

数据挖掘
- 区间型数据(Interval)
数值型数据的取值都是数值型,其大小代表了对象的状态,比如,年收入的取值,其大小代表了其收入状态。 - 分类型数据(Categorical)
分类型数据的每一个取值都代表了一个类别,如性别,两个取值代表了两个群体。 - 序数型数据(Oridinal)
和分类型数据非常相似,每个取值代表了不同的类别,但是序数型的数据还有另外一层含义就是每个取值是有大小之分的。比如:如果将年收入划分为3个档次:高、中、低,则不同的取值既有类别之分,也有大小之分。
注:充分了解字段的含义是很重要的
不同的数据类型,在算法进行模型训练时,处理和对待方式是不同的。区间型数据是直接进行计算的;分类型数据是先将其转换为稀疏矩阵:每一个类别是一个新的字段,然后根据其取值”1″,”0″进行计算。
在很多场景下,人们习惯将分类型数据和序数型数据统称为分类型数据,即数据类型可以是:数值型数据(区间型数据)和分类型数据(分类型数据和序数型数据)。
连续型数据的探索
1缺失值:缺失值的比例是确定该字段是否可用的重要指标,一般情况下,如果缺失率超过50%,则该字段就完全不可以。在很多情况下,需要区别对待Null和0的关系。Null为缺失值,0是有效值,要小心区别对待。例如,某客户在银行内的某账户余额为null,意味着该客户没有该账号,但是如果将Null改为0,则是说用户有该账户,但账户余额为0。
1 均值:反映整体水平。
2 最大值和最小值:反映指标的取值范围。
3 方差:反映各个取值离平均值的离散程度。
4 标准差:与方差类似。
5 中位数:是按顺序排列的一组数据中居于中间位置的数。
6 众数:出现次数最多的取值。
7 四分位数:用3个序号将已经排序过的数据分为四份。
8 四分位距:四分位距通过第三四分位数和第一四分位数的差值来计算,即IQR=Q3–Q1.四分位距是进行离群值判别的一个重要统计指标。一般情况下,极端值都在Q1–1.5 _IQR之下,或者Q3+1.5_IQR之上。
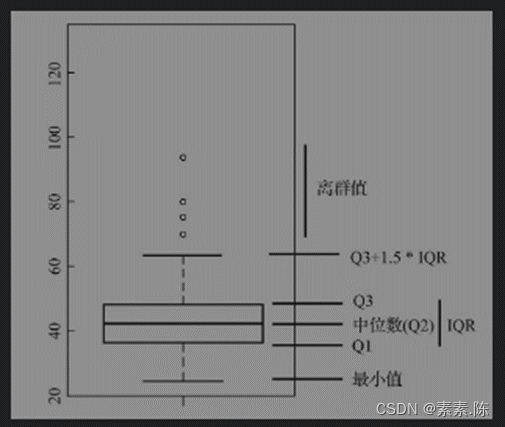

9 偏斜度:偏斜度是关于表现数据分布的对称性的指标,值为0,则代表一个对称性的分布;值为正值,代表分布的峰值偏左;若其值是负值,代表分布的峰度偏右。偏斜度的计算公式为(数据的三阶中心矩):
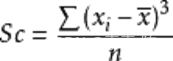
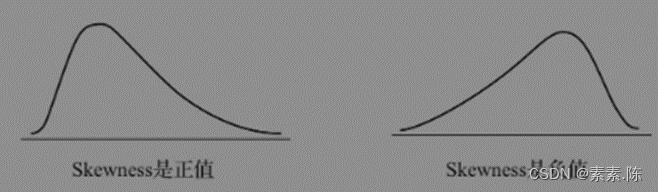
通过中位数和均值的差异来判断分布的偏斜情况
判断条件 结论
中位数>均值 偏左分布
中位数、均值相差无几 对称分布
中位数
其中m4是四阶样本中心矩,m2是二阶中心矩(即使样本方差),xi是第i个值, 是样本平均值。注意此处计算方差的时候除数是N,而不是单独计算样本方差的(N-1)。
分类型数据探索
分类型数据的探索主要从分类的分布等方面进行考察,常见的统计指标有以下几个:
- 缺失值:缺失值的比例是确定该字段是否可用的重要指标,过多的缺失值,会使得指标失去意义。
- 类别个数:依据分类型数据中类别个数,可以对指标是否可用有个大致判断。例如:从业务角度讲,某指标应该有6个类别,但实际样本只有5个类别,则需要重新考虑样本的质量。再例如,某个分类型变只有一个类别时,对数据分析是完全不可用的。
- 类别中个体数量:反映样本中类别组成结构。
- 众数:出现次数最多的取值。
下面是数据探索的代码
def dataDescription(data_df):
from collections import OrderedDict
dict_result = OrderedDict()
dict_result['Min.']= data_df.min()
dict_result['1st Qu.']= data_df.quantile(q = 0.25)
dict_result['Median']= data_df.median()
dict_result['Mean']= data_df.mean()
dict_result['3rd Qu.']= data_df.quantile(q = 0.75)
dict_result['Qu_Dist.'] = data_df.quantile(q = 0.75) - data_df.quantile(q = 0.25)
dict_result['Max.']= data_df.max()
dict_result['Skew.']=data_df.skew()
dict_result['Kurt.']=data_df.kurt()
dict_result['NA counts']= data_df.isnull().sum()
return pd.DataFrame(dict_result).T
Original: https://blog.csdn.net/chensq_yinhai/article/details/124550898
Author: 素素.陈
Title: 大数据探索
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/695845/
转载文章受原作者版权保护。转载请注明原作者出处!