

数分基本流程:
一、数据载入、读取
二、数据预处理
三、数据转换
四、数据建模、计算、分析
五、结果可视化呈现
介绍
Python小白一枚,根据Datawhale小组引导文档完成Kaggle泰坦尼克任务,本文用来记录学到的知识点与一些心得。欢迎各位老师批评指正。参考书籍《利用Python进行数据分析》
一、数据载入
import numpy as np
import pandas as pd
import os
#相对路径载入数据
pd.read_csv('train.csv')
#如果相对路径载入报错,查看当前工作目录再进行载入
os.getcwd('train.csv')
#查看绝对路径工作目录并进行载入
path = os.path.abspath('train.csv')
pd.read_csv(path)
绝对路径中有中文会报错 “Initializing from file failed”,运行下列代码。文件名含有中文同理。
p = open(path)
df = ps.read_csv(p)
Numpy:以数组为对象进行计算的基础包,在数据处理时可以进行快速的向量化计算,也就是说以N(Ndarray)维数组为对象,无需编写循环程序遍历数组中的每一个元素,直接对所有数据进行矩阵计算。适合处理同质型的数值类数组数据。
Pandas:用来处理表格型或异质型数据,相较于Numpy,Pandas更多提供了针对特定场景的函数功能。
相对路径:相对于当前工作目录,文件位置的路径。
绝对路径:完整描述文件位置的路径。
‘.csv’和’.tsv’
‘.csv’文件以半角逗号作为字段值的分隔符,’.tsv’文件以制表符作为字段值的分隔符
pd.read_csv()和pd.read_table()
read_csv()读取以’ , ‘分隔的文件到DataFrame
read_table()读取以制表符’ /t ‘分隔的文件到DataFrame
在read_table()通过设置sep参数,以达到同样的效果
pd.read_table(‘train.csv’, sep=’,’) = pd.read_csv(‘train.csv’)
#每1000行作为一个数据模块,逐块读取
chunker = pd.read_csv('train.csv',chunksize=1000)
#chunker数据类型
print(type(chunker))


#用for循环打印
for chunker in df:
print(chunker)
逐块读取:数据量过大的时候,可以将数据按照chunksize作为每一块的行数分块读取数据,最终返回一个TextParser对象。TextParser允许根据chunksize遍历数据,将每行出现的’Key’所出现的次数作为Series的一个元素,然后再对Series进行处理。
二、数据预处理
1、英文列名表头替换成中文
df = pd.read_csv('train.csv', names=['乘客ID','是否幸存','仓位等级','姓名','性别','年龄'
,'兄弟姐妹个数','父母子女个数','船票信息','票价','客舱','登船港口'],index_col='乘客ID',header=0)
df.head()
其他方法
df = pd.read_csv('train.csv')
df.columns = ['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐妹个数'
,'父母子女个数','船票信息','票价','客舱','登船港口']
df.set_index(['乘客ID',inplace=True])
df.rename(columns={'PassengerId':'乘客ID','Survived':'是否幸存'
,'Pclass':'乘客等级(1/2/3等舱位)','Name':'乘客姓名','Sex':'性别','Age':'年龄'
,'SibSp':'堂兄弟/妹个数','Parch':'父母与小孩个数','Ticket':'船票信息'
,'Fare':'票价','Cabin':'客舱','Embarked':'登船港口'},inplace=True)
df.set_index(['乘客ID',inplace=True])
2、观察数据
要对数据的整体结构和样例进行概览,比如说,数据大小、有多少列,各列都是什么格式的,是否包含null等
#查看数据基本信息
df.info()
#观察表格前10行的数据
df.head(10)
#观察表格后15行的数据
df.tail(15)
#判断数据是否为空,为空的地方返回True,其余地方返回False
df.isnull().head()
[总结]可以从哪些方面对数据进行观察
#查看数据基本信息
df.info()
#观察表格前n行的数据
df.head(n)
#观察表格后n行的数据
df.tail(n)
#观察数组的结构
df.shape()
#判断数据是否为空,为空的地方返回True,其余地方返回False
df.isnull().head()
#数值型数据8数概括/非数值型数据独立元素个数、频数最大类别
df.describe()
#直方图
#箱线图
#非数值型数据频数
df.value_counts()
#非数值型数据占比
df = pd.DataFrame(df.value_counts())
df = pd.DataFrame(df.value_counts()).reset_index()
df['rate'] = df[0]/df[0].sum()
#***观察集中趋势***
#平均数
df.mean()
#中位数
df.median()
#众数
df.value_counts()
#观察数据分布:对称、偏左、偏右
#***观察离散趋势***
#标准差
df.std()
#方差
df.var()
#极差
df.max()-df.min()
#偏度
df.skew()
#峰度
df.kurtosis()
#保存数据
df.to_csv('train_chinese.csv')
Pandas基础
1、Pandas中有两个数据类型DateFrame和Series
Series:是带标签的 一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据。轴标签统称为 索引。
s = pd.Series(data, index=index)
字典、单个数组,多维数组,标量值都可以构建Series。
通过values属性和index属性分别获得Series对象的由值组成的数组和索引
DataFrame:是由多种类型的列构成的而为标签数据结构,既有行索引也有列索引。每一列可以是不同的值类型。也可以被视为一个共享相同索引的Series的字典。
一维ndarry、字典、列表;二维numpy.ndarray;Series都可以构建DataFrame。
#查看DataFrame数据的每列的名称
df.columns
#查看"Cabin"这列的所有值
#第一种
df.Cabin
#第二种
df['Cabin']
#删除某一列
#第一种
del test_1['a']
#第二种
test_1.pop('a')
#第三种
test_1.drop(['a'],axis=1,inplace=True)
#隐藏某几列
test_1.drop(['a','b','c'],axis=1)
axis=0表示第一维度,axis=1表示第二维度,以此类推(是几维数组就有几个维度)
test_1.drop([‘a’],axis=1)表名沿着第二维度将列a删除test_1.drop([‘a’],axis=1,inplace=True)inplace默认False,最终只返回一个副本,DataFrame并没有更改。inplace=True时,在DataFrame上直接进行更改。
2、数据的筛选
#以"Age"为筛选条件,显示年龄在10岁以下的乘客信息。
df[df['Age']10) & (df['Age']10)|(df['Age']
#将midage的数据中第100行的"Pclass"和"Sex"的数据显示出来
midage.loc[[100],['Pclass','Sex']]
因为midage是筛选后的dataframe,轴标签不再是依此递增。以上做法错误。
midage = midage.reset_index(drop=True)
reset_index()可以重置索引。
drop默认False,重置后原先的索引变成了数据本身的一列
drop=True,重置后,原先的索引被删除(取代)
#使用loc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
midage.loc[[100,105,108],['Pclass','Name','Sex']]
#使用iloc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
midage.iloc[[100,105,108],[2,3,4]]
loc是根据index来索引,iloc的列参数只能用整数来取数。
探索性数据分析
1、基础知识
1.1、数据排序
#构建一个都为数字的DataFrame数据
#第一种
frame = pd.DataFrame(np.random.randn(3,4),index=list('312'),columns=list('bdac'))
#第二种
frame = pd.DataFrame(np.arange(12).reshape((3,4)),index=list('312'),columns=list('bdac'))
[总结]不同的排序方式
让行索引升序排序
frame.sort_index()
让行索引降序排序
frame.sort_index(ascending=False)
让列索引升序排序
frame.sort_index(axis=1)
让列索引降序排序
frame.sort_index(axis=1,ascending=False)
#根据某列的值升序排序
frame.sort_values('a')
frame.sort_values(by='c')
任选两列数据同时降序排序
frame.sort_values(by=['a', 'c'], ascending=False)
1.2、算术计算,计算两个DataFrame数据相加结果
frame1 = pd.DataFrame(np.random.randn(3,4),index=list('312'),columns=list('bdac'))
frame1
frame2 = pd.DataFrame(np.random.randn(3,3),index=list('312'),columns=list('abc'))
frame2
frame1+frame2

两个DataFrame相加后,会返回一个新的DataFrame,对应的行和列的值会相加,没有对应的会变成空值NaN。
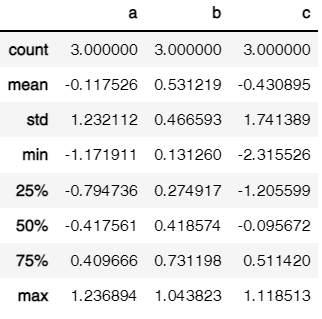
1.3、describe()函数查看数据基本统计信息
frame.describe()
2、项目实操
2.1、导入numpy、pandas包和数据
2.2、对泰坦尼克号数据(trian.csv)按票价和年龄两列进行综合排序(降序排列),从数据中你能发现什么
df.sort_values(by=['票价','年龄'],ascending=False)
优先排票价,再排年龄
按票价排序前50人有37人幸存,按年龄排序前50人有16人幸存
排除空值,可以进一步观察后五十人的幸存状况,进而分析能否幸存与年龄或票价是否有关系
2.3、通过泰坦尼克号数据如何计算出在船上最大的家族有多少人?
max(df['兄弟姐妹个数'] + df['父母子女个数'])
2.4、分别看看泰坦尼克号数据集中 票价、父母子女 这列数据的基本统计数据,你能发现什么?
df['票价'].describe()
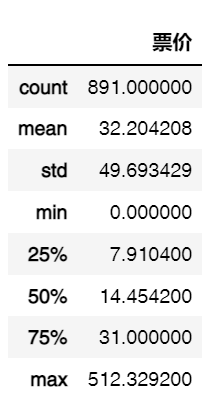
标准差约为49.69,说明票价波动特别大;75%的人的票价低于31.00, 票价最大值约为512.33,说明高票价的乘客非常少,因为每个几个区间的乘客不是均匀分布,那么,之前分析票价与幸存率可能存在关系的分析方向是否正确?
df['父母子女个数'].describe()
Original: https://blog.csdn.net/weixin_47754374/article/details/122425727
Author: 哇塞小夏
Title: 学习笔记 — Datawhale数据分析入门Task01
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/696338/
转载文章受原作者版权保护。转载请注明原作者出处!