

序言:
在信贷风控场景中,联合建模指的是放贷机构和外部数据厂商合作的建模项目,合作的方式为放贷机构提供有风险表现的样本给到数据厂商,去匹配特征数据来开发模型,然后接入模型来做风险策略。随着个人数据隐私的监管趋严,以及放贷机构对外部数据的越发依赖,联合建模也越来越受到重视,基于此背景,我们将在这篇文章中分享相关的实践经验供大家参考。
本次整体的内容较多,除了公众号上的内容更会在知识星球上为大家提供本次内容所涉及的实操数据与代码,手把手实操带领大家领略整个模型编码方式的内容,本次整体目录如下:
PART 1.联合建模前的准备
1.1.联合建模的方式
1.2.立项前的注意点
1.3.怎么提取合适的样本
PART 2.联合建模过程中的问题点
2.1.面对陌生的数据怎么做数据探索
2.2.规定了入模特征数怎么做特征筛选
2.3.特征维度很高,文件比较大,怎么提高数据处理和特征筛选的效率
PART 3.联合建模的部署和迭代
PART 4.实操—用CV方法评估联合建模对融合模型的增益效果(数据集+代码内容)
关于本课题文字较多,干货部分也集中了我们多年的开发经验总结,本次我们仅在公众号上重点分析以上的part1与part2部分,其余关于part3与part4部分详细的内容,欢迎大家移步至知识星球平台查看完整版本的内容,当然包括数据+代码也将提供给各位星球童鞋学习。
Part1.联合建模前的准备
一.联合建模的方式
首先是谁来建模的问题,一般来说,放贷机构是模型使用方,那就由放贷机构来建模,本文也是站在建模方的角度来写的。关于建模的场地,现在除了银行这种机构会要求驻场建模,大部分联合建模都是远程操作的,这里介绍下远程操作建模的几种方式:
1)线下联合建模:有些数据公司的数据支持离开本地操作,即将特征数据回溯好传给放贷机构,为了保护数据隐私,特征都是匿名化的。这种方式模型的开发和部署都在放贷机构这,上线时数据公司将特征通过API传给放贷机构,放贷机构再跑出模型结果。


2)沙盒环境建模:如果数据不支持离开本地,那数据公司需要将特征数据放在沙盒环境里,放贷机构在沙盒环境里进行模型开发,模型是部署在数据公司那边的,上线时数据公司直接将模型结果传给放贷机构。

3)联合建模平台:一些大的数据公司会开发一套建模平台,例如百度的”智能云联合建模”,相当于高级版的沙盒环境,在平台里能实现从数据加工,模型开发到模型部署的一站式自助服务,这种方式的优点在于在保障数据安全的前提下,实现多种灵活功能,并降低了建模的技术门槛。
二.立项前的注意点
联合建模的第一步就是”立项沟通”,作为建模方,这里面有一些注意点给大家说说:
1)要了解特征的底层是怎样的数据,现在市场上数据同质化有点严重,例如两家公司都提供支付特征,背后可能都是银联的支付数据,那建模后效果可能差不多,不用两家都接入。
2)特征是否匿名,匿名后的特征没法知晓其业务含义,对于特征的处理和模型解释性有影响。
3)总共有多少特征,最终能入模多少特征,有些机构对入模的特征数量有要求,或者是按特征个数来阶梯收费的,这样我们做特征筛选时需要注意。
4)能回溯多少样本,最早能回溯到什么时候,用什么主键来匹配数据,三要素加密方式…这些关系到我们取样本的逻辑。
5)模型部署在谁那边,如果需要部署在数据公司那,那要问清楚适用的算法,要提供怎样的模型上线资料。
6)联合建模收费的方式,除了按特征个数来收费,有些也会根据模型的效果,日调用量等来议价。
三.怎么提取合适的样本
1)应用场景角度,例如做额度模型和风险预测模型除了取样逻辑不一样,选择的底层数据也不同,额度模型偏向反映收入还款能力的数据,如消费/支付明细,风险模型偏向反映还款意愿的数据,如多头,还款行为记录。
2)应用客群的角度,例如现在新客的坏账较高,得控制一下,就优先用新客的样本做联合建模。
3)样本越新越能反映未来的趋势,所以回溯的时间范围越近越好,关于样本量,如果免费回溯的量不够,可考虑付费回溯,跟对方商务议价一下打个折。
4)样本是否需要抽样,笔者认为不应该抽样,抽样后好坏比不符合真实情况,做出的模型效果也会有偏差。
5)除了有风险表现的样本,可以放少量的拒绝样本来观察在拒绝用户上的分布表现。
Part2.联合建模过程中的问题点
我们根据自己的项目经历,整理了一些建模中常见问题的处理方式:
一.面对陌生的数据怎么做数据探索
第一步,如果特征没有做匿名化,数据公司一般会提供特征字典阐明特征的含义,数据类型,有些还会写明衍生的逻辑。通过这份字典我们就能大致了解数据的构成情况,从衍生逻辑中也能学到一些别人家的东西。
第二步,可以先用python的df.head()观察下数据的全貌,然后确认特征的类别及数量,特征主要分为连续型和类别型,连续型一般用数值表示,类别型用字符,但有些数值特征也可能是类别型,这个要参考特征字典做判断。另外有些字符特征要做处理,例如百分比是”24%”这种就要去掉百分号并转小数。
第三步,做缺失值和异常值的探索,在计算缺失率之前,要询问数据公司是否做了缺失值映射以及映射逻辑,对于连续型特征,要把缺失规约成np.nan表示,类别型可用字符”null”表示,了解缺失率概况除了手动计算,也可用python的missingno包做可视化展示。关于异常值处理,统计上的分布异常可用分箱,算法来解决,如果是数据错误就得找数据公司了,这一步的探索比较费时间,但对模型开发非常重要。
第四步,一些特征自身的分布及对于Y标签的分布情况,看是否符合业务解释,例如近30天命中催收标签的号码次数,正常来讲是右偏分布,且次数越多badrate越高,如果实际情况不符,就要和数据公司沟通是否有问题。
二.规定了入模特征数怎么做特征筛选
如果数据公司规定了入模特征数不超过30个,做LR评分卡肯定是能筛到30个以内的,但对于xgb,lgb这种怎么做特征筛选呢?笔者的经验是先做粗筛后做细筛,然后挑出最好的特征入模,步骤如下:
1.用缺失率筛选,方差,常值占比等做粗筛,筛掉那些垃圾/无用的特征。
2.通过计算IV筛掉IV比较低的特征,然后将剩下的特征按IV排序做共线性筛选。
3.用集成算法自带的重要性挑出最好的特征,简单点做就是直接选出排名前30的特征,要做的精细点可选择两种手段:
1)用交叉验证做重要性筛选,以5折交叉为例,训练出5个模型和5个重要性结果,找出在5个模型中重要性排名都在TOP 30的特征。
2)用后向剔除的方法,先训练模型得出重要性排名,将重要性为0的全部剔除,然后依次剔除重要性最低的特征,每剔除一次就重新训练模型计算重要性,直到剩下30个特征为止。
三.特征维度很高,文件比较大,怎么提高数据处理和特征筛选的效率
如果特征有成千上万个,那文件大小会达到GB级,由于python执行效率慢,处理GB级的数据就很花时间,这里给出几个提高数据处理和特征筛选的效率的方法:
1.信贷模型的特征基本都为int和float类型,因pandas加载文件时,默认是int64和float64类型,那在使用read_csv读取数据时,可将特征强制转换为int32和float32,这样在不损失精度情况下能节约一半的内存空间,并且提高了数据处理速度(文件越小,pandas处理越快),我们可以实验一下(如下图),直接读取data.csv文件后,可看到有1万多个特征,大部分都是float64类型的,占用内存1.6G。

我们做一下优化,先读取前100条数据,找出float64的特征,然后再调用read_csv将float64特征转换为float32,可以看到占用内存为848MB,节约了一半内存。
2.分块读取数据并分块做特征筛选。假如有2万个特征,可以按4000个拆分为5部分数据,分别做完特征筛选后再合并到一块做探索,由于分块后降低了内存,相比整个处理能节约不少时间。第1种和第2种方法可结合使用。
3.用内置的数据结构和向量化处理,python内置的数据结构有list,dict,tuple等,比pandas的处理速度要快不少。向量化也是加速计算的有效手段,python执行速度慢最为诟病的就是循环太慢,而向量化可以规避循环,以矩阵化的方式进行行列计算,无需使用for循环,使计算性能有质的飞跃。除了上述两种,大家可以多去了解python的高性能编程,里面有更多的优化方法。
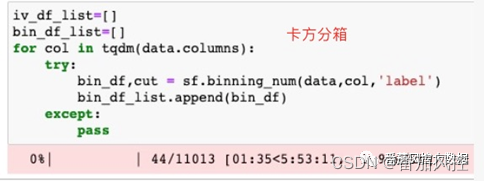
4.用更高效的分箱方式,在计算IV时,我们一般用决策树分箱或者卡方分箱,从计算效率上比较,决策树比卡方要快的多,可以用刚才的data.csv实验一下(如下图),决策树分箱1万多个特征要花7分钟左右,而卡方分箱得用5个多小时。

5.用python的multiprocessing模块实现多进程计算,降低计算的时间成本。
6.提高机器内存和CPU配置,防止跑数据时出现内存溢出等问题。
四.怎么对特征做二次衍生
如果知晓特征的含义,我们可以对原始特征做二次衍生来提升模型效果,常见的二次衍生方式为时间窗口的占比类,趋势类,合计类,还是举两个例子来说明:
1)原始特征为近7天申请机构数,近7天小贷申请机构数,可衍生为”近7天小贷申请机构数/近7天申请机构数”,来代表用户对小贷产品借款的偏好。
2)原始特征为近7天申请机构数,近90天申请机构数,可衍生为”近7天申请机构数/近90天申请机构数”。来代表用户近期多头的集中情况
需要注意的是,二次衍生由于要增加开发成本,所以得评估衍生特征对于模型的增益效果,如果增益不明显,就没有必要带到模型里去。
五.联合建模怎么应用在风控策略中
1.联合建模的模型当作单规则使用,用来拒绝尾部最差的用户。
2.加进融合模型里,提升融合模型的效果,这里有两种情况:
1)联合建模的特征可对外输出,那直接把明细特征加进融合模型里去就行
2)特征不可对外输出,就只能将模型分加进融合模型里,这样会遇到一个问题:train数据集的模型分怎么得出来?很多人觉得简单,直接拿做好的模型预测train就行了啊,这种做法是有问题的,因为xgb,lgb等集成算法,由于模型比较复杂,在训练过程中train和valid很容易过拟合,这是很难避免的,例如下图的训练结果,train的AUC有0.795,但valid的AUC只有0.625,如果直接预测train,得到的模型分效果会很好,但这不是真实的效果(valid和OOT才能反应模型的真实效果),要解决这一问题,可以借鉴stacking的思路,在stacking中为了得到train的子模型结果,会使用CV(交叉验证)的方法,将train分为N个部分,其中一部分作为valid,剩下N-1部分来训练模型,这样交叉产出N个模型和N个valid预测结果,将N个valid结果合并在一块就是train的模型分了,具体的实现过程在后面的实操中会详细阐述。
Part3.联合建模的部署和迭代
一.模型部署和一致性校验
其中的内容涉及模型文件,pkl或者pmml格式以及特征文件的处理,以及配置文件等相关内容,详细的内容的阐述我们在文章的详版内容中展开。
二.模型的上线迭代
1.模型上线后最好再做一次一致性校验,保证结果不出错。
2.模型监控的内容包括:
缺失率的监控并设置,极值监控以及模型分的均值占比分析等情况,相关内容的阐述我们仅以在文章的详版内容中展开。
3.模型的迭代优化:
迭代优化是在详版中也将详细就对数据总出现的底层数据出现变动,模型如何优化,模型回溯效果变动等英国如何,详细阐述。
对旧模型做优化。
(可以优先移步知识星球,参见详细内容)
另外在以下的第四部分中,我们还会跟大家带来关于本次的实操内容(参见数据集与代码),一步步进行内容实操。主要的内容包括:
1.导入融合模型和联合建模的数据,两份数据都是同一批样本,v1…v93是融合模型的建模特征,s1…s47是联合建模的特征
2.对df_ronghe和df_lianhe按时间顺序划分出训练数据和OOT数据 3.定义计算KS的函数和lightgbm训练的函数
4.用K折将联合建模的训练数据(data_lianhe)划分为5部分
5.开发每个CV模型并输出valid的lianhe_score,
6.将每个CV valid.xxxxxxxxx
Part4.实操—用CV方法评估联合建模对融合模型的增益效果
实操背景:
我们与一家数据公司开展了联合建模项目,想把他们的数据加到我们的融合模型中,提升融合模型的KS,因为特征不能离开本地,所以只能输出样本的模型分,这就遇到了一个问题,联合建模是用lightgbm做的,由于lightgbm容易过拟合,train的效果比valid,OOT效果会好很多,如果直接用做好的模型来预测train,与真实结果会有很大偏差,所以得用CV(交叉验证)的方法来输出train的模型分。然后将模型分带到融合模型看增益效果。
实现的步骤为:
1)先开发好融合模型(model_ronghe)和联合建模模型(model_lianhe)
2) 用CV的方法输出train的联合建模模型分(lianhe_score)
3) 将lianhe_score加到model_ronghe中迭代模型model_ronghe2,比较model_ronghe2和model_ronghe的KS
1.导入融合模型和联合建模的数据,两份数据都是同一批样本,v1…v93是融合模型的建模特征,s1…s47是联合建模的特征
2.对df_ronghe和df_lianhe按时间顺序划分出训练数据和OOT数据 3.定义计算KS的函数和lightgbm训练的函数
4.用K折将联合建模的训练数据(data_lianhe)划分为5部分
5.开发每个CV模型并输出valid的lianhe_score,
6.将每个CV valid.xxxxxxxxx
…,实操部分详见知识星球内容
…文章详版内容,因篇幅关系,详情可以移步知识星球参考完整详版内容。

另外,关于近期番茄风控关于模型相关的实操内容,更可以同步至知识星球后台,查看完整版本数据集+代码内容,欢迎星球同学移步到知识星球查收完整内容:

…
~原创文章
Original: https://blog.csdn.net/weixin_45545159/article/details/125054206
Author: 番茄风控
Title: 手把手系列|怎么做联合建模?看这篇文章就够了
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/695153/
转载文章受原作者版权保护。转载请注明原作者出处!