

1 实验简介
R简介及线性回归实验
- 熟悉 R 语言基本语法
- 利用 R 语言完成线性回归
2 实验内容
2.1 混合同余法
利用如下递推公式:
x n = ( a x n − 1 + c ) m o d m x_{n} = ( ax_{n-1} + c ) \ mod \ m x n =(a x n −1 +c )m o d m
用混合同余法产生 ,编写一个函数,并利用该函数计算:
如果 x 0 = 3 x_0 = 3 x 0 =3,x n = ( 5 n − 1 + 7 ) m o d 200 x_n = (5_{n-1} + 7 )\ mod \ 200 x n =(5 n −1 +7 )m o d 2 0 0。求 x 0 , x 1 , . . . , x 10 x_0, x_1, …, x_{10}x 0 ,x 1 ,…,x 1 0
基本思路
利用递推公式编写函数,依次代入 x n − 1 x_{n-1}x n −1 计算 x n x_{n}x n ,即可求得。
代码实现
f
实验结果
运行以上代码,我们可以得到 x 0 , x 1 , . . . , x 10 x_0, x_1, …, x_{10}x 0 ,x 1 ,…,x 1 0 ,如下图:


; 2.2 π \pi π 的估计
考虑服从 (0,1) 区间上均匀分布的独立的随机变量,因此,二维随机变量 (X,Y) 的联合概率密度为:
f ( x , y ) = { 1 , 0 < x < 1 , 0 < y < 1 0 , o t h e r w i s e f(x,y) = \begin{cases} 1, 0
则
P ( X 2 + Y 2 < = 1 ) = π 4 P(X^2 + Y^2
提示:产生均匀分布随机变量
runif()
基本思路
利用 runif() 函数生成 [0, 1] 上的均匀分布,计算满足公式 (3) 条件的点的频率,以此来估计 π 4 \frac{\pi}{4}4 π 的值
代码实现
distance
实验结果
我们运行以上代码,可得到结果
nf(n)1041003.3210003.08100003.14361000003.1473210000003.143336100000003.142091
我们可以看到,随着生成点数目的逐渐增加,π \pi π 的估计值逐渐向真实值靠近
2.3 线性回归实验
糖尿病数据:有10个标准化的变量,另外一个是因变量 y,建立合适的线性回归方程进行拟合。
基本思路
如题,将包括年龄,性别,bmi 等前 10 列变量视作是自变量,将最后一列 y 视作是因变量,利用 lm() 模块进行线性回归建模
代码实现
data
实验结果
运行以上代码,得到结果:
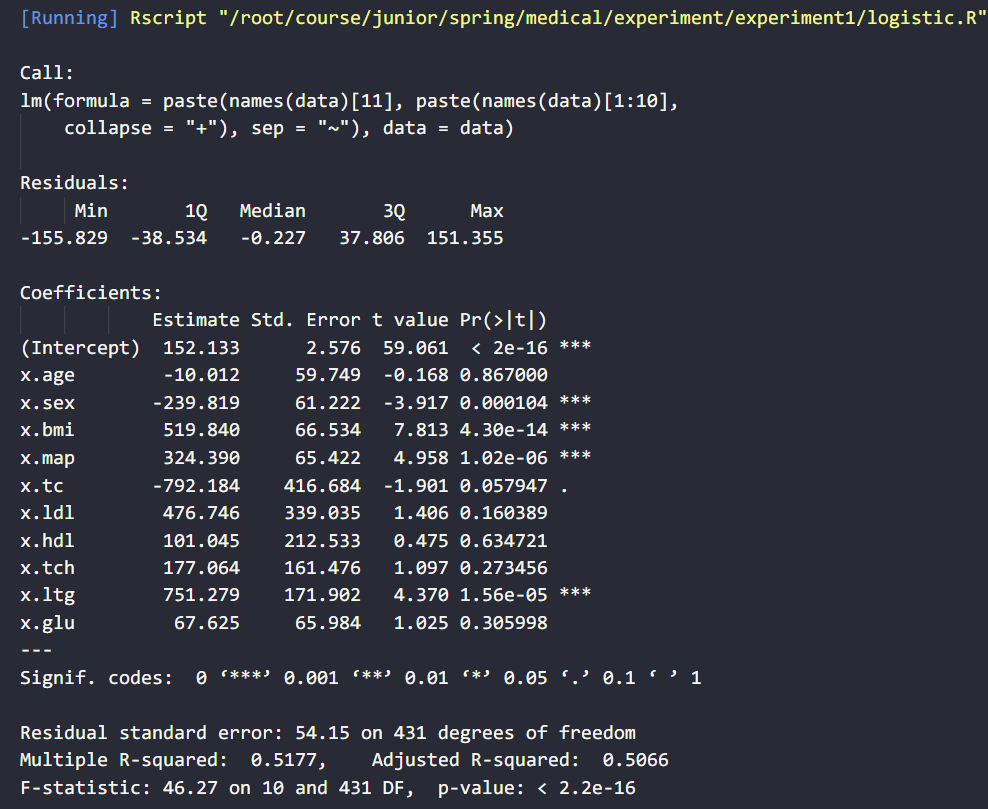
观察上述结果,我们可以发现:
- 残差项的中位数比较靠近 0,并且最大值最小值、1Q 与 3Q 的数值大小(绝对值)较为接近,说明残差分布较为对称、均匀,说明模型整体上较为充分的提取了自变量的信息。
- 拟合优度”和”修正的拟合优度”数值在 0.5 左右,说明回归方程对于数据的拟合程度较为一般
- F 统计量为 46.27,p-value < 2.2e-16 << 0.05,说明模型十分显著
- 在细节方面,sex,bmi,map,ltg 因素对于 y 值的影响较为显著,其他变量的影响不那么显著。每一个变量系数的标注差较大,说明数据分布不太均匀
- 综合以上几点,我们可以推测,线性模型对于该数据的变量信息提取比较充分,但拟合能力较为有限。不能很好的刻画原始数据的分布,后续可采用变换对数据进行预处理或者采用更为复杂的模型对数据作进一步的拟合
至此,本次实验完成。
Original: https://blog.csdn.net/BrilliantAntonio/article/details/123510765
Author: 丶无尘
Title: 医学健康数据分析与挖掘(一)—— R语言实战
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/695318/
转载文章受原作者版权保护。转载请注明原作者出处!