

列联分析
- 收集样本数据产生二维或多维交叉列联表;
- 对两个分类变量的相关性进行检验(假设检验)
pandas.crosstab(index,columns,margins,normalize)
- margins默认为False不带合计数据
- normalize=True频率列联表



salary_reform.scv


结果为列联表
补充的内容


列联表的期望分布
根据比例求出的各个变量的期望值
RT为给定单元所在行的合计,CT为给定单元所在列的合计,n为样本量


卡方检验
-
当样本量较大时,上述统计量服从自由度为(r-1)(c-1)的卡方分布
-
用于衡量实际值与理论值的差异程度(有差异表示自变量对因变量有影响)
-
返回值:统计量,p值,自由度
- p值:可以理解为落在极端值上的概率
- 计算方法:已知统计量的值,求对应卡方分布的概率,过大则拒绝原假设(独立)

课堂练习一
作列联表

期望值分析

卡方检验
结果分析:p值较小,说明race对于工资水平的影响不显著

方差分析
比较多个总体的均值是否相等;
研究一个或多个分类型自变量与一个数值型因变量的关系;
假设:
(1)每个总体都应服从正态分布(如何检验样本是否服从正态分布?);
(2)各个总体的方差必须相同;
(3)观测值是独立的
单因素方差分析
方差齐性检验levene
H0:
, H1: 不全相等(自变量对因变量有显著影响)
构建统计量F检验
SST:总平方和;SSA:组间平方和;SSE:组内平方和
;
若原假设成立,则表明没有系统误差,组间方差MSA与组内方差MSE的比值不会太大,F>Fa,拒绝原假设

方差来源分析及检验过程anova_lm()
运算符
说明
+
将运算符左右两边的数据都纳入生成的数据集中
–
将运算符左边的纳入,右边的移除
:
计算运算符两边的交集(交互效应),生成一列数据
*
a+b+a:b形式的简写
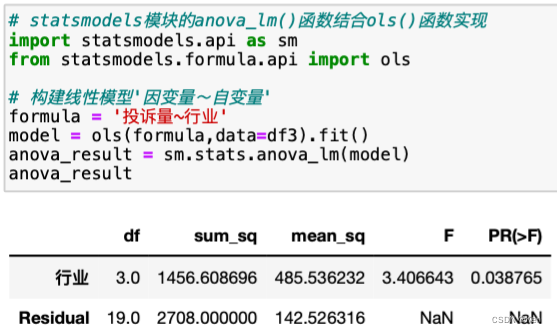
关系强度的测量
组间误差占总误差比例越高,相关度越高

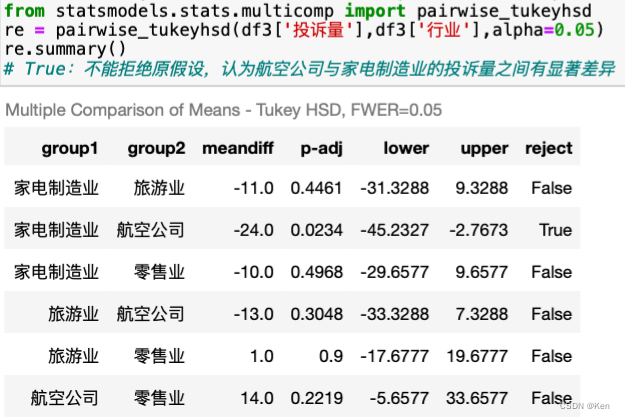
多重比较
通过对总体均值之间的两两比较来检验哪些均值之间存在差异
LSD检验
已知总体方差的联合估计量
组内方差
k = 2时,
构造统计量:
若
,认为差异是显著的,拒绝原假设。
HSD检验
基于学生化极差的成对比较。
计算HSD统计量,如果两组均数的差异大于该极差,认为差异是显著的,拒绝原假设。
HSD检验较LSD检验更保守,更不易发现显著差异,一般用于样本容量相同的组之间的均值比较
多因素方差分析
不存在交互效应的多因素方差分析


tv.csv



结果解释:”品牌”的p值过小,拒绝”品牌”的原假设,可认为品牌对销售量有显著影响。

存在交互效应的多因素方差分析


traffic.csv


结果解释:路段对通行时间有显著影响;时段对通行时间有显著影响;没有证据表明路段和时段的交互作用对通行时间有显著影响。

Original: https://blog.csdn.net/weixin_56631477/article/details/124732817
Author: Kentos(acoustic ver.)
Title: python数据分析(一):列联分析与方差分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/694918/
转载文章受原作者版权保护。转载请注明原作者出处!