

参考资料:pandas官方参考文档
本文详细介绍了pandas中关于DataFrame数据类型的常用函数及其使用方法,结合了pandas给出的官方文档,佐以简单示例,万字长文助您一文搞定DataFrame相关的api调用问题。在使用pandas包中的函数时默认已经执行语句 import pandas as pd和 import numpy as np以调用pandas包和numpy包。
目录
*
– DataFrame数据类型
–
+ Constructor构造
+ Attributes属性
+
* Axes轴函数
* conversion转换函数
* Indexing, iteration索引、遍历函数
– DataFrame的构造转换函数:pd.DataFrame()
– DataFrame的聚合函数、应用函数
–
+ df.apply() 或 df.applymap()
+ df.aggregate()或df.agg()
+ df.transform()
+ df.groupby()
DataFrame数据类型
DataFrame是在python中独有的一种数据类型,它是一种二维的、大小可变的、有潜在异构的表格型数据。
Constructor构造
DataFrame([data, index, columns,dtype, copy])
Attributes属性
这里只介绍常用的api,如需了解其它的,请参考文章顶部参考链接。
Axes轴函数
- df.index:返回行标签;
- df.columns:返回列标签;注意这两处都没有括号,且列标签要求有s;
- df.dtypes:返回df的dtypes;
- df.info(): 返回对于df的信息概述,如:


- df.values:返回二维np数组的形式的df,如:
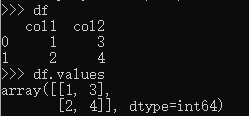
- df.size:求出df中的元素数量,如上图df的size即为4;
; conversion转换函数
- DataFrame.astype(dtype[, copy, errors])
作用:将一个df转换成指定的类型;
格式:df.astype('int32')
示例:
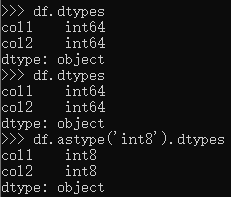
注意:不通过赋值不会存储转换结果,即执行完df.astype(‘int8’)之后如果直接执行df.dtypes返回的结果仍是int64; - DataFrame.convert_dtypes([infer_objects, …])
作用:将df中的列自动转换成最可能适配的类型,并且使用的dtype都是支持pd.NA的;即把用户自定义的类型转换成python语言中最适配的数据类型,并把np.nan转换为pd.NA;
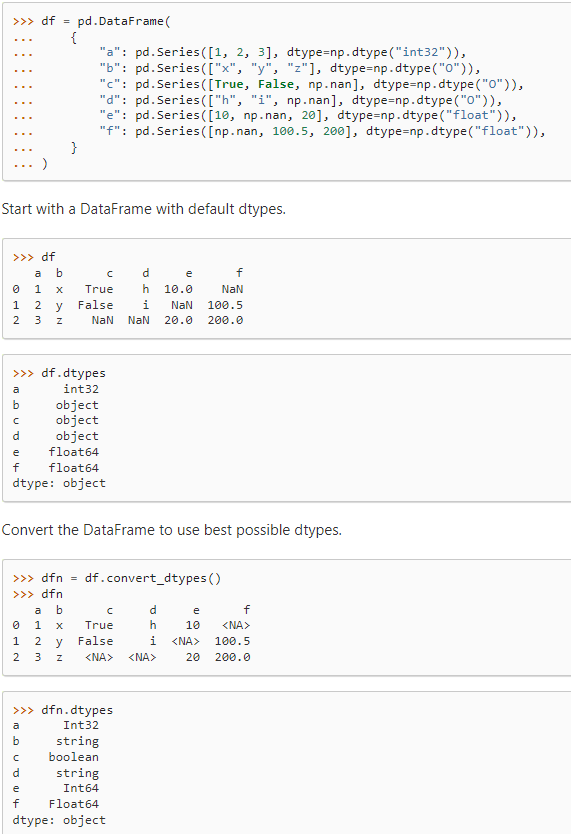
即把用户自定义的类型转换成python语言中最适配的数据类型,并把np.nan转换为pd.NA; - DataFrame.infer_objects()
作用:尝试为列类型为object的列推断更好的数据类型;
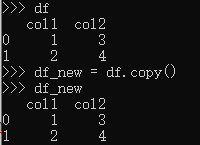
与convert_dtypes()的区别:infer_objects()只针对类型为object的列,而convert_dtypes()针对所有的列; - DataFrame.copy([deep])
作用:复制一个df;
格式:df_new = df.copy()
示例:
Indexing, iteration索引、遍历函数
- df.head([n])
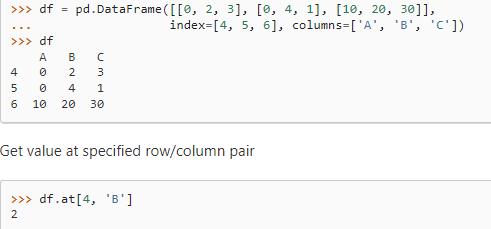
作用:返回前n行数据,默认为5 - df.at
作用:按标签返回 行列对的单个值
格式:df.at[row_label, col_label]
示例:
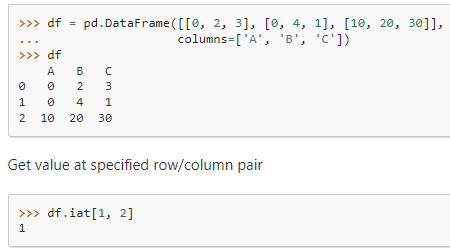
- df.iat
作用:按索引返回 行列对的单个值
示例:
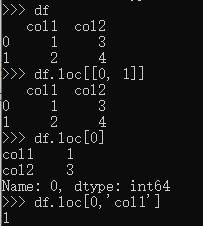
- df.loc
作用:通过 标签或布尔数组访问 一行或多行或一行列对(不是只能行列对哦!)
格式:df.loc[row_label]或df.loc[row_label, col_label]或df.loc[[row1_label, row2_label,...]]
注意:不能取一列数据
示例:
- df.iloc
作用:通过 索引或布尔数组访问 一行或多行或一行列对(不是只能行列对哦!)
格式:df.iloc[row_label]或df.loc[row_label, col_label]或df.loc[[row1_label, row2_label,...]]
注意:不能取一列数据
; DataFrame的构造转换函数:pd.DataFrame()
作用:将data转换成dataframe的数据类型;
格式:
pd.DataFrame(data = None, index = None, columns = None, dtype = None, copy = None)
参数:
data:需要转换位dataframe格式的原数据
index:行标签列表
columns:列标签列表
dtype:数据类型列表
示例:

DataFrame的聚合函数、应用函数
df.apply() 或 df.applymap()
作用:对于df执行某函数 或 对df的所有元素执行某函数
格式:
DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwargs)
df.applymap(func[, na_action])
参数:
func:欲施加给某行或者某列的函数
axis:{0 or ‘index’, 1 or ‘columns’}, default 0即为对列实施函数
- 0 or ‘index’: 对某列(的每行)实施函数
- 1 or ‘columns’: 对某行中(的每列)实施函数
raw:一个布尔值, default False,决定了一行或列的数据类型是以series还是ndarray object的形式传入函数
- False : 以series为数据类型传入参数
- True : 以ndarray objects为数据类型传入参数,如果函数是基于numpy包实现的时候有更好的表现
示例:
- np自带的函数:
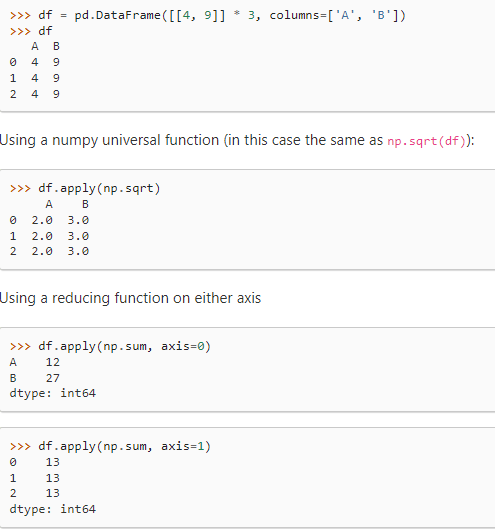
- lambda函数:
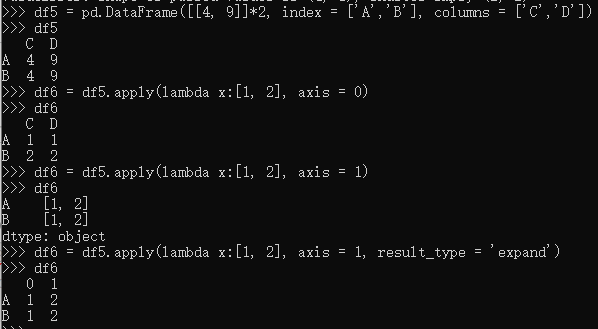
df.aggregate()或df.agg()
作用: 对所有行或所有列做一项或多项聚合操作(两种形式的函数效果一模一样);
格式:
DataFrame.aggregate(func=None, axis=0, *args, **kwargs)
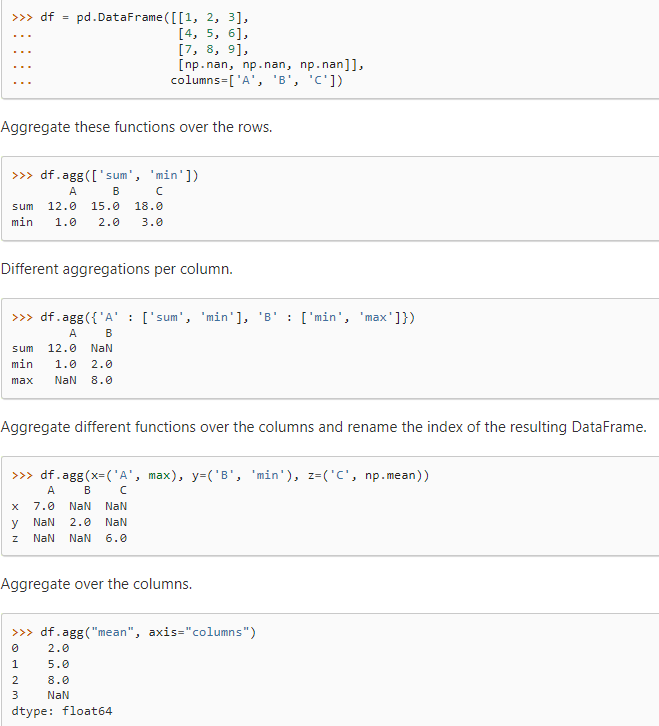
示例:
df.transform()
作用:对df每个元素调用函数;
与df.apply()的区别:在调用一个普通函数的时候没有区别,调用聚合函数时有区别,调用多个函数时也有区别。(个人理解transform只能对每个元素都进行操作,选择axis参数的意义不大)
格式:
DataFrame.transform(func, axis=0, *args, **kwargs)
示例:
- 只调用一个函数:

- 同时调用多个lambda函数:
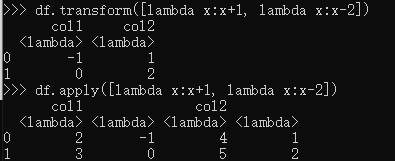
transform只显示最后一个lambda函数的执行结果,而apply会把每个执行结果都显示出来; - 同时调用多个聚合函数:(部分函数只能使用apply函数)
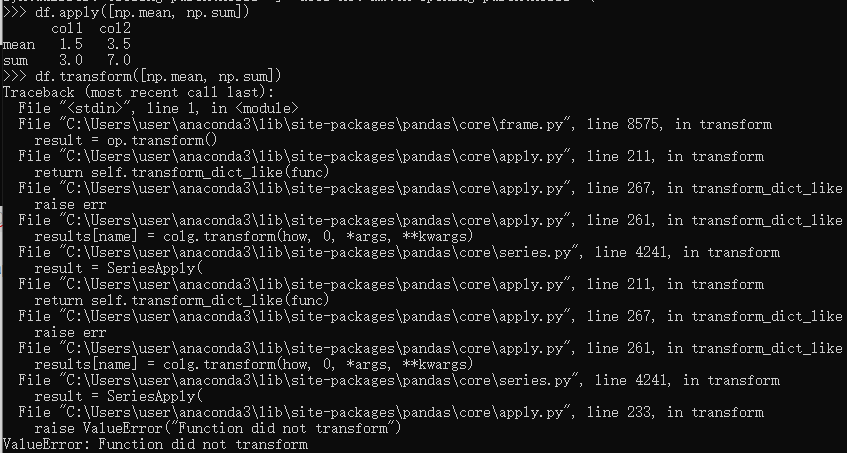
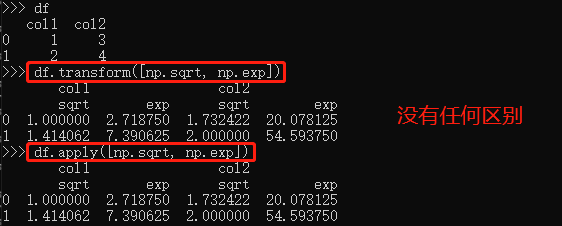
np.sqrt, np.exp等两种函数都能使用:
- sum等聚合函数在df.transform中要与groupby配合使用:
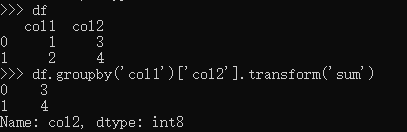
而df.transform(‘sum’)和df.transform(np.sum)都将报错;
总结:对于df执行函数时的情况复杂,如果不是对普通函数建议直接使用apply(),使用聚合函数时考虑实际情况选择需要调用的api。(需要groupby分区时用transform())
df.groupby()
作用:在对数据做聚合操作前给数据分组
格式:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, observed=False, dropna=True)
主要参数:
by:mapping, function, label, or list of labels
用于确定 groupby 的组:
- 如果 by 是一个函数,它会在对象索引的每个值上调用。
- 如果传递了 dict 或 Series,则 Series 或 dict VALUES 将用于确定分组规则。
- 如果传递了 ndarray,则按原样使用这些值来确定组。
- 标签或标签列表可以通过 self 中的列传递给 group。
- 请注意,元组被解释为(单个)键。
axis:{0 or ‘index’, 1 or ‘columns’}, default 0
与其余函数的规则一致;
as_index:bool, default True
对于聚合输出,返回带有组标签的对象作为索引。 仅与 DataFrame 输入相关。 as_index=False 是有效的”SQL 风格”分组输出。
sort:bool, default True
对组键进行排序。 关闭此功能可获得更好的性能。 请注意,这不会影响每个组内的观察顺序。 Groupby 保留每个组中行的顺序。
group_keys:bool, default True
调用apply时,将组键添加到索引以识别片段。
dropna:bool, default True
如果为 True,并且组键包含 NA 值,则 NA 值和行/列将被删除。 如果为 False,NA 值也将被视为组中的键。
示例:

Original: https://blog.csdn.net/Daisy_Wang777/article/details/122099335
Author: 芊欣欲
Title: pandas中关于DataFrame数据类型超好用的方法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/695346/
转载文章受原作者版权保护。转载请注明原作者出处!