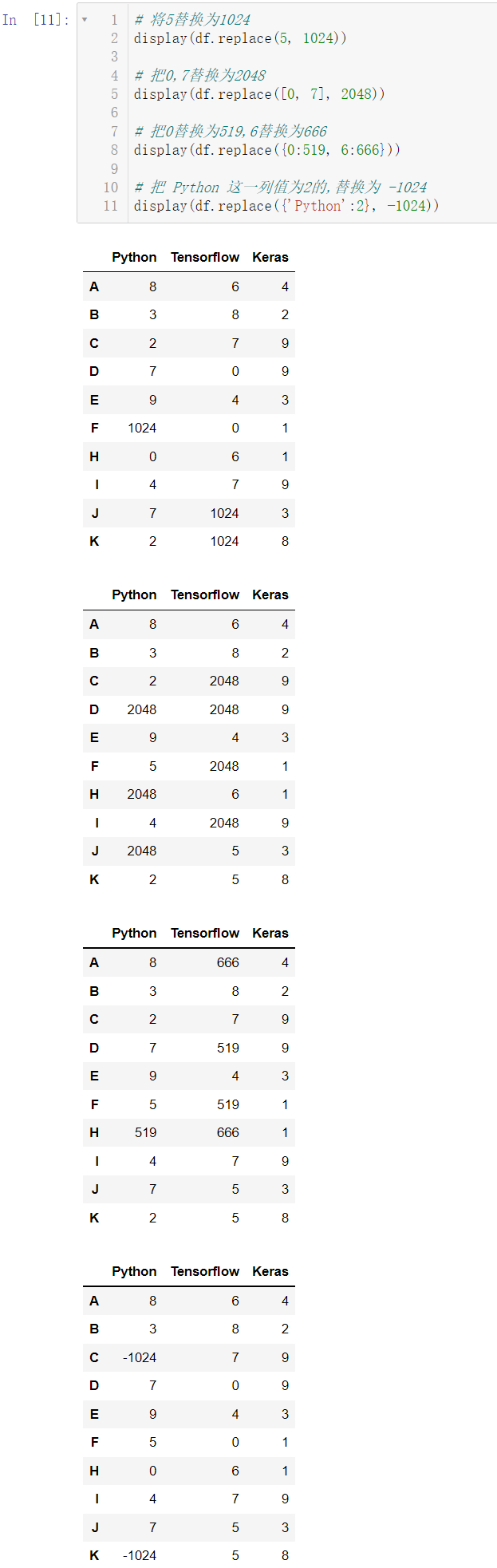
🚩元素的替换使用 replace() 函数:
display(df.replace(5, 1024))
display(df.replace([0, 7], 2048))
display(df.replace({0:519, 6:666}))
display(df.replace({'Python':2}, -1024))
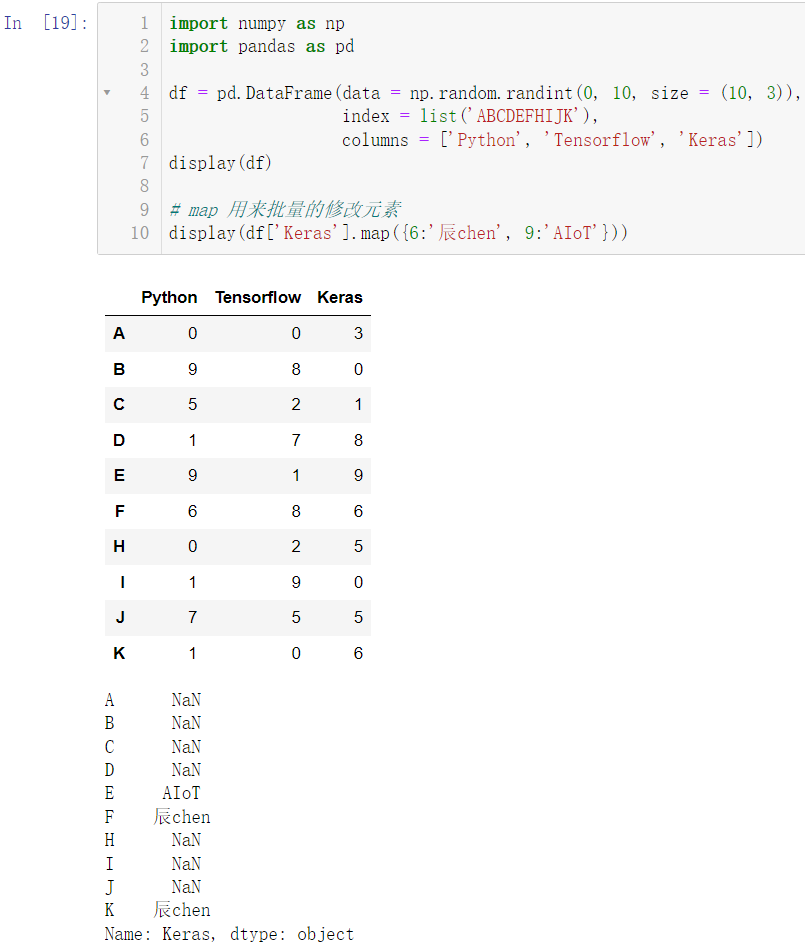
3.2 map Series元素改变
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 10, size = (10, 3)),
index = list('ABCDEFHIJK'),
columns = ['Python', 'Tensorflow', 'Keras'])
display(df)
display(df['Keras'].map({6:'辰chen', 9:'AIoT'}))
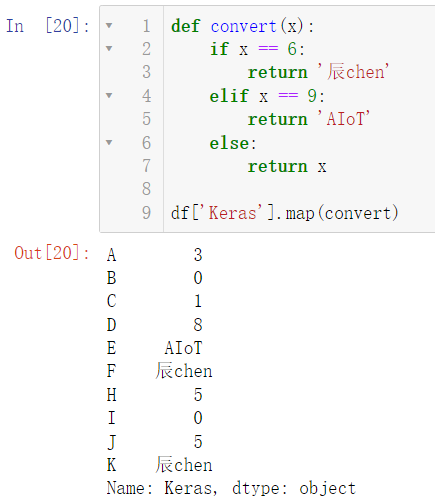
从运行结果我们可以看出,使用 map 对数据进行替换后,未规定替换的数据会变成空数据。
如果我们想要保留原数据,可以写自定义函数:
def convert(x):
if x == 6:
return '辰chen'
elif x == 9:
return 'AIoT'
else:
return x
df['Keras'].map(convert)
当然,我们在 Python 中还学习过 lambda 表达式,在这里同样可以使用:
df['Python'].map(lambda x : True if x >= 5 else False)
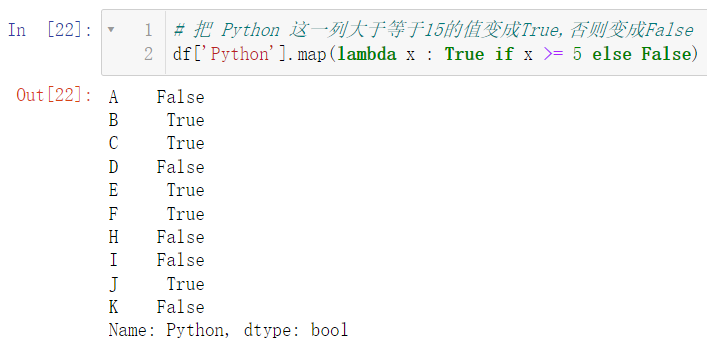
3.3 apply元素改变,既支持 Series也支持 DataFrame
3.3.1 apply简单介绍
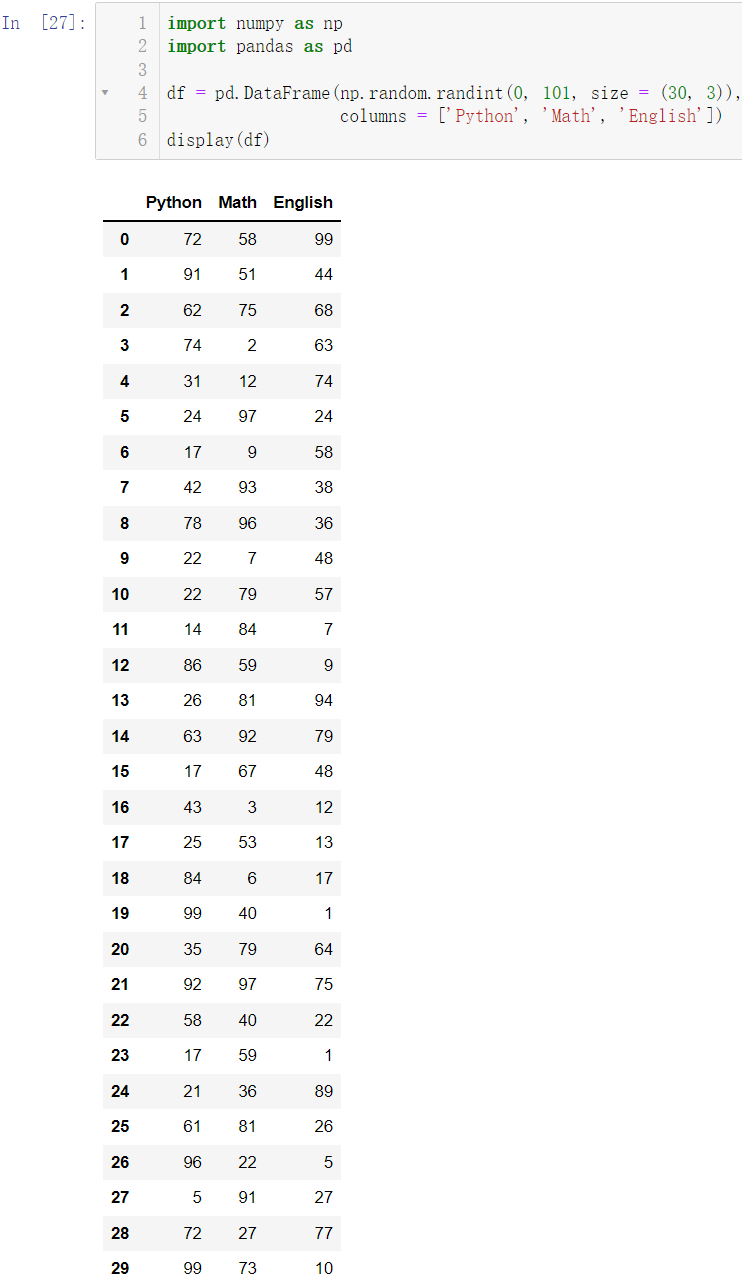
创造数据:
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0, 101, size = (30, 3)),
columns = ['Python', 'Math', 'English'])
display(df)
apply 对数据进行修改:
def convert(x):
if x < 60:
return '不及格'
elif x < 80:
return '中等'
else:
return '优秀'
df['Python'].apply(convert)

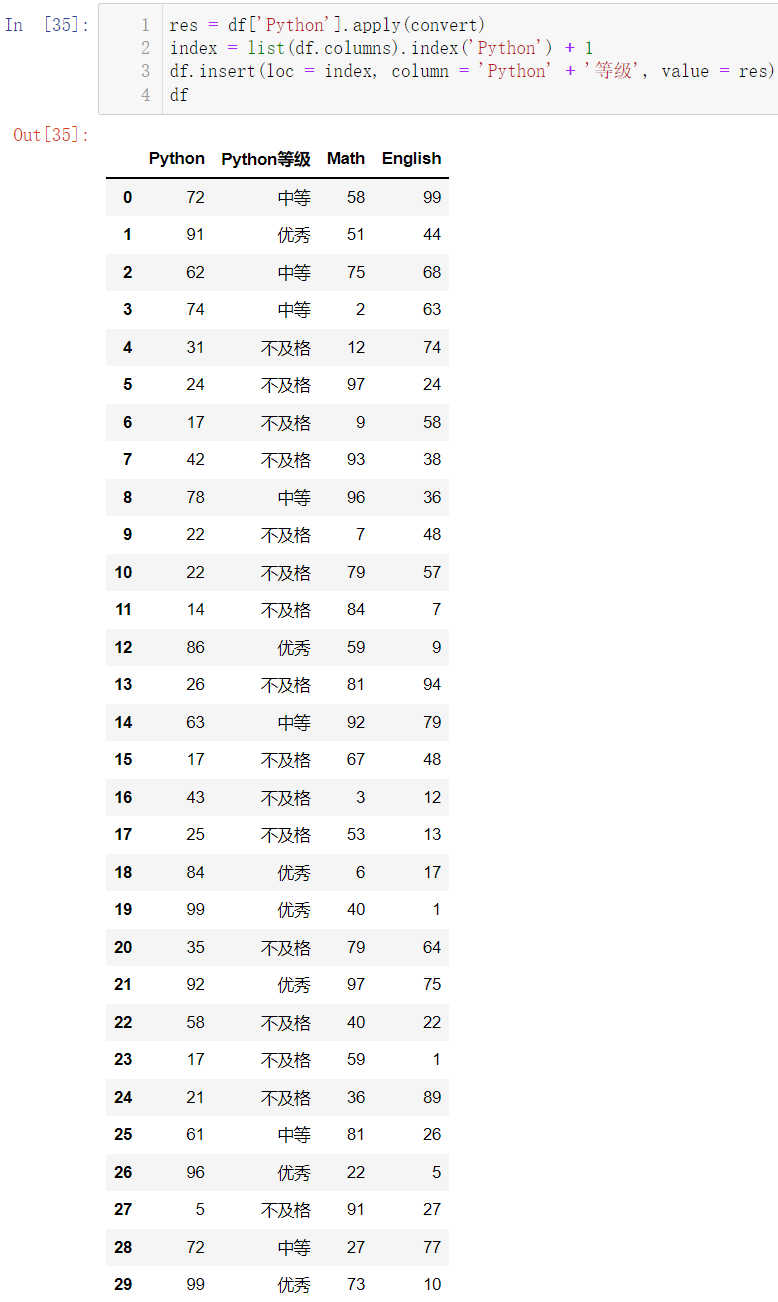
我们现在来把这两个表格进行合并:
res = df['Python'].apply(convert)
index = list(df.columns).index('Python') + 1
df.insert(loc = index, column = 'Python' + '等级', value = res)
df
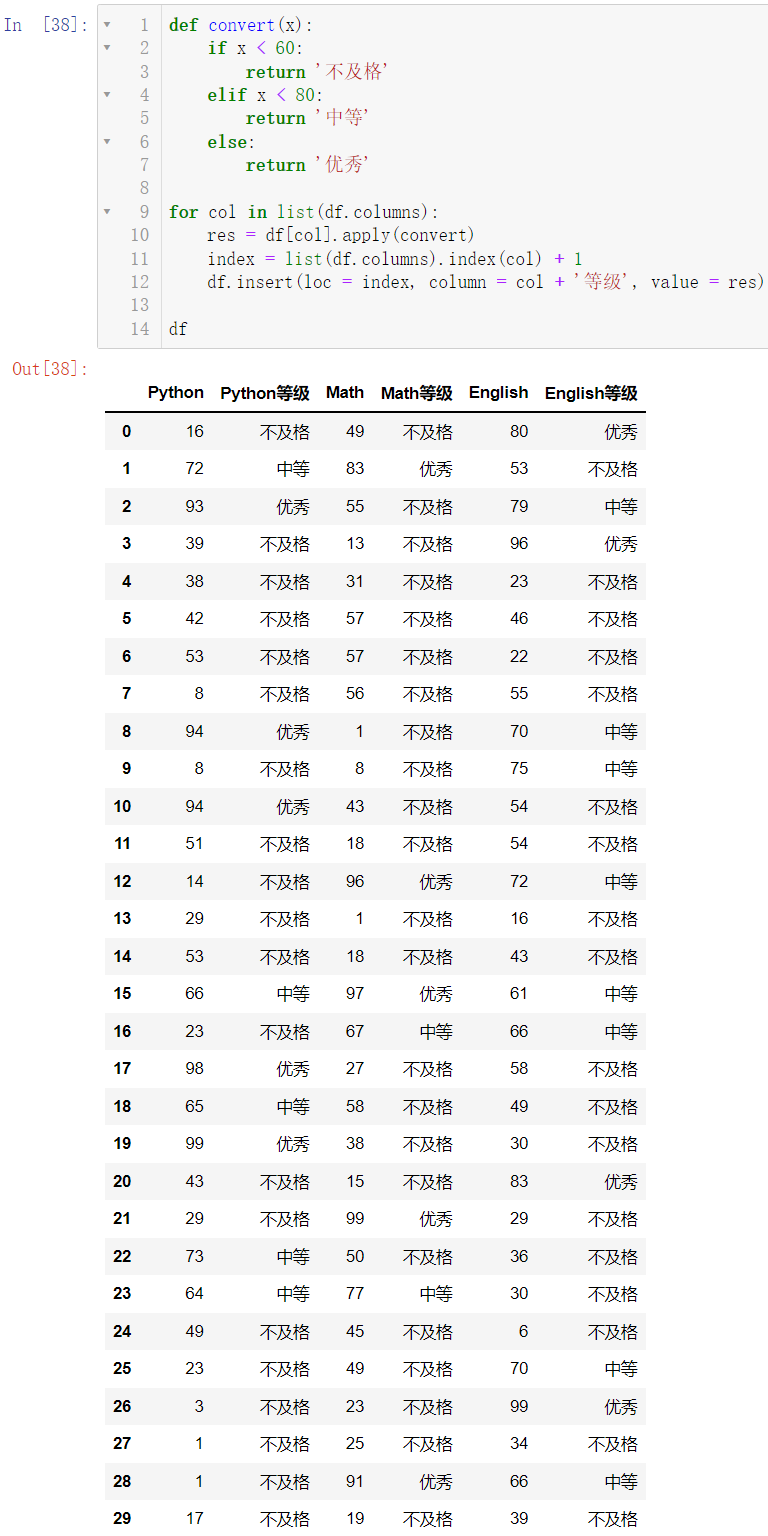
如果我们要生成所有学科的等级,我们可以利用 for 循环:
def convert(x):
if x < 60:
return '不及格'
elif x < 80:
return '中等'
else:
return '优秀'
for col in list(df.columns):
res = df[col].apply(convert)
index = list(df.columns).index(col) + 1
df.insert(loc = index, column = col + '等级', value = res)
df
3.3.2 apply应用
apply 可以对一列数据进行修改:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 10, size = (10, 3)),
index = list('ABCDEFHIJK'),
columns = ['Python', 'Tensorflow', 'Keras'])
display(df)
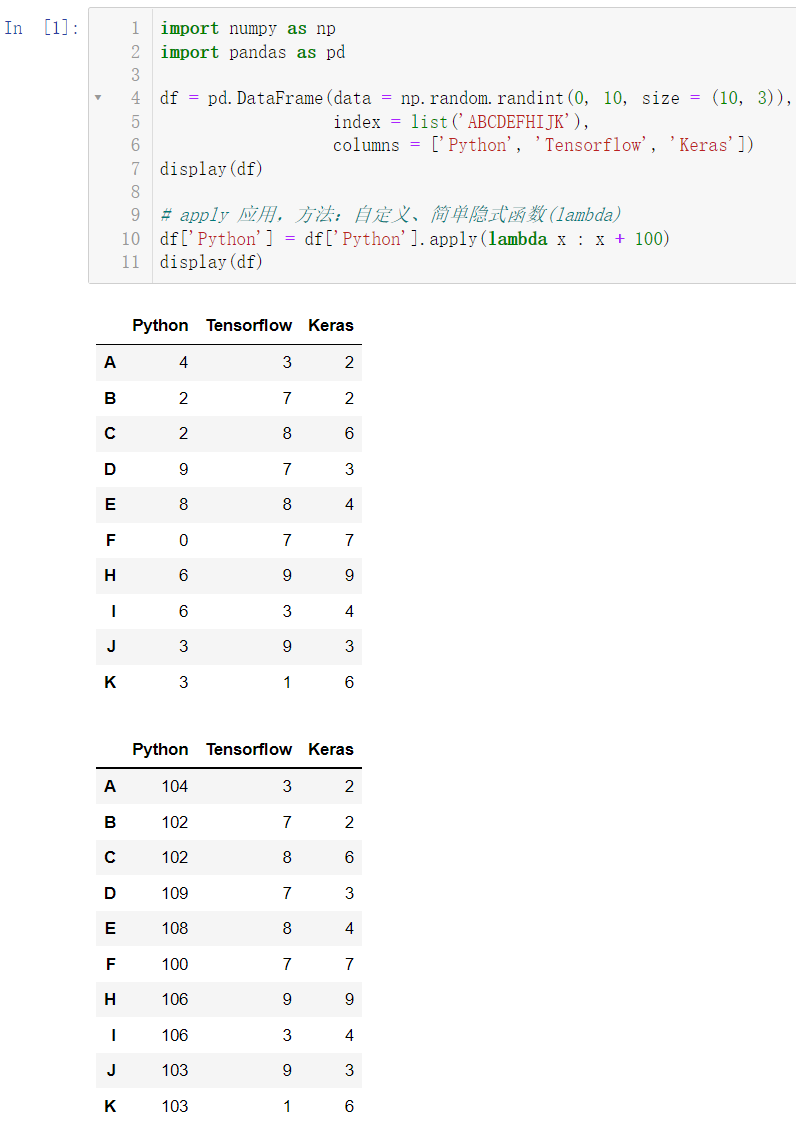
df['Python'] = df['Python'].apply(lambda x : x + 100)
display(df)
map 可以对一列数据进行修改:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 10, size = (10, 3)),
index = list('ABCDEFHIJK'),
columns = ['Python', 'Tensorflow', 'Keras'])
display(df)
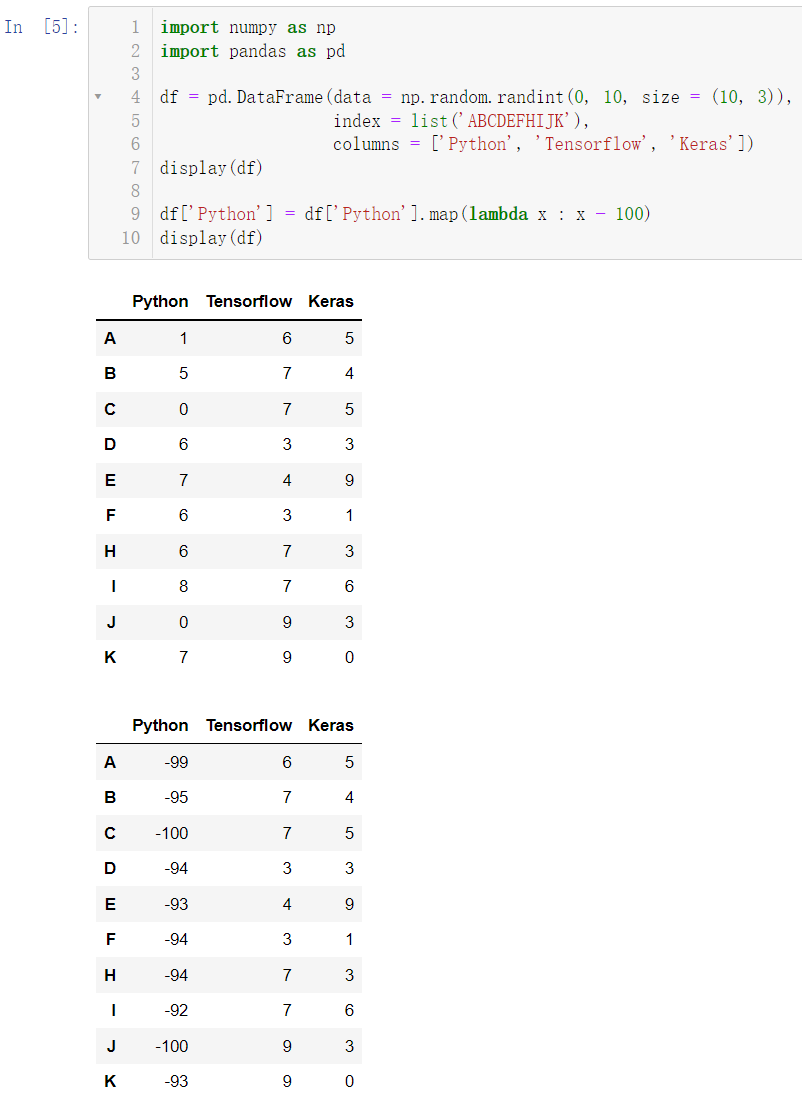
df['Python'] = df['Python'].map(lambda x : x - 100)
display(df)
3.3.3 applymap应用
applymap 可以对整个 DataFrame 进行全部的处理
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 10, size = (10, 3)),
index = list('ABCDEFHIJK'),
columns = ['Python', 'Tensorflow', 'Keras'])
display(df)
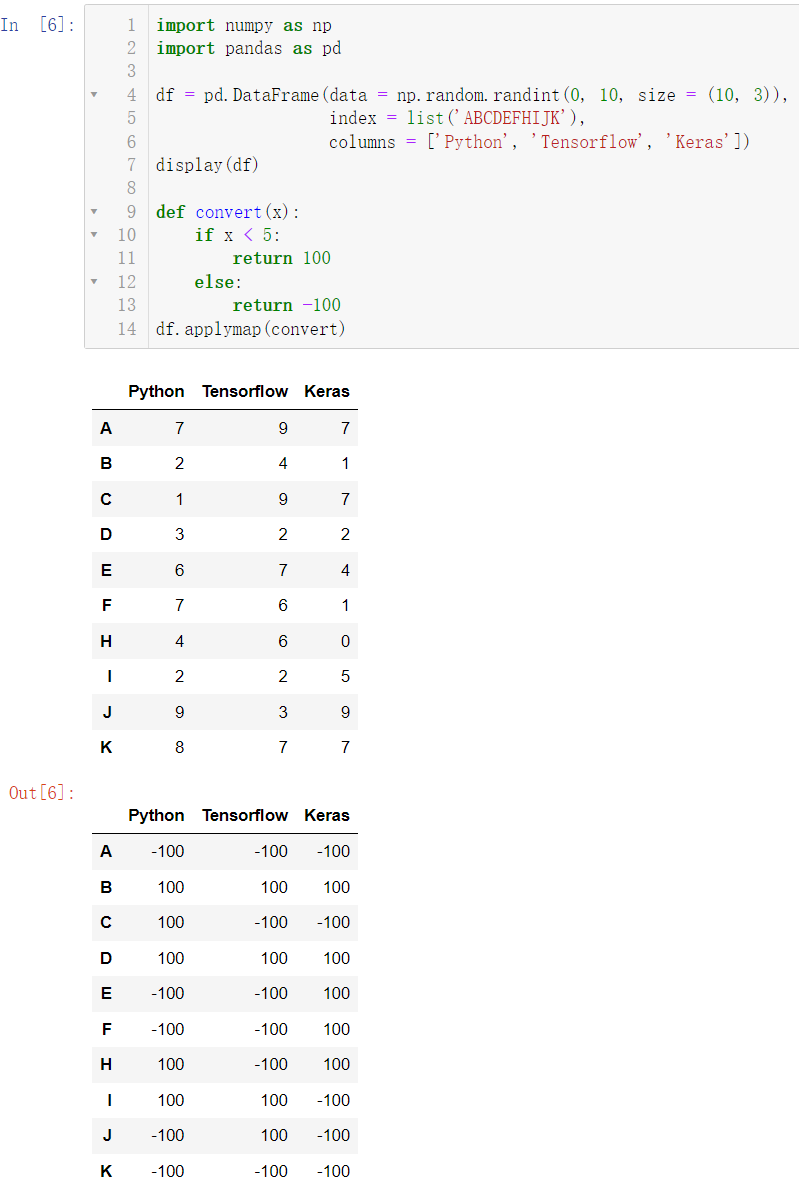
def convert(x):
if x < 5:
return 100
else:
return -100
df.applymap(convert)
3.4 transform变形金刚
创建数据:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 10, size = (10, 3)),
index = list('ABCDEFHIJK'),
columns=['Python', 'Tensorflow', 'Keras'])
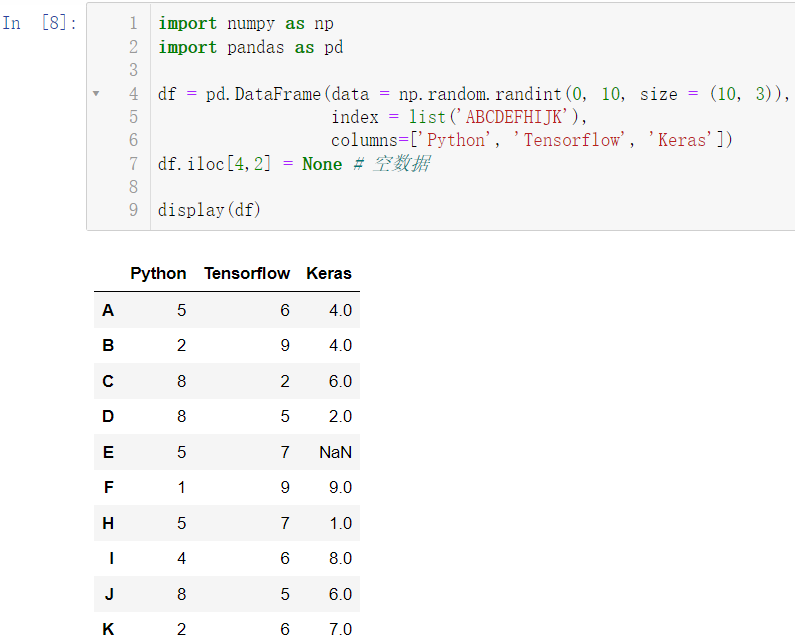
df.iloc[4,2] = None
display(df)
transform 一样是支持 lambda 和自定义函数的:
df['Python'].transform(lambda x : x + 10)
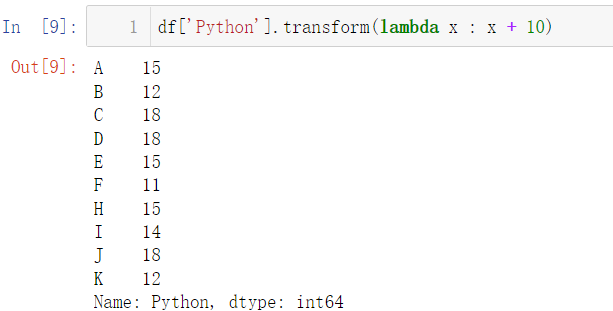
def convert(x):
if x < 5:
return 100
else:
return -100
df['Python'].transform(convert)

对一列进行不同的操作:
df['Python'].transform([np.sqrt, np.exp])
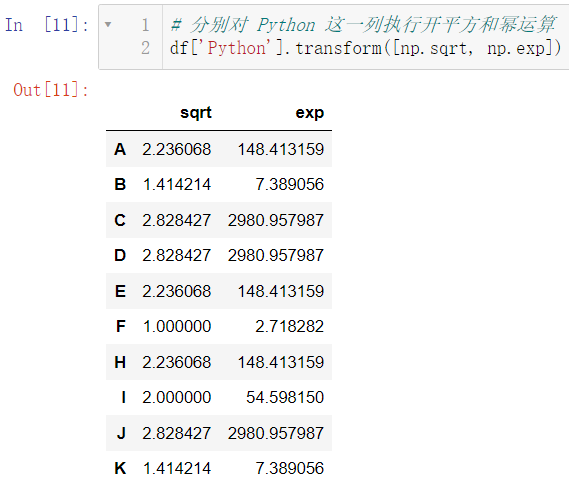
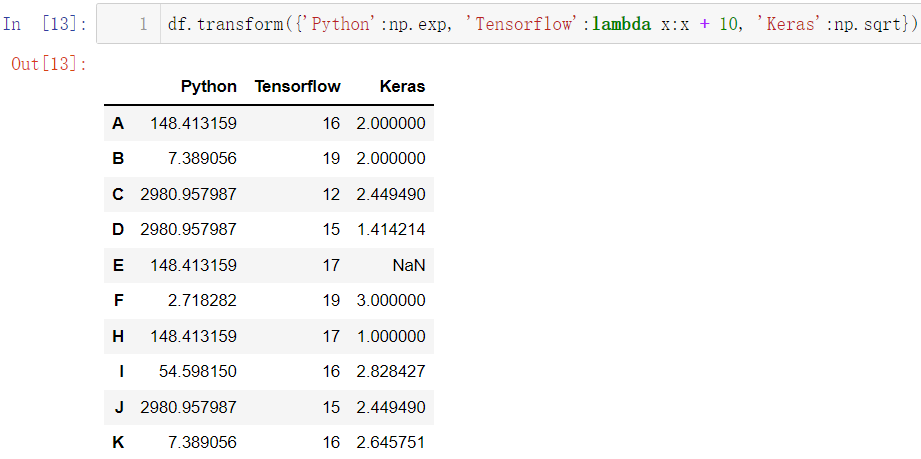
对多列进行不同的操作:
df.transform({'Python':np.exp, 'Tensorflow':lambda x:x + 10, 'Keras':np.sqrt})
3.5 重排随机抽样哑变量
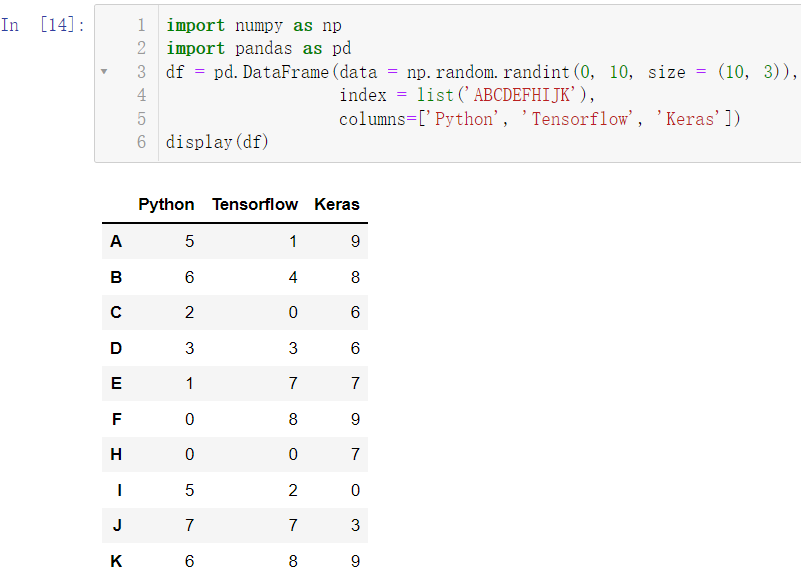
创建数据:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 10, size = (10, 3)),
index = list('ABCDEFHIJK'),
columns=['Python', 'Tensorflow', 'Keras'])
display(df)
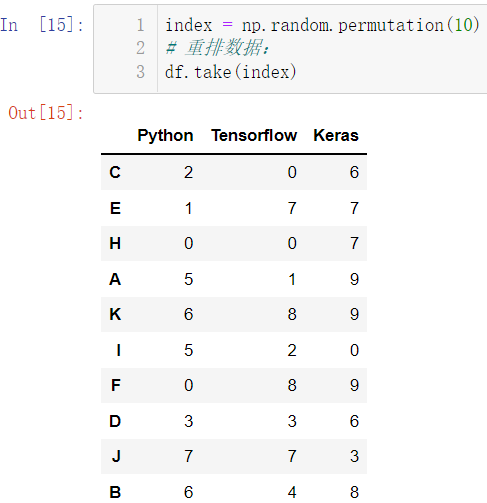
3.5.1 重拍数据
index = np.random.permutation(10)
df.take(index)
3.5.2 随机抽样
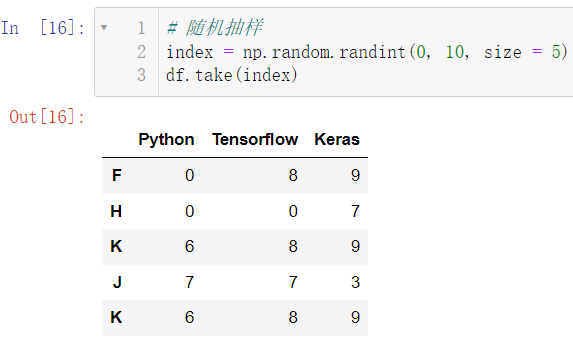
注:随机抽样是允许重复的
index = np.random.randint(0, 10, size = 5)
df.take(index)
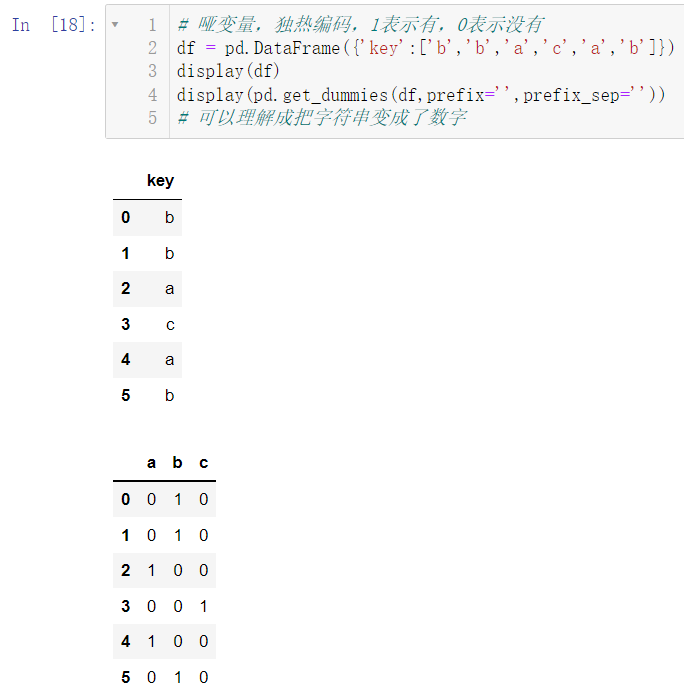
3.5.3 哑变量
df = pd.DataFrame({'key':['b','b','a','c','a','b']})
display(df)
display(pd.get_dummies(df,prefix='',prefix_sep=''))
4.训练场
4.1 知识点概述
4.1.1 字符串替换
将字符串:”我在大学的体能极限是1000米3分34秒!” 中的”我”替换为”辰chen”,再将成绩转换为纯数字:
import numpy as np
import pandas as pd
s1 = '我在大学的体能极限是1000米3分34秒!'
s1 = s1.replace('我', '辰chen')
display(s1)
s2 = "3'34"
s2 = s2.replace('\'', '.')
s2 = float(s2)
display(s2)

4.1.2 报错演示
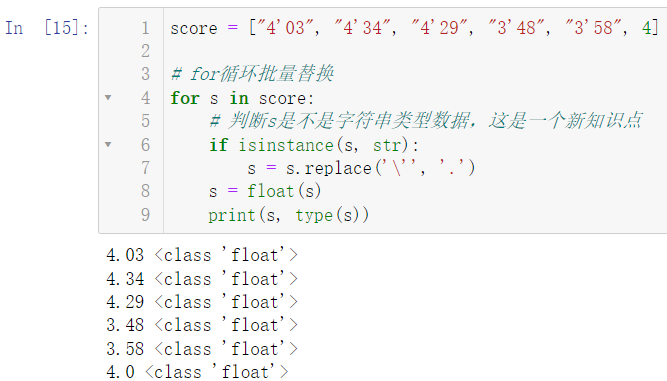
score = ["4'03", "4'34", "4'29", "3'48", "3'58", 4]
for s in score:
s = s.replace('\'', '.')
print(s)
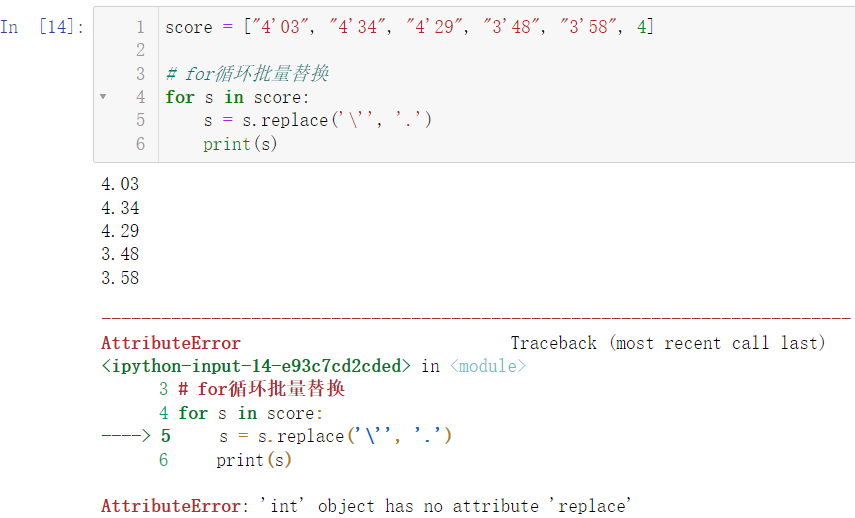
可以看出前几个数据都进行了正确的替换,只有最后一个数据因无法替换而报错,报错的原因在于最后一个数据是 int 类型的数据,是不能调用 replace 方法的,replace 只作用于字符串
所以我们在替换的过程中可以进行特判:
4.1.3 报错修复
使用 isinstance() 方法判断是否是字符串类型
score = ["4'03", "4'34", "4'29", "3'48", "3'58", 4]
for s in score:
if isinstance(s, str):
s = s.replace('\'', '.')
s = float(s)
print(s, type(s))
4.2 体测成绩的部分转换
4.2.1 男生1000米跑成绩转换
首先我们需要下载一个 Excel 文件:
链接: https://pan.baidu.com/s/1msM5CSZxyJ3TZ5e3TG4XiQ?pwd=w3ut
提取码: w3ut
复制这段内容后打开百度网盘手机App,操作更方便哦
下载完成之后,把该文件和我们的代码放到同一个文件夹下,这一操作我们在之前的博客中已经反复说到,这里就不再进行演示
我们点开我们下载好的文件:
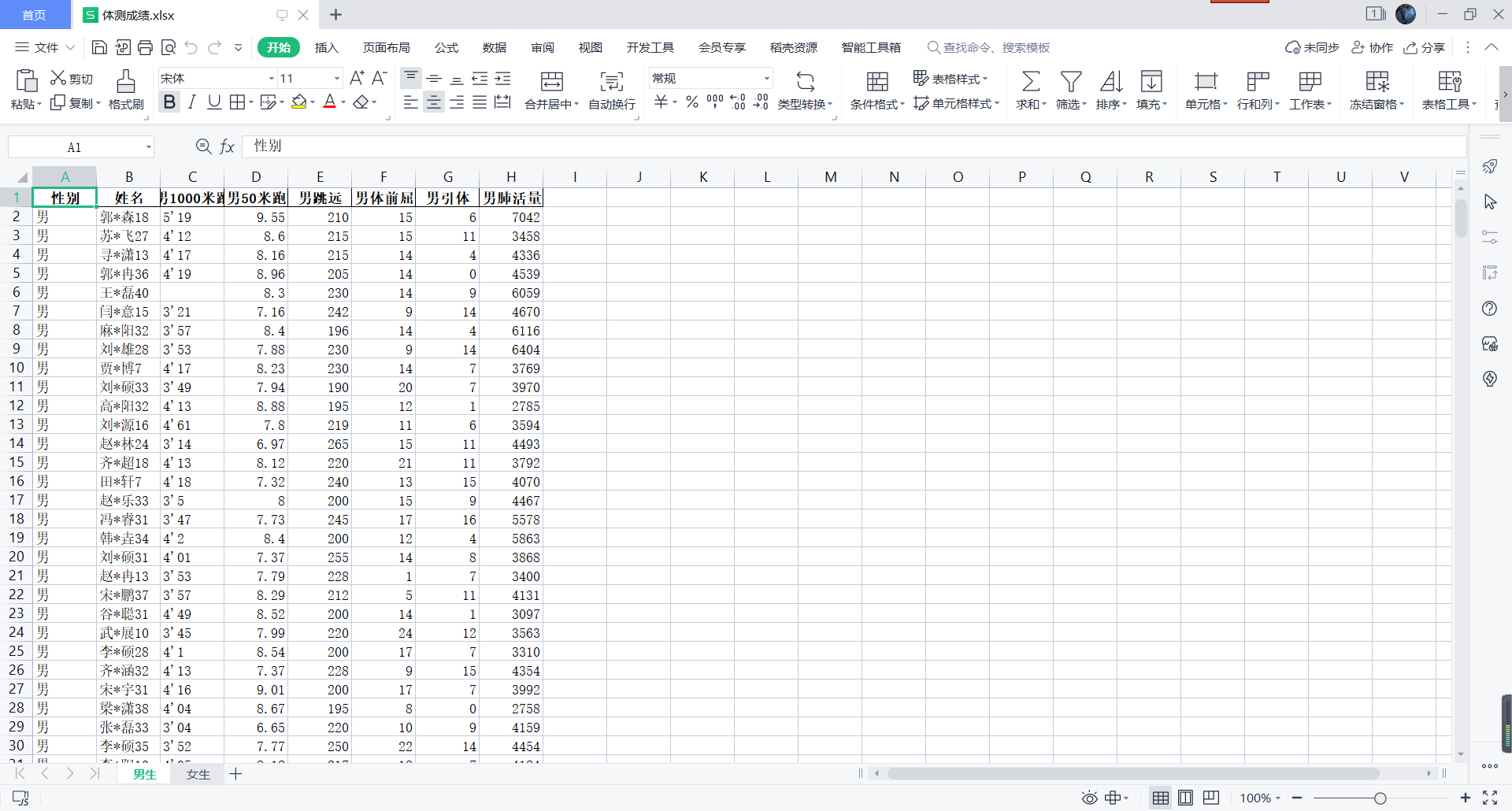
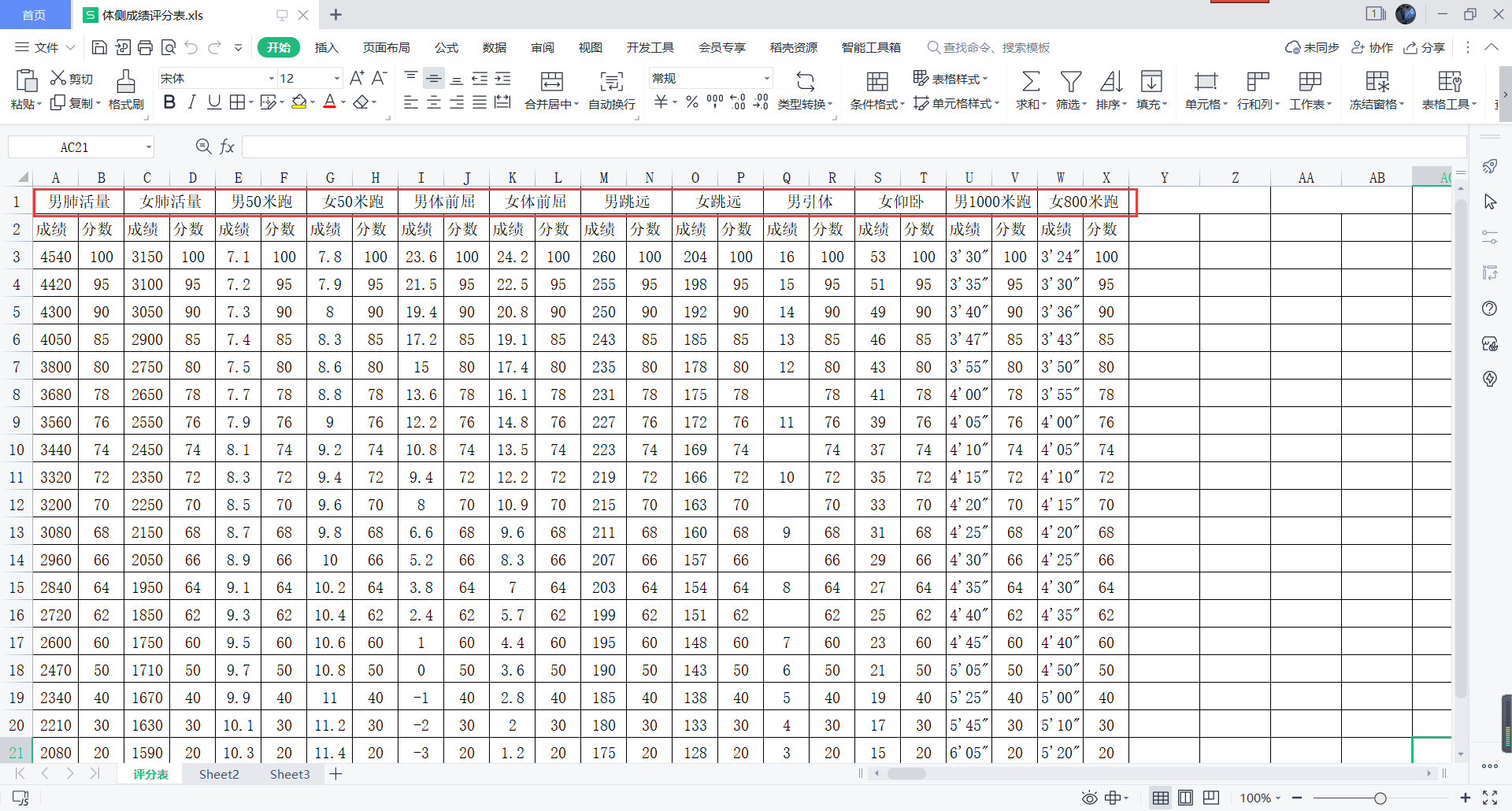
表格有男生表,也有女生表,在男生表中通过观察可以看出,只有 男1000米跑这一列数据是
xx'xx 的形式,我们要把它转为和 男50米跑,男跳远这样的数据形式,并且需要注意到,可能有些同学没有参加 1000米跑的测试,我们需要把这些空数据统一赋值为0
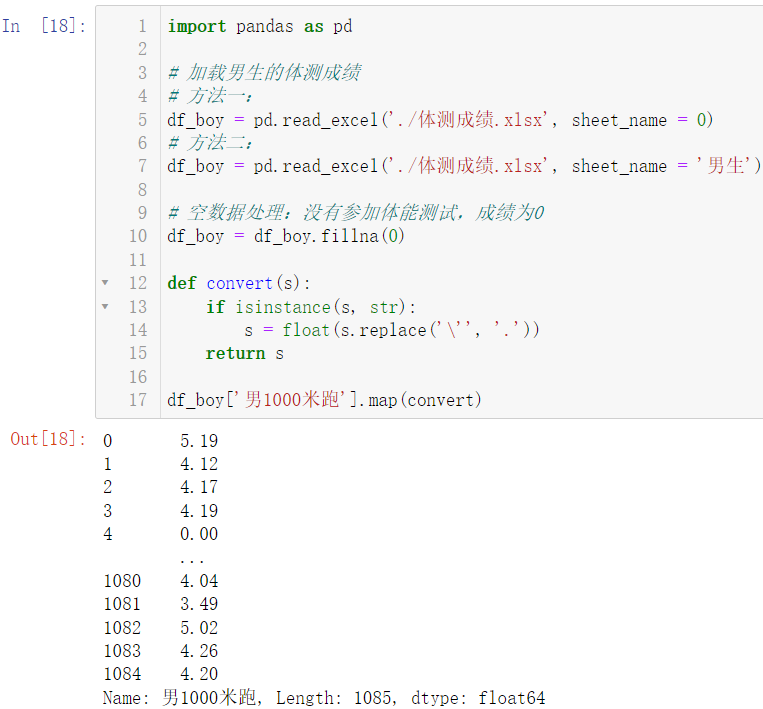
import pandas as pd
df_boy = pd.read_excel('./体测成绩.xlsx', sheet_name = 0)
df_boy = pd.read_excel('./体测成绩.xlsx', sheet_name = '男生')
df_boy = df_boy.fillna(0)
def convert(s):
if isinstance(s, str):
s = float(s.replace('\'', '.'))
return s
df_boy['男1000米跑'].map(convert)
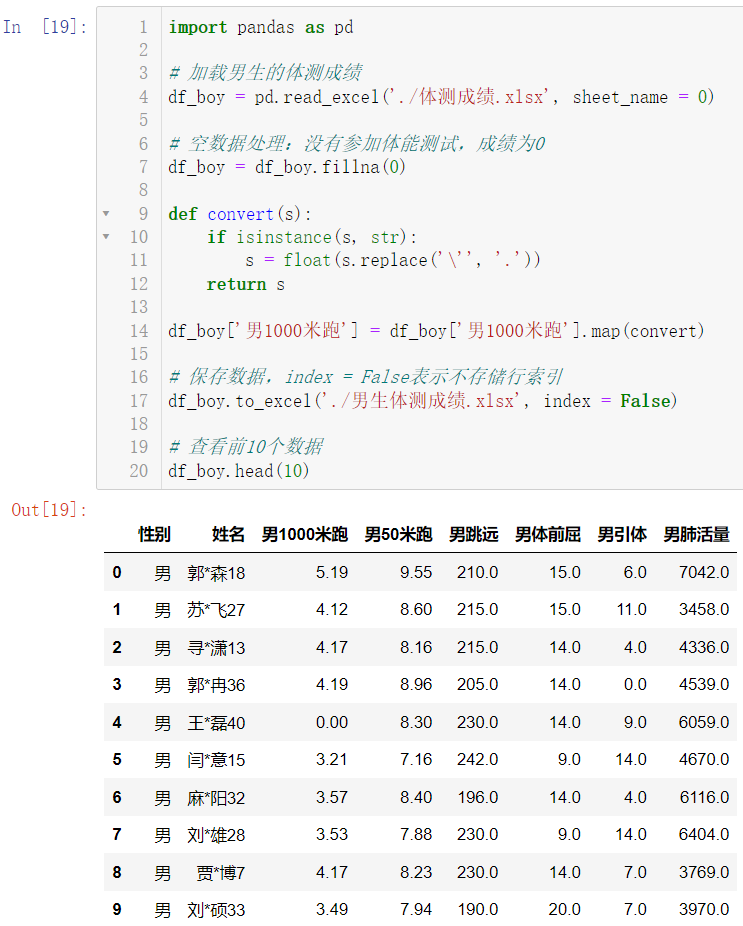
4.2.2 男生1000米跑成绩转换并赋值
import pandas as pd
df_boy = pd.read_excel('./体测成绩.xlsx', sheet_name = 0)
df_boy = df_boy.fillna(0)
def convert(s):
if isinstance(s, str):
s = float(s.replace('\'', '.'))
return s
df_boy['男1000米跑'] = df_boy['男1000米跑'].map(convert)
df_boy.to_excel('./男生体测成绩.xlsx', index = False)
df_boy.head(10)
对于女生数据,我们可以做同样的处理
import pandas as pd
df_girl = pd.read_excel('./体测成绩.xlsx',sheet_name = 1)
df_girl = df_girl.fillna(0)
def convert(s):
if isinstance(s, str):
s = float(s.replace('\'', '.'))
return s
df_girl['女800米跑'] = df_girl['女800米跑'].apply(convert)
df_girl.to_excel('./女生体测成绩.xlsx', index = False)
df_girl.tail(10)

4.3 体测成绩评分表数据转换
首先我们下载一个 Exel 文件:
链接: https://pan.baidu.com/s/1wxeENf0tjx5bWxTGxkZGeg?pwd=szmk
提取码: szmk
复制这段内容后打开百度网盘手机App,操作更方便哦
下载完成之后,把该文件和我们的代码放到同一个文件夹下,这一操作我们在之前的博客中已经反复说到,这里就不再进行演示
我们先按照传统的方法把数据进行加载查看
import numpy as np
import pandas as pd
score = pd.read_excel('./体侧成绩评分表.xls')
score
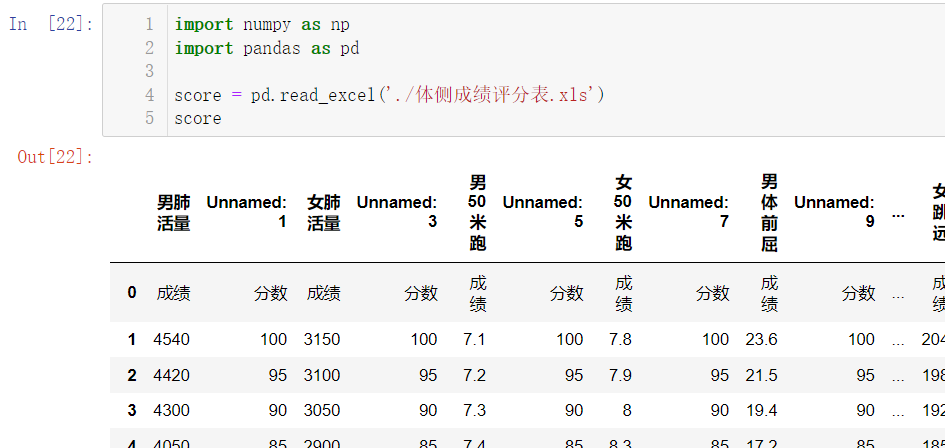
是不是感觉看起来特别的别扭?这是因为我们在我们的 Excel 文件中,我们最上方一行每个都占了两列的原因,所以代码运行中的 Unnamed1,Unnamed3 其实就是填充。
针对上述现象,我们可以按如下方法执行:
import numpy as np
import pandas as pd
score = pd.read_excel('./体侧成绩评分表.xls',header = [0, 1])
score
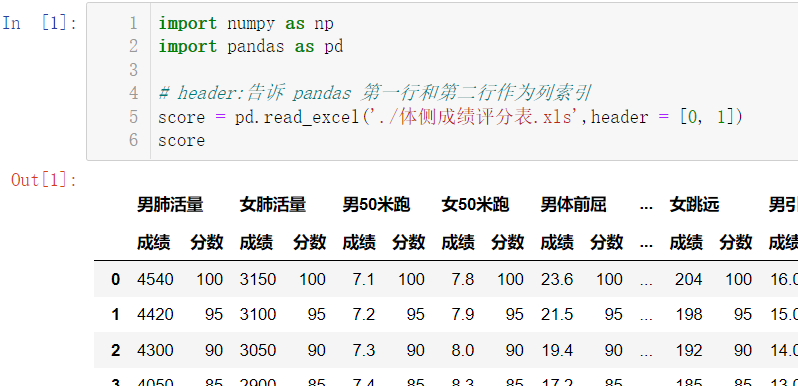
我们来观察数据:

发现成绩的形式都是:
xx'xx" 的形式,现在我们想把它转为数字的形式:
def convert(x):
if isinstance(x, str):
s = float(x.replace('\"', '').replace('\'', '.'))
return s
x = '''3'30"'''
convert(x)

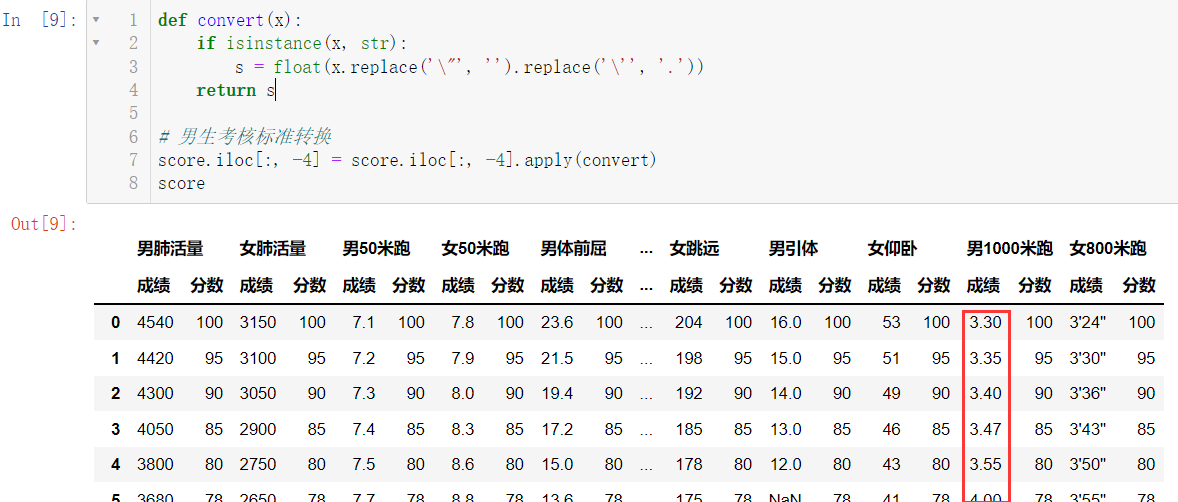
我们用上述方法对男生考核标准进行转换:
def convert(x):
if isinstance(x, str):
s = float(x.replace('\"', '').replace('\'', '.'))
return s
score.iloc[:, -4] = score.iloc[:, -4].apply(convert)
score
同样的方法,对女生信息进行转换:
score = pd.read_excel('./体侧成绩评分表.xls',header=[0, 1])
def convert(x):
if isinstance(x, str):
s = float(x.replace('\"', '').replace('\'', '.'))
return s
score.iloc[:, -4] = score.iloc[:, -4].apply(convert)
score.iloc[:, -2] = score.iloc[: , -2].apply(convert)
score
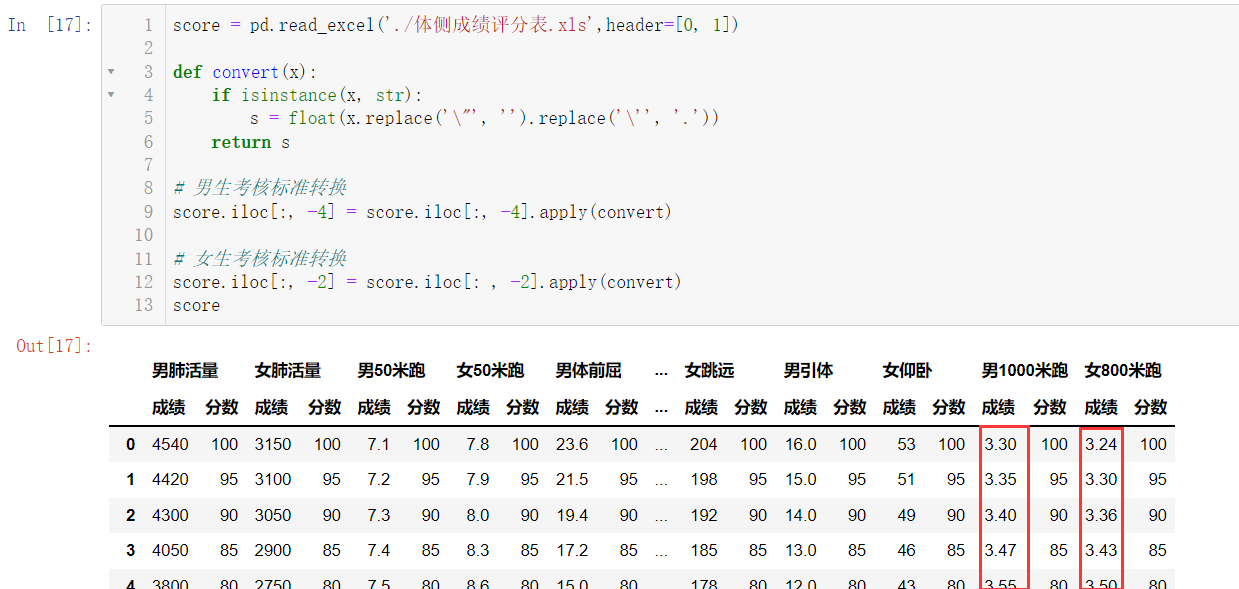
最后保存我们的文件:
score = pd.read_excel('./体侧成绩评分表.xls',header=[0, 1])
def convert(x):
if isinstance(x, str):
s = float(x.replace('\"', '').replace('\'', '.'))
return s
score.iloc[:, -4] = score.iloc[:, -4].apply(convert)
score.iloc[:, -2] = score.iloc[: , -2].apply(convert)
score.to_excel('./体侧成绩评分表_处理.xlsx', header=[0, 1])

再来查看以下我们的数据:
pd.read_excel('./体侧成绩评分表_处理.xlsx', header = [0, 1])
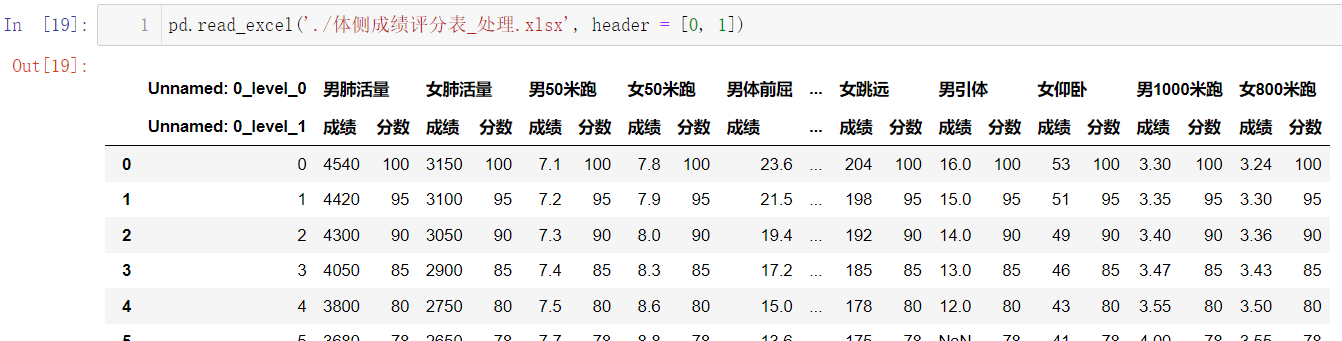
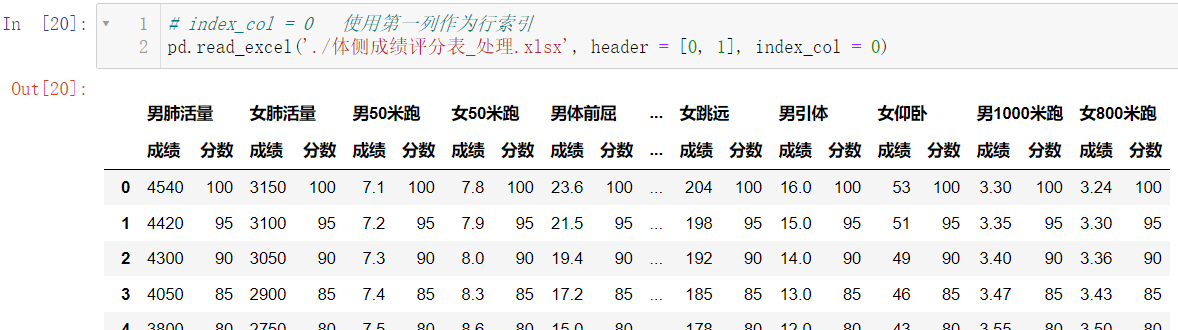
可以看到第一列多了一些奇奇怪怪的东西,我们用
index_col = 0 删除:
pd.read_excel('./体侧成绩评分表_处理.xlsx', header = [0, 1], index_col = 0)
4.4 男生体测分数成绩转换
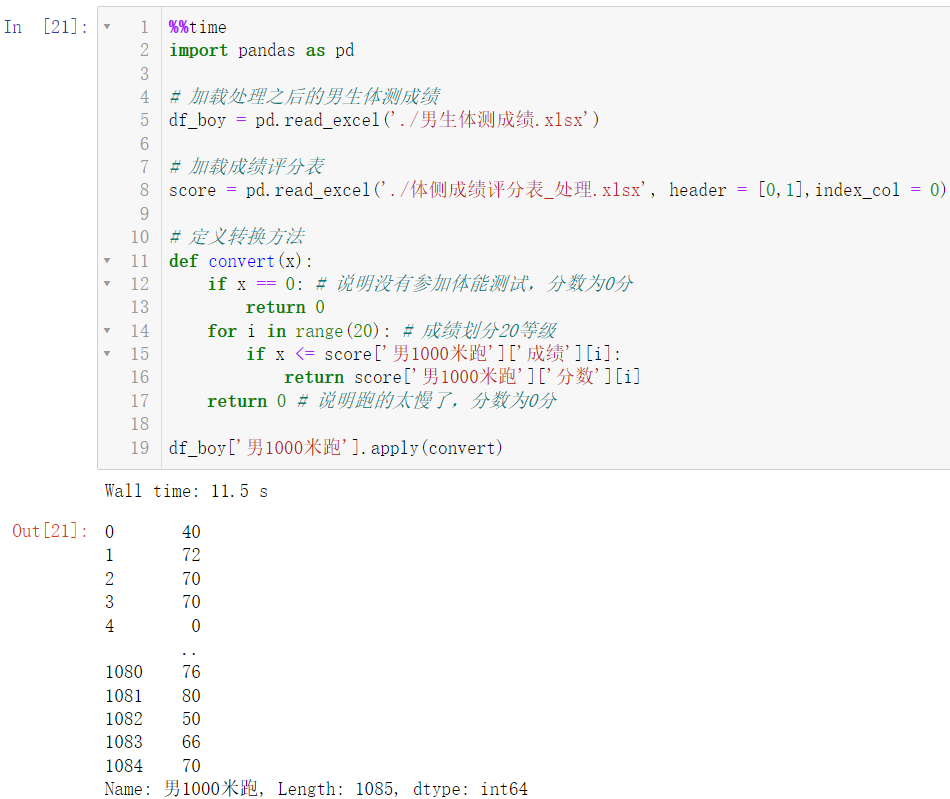
4.4.1 男生1000米跑成绩分数转换
注:代码处于运行中将显示:

下列代码运行十几秒,几十秒甚至几分钟都是正常的,耐心等待运行结果即可。
%%time
import pandas as pd
df_boy = pd.read_excel('./男生体测成绩.xlsx')
score = pd.read_excel('./体侧成绩评分表_处理.xlsx', header = [0,1],index_col = 0)
def convert(x):
if x == 0:
return 0
for i in range(20):
if x score['男1000米跑']['成绩'][i]:
return score['男1000米跑']['分数'][i]
return 0
df_boy['男1000米跑'].apply(convert)
4.4.2 男生1000米跑成绩分数转换并赋值
%%time
import pandas as pd
df_boy = pd.read_excel('./男生体测成绩.xlsx')
score = pd.read_excel('./体侧成绩评分表_处理.xlsx', header = [0, 1])
def convert(x):
if x == 0:
return 0
for i in range(20):
if x score['男1000米跑']['成绩'][i]:
return score['男1000米跑']['分数'][i]
return 0
df_boy['男1000米跑' + '分数'] = df_boy['男1000米跑'].apply(convert)
df_boy.head(10)
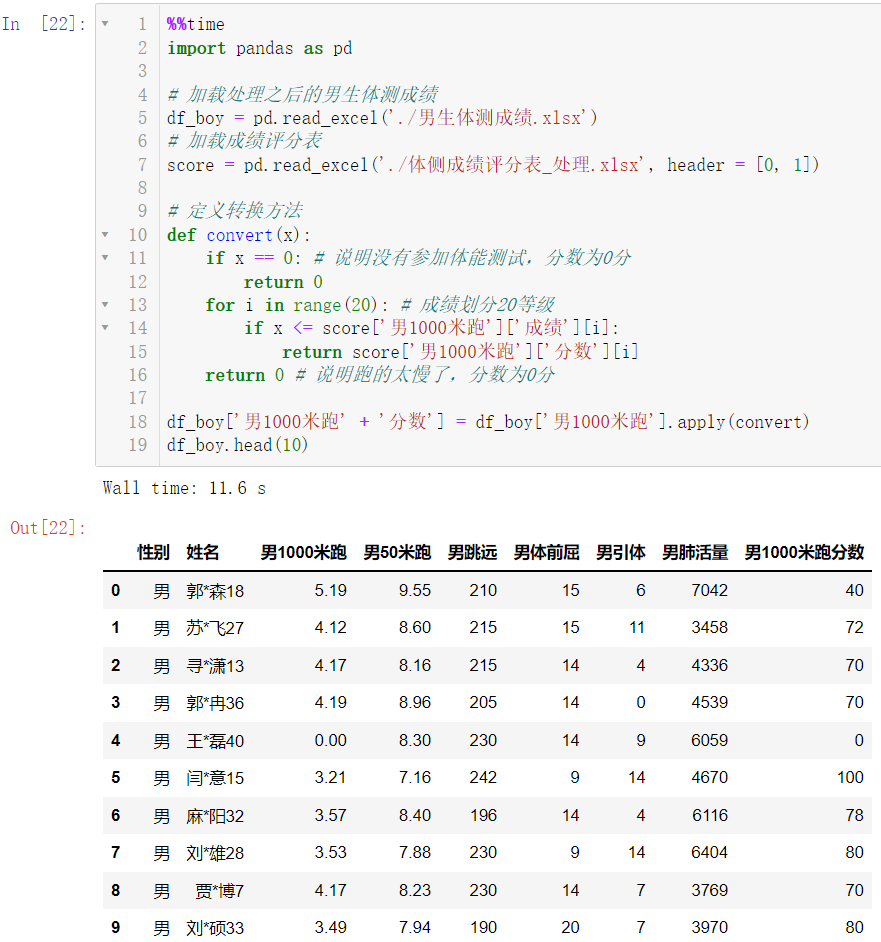
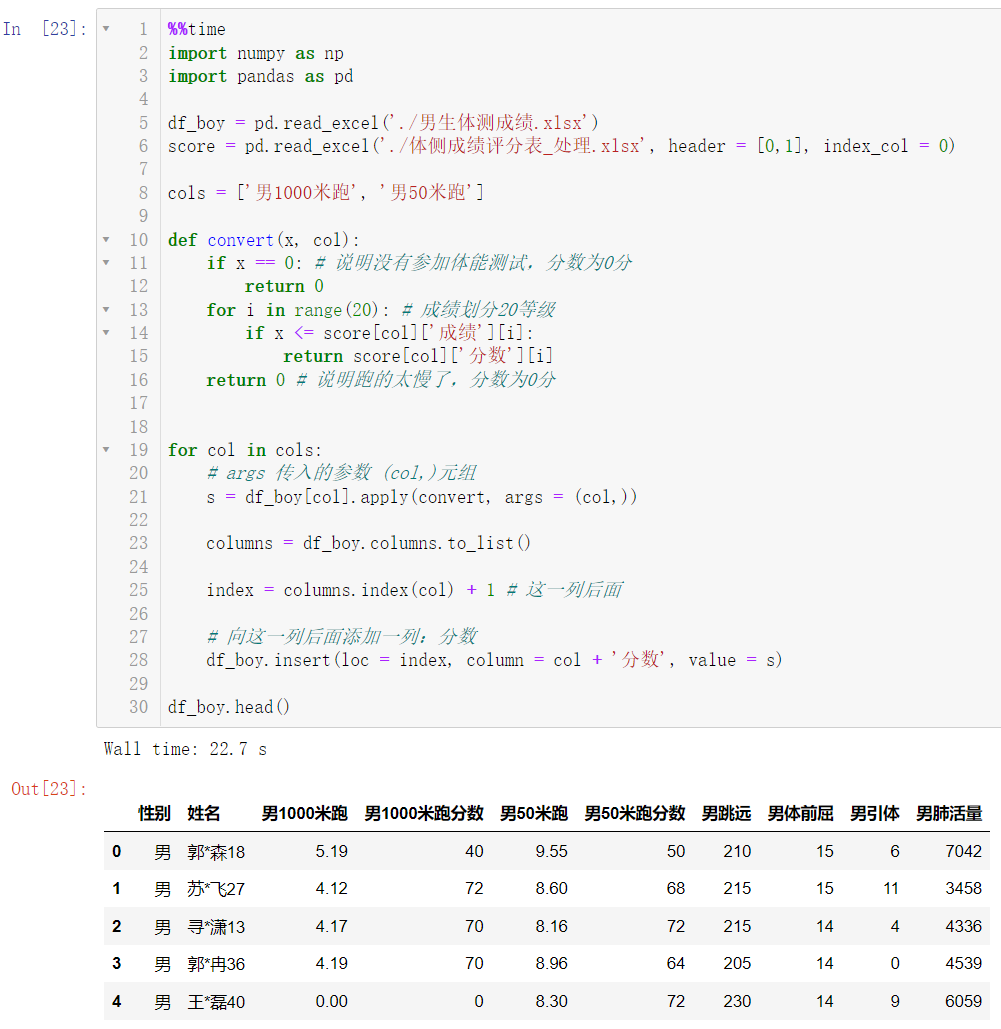
4.4.3 批量转换男生速度类成绩分数
%%time
import numpy as np
import pandas as pd
df_boy = pd.read_excel('./男生体测成绩.xlsx')
score = pd.read_excel('./体侧成绩评分表_处理.xlsx', header = [0,1], index_col = 0)
cols = ['男1000米跑', '男50米跑']
def convert(x, col):
if x == 0:
return 0
for i in range(20):
if x score[col]['成绩'][i]:
return score[col]['分数'][i]
return 0
for col in cols:
s = df_boy[col].apply(convert, args = (col,))
columns = df_boy.columns.to_list()
index = columns.index(col) + 1
df_boy.insert(loc = index, column = col + '分数', value = s)
df_boy.head()
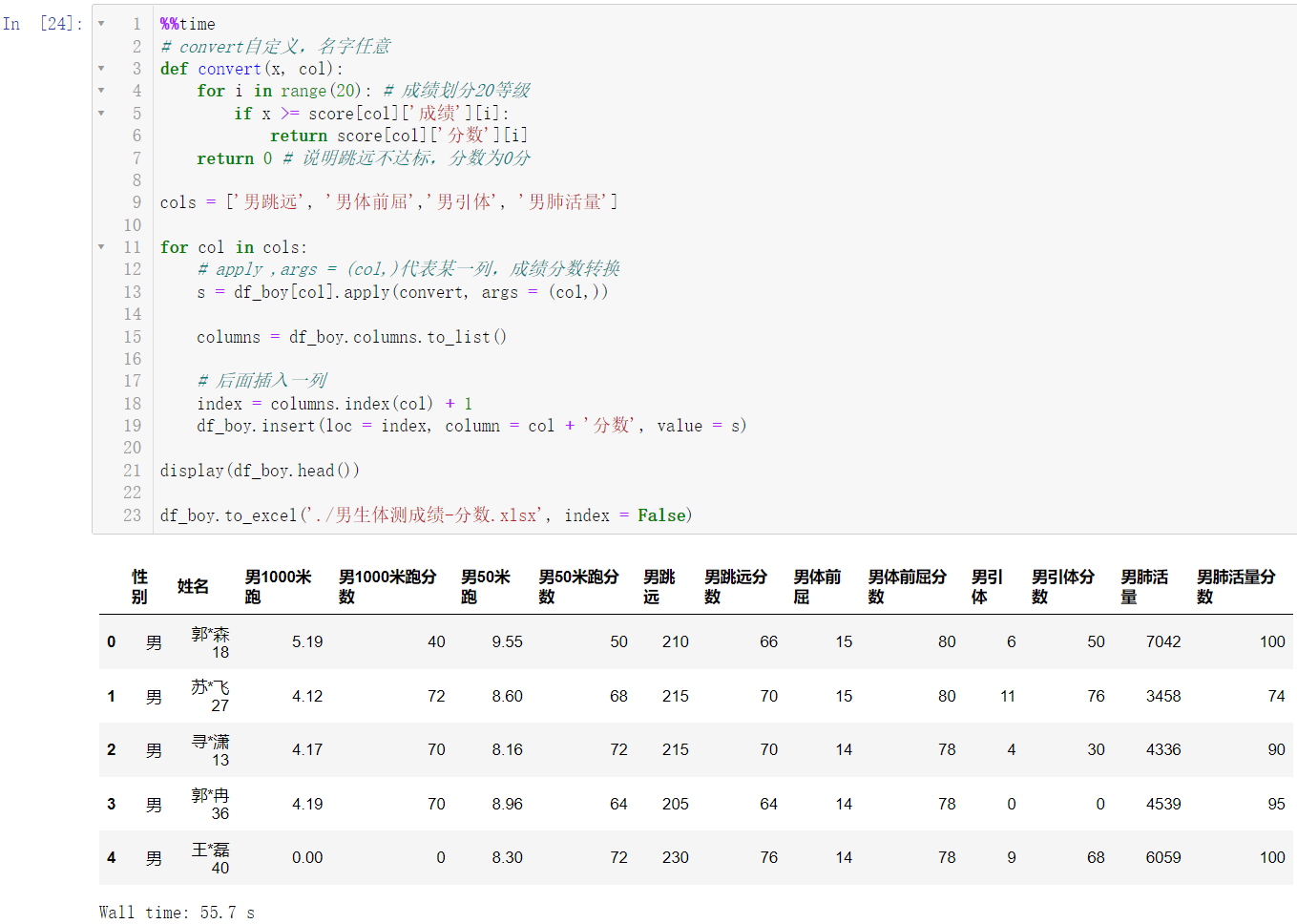
4.4.4 批量转换男生力量型成绩分数并保存
%%time
def convert(x, col):
for i in range(20):
if x >= score[col]['成绩'][i]:
return score[col]['分数'][i]
return 0
cols = ['男跳远', '男体前屈', '男引体', '男肺活量']
for col in cols:
s = df_boy[col].apply(convert, args = (col,))
columns = df_boy.columns.to_list()
index = columns.index(col) + 1
df_boy.insert(loc = index, column = col + '分数', value = s)
display(df_boy.head())
df_boy.to_excel('./男生体测成绩-分数.xlsx', index = False)
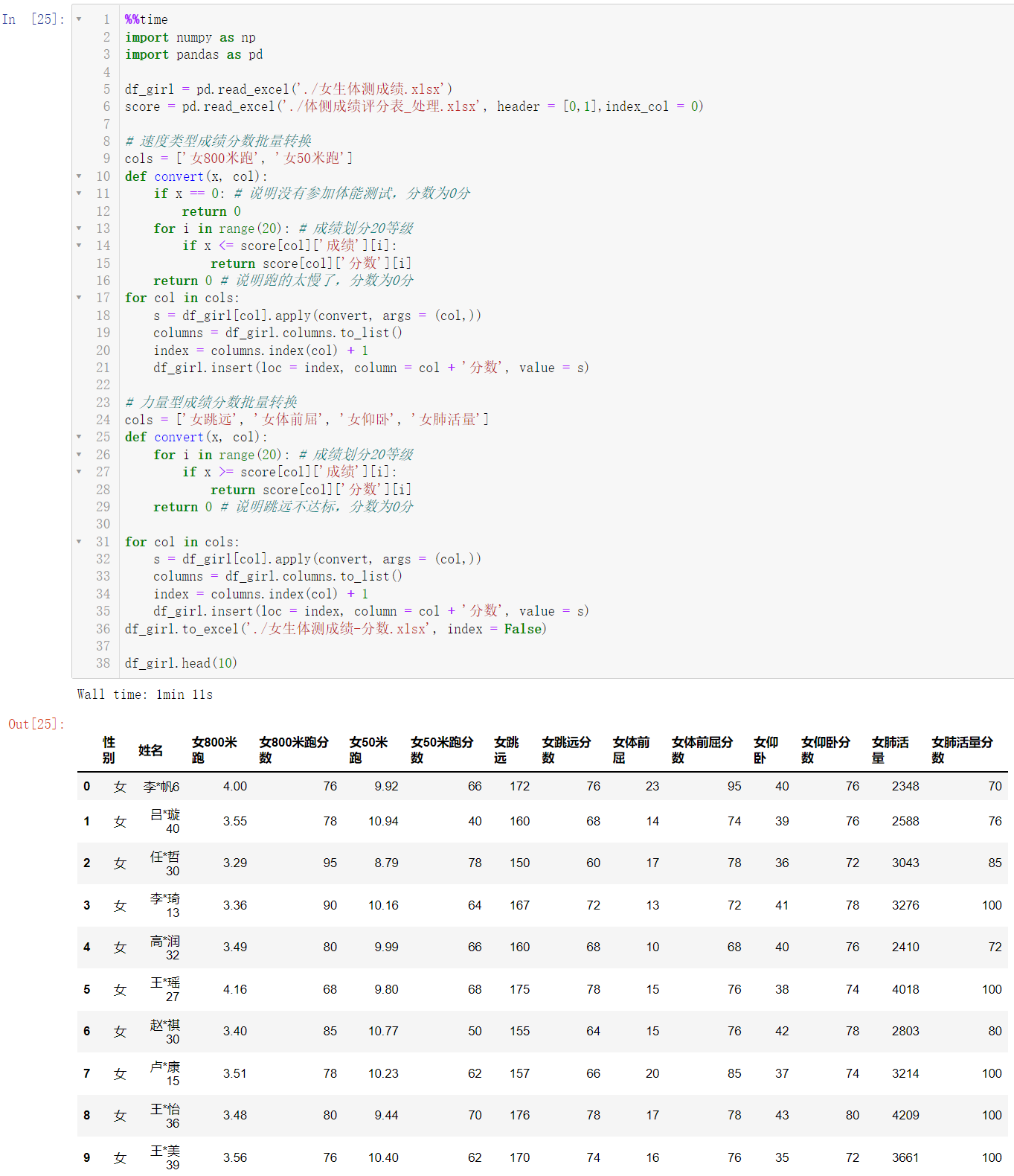
4.5 女生体测成绩分数转换
%%time
import numpy as np
import pandas as pd
df_girl = pd.read_excel('./女生体测成绩.xlsx')
score = pd.read_excel('./体侧成绩评分表_处理.xlsx', header = [0,1],index_col = 0)
cols = ['女800米跑', '女50米跑']
def convert(x, col):
if x == 0:
return 0
for i in range(20):
if x score[col]['成绩'][i]:
return score[col]['分数'][i]
return 0
for col in cols:
s = df_girl[col].apply(convert, args = (col,))
columns = df_girl.columns.to_list()
index = columns.index(col) + 1
df_girl.insert(loc = index, column = col + '分数', value = s)
cols = ['女跳远', '女体前屈', '女仰卧', '女肺活量']
def convert(x, col):
for i in range(20):
if x >= score[col]['成绩'][i]:
return score[col]['分数'][i]
return 0
for col in cols:
s = df_girl[col].apply(convert, args = (col,))
columns = df_girl.columns.to_list()
index = columns.index(col) + 1
df_girl.insert(loc = index, column = col + '分数', value = s)
df_girl.to_excel('./女生体测成绩-分数.xlsx', index = False)
df_girl.head(10)
4.6 保存成绩
最后我们把男女生成绩整合到一个文件当中:
with pd.ExcelWriter('./分数汇总.xlsx') as writer:
df_boy.to_excel(writer, sheet_name = '男生', index = False)
df_girl.to_excel(writer, sheet_name = '女生', index = False)
三、pandas进阶
1.数据重塑
🚩数据重塑其实就是行变列,列变行
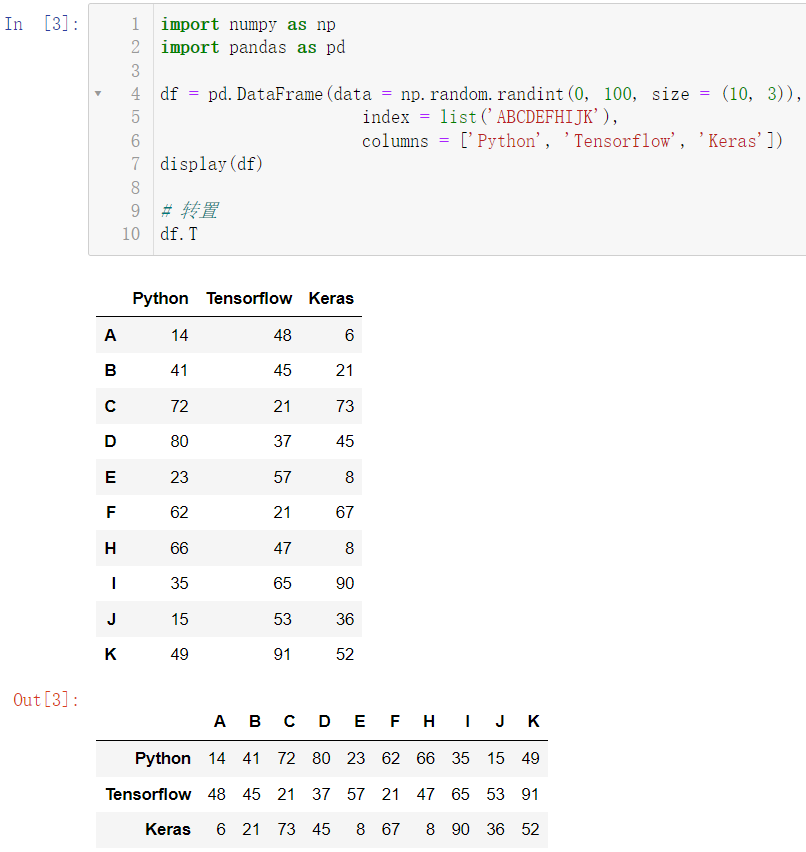
1.1 一般数据
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 100, size = (10, 3)),
index = list('ABCDEFHIJK'),
columns = ['Python', 'Tensorflow', 'Keras'])
display(df)
df.T
1.2 多层索引
df2 = pd.DataFrame(data = np.random.randint(0, 100, size = (20, 3)),
index = pd.MultiIndex.from_product([list('ABCDEFHIJK'),
['期中', '期末']]),
columns = ['Python', 'Tensorflow', 'Keras'])
df2
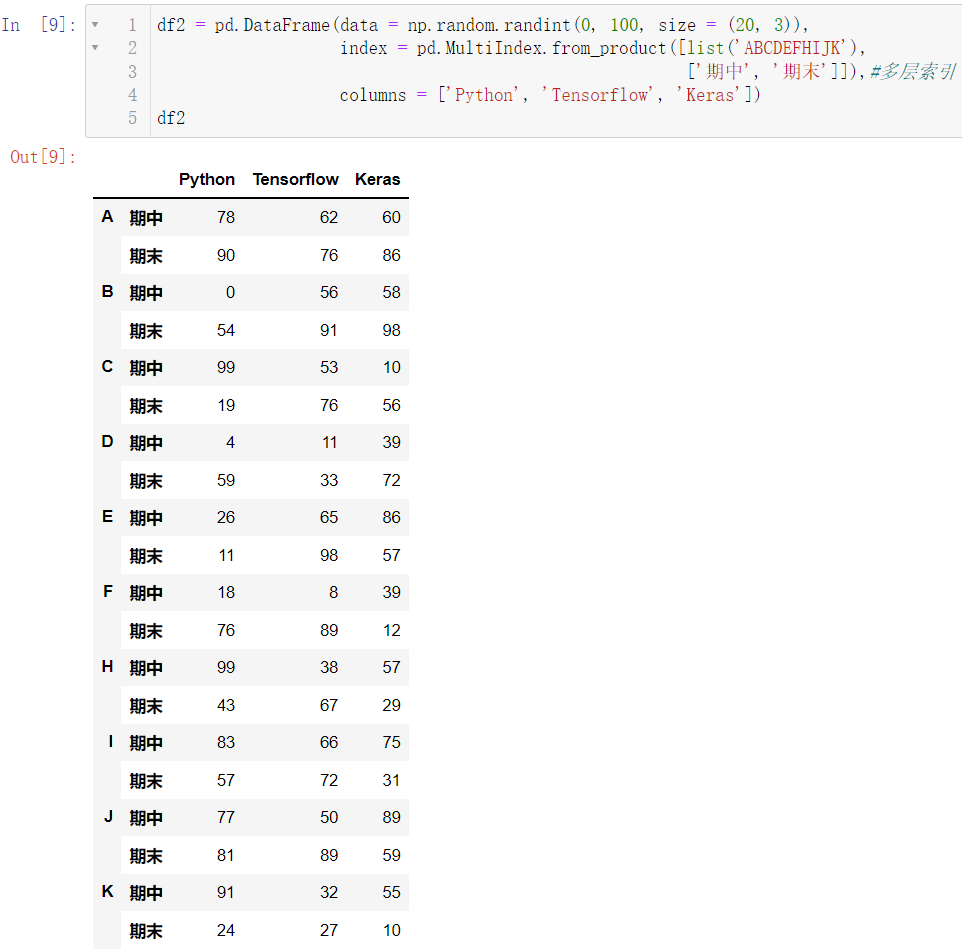
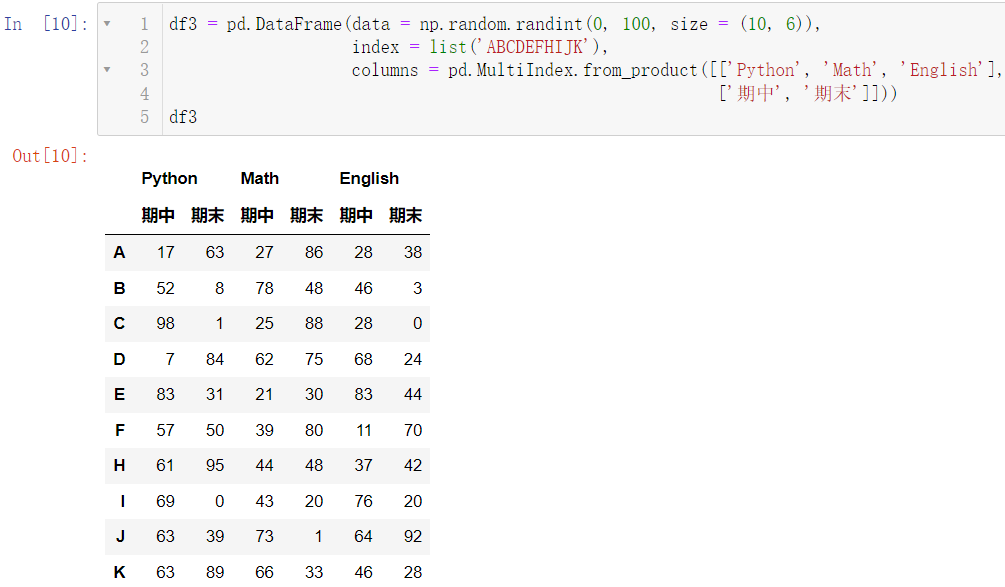
我们来解释一下这个复杂的代码:
ndex = pd.MultiIndex.from_product([list('ABCDEFHIJK'), ['期中', '期末']]),我们的第一个参数: ABCDEFHIJK,共是 10 10 1 0 个字母,第二个参数是两个字符串,所以我们一共会有 20 20 2 0 行的数据,这正好对应了前面的代码 size = (20, 3),读者自行理解下面这个代码:
df3 = pd.DataFrame(data = np.random.randint(0, 100, size = (10, 6)),
index = list('ABCDEFHIJK'),
columns = pd.MultiIndex.from_product([['Python', 'Math', 'English'],
['期中', '期末']]))
df3
我们用 unstack() 完成多层索引行变列的数据重塑:
df2.unstack()

可以看出来,只是把行索引最里层的期中期末 移到了列索引的位置,我们也可以把行索引外层的 ABCDEFHIJK 移动至列索引的位置:
df2.unstack(level = 0)

我们用 stack() 完成多层索引列变行的数据重塑:
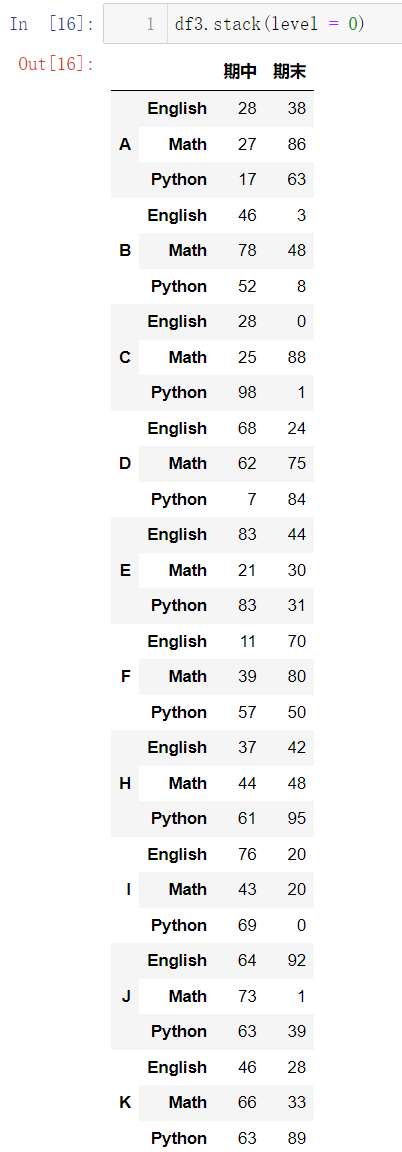
df3.stack()

同样,我们通过调整参数可以实现使得列索引的最外层变成行索引:
df3.stack(level = 0)
1.3 多层索引的运算
sum() 求和运算:
df2.sum()

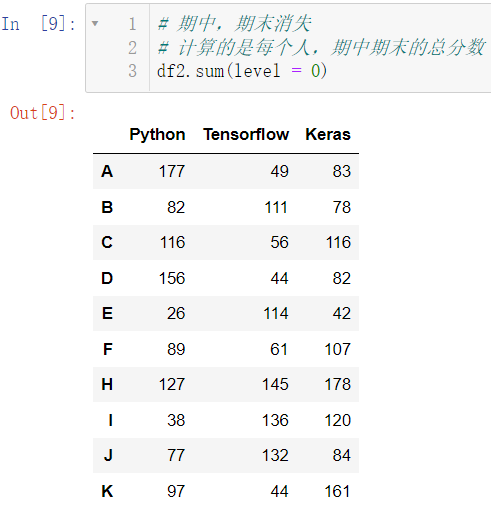
当然,这样的数据一般是没有意义的,我们一般想要求出每一位同学的总分,而不是每门科目的总分:
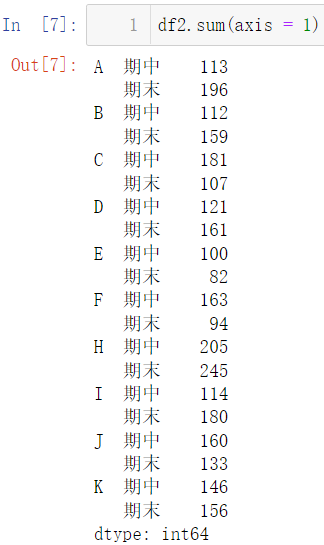
df2.sum(axis = 1)
df2.sum(level = 0)
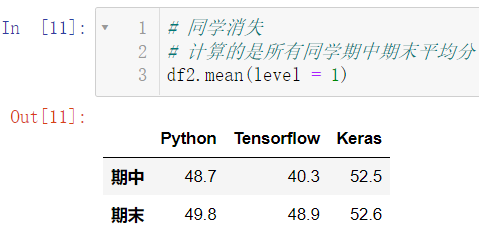
mean() 用来计算平均分:
df2.mean(level = 1)
接下来简单介绍一下如何取数据:
df3['Python', '期中']['A']

df2['Python']['A', '期中']

2.数学和统计方法
🚩pandas对象拥有一组常用的数学和统计方法。它们属于汇总统计,对Series汇总计算获取mean、max值或者对DataFrame行、列汇总计算返回一个Series。
2.1 简单统计指标
创建数据:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 100,size = (20, 3)),
index = list('ABCDEFHIJKLMNOPQRSTU'),
columns = ['Python', 'Tensorflow', 'Keras'])
df
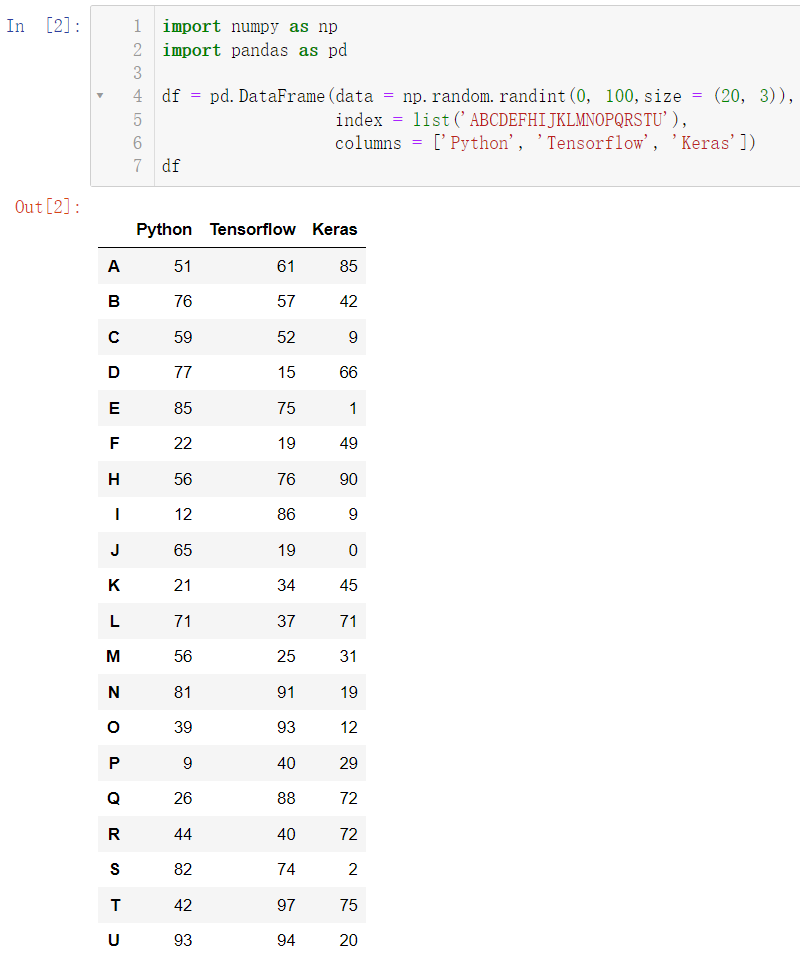
我们现在来把一部分数据设置为空:
def convert(x):
if x > 80:
return np.NaN
else:
return x
df['Python'] = df['Python'].map(convert)
df['Tensorflow'] = df['Tensorflow'].apply(convert)
df['Keras'] = df['Keras'].transform(convert)
df
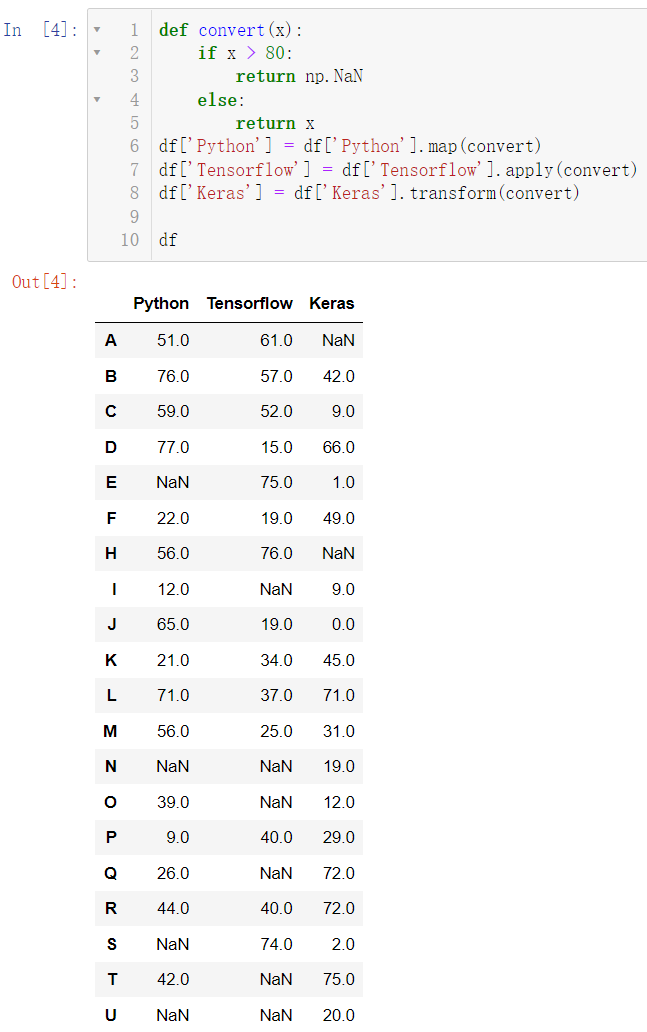
现在我们想知道到底有多少个空数据,我们可以自己去数,但这显然是低效的方法,使用 count() 函数可以直接去统计有多少个非空数据:
df.count()

我们重新来构造数据:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 100,size = (20, 3)),
index = list('ABCDEFHIJKLMNOPQRSTU'),
columns = ['Python', 'Tensorflow', 'Keras'])
df
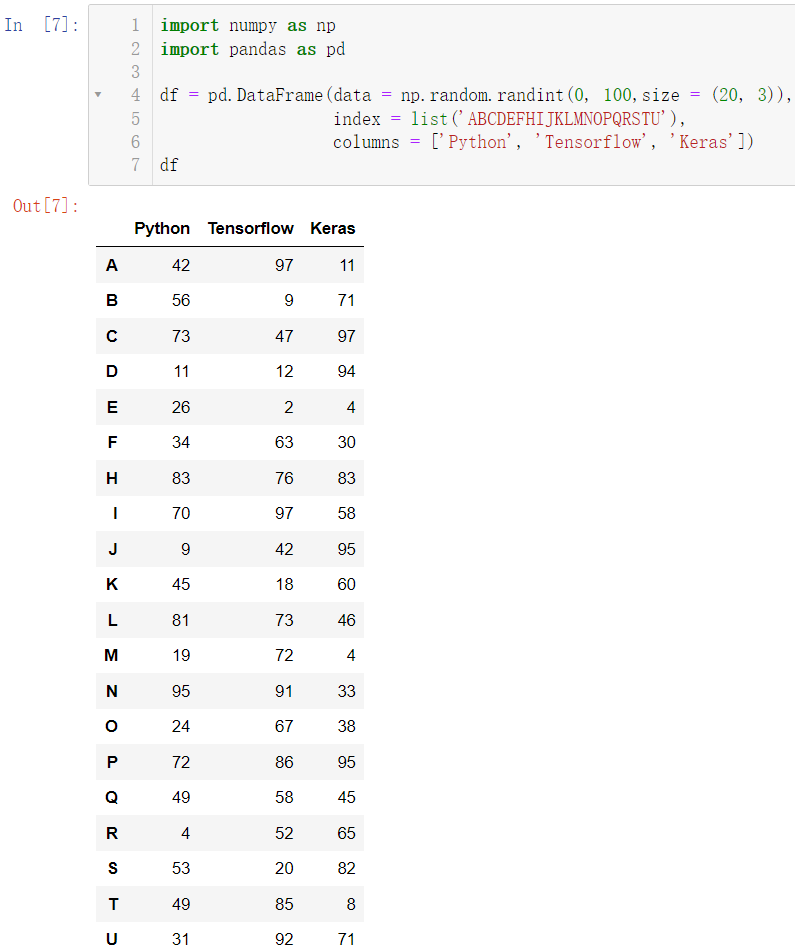
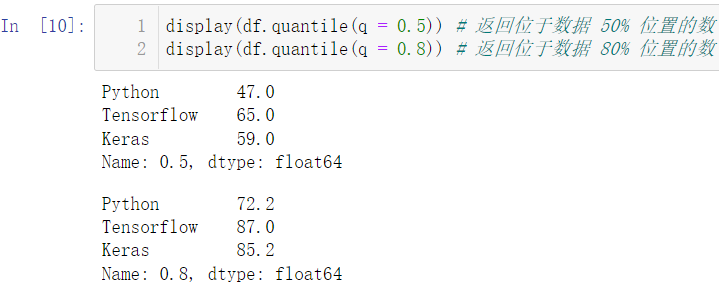
使用 median() 可以计算数据的中位数:
df.median()

display(df.quantile(q = 0.5))
display(df.quantile(q = 0.8))
我们也可以使用如下的方法实现同样的效果:
df.quantile(q = [0.5, 0.8])

2.2 索引标签、位置获取
display(df['Python'].argmin())
display(df['Keras'].argmax())

display(df.idxmax())
display(df.idxmin())
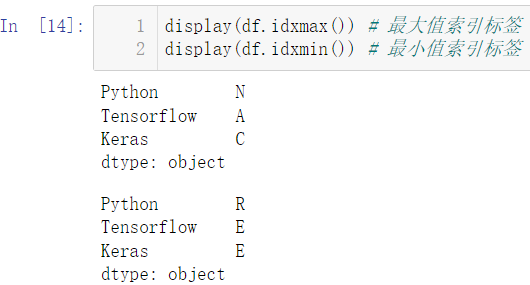
索引就是自然数,标签就是我们初始设置的 ABCD…,索引和标签是一一对应的,如 0 对应的就是 A
2.3 更多统计指标
创建数据:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 5,size = (20, 3)),
index = list('ABCDEFHIJKLMNOPQRSTU'),
columns = ['Python', 'Tensorflow', 'Keras'])
df
使用 value_counts() 可以统计元素出现的次数:
df['Python'].value_counts()

使用 unique() 可以实现去重:
df['Python'].unique()

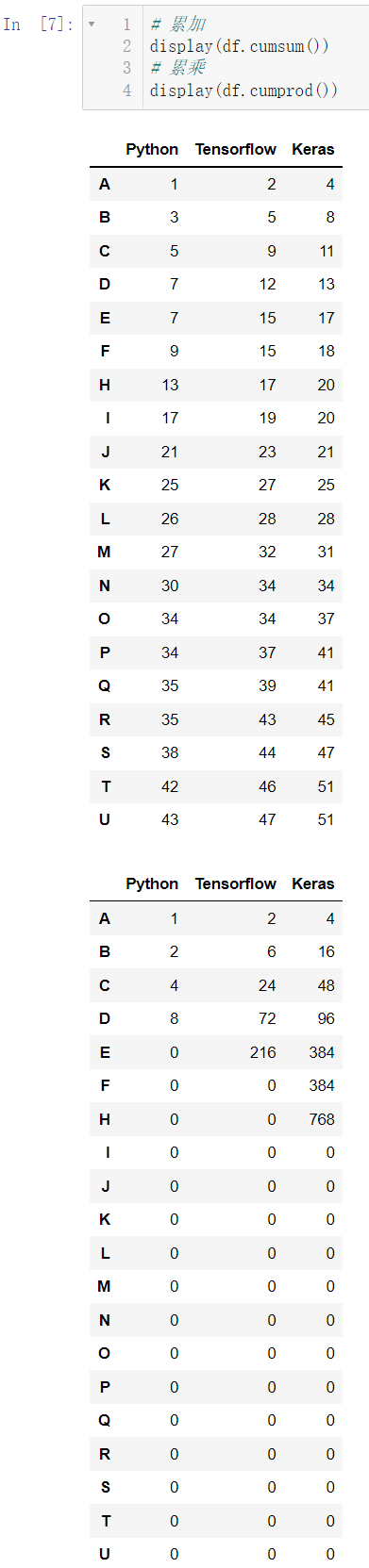
调用 cumsum() 实现累加,调用 cumprod() 实现累乘:
display(df.cumsum())
display(df.cumprod())
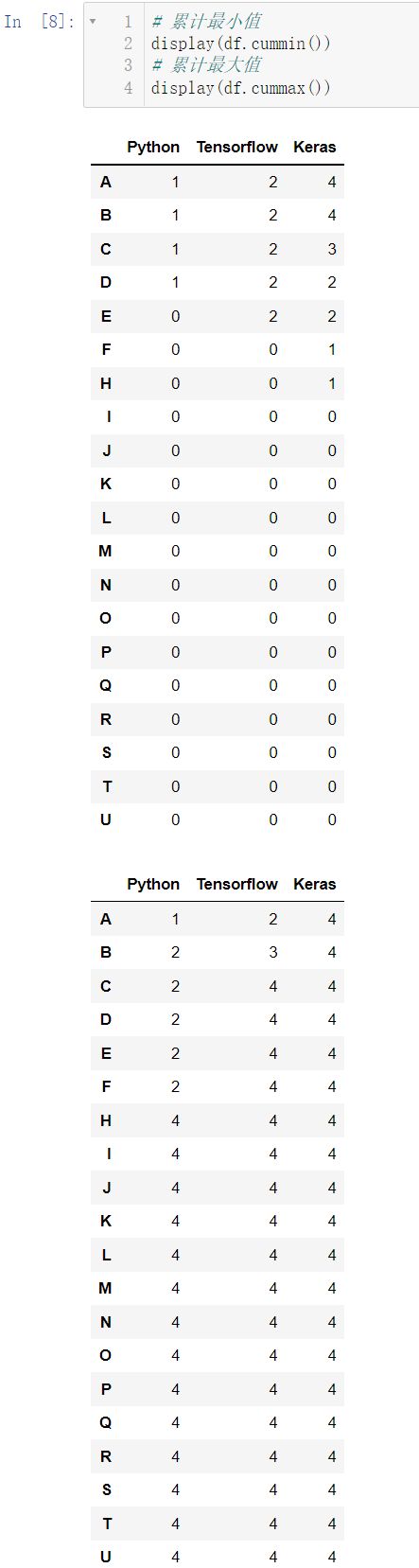
cummin() 的作用是累计最小值,即碰到更小的数后,该数往后所有数都变成这个更小的数,cummax() 的作用是累计最大值,即碰到更大的数后,该数往后所有的数都变成这个更大的数:
display(df.cummin())
display(df.cummax())
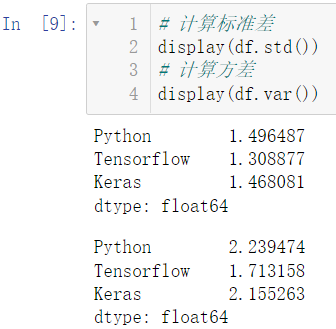
计算标准差调用 std(),计算方差调用 var()
display(df.std())
display(df.var())
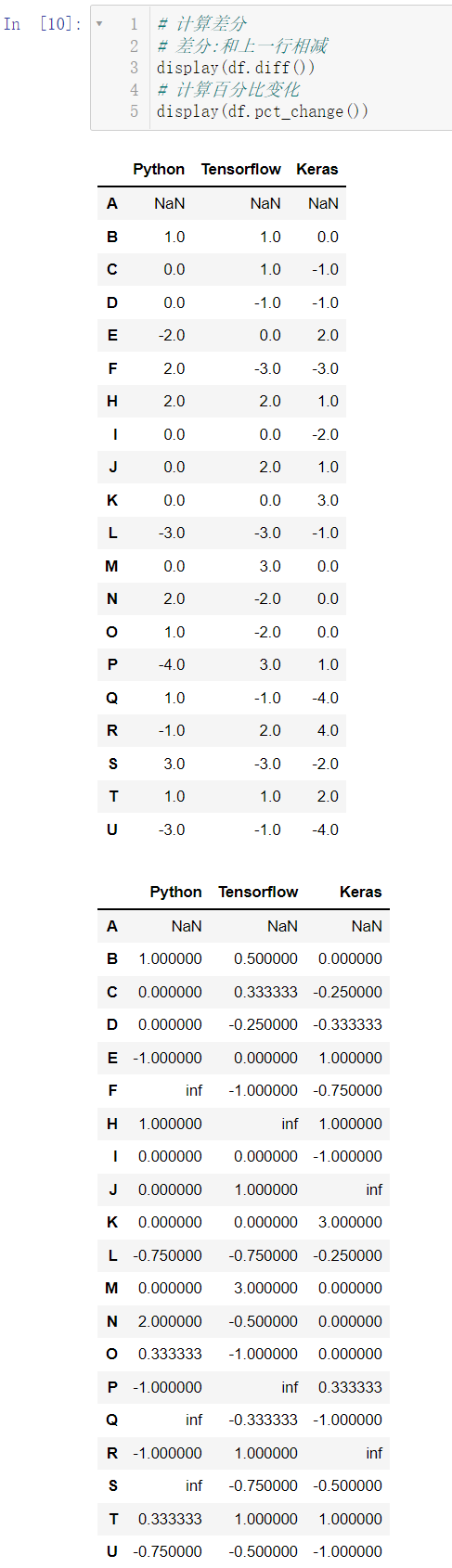
计算差分使用 diff(),差分就是这一行减上一行的结果,计算百分比的变化使用 pct_change():
display(df.diff())
display(df.pct_change())
2.4 高级统计指标
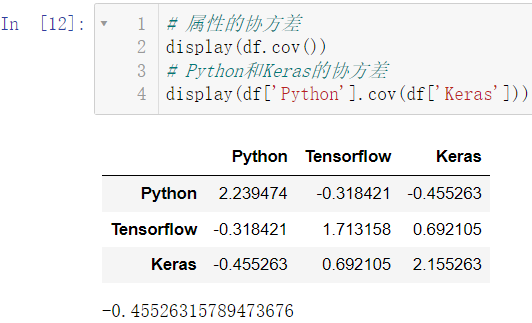
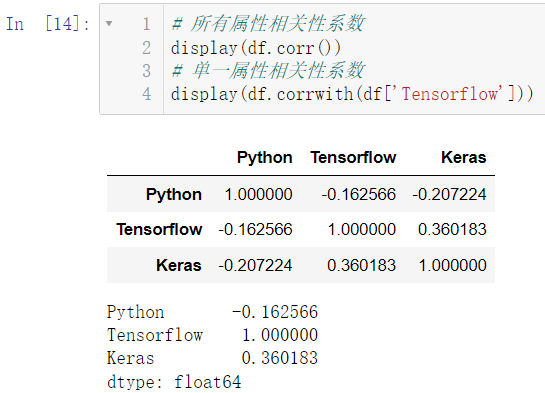
我们使用 cov() 和 corr() 用来分别计算协方差和相关性系数:
协方差:C o v ( X , Y ) = ∑ 1 n ( X i − X ‾ ) ( Y i − Y ‾ ) n − 1 Cov(X,Y) = \frac{\sum_{1}^{n}(X_i-\overline{X})(Y_i-\overline{Y})}{n-1}C o v (X ,Y )=n −1 ∑1 n (X i −X )(Y i −Y )
相关性系数:r ( X , Y ) = C o v ( X , Y ) V a r [ X ] V a r [ Y ] r(X,Y) = \frac{Cov(X,Y)}{\sqrt{Var[X]Var[Y]}}r (X ,Y )=V a r [X ]V a r [Y ]C o v (X ,Y )
display(df.cov())
display(df['Python'].cov(df['Keras']))
display(df.corr())
display(df.corrwith(df['Tensorflow']))
3.数据排序
创建数据
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 30, size = (30, 3)),
index = list('qwertyuioijhgfcasdcvbnerfghjcf'),
columns = ['Python', 'Keras', 'Pytorch'])
df
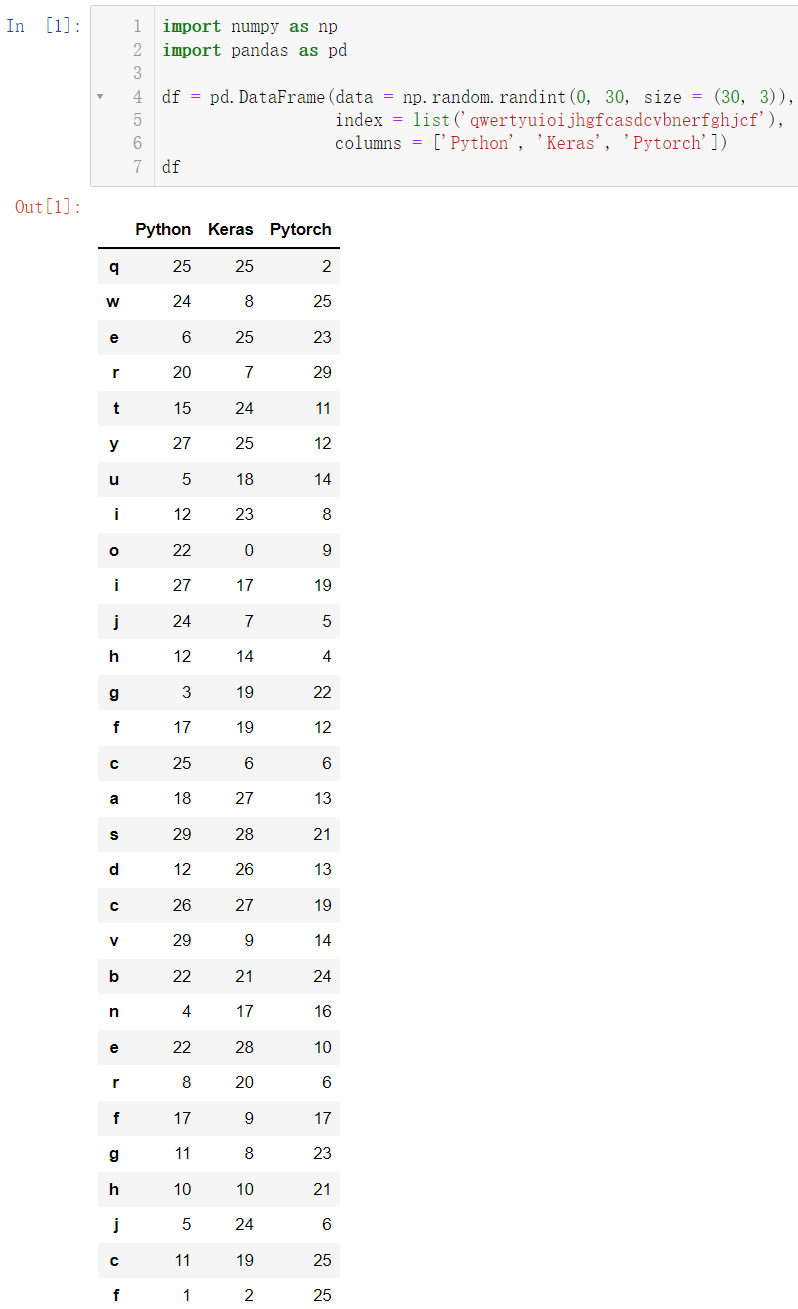
是一个看起来乱糟糟的数据,我们排序介绍三种方法
3.1 根据索引行列名进行排序
display(df.sort_index(axis = 0, ascending = True))
display(df.sort_index(axis = 1, ascending = False))
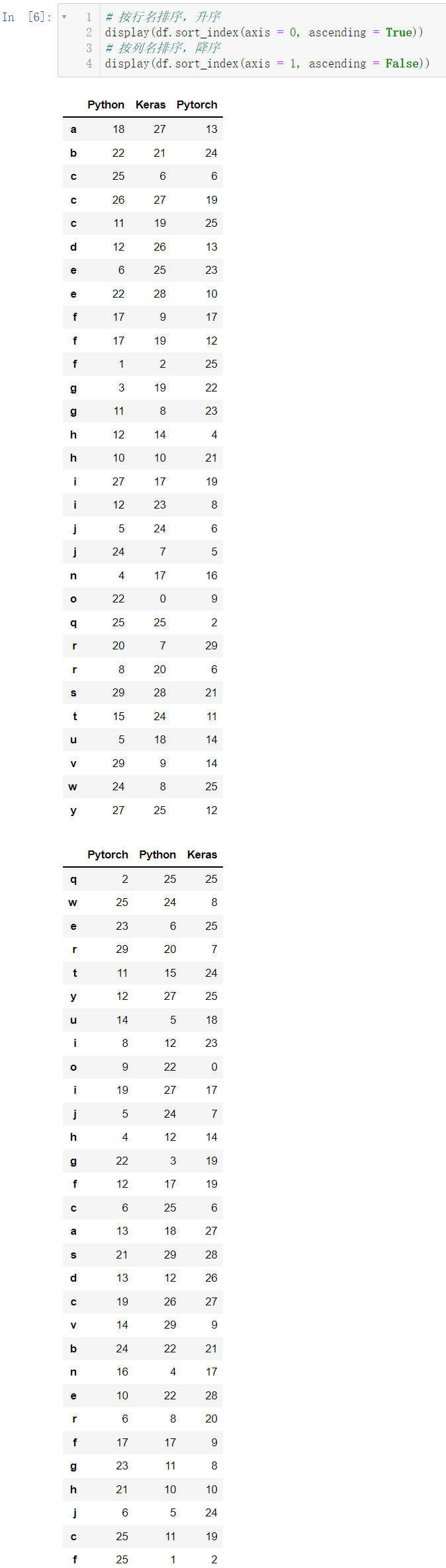
当然,按照索引行列名进行排序是不常用的,我们一般都是对数据进行排序
3.2 属性值排序
display(df.sort_values(by = ['Python']))
display(df.sort_values(by = ['Python', 'Keras']))
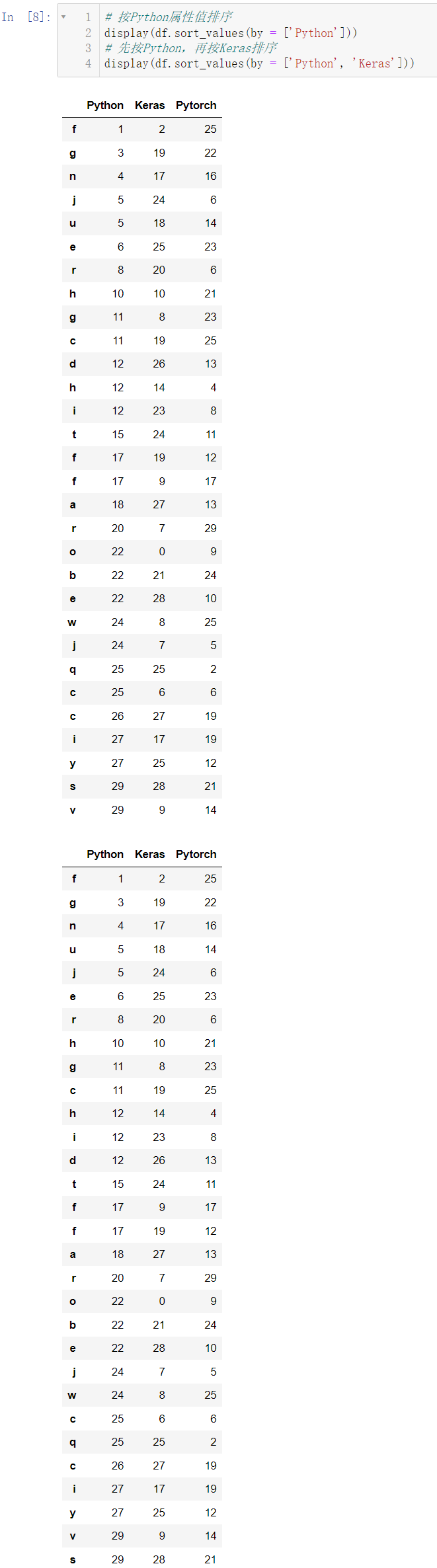
3.3 返回属性n大或者n小的值
display(df.nlargest(3, columns = 'Keras'))
display(df.nsmallest(5, columns = 'Python'))
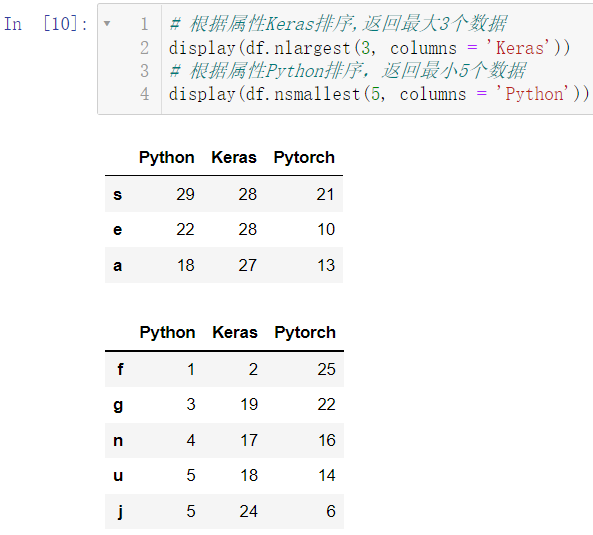
4.分箱操作
🚩分箱操作就是将连续数据转换为分类对应物的过程。比如将连续的身高数据划分为:矮中高。
分箱操作分为等距分箱和等频分箱。
分箱操作也叫面元划分或者离散化。
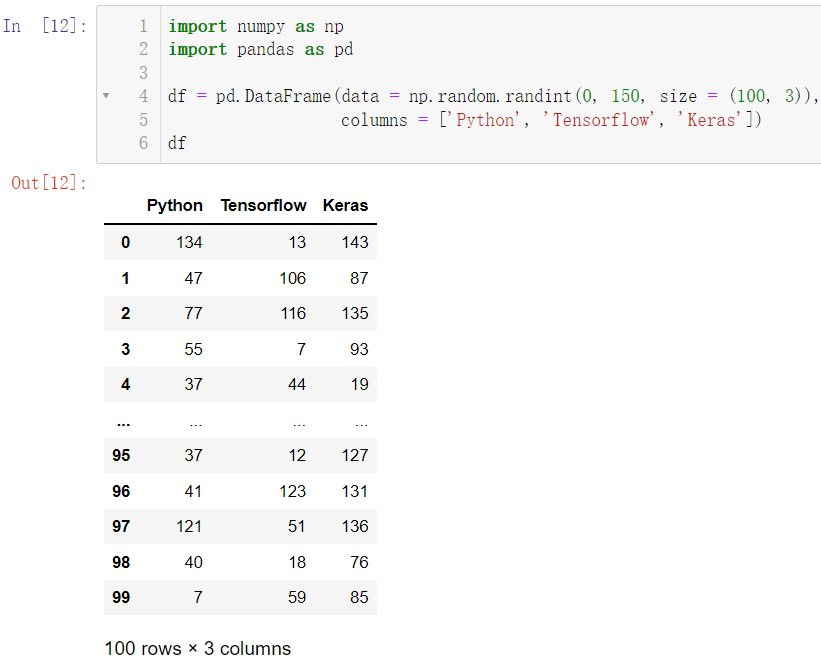
我们先来创建数据:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 150, size = (100, 3)),
columns = ['Python', 'Tensorflow', 'Keras'])
df
4.1 等宽分箱
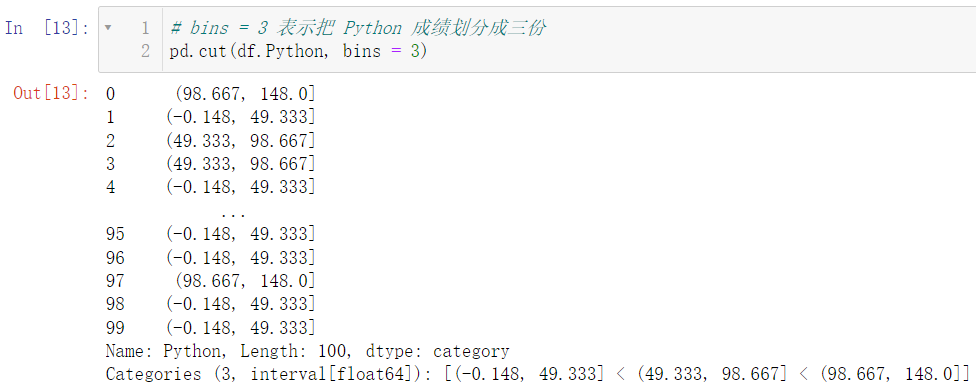
🚩等宽分箱在实际操作中意义不大,因为我们一般都会给一个特定的分类标准,比如高于 60 是及格,等分在生活中应用并不多
pd.cut(df.Python, bins = 3)
4.2 指定宽度分箱
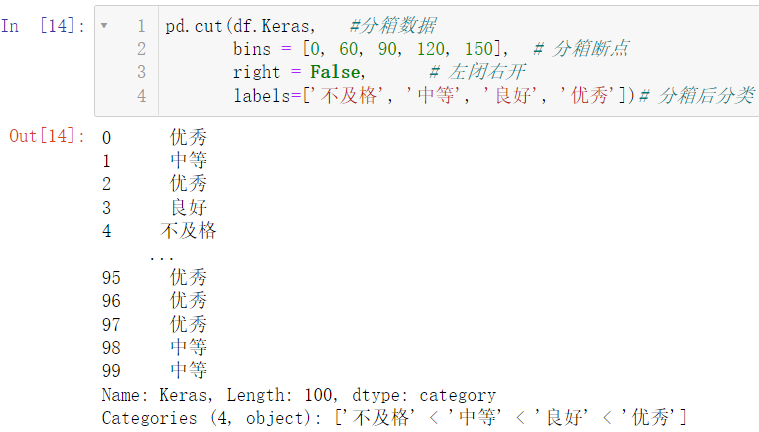
🚩下述代码就实现了自行定义宽度进行分箱操作,在下述带啊中,不及格是 [ 0 , 60 ) [0,60)[0 ,6 0 ),中等是 [ 60 , 90 ) [60, 90)[6 0 ,9 0 ),良好是 [ 90 , 120 ) [90, 120)[9 0 ,1 2 0 ),优秀是 [ 120 , 150 ) [120, 150)[1 2 0 ,1 5 0 ) 均为左闭右开,这个是由 right = False 设定的
pd.cut(df.Keras,
bins = [0, 60, 90, 120, 150],
right = False,
labels=['不及格', '中等', '良好', '优秀'])
4.3 等频分箱
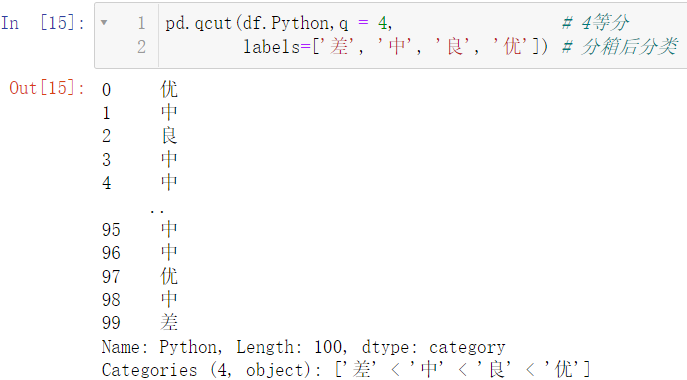
🚩等频分箱是按照大家的普遍情况进行等分的操作
pd.qcut(df.Python,q = 4,
labels=['差', '中', '良', '优'])
5.分组聚合
首先来创建数据:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = {'sex':np.random.randint(0, 2, size = 300),
'class':np.random.randint(1, 9, size = 300),
'Python':np.random.randint(0, 151, size = 300),
'Keras':np.random.randint(0, 151, size =300),
'Tensorflow':np.random.randint(0, 151, size = 300),
'Java':np.random.randint(0, 151,size = 300),
'C++':np.random.randint(0, 151, size = 300)})
df['sex'] = df['sex'].map({0:'男', 1:'女'})
df
5.1 分组
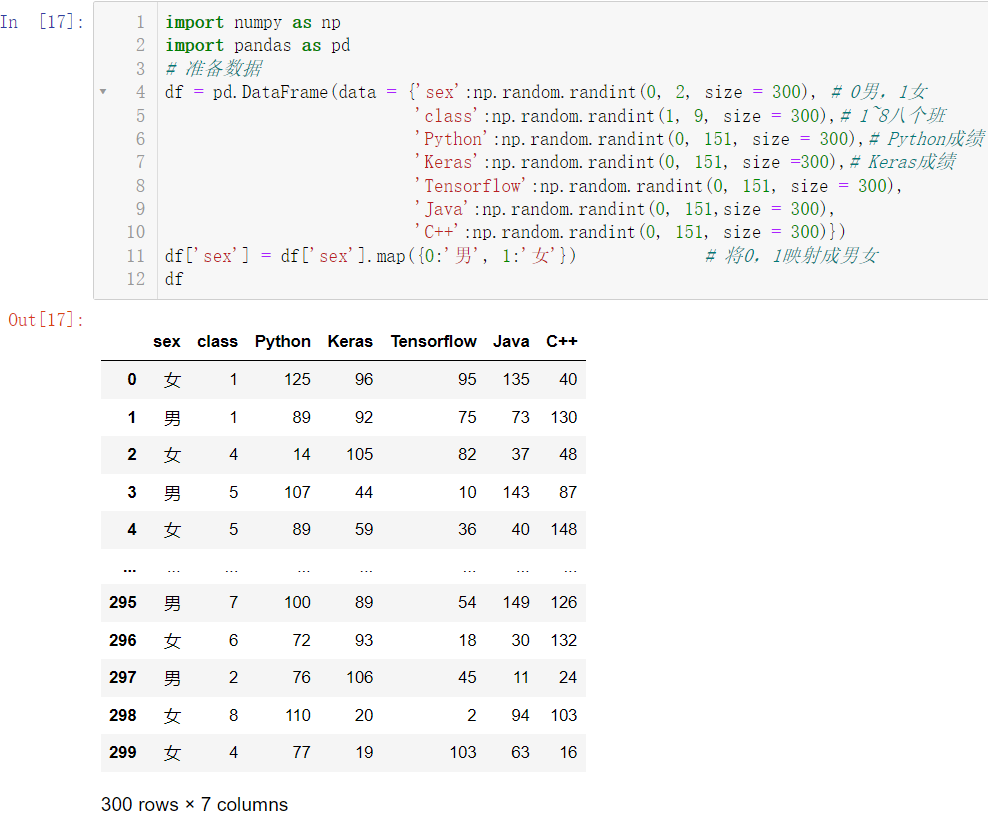
🚩根据性别分组并求出平均值,并把平均值保留一位小数:
df.groupby(by = 'sex').mean().round(1)
分组统计男女的数量:
df.groupby(by = 'sex').size()

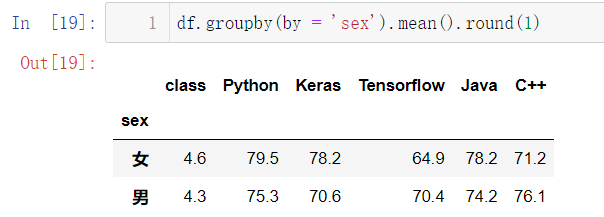
根据性别和班级两个属性进行分组:
df.groupby(by = ['sex', 'class']).size()
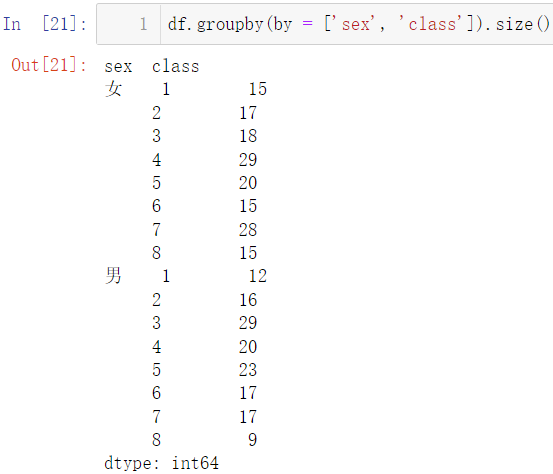
获取每个班,男生女生 P y t h o n , J a v a Python,Java P y t h o n ,J a v a 最高分
df.groupby(by = ['sex', 'class'])[['Python', 'Java']].max()

我们通过多层索引的思想对上述代码稍作调整:
df.groupby(by = ['class', 'sex'])[['Python', 'Java']].max()
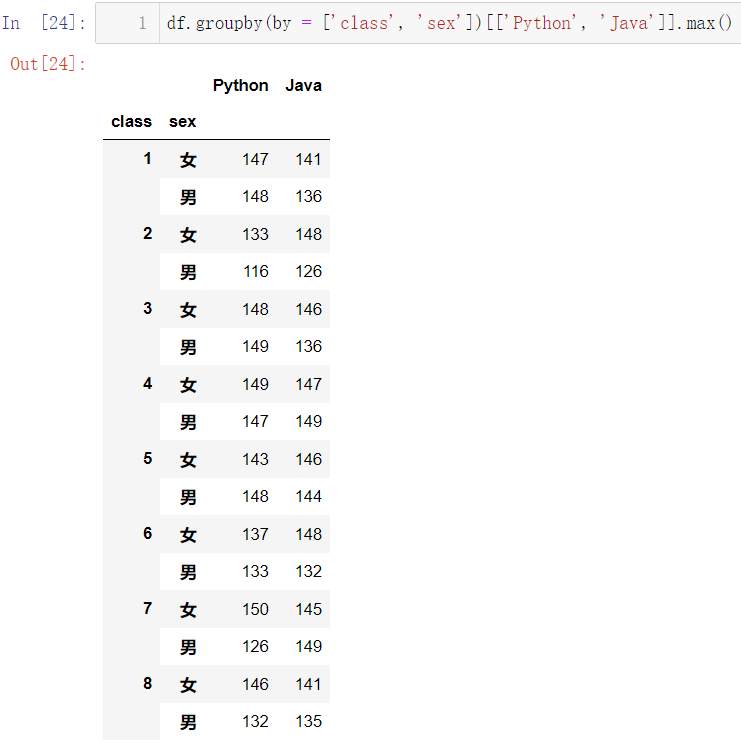
再用之前学过的数据重塑,又可以稍加变形:
df.groupby(by = ['class', 'sex'])[['Python', 'Java']].max().unstack()
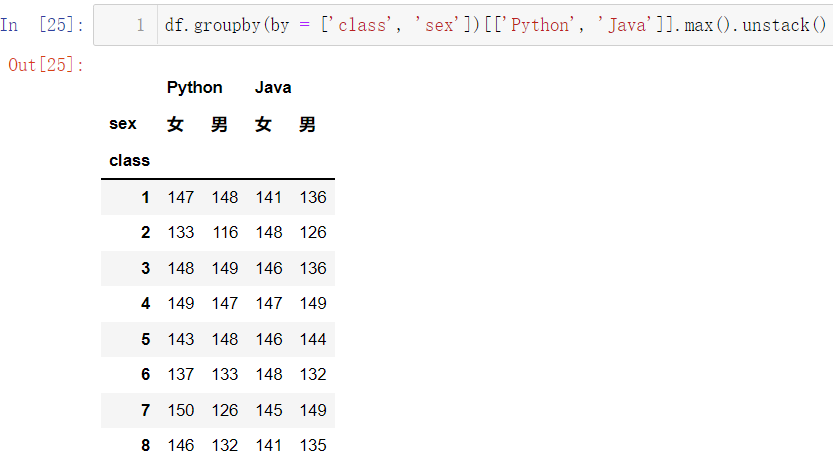
5.2 分组聚合apply、transform
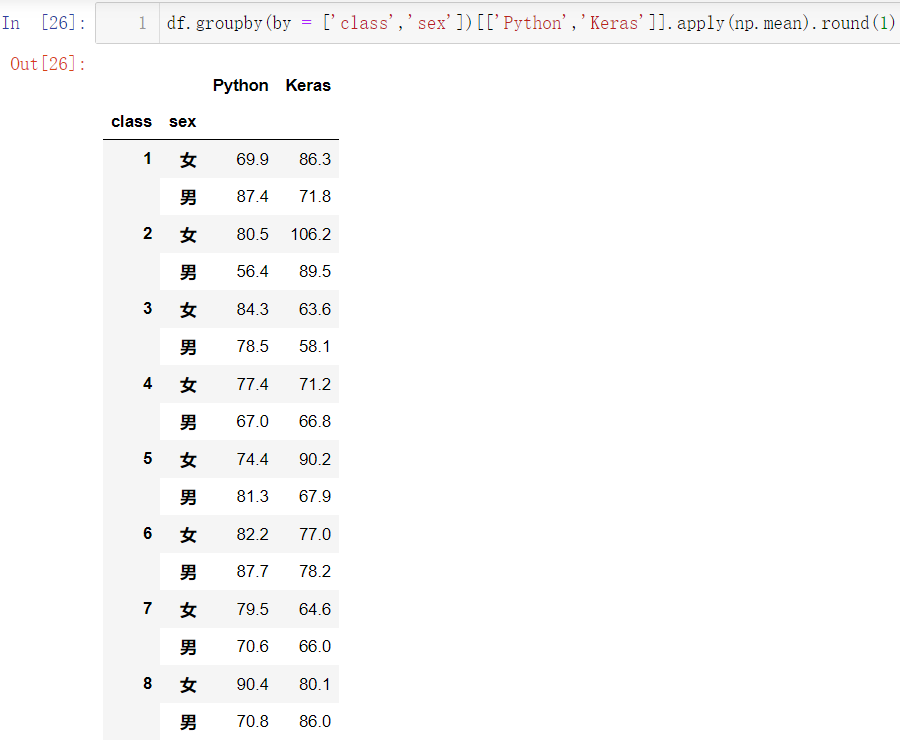
🚩a p p l y apply a p p l y 返回的是汇总后的情况,对于每一个分组大类都只返回一个结果:
df.groupby(by = ['class','sex'])[['Python','Keras']].apply(np.mean).round(1)
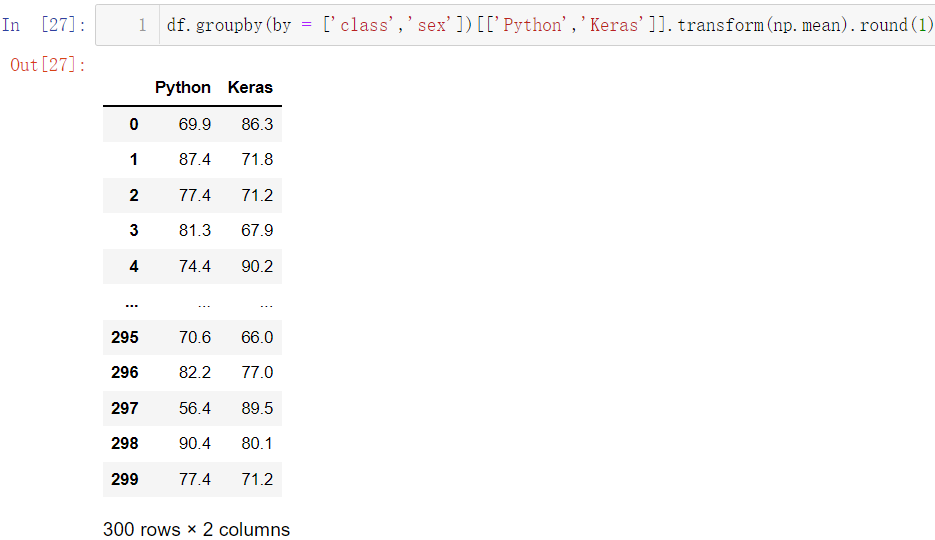
t r a n s f o r m transform t r a n s f o r m 是把所有的元素全部返回:
df.groupby(by = ['class','sex'])[['Python','Keras']].transform(np.mean).round(1)
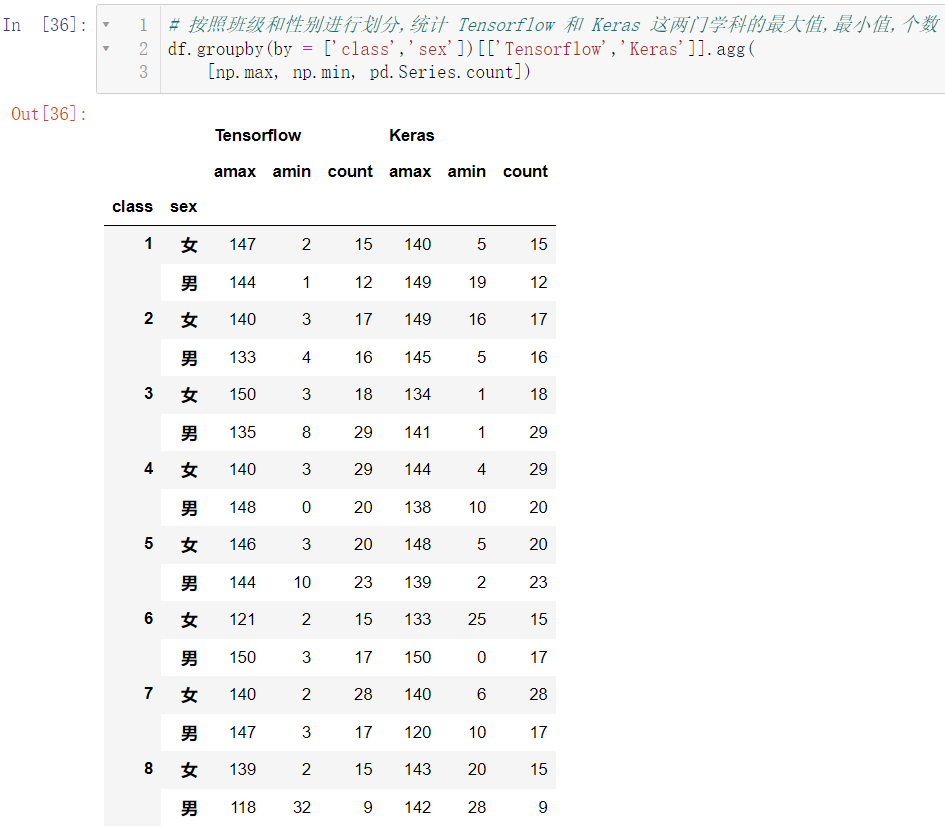
5.3 分组聚合agg
🚩agg 比起 apply 和 transform 来说,功能更加的强大
df.groupby(by = ['class','sex'])[['Tensorflow','Keras']].agg(
[np.max, np.min, pd.Series.count])
df.groupby(by = ['class','sex'])[['Python','Keras']].agg(
{'Python':[('最大值',np.max),('最小值',np.min)],
'Keras':[('计数',pd.Series.count),('中位数',np.median)]})

5.4 透视表pivot_table
🚩所谓透视,其实就是发现事物的一定规律
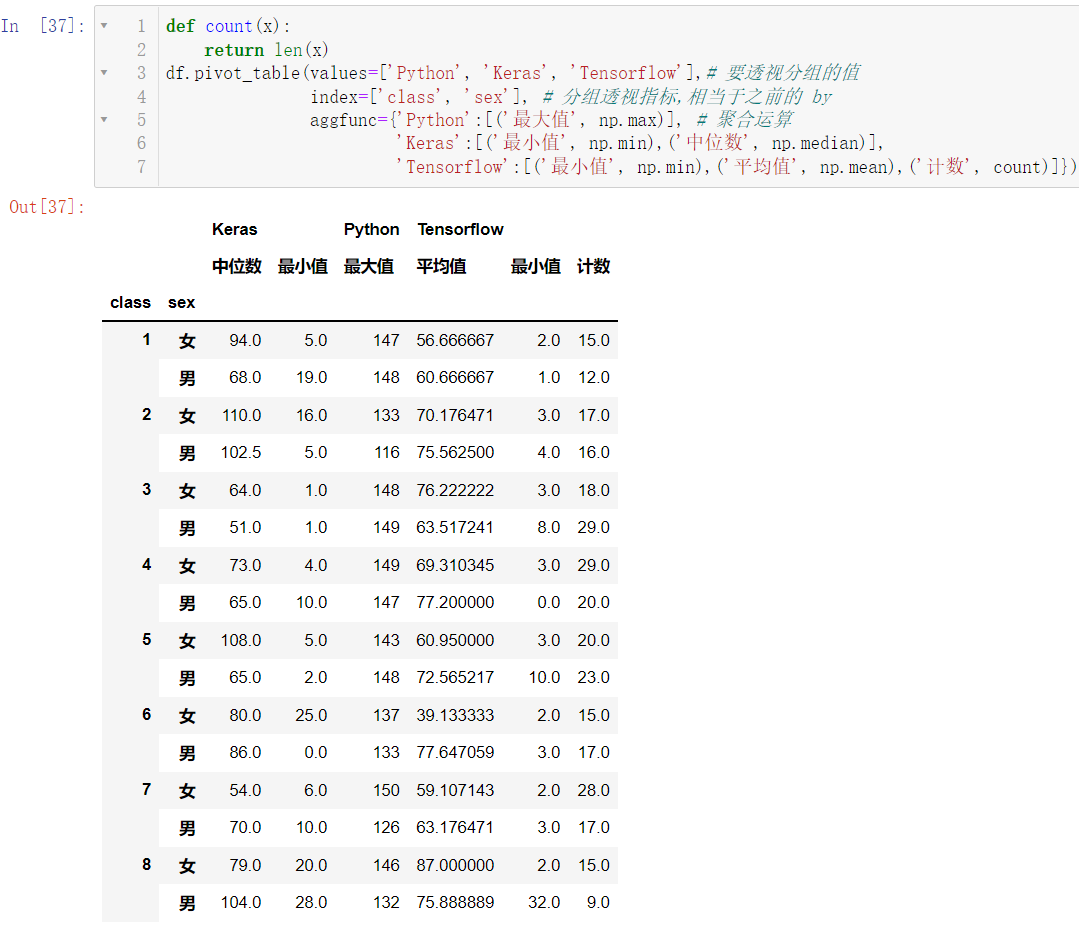
def count(x):
return len(x)
df.pivot_table(values=['Python', 'Keras', 'Tensorflow'],
index=['class', 'sex'],
aggfunc={'Python':[('最大值', np.max)],
'Keras':[('最小值', np.min),('中位数', np.median)],
'Tensorflow':[('最小值', np.min),('平均值', np.mean),('计数', count)]})
6.数据可视化
🚩修本章节之前需要安装 m a t p l o t l i b matplotlib m a t p l o t l i b,建议先修:matplotlib的安装教程以及简单调用
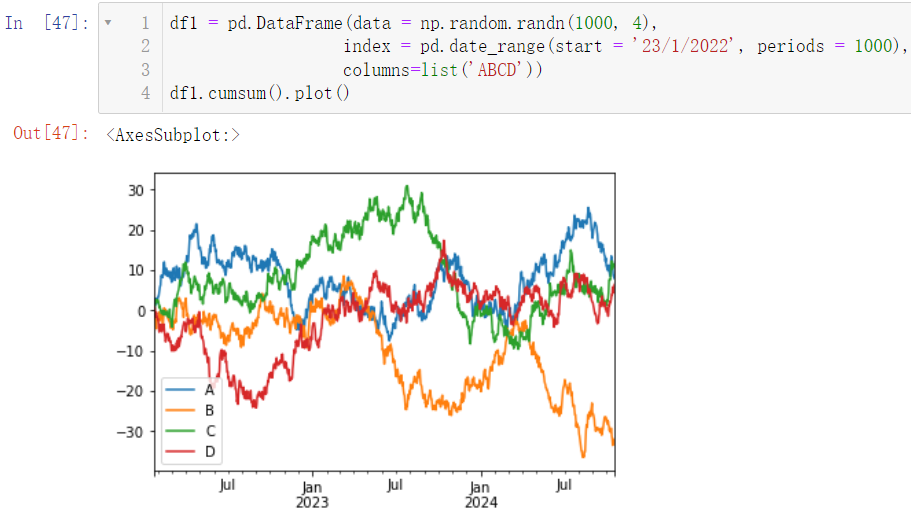
6.1 线形图
df1 = pd.DataFrame(data = np.random.randn(1000, 4),
index = pd.date_range(start = '23/1/2022', periods = 1000),
columns=list('ABCD'))
df1.cumsum().plot()
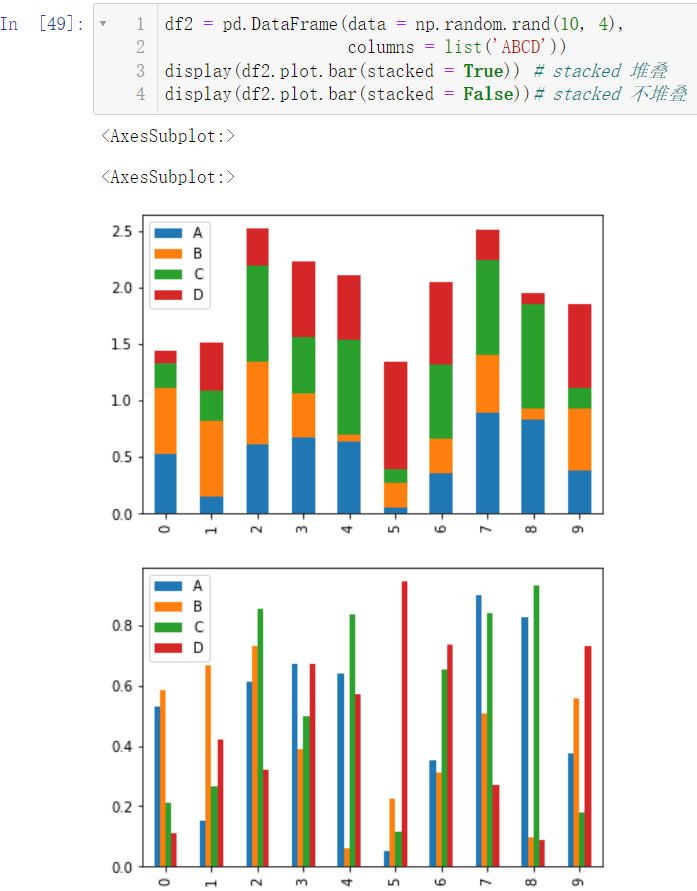
6.2 条形图
df2 = pd.DataFrame(data = np.random.rand(10, 4),
columns = list('ABCD'))
display(df2.plot.bar(stacked = True))
display(df2.plot.bar(stacked = False))
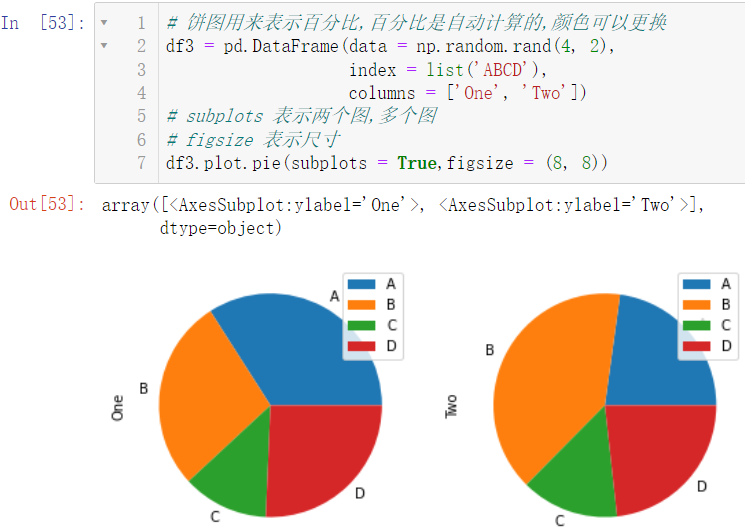
6.3 饼图
df3 = pd.DataFrame(data = np.random.rand(4, 2),
index = list('ABCD'),
columns = ['One', 'Two'])
df3.plot.pie(subplots = True,figsize = (8, 8))
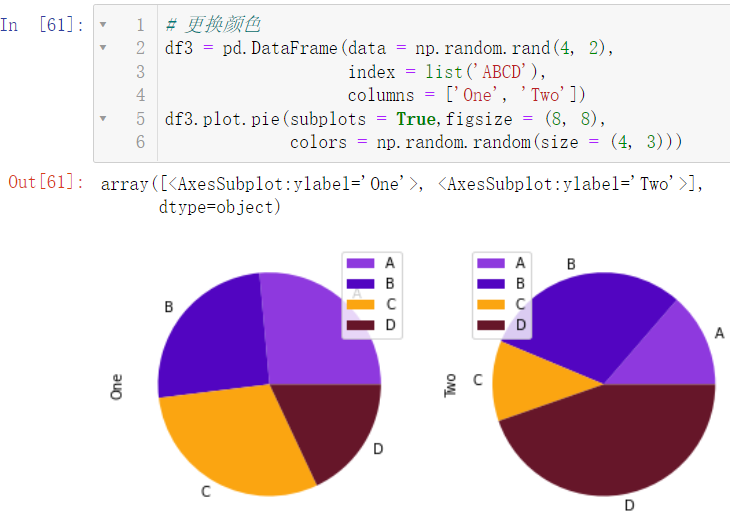
更换颜色:
df3 = pd.DataFrame(data = np.random.rand(4, 2),
index = list('ABCD'),
columns = ['One', 'Two'])
df3.plot.pie(subplots = True,figsize = (8, 8),
colors = np.random.random(size = (4, 3)))
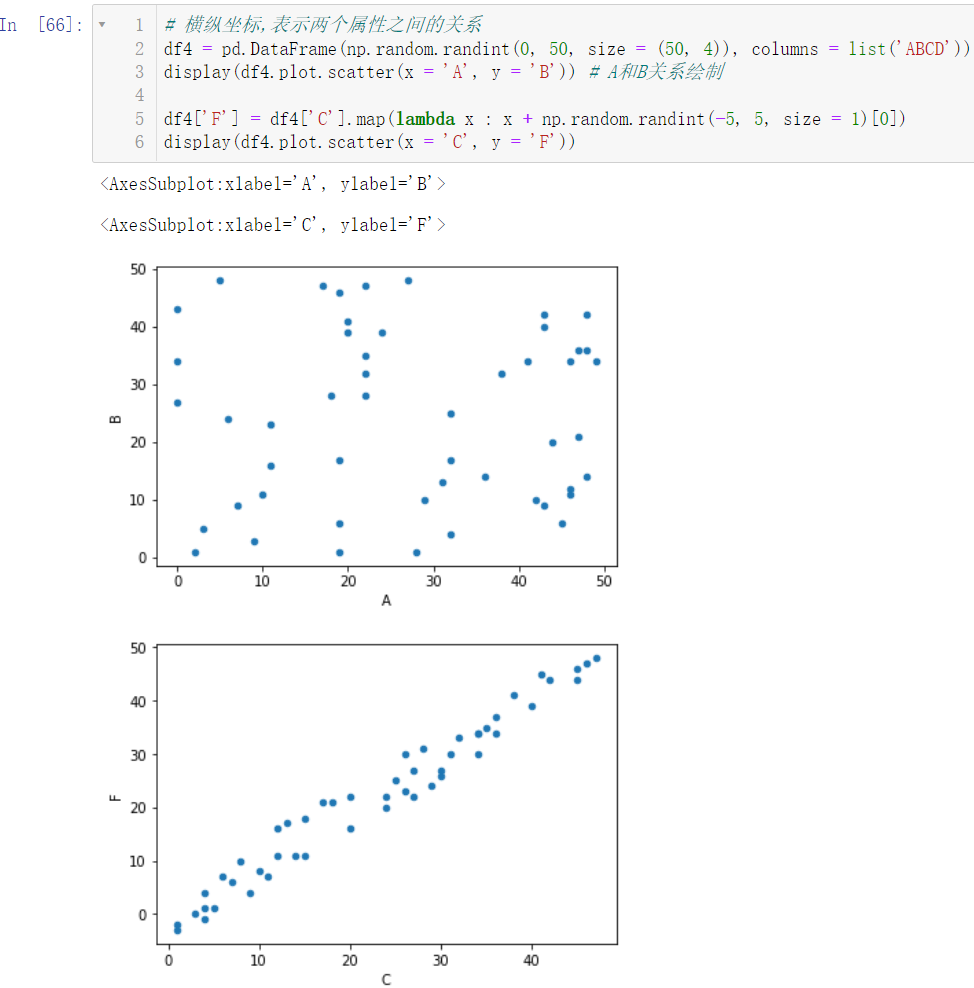
6.4 散点图
df4 = pd.DataFrame(np.random.randint(0, 50, size = (50, 4)), columns = list('ABCD'))
display(df4.plot.scatter(x = 'A', y = 'B'))
df4['F'] = df4['C'].map(lambda x : x + np.random.randint(-5, 5, size = 1)[0])
display(df4.plot.scatter(x = 'C', y = 'F'))
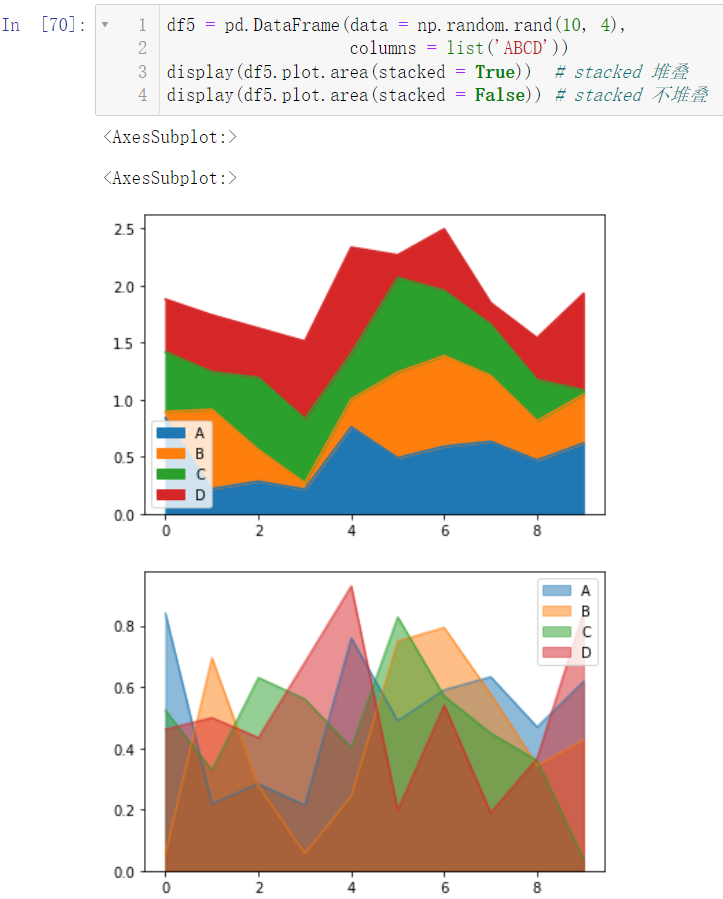
6.5 面积图
df5 = pd.DataFrame(data = np.random.rand(10, 4),
columns = list('ABCD'))
display(df5.plot.area(stacked = True))
display(df5.plot.area(stacked = False))
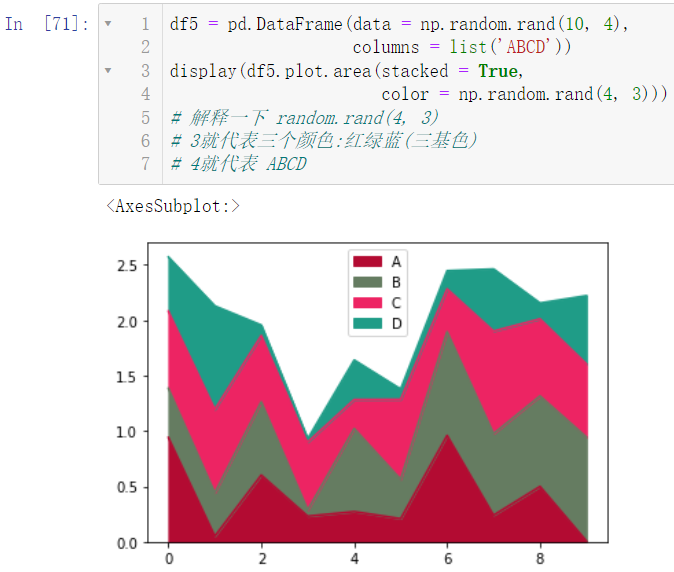
同样,我们可以调节它的颜色:
df5 = pd.DataFrame(data = np.random.rand(10, 4),
columns = list('ABCD'))
display(df5.plot.area(stacked = True,
color = np.random.rand(4, 3)))
7.训练场
首先我们需要下载一个 Excel 文件:
链接:https://pan.baidu.com/s/1gkEEH1yVA1RdaXTrFbw3ww?pwd=rm9t
提取码:rm9t
下载完成之后,把该文件和我们的代码放到同一个文件夹下,这一操作我们在之前的博客中已经反复说到,这里就不再进行演示
7.1 找到一班(名字后面跟的数字表示班级),获取班级将其男生1000米跑,成绩绘制线形图
import numpy as np
import pandas as pd
df = pd.read_excel('./分数汇总.xlsx', sheet_name = 0)
cnt = df['姓名'].str[3:].astype(np.int16) == 1
df2 = df[cnt]
s = df2['男1000米跑分数']
score = s.reset_index()[['男1000米跑分数']]
score.plot()
绘图虽然绘制出来了,但是报错一大堆,这是因为有中文的原因,我们接着继续处理:
接下来的处理方法涉及 m a t p l o t l i b matplotlib m a t p l o t l i b,属于超纲内容,可以不进行模拟,安装 m a t p l o t l i b matplotlib m a t p l o t l i b 见博文:matplotlib的安装教程以及简单调用
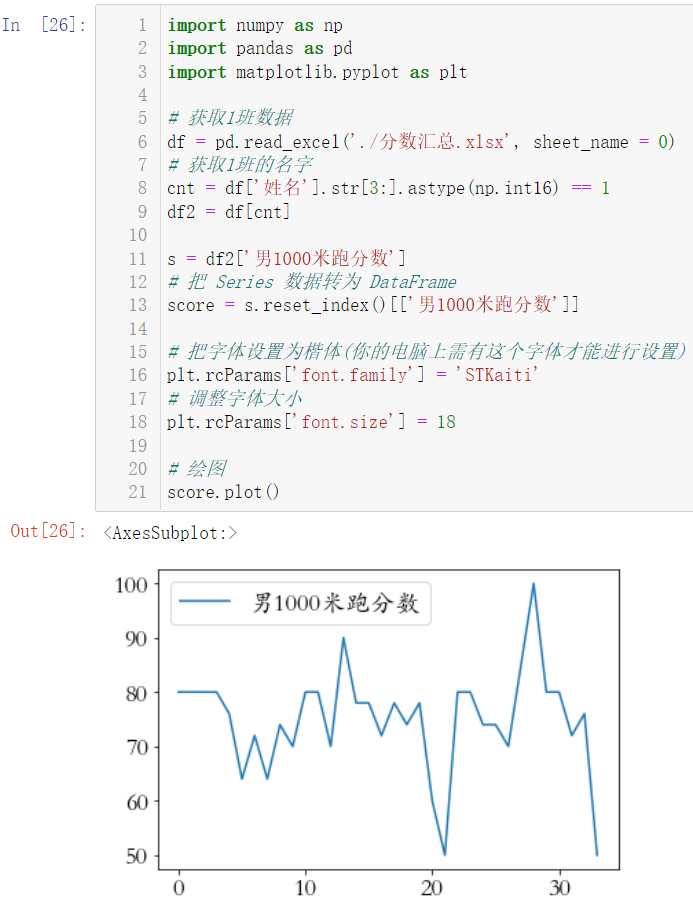
这是字体需要导包:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel('./分数汇总.xlsx', sheet_name = 0)
cnt = df['姓名'].str[3:].astype(np.int16) == 1
df2 = df[cnt]
s = df2['男1000米跑分数']
score = s.reset_index()[['男1000米跑分数']]
plt.rcParams['font.family'] = 'STKaiti'
plt.rcParams['font.size'] = 18
score.plot()
7.2 对各项体侧指标进行分箱操作:不及格(0~59)、及格(60~69)、中等(70~79)、良好(80~89)、优秀(90~100)
columns = df.columns
for col in columns:
if col.endswith('分数'):
df[col] = pd.cut(df[col], bins = [0, 60, 70, 80, 90, 101],
labels = ['不及格', '及格', '中等', '良好', '优秀'],
right = False)
df2 = pd.read_excel('./分数汇总.xlsx', sheet_name = 1)
columns = df2.columns
for col in columns:
if col.endswith('分数'):
df2[col] = pd.cut(df2[col], bins = [0, 60, 70, 80, 90, 101],
labels = ['不及格', '及格', '中等', '良好', '优秀'],
right = False)
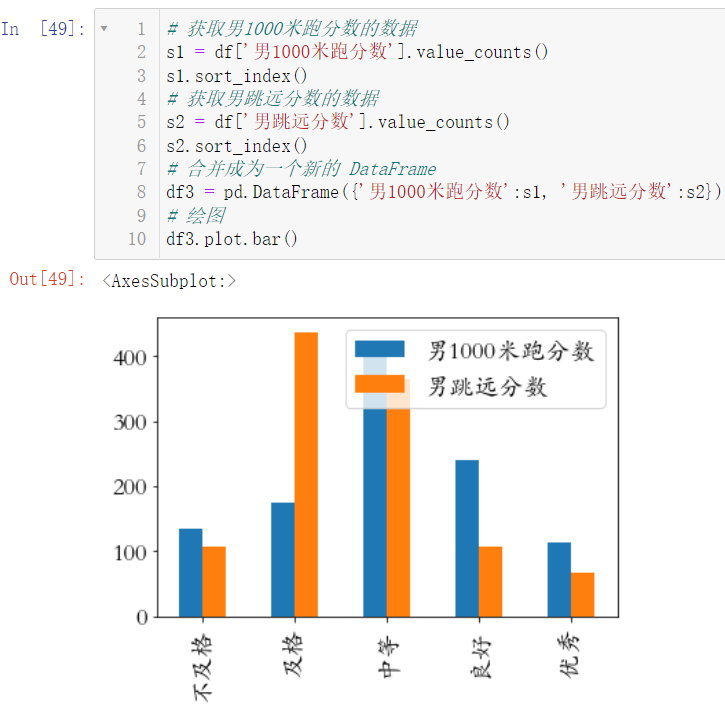
7.3 绘制全校男生1000米跑和男跳远的条形图(分箱操作后统计各个成绩水平数量)
s1 = df['男1000米跑分数'].value_counts()
s1.sort_index()
s2 = df['男跳远分数'].value_counts()
s2.sort_index()
df3 = pd.DataFrame({'男1000米跑分数':s1, '男跳远分数':s2})
df3.plot.bar()
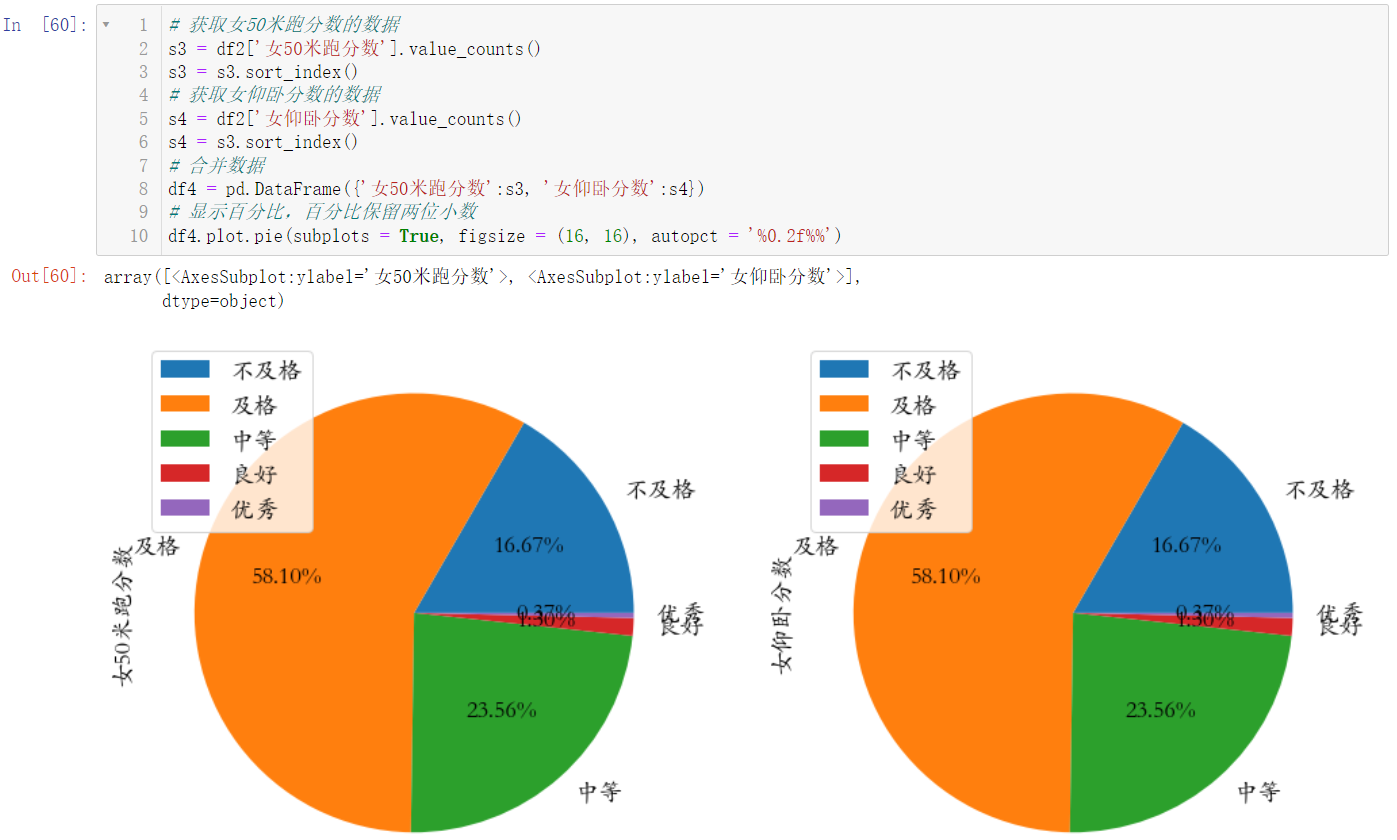
7.4 绘制全校女生50米跑和女仰卧的饼图(分箱操作后统计各个成绩水平的数量)
s3 = df2['女50米跑分数'].value_counts()
s3 = s3.sort_index()
s4 = df2['女仰卧分数'].value_counts()
s4 = s3.sort_index()
df4 = pd.DataFrame({'女50米跑分数':s3, '女仰卧分数':s4})
df4.plot.pie(subplots = True)

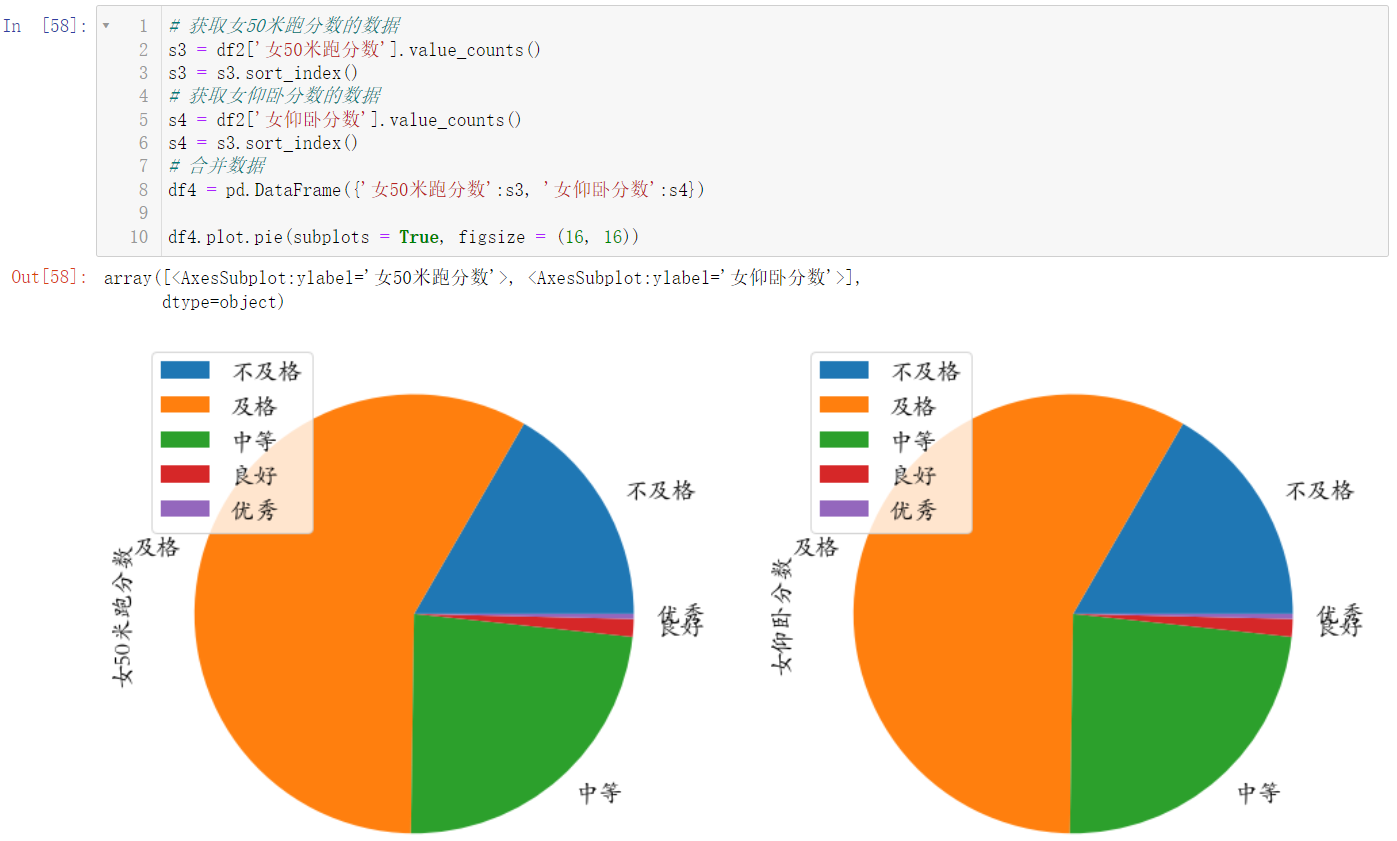
更改一下我们的图像尺寸:
s3 = df2['女50米跑分数'].value_counts()
s3 = s3.sort_index()
s4 = df2['女仰卧分数'].value_counts()
s4 = s3.sort_index()
df4 = pd.DataFrame({'女50米跑分数':s3, '女仰卧分数':s4})
df4.plot.pie(subplots = True, figsize = (16, 16))
显示各部分的百分比:
s3 = df2['女50米跑分数'].value_counts()
s3 = s3.sort_index()
s4 = df2['女仰卧分数'].value_counts()
s4 = s3.sort_index()
df4 = pd.DataFrame({'女50米跑分数':s3, '女仰卧分数':s4})
df4.plot.pie(subplots = True, figsize = (16, 16), autopct = '%0.2f%%')
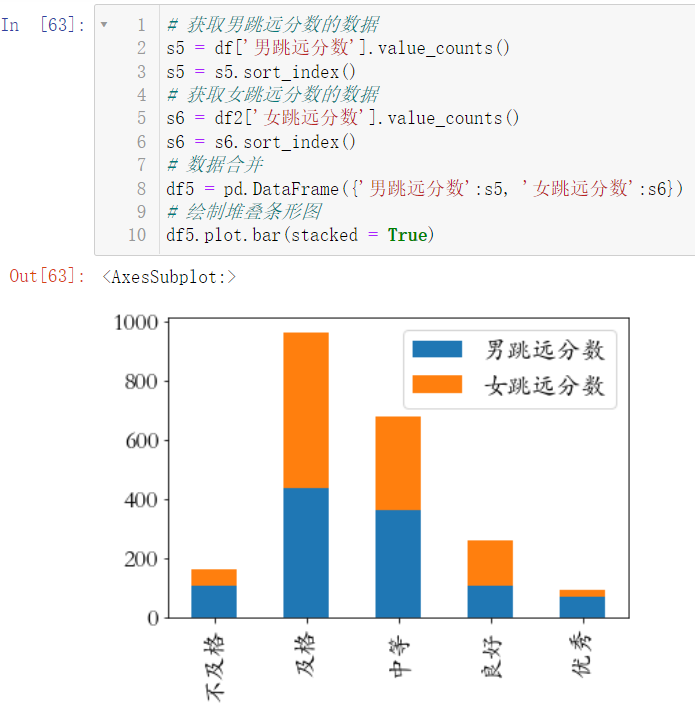
7.5 绘制男跳远、女跳远的堆叠条形图(分箱操作后统计各个成绩水平的数量)
s5 = df['男跳远分数'].value_counts()
s5 = s5.sort_index()
s6 = df2['女跳远分数'].value_counts()
s6 = s6.sort_index()
df5 = pd.DataFrame({'男跳远分数':s5, '女跳远分数':s6})
df5.plot.bar(stacked = True)
总结:pandas库的亮点
- 一个快速、高效的 DataFrame对象,用于数据操作和综合索引;
- 用于在内存数据结构和不同格式之间 读写数据的工具:CSV和文本文件、Microsoft Excel、SQL数据库和快速HDF 5格式;
- 智能 数据对齐和丢失数据的综合处理:在计算中获得基于标签的自动对齐,并轻松地将凌乱的数据操作为有序的形式;
- 数据集的 灵活调整和旋转;
- 基于智能标签的 切片、花式索引和大型数据集的 子集;
- 可以从数据结构中插入和删除列,以实现 大小可变;
- 通过在强大的引擎中 聚合或转换数据,允许对数据集进行拆分应用组合操作;
- 数据集的高性能 合并和连接;
- 层次轴索引提供了在低维数据结构中处理高维数据的直观方法;
- 时间序列-功能:日期范围生成和频率转换、移动窗口统计、移动窗口线性回归、日期转换和滞后。甚至在不丢失数据的情况下创建特定领域的时间偏移和加入时间序列;
- 对 性能进行了高度优化,用Cython或C编写了关键代码路径。
- Python与pandas在广泛的 学术和商业领域中使用,包括金融,神经科学,经济学,统计学,广告,网络分析,等等
- 学到这里,体会一会pandas库的亮点,如果对哪些还不熟悉,请对之前知识点再次进行复习。
Original: https://blog.csdn.net/qq_52156445/article/details/122549058
Author: 辰chen
Title: pandas从入门到进阶
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/696591/
转载文章受原作者版权保护。转载请注明原作者出处!