

整理了一套字节的面试真题,还有100道PDF版的面试题库
一、SQL题
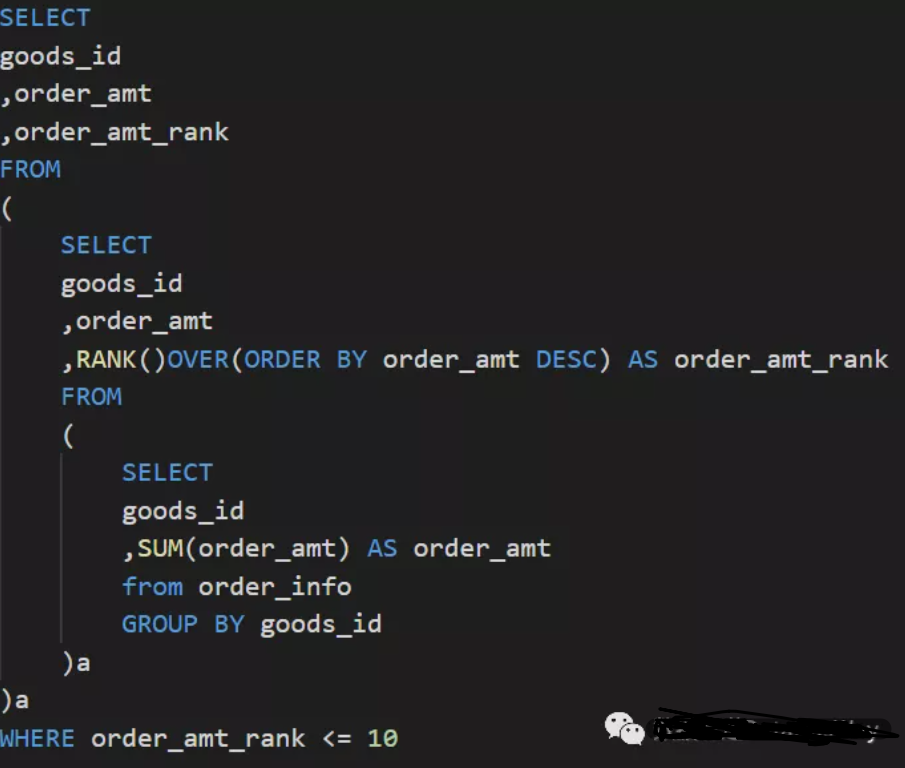
面试真题1:
抖音电商平台,现有一张订单表(order_info),有以下字段:
- order_id
- goods_id
- order_amt
请统计销量金额前10的商品信息。
▼ 参考答案:
此题考察的知识点较为简单,主要是考察GROUP BY 和窗口函数。

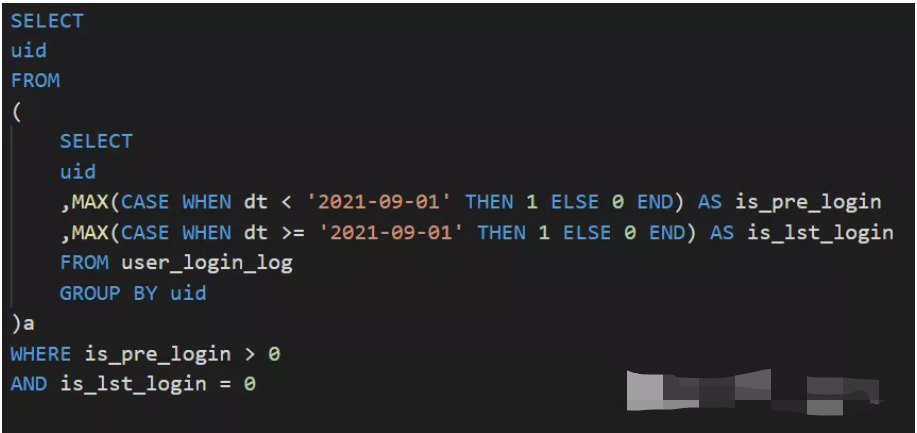
面试真题2:
现有一张用户登录表(user_login_log),请统计2021.9.1之前活跃过,但是9.1之后再也没有登录的用户。表结构如下:
- uid
- dt
▼ 思路启发:
统计用户最早和最晚一次登录时间,限制最早和最晚一次登录时间都在9.1之前即可。
二、机器学习&概率论
面试真题1:
假设家乐福决定对世界范围内1000家门店实行某措施,然后先对100家店进行试水,结果不错,但是应用到1000家店之后,发现效果不行,这是为什么?怎么分析。
▼ 思路启发:
① 为什么效果不行?
答:因为试水的门店与实际分布偏差太大,简言之,也就是这试水的100家门店分布与1000家门店的分布不一致。导致全面试行之后,效果不好。
②该怎么分析?
答:基于现有的数据说明该措施对部分门店有效,并非对所有门店有效。现在需要解决的问题就是,对哪些门店是有效的。这个问题可以结合门店的特征属性进行分析,比如门店所处城市、城市人口情况、城市人口习惯偏好、门店规模、销量等进行挖掘分析。
③补充问题,如何进行抽样。
答:针对第一小问中,试水门店与实际分布偏差太大,应该如何避免。这涉及到随机抽样的问题,可以考虑分层抽样。具体操作可以结合实际问题进行回答。比如家乐福的问题,应该结合门店城市及门店本身情况进行分层,目的尽量保证随机抽样可以代码整体抽样。
面试真题2:
请简单说一下kmeans算法原理?
▼ 思路启发:
简单来说,K-Means就是在没有任何监督信号的情况下将数据分为K份的一种方法。
具体的算法步骤如下:
- 随机选择K个中心点
- 把每个数据点分配到离它最近的中心点;
- 重新计算每类中的点到该类中心点距离的平均值
- 分配每个数据到它最近的中心点;
- 重复步骤3和4,直到所有的观测值不再被分配或是达到最大的迭代次数(R把10次作为默认迭代次数)
面试真题3:
关于K-means算法细节有关的问题
问题 ①:
K值怎么定?我怎么知道应该几类?
▼ 思路启发:
这个确实没有确定的标准做法。分几类主要取决于个人的经验与尝试。
通常的做法是多尝试几个K值,看分成几类的结果更好解释,更符合分析目的等。或者可以把各种K值算出的SSE做比较,取最小的SSE的K值。
问题 ②:
初始的K个质心怎么选?
▼ 思路启发:
常见的有以下三种方法:
- 第一种是是随机选,也是最常用的方法,初始质心的选取对最终聚类结果有影响,因此算法一定要多执行几次,哪个结果更reasonable,就用哪个结果。当然也有一些优化的方法
- 第二种是选择彼此距离最远的点,具体来说就是先选第一个点,然后选离第一个点最远的当第二个点,然后选第三个点,第三个点到第一、第二两点的距离之和最大,以此类推。
- 第三种是先根据其他聚类算法(如层次聚类)得到聚类结果,从结果中每个分类选一个点。
问题 ③:
判断每个点归属哪个质心的距离怎么算?
▼ 思路启发:
主要有以下两种方式:
- 第一种:欧几里德距离,这个距离就是平时我们理解的距离,如果是两个平面上的点,也就是(x1,y1),和(x2,y2),那这俩点距离是多少初中生都会,就是√( (x1-x2)^2+(y1-y2)^2),多维空间以此类推。注意,欧几里德只能应用在连续变量上。
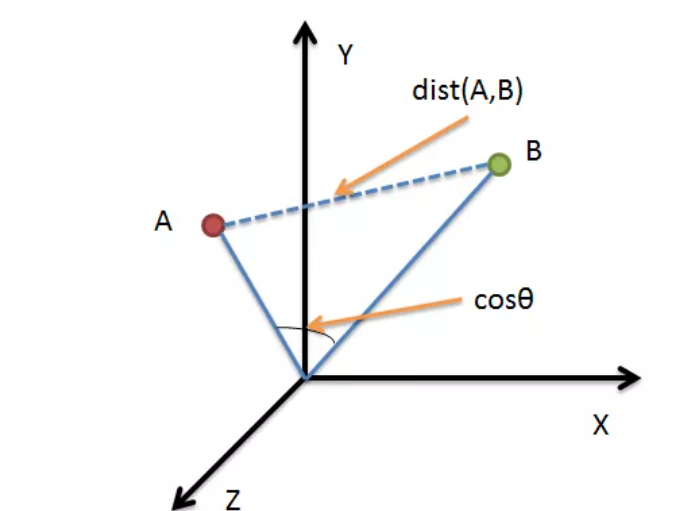
- 第二种,余弦相似度,余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。下图表示余弦相似度的余弦是哪个角的余弦,A,B是三维空间中的两个向量,这两个点与三维空间原点连线形成的角,如果角度越小,说明这两个向量在方向上越接近,在聚类时就归成一类
三、 开放性问题
面试真题1:
西瓜视频推出初期,希望通过push来引导更多的用户参与答题。现在如果需要你确认哪段时间进行push推送能更好的引流,你怎么做,给出解题思路即可。
▼ 思路启发:
主要有两种push方案
- 非个性化方案,也就是所有用户push时间点一样。该方案可以结合历史用户使用西瓜视频APP的习惯对用户使用时间进行分析,选取用户使用APP高峰时间段进行push
- 个性化运营方案,也就是不同的用户收到push的时间是不一样的。这种方案可以结合模型进行用户预测,预测用户使用APP高峰时期。目标是为了在用户打开APP概率最高的时刻进行推送。
面试真题2:
不同领域答案的点赞数不一样,比如5K赞在娱乐领域很常见但在医学领域算是高赞回答,如果按照点赞数进行高质量答案判断,怎么处理数量级不一样的问题。
▼ 思路启发:
该问题可以简单的理解为,不同领域点赞数无法纵向比较。所以应该分领域进行处理。
方法①:
分领域进行排名,根据排名占比划分高质量回答。比如将所有医学领域回答依据点赞数从高到低进行排名,选取前10%的回答定义为高质量回答。
方法②:
分领域设置不同的标准,结合不同领域答案点赞数分布。比如娱乐领域高质量答案的点赞数必须大于5万,医学领域高赞回答必须大于5千。这个阈值的判断需要结合历史点赞数分布进行界定。
面试真题3:
如何定义指标异常?
▼ 思路启发:
- 基线分析法:通过预设的基线数据来判断当前指标是否存在异常
- 同比/环比分析法:通过设定同比/环比的异常阈值进行判断
- 模型预测:构建模型,对指标进行预测。
- 3sigma原则:结合历史数据计算指标的均值方差,构建3sigma区间
面试真题4:
国家出台某政策,统计发现各个省人均收入均有所增加,但是全国人均收入下降了,请问这种情况有可能发生吗?
▼ 思路启发:
答案是有可能,这属于辛普森悖论问题。
这里涉及到两个时间点
- 出台政策前各省的人均收入
- 出台政策后各省的人均收入
因为统计的两个时间存在一段时间间隔,可能导致各省份人口数发生变化,从而导致在各省收入增加的情况下,全国人均收入出现下降。
那么有哪些可能的情况影响了各省人口数发生变化呢?
- 各省人口流动性
- 各省出生率和死亡率
以上,即为字节数分岗的面试真题+思路参考。
字节100道PDF真题面试题库请给我留言,看到会及时回复的
Original: https://blog.csdn.net/qq_40002713/article/details/122853340
Author: 六哥(数据攻略)
Title: 【数据攻略】字节面试真题(含答案)+100道面试题库
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/696005/
转载文章受原作者版权保护。转载请注明原作者出处!