

一、 KNN 算法
1.1 概述
- KNN(全称K Nearest Neighbors)可以说是最简单的分类算法之一,同时,它也是最常用的分类算法之一。
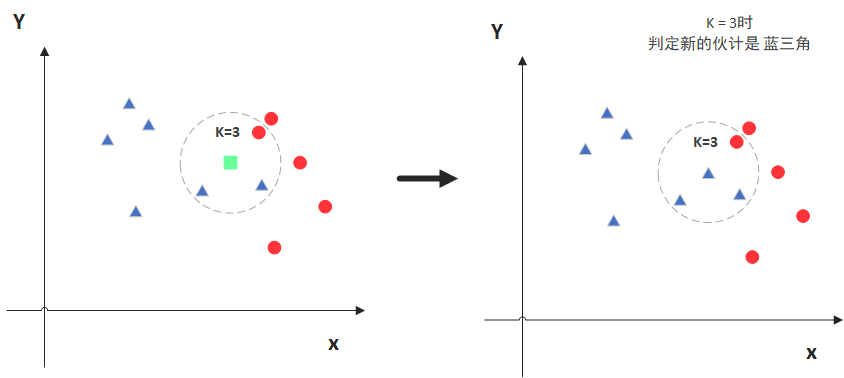

绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
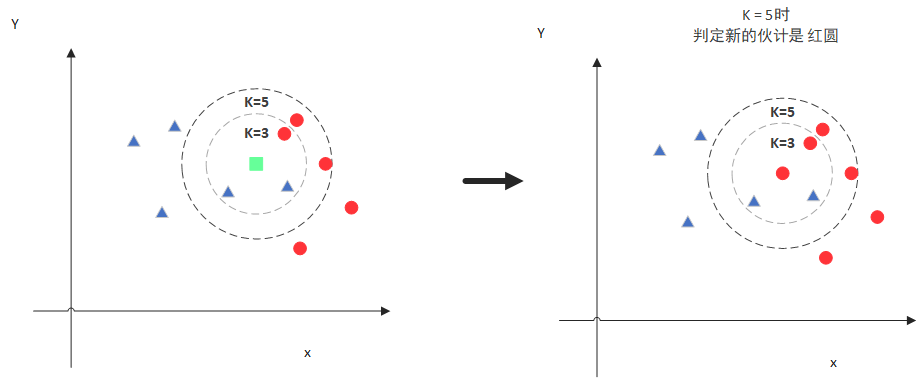
当K=5的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿点被归类成红圆。从这个例子中,我们就能看得出K的取值是很重要的。
; 1.2 细节
影响以上算法的有三个因素: K值的选取、 距离的确定和 距离的权重。
1.2.1 K值的选取
根据上面的图可以知道K值的选取决定决策的结果,但是具体选哪个K值没有相应的理论。
如果k值比较小,相当于我们在较小的领域内训练样本对实例进行预测。这时,算法的近似误差(Approximate Error)会比较小,因为只有与输入实例相近的训练样本才会对预测结果起作用。
但是,它也有明显的缺点:算法的估计误差比较大,预测结果会对近邻点十分敏感,也就是说,如果近邻点是噪声点的话,预测就会出错。因此,k值过小容易导致KNN算法的过拟合。
同理,如果k值选择较大的话,距离较远的训练样本也能够对实例预测结果产生影响。这时候,模型相对比较鲁棒,不会因为个别噪声点对最终预测结果产生影响。但是缺点也十分明显:算法的近邻误差会偏大,距离较远的点(与预测实例不相似)也会同样对预测结果产生影响,使得预测结果产生较大偏差,此时模型容易发生欠拟合。
一般是采用交叉验证的方式选取一个比较理想的K值。
1.2.2 距离的确定
样本空间内的两个点之间的距离量度表示两个样本点之间的相似程度:距离越短,表示相似程度越高;反之,相似程度越低。
闵可夫斯基距离:
对于n维空间中的两个点x = ( x 1 , x 2 , … , x n ) T x=(x_1,x_2,…,x_n)^T x =(x 1 ,x 2 ,…,x n )T和y = ( y 1 , y 2 , ⋯ , y n ) T y=(y_1,y_2,\cdots,y_n)^T y =(y 1 ,y 2 ,⋯,y n )T,x x x和y y y之间的闵可夫斯基距离可以表示为:
d x y = ( ∑ i = 1 n ( x i − y i ) p ) 1 p d_{xy}=(\sum_{i=1}^n (x_i-y_i)^p)^{\frac{1}{p}}d x y =(i =1 ∑n (x i −y i )p )p 1
其中,p是一个可变参数:
- 当p=1时,被称为曼哈顿距离;
- 当p=2时,被称为欧氏距离;
- 当p=∞ \infty ∞时,被称为切比雪夫距离。
1.2.3 距离的权重
当确定好距离后,要判断输入变量x x x所属的类y y y,就要找出距离x x x最近的k k k个点,用N k ( x ) N_k(x)N k (x )表示这k k k个点,通常来说,这k k k个点中哪一类的最多,x x x就属于哪一类。这种思考意味着不论远近,N k ( x ) N_k(x)N k (x )中所有的点对判断x x x属于哪一类的影响都一样。
但实际中,距离的远近对x x x的影响还是有区别的,又是距离更近的点更加重要。一般情况下设置权重和距离成反比,距离预测目标越近具有越高的权重。然后计算每一类所占的权重。
1.3 代码实现
接下来利用代码实现一个简单的 KNN算法。
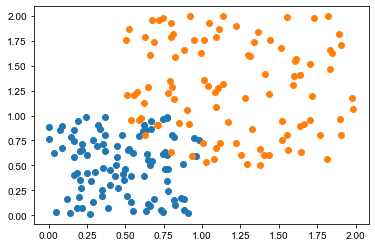
- 生成数据:
import numpy as np
import matplotlib.pyplot as plt
X_1=np.random.normal(0,2,(50,2))
X_2=np.random.normal(0,4,(50,2))
plt.scatter(X_1[:,0],X_1[:,1])
plt.scatter(X_2[:,0],X_2[:,1])
- 整合数据,划分训练集和测试集
y=np.repeat([0,1],50)
X=np.vstack([X_1,X_2])
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =train_test_split(X, y, random_state=2022,test_size=0.2, shuffle=True)
关于 train_test_split的文档 。
* 根据训练集中的数据预测测试集中的标签,并和真实标签进行比较。
def getDistance(x,y):
return np.sqrt((x[0]-y[0])**2+(x[1]-y[1])**2)
def kNN(X_train,y_train,X_test,y_test,K):
indexs=[]
distances=[]
y_test_hats=[]
for i in np.arange(len(X_test)):
for j in np.arange(len(X_train)):
d=getDistance(X_test[i],X_train[j])
if(len(indexs)==7):
if(d<np.argmax(distances)):
index=np.argmax(distances)
indexs[index]=j
distances[index]=d
else:
indexs.append(j)
distances.append(d)
y_s=y_train[index]
y_test_hat=0 if np.sum(y_s==0)>np.sum(y_s==1) else 1
y_test_hats.append(y_test_hat)
accuracy=np.sum(y_test_hats==y_test)/len(y_test_hats)
return (accuracy,y_test_hats)
accuracy,y_test_hats=kNN(X_train,y_train,X_test,y_test,3)
print(accuracy)
1.4 sklearn 包中的KNN算法
在sklearn库中,KNeighborsClassifier是实现K近邻算法的一个类。
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, *, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None, **kwargs)
参数 说明 n_neighbors int, default=5
默认情况下用于
kneighbors
查询的近邻数
weights {‘uniform’, ‘distance’} or callable, default=’uniform’
预测中使用的权重函数。 可能的值: “uniform”:统一权重。 每个邻域中的所有点均被加权。 “distance”:权重点与其距离的倒数。 在这种情况下,查询点的近邻比远处的近邻具有更大的影响力。 [callable]:用户定义的函数,该函数接受距离数组,并返回包含权重的相同形状的数组。
algorithm {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, default=’auto’
用于计算最近临近点的算法: ” ball_tree”将使用
BallTree
kd_tree”将使用
KDTree
“brute”将使用暴力搜索。 “auto”将尝试根据传递给fit方法的值来决定最合适的算法。 注意:在稀疏输入上进行拟合将使用蛮力覆盖此参数的设置。
leaf_size int, default=30
叶大小传递给BallTree或KDTree。 这会影响构造和查询的速度,以及存储树所需的内存。 最佳值取决于问题的性质。
p int, default=2
Minkowski指标的功率参数。 当p = 1时,这等效于对p = 2使用manhattan_distance(l1)和euclidean_distance(l2)。对于任意p,使用minkowski_distance(l_p)。
metric str or callable, default=’minkowski’
树使用的距离度量。 默认度量标准为minkowski,p = 2等于标准欧几里德度量标准。 有关可用度量的列表,请参见DistanceMetric的文档。 如果度量是”预先计算的”,则X被假定为距离矩阵,并且在拟合过程中必须为平方。 X可能是一个稀疏图,在这种情况下,只有”非零”元素可以被视为临近点。
metric_params dict, default=None
度量功能的其他关键字参数。
n_jobs int, default=None
为临近点搜索运行的并行作业数。 除非在
joblib.parallel_backend
上下文中,否则None表示1。 -1表示使用所有处理器。 有关更多详细信息,请参见
词汇表
。 不会影响拟合方法。
对象方法:
方法说明 fit
(, X, y)使用X作为训练数据和y作为目标值拟合模型 get_params
([, deep])获取此估计量的参数。 kneighbors
([, X, n_neighbors, …])查找点的K临近点。 kneighbors_graph
([, X, n_neighbors, mode])计算X中点的k临近点的(加权)图 predict
(, X)预测提供的数据的类标签。 predict_proba
(, X)测试数据X的返回概率估计。 score
(, X, y[, sample_weight])返回给定测试数据和标签上的平均准确度。 set_params
(, **params)设置此估算器的参数。
其他详见官方文档。
通过调用相关函数实现KNN算法:
from sklearn.datasets import load_iris
dataset=load_iris()
X=dataset.data
y=dataset.target
X_train, X_test, y_train, y_test =train_test_split(X, y, random_state=2022,test_size=0.2, shuffle=True)
from sklearn.neighbors import KNeighborsClassifier
knc=KNeighborsClassifier(n_neighbors=3)
knc.fit(X_train,y_train)
knc.score(X_test,y_test)
1.5 交叉验证
- 交叉验证(Cross Validation)用来验证分类器的性能一种统计分析方法,基本思想是把在某种意义下降原始数据(dataset)进行分组,一部分用来为训练集(train set),另一部分做为验证集(validation set)。利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此分类器的性能指标。
- 使用交叉验证的方式可以防止在搜索最优参数的过程中在测试集也也发生了过拟合。通过交叉验证,测试集仅仅参与了最终的验证。
from sklearn.model_selection import cross_val_score
scores = cross_val_score(knc, X_train, X_test, cv=5)
print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
1.6 网格搜索
由于 K的不同,度量方式的不同,权重选择的不同,对KNN算法的准确度均有影响,如何选择一组最优的配置, sklearn提供了网格搜索的算法。
sklearn.model_selection.GridSearchCV(estimator, param_grid, *, scoring=None, n_jobs=None, iid='deprecated', refit=True, cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score=nan, return_train_score=False)
常见参数:
参数说明
estimator
提供一个基于scikit-learn的估计器接口。估计器需要提供 score
功能,或者必须通过 scoring param_grid dict or list of dictionaries
以参数名称( str
)作为键,将参数设置列表尝试作为值的字典,或此类字典的列表,在这种情况下,将探索列表中每个字典所跨越的网格。这样可以搜索任何顺序的参数设置。
scoring str, callable, list/tuple or dict, default=None
估计器评分指标
n_jobs int, default=None
要并行运行的CPU内核数。 None
环境中,否则表示1 。 -1
表示使用所有处理器。
pre_dispatch int, or str, default=n_jobs
控制在并行执行期间分派的CPU内核数。
cv int, cross-validation generator or an iterable, default=None
确定交叉验证切分策略。可以输入: -None,默认使用5折交叉验证 -integer,用于指定在 (Stratified)KFold
中的折叠次数 –
CV splitter
-一个输出训练集和测试集切分为索引数组的迭代。 对于integer或None,如果估计器是分类器,并且 y
是二分类或多分类,使用StratifiedKFold
。在所有其他情况下,使用KFold
。 有关可在此处使用的各种交叉验证策略,请参阅
用户指南 在0.22版本中: cv
为”None”时,默认值从3折更改为5折
verbose integer
打印的日志详细程度:值越高,消息越丰富。
from sklearn.model_selection import GridSearchCV
param_grid = [
{
'weights':['uniform'],
'n_neighbors':[i for i in range(1, 11)]
},
{
'weights':['distance'],
'n_neighbors':[i for i in range(1, 11)],
'p':[i for i in range(1, 6)]
}
]
knc=KNeighborsClassifier()
grid_search = GridSearchCV(knc, param_grid, n_jobs = -1, verbose = 2)
grid_search.fit(X_train,y_train)
grid_search.best_score_
grid_search.best_params_
best_knc=grid_search.best_estimator_
best_knc.predict(X_test)
Original: https://blog.csdn.net/Y_L_Wang/article/details/123955932
Author: Y_L_Wang
Title: 一、KNN算法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/696179/
转载文章受原作者版权保护。转载请注明原作者出处!