

文章目录
- 欢迎关注公众号【Python开发实战】,免费领取Python学习电子书!
- Dataframe的drop_duplicates方法
* - drop_duplicates方法介绍
- 用例1
- 用例2
- 用例3
- 用例4
- 用例5
欢迎关注公众号【Python开发实战】,免费领取Python学习电子书!
Dataframe的drop_duplicates方法
在实际处理数据中,数据预处理操作中,常常需要去除掉重复的数据,这就用到了Dataframe的drop_duplicates方法。
drop_duplicates方法介绍
方法形式为 drop_duplicates(subset=None, keep=’first’, inplace=False, ignore_index=False),返回删掉重复行的Dataframe。
参数解析:
- subset:列名或列名序列,对某些列来识别重复项,默认情况下使用所有列。
- keep:可选值有first,last,False,默认为first,确定要保留哪些重复项。
- first:删除除第一次出现的重复项,即保留第一次出现的重复项。
- last:保留最后一次出现的重复项。
- False:删除所有重复项。
- inplace:布尔值,默认为False,返回副本。如果为True,则直接在原始的Dataframe上进行删除。
- ignore_index:布尔值,默认为False,如果为True,则生成的行索引将被标记为0、1、2、…、n-1。
返回:
- 返回删除重复项的Dataframe或None,当inplace=True时返回None。
用例1
导入包
import pandas as pd
import numpy as np
df = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
})
df
输出:
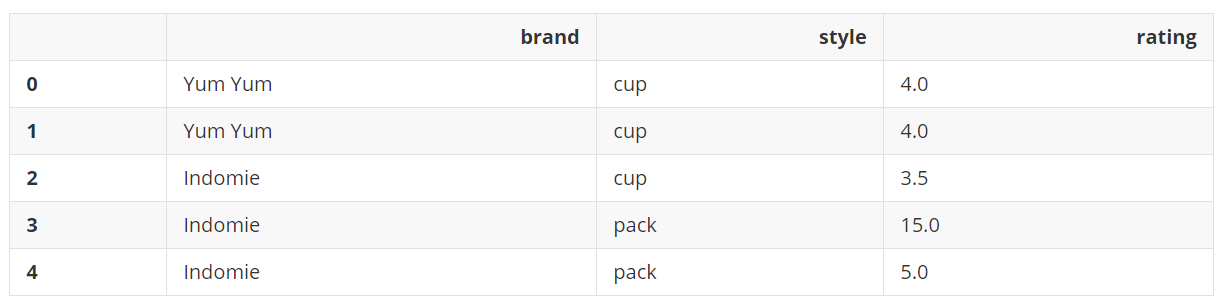

默认情况下,会根据所有列来删除重复的行。
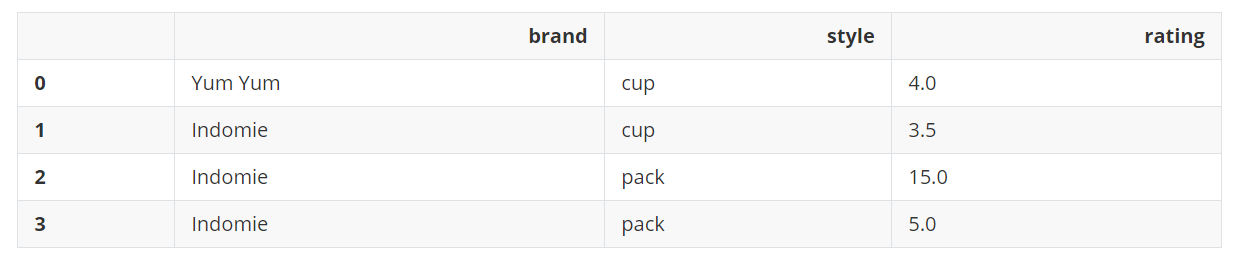
df.drop_duplicates()
输出:
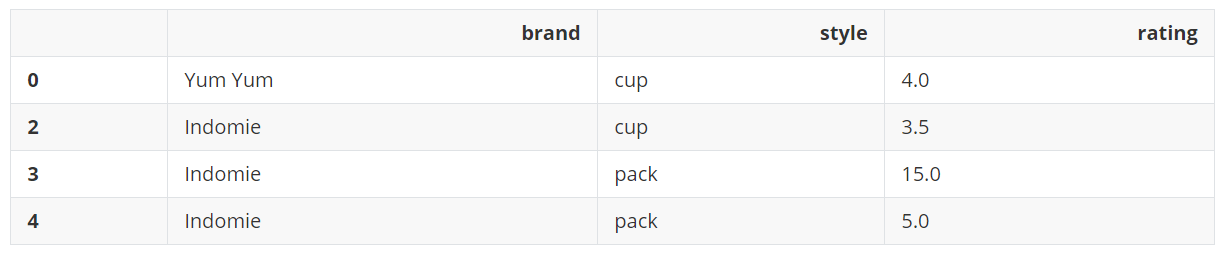
用例2
删除特定列上的重复项,使用subset参数。
df.drop_duplicates(subset=['brand'])
输出:

df.drop_duplicates(subset='brand')
输出:

用例3
删除前两列的重复项,并保留最后一次出现的数据,使用keep。
df.drop_duplicates(subset=['brand', 'style'], keep='last')
输出:

用例4
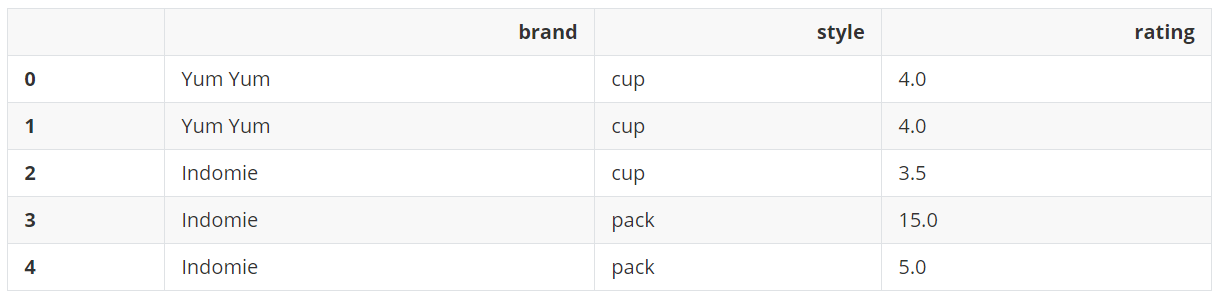
删除所有列的重复项,并直接在原数据上操作。
df
输出:
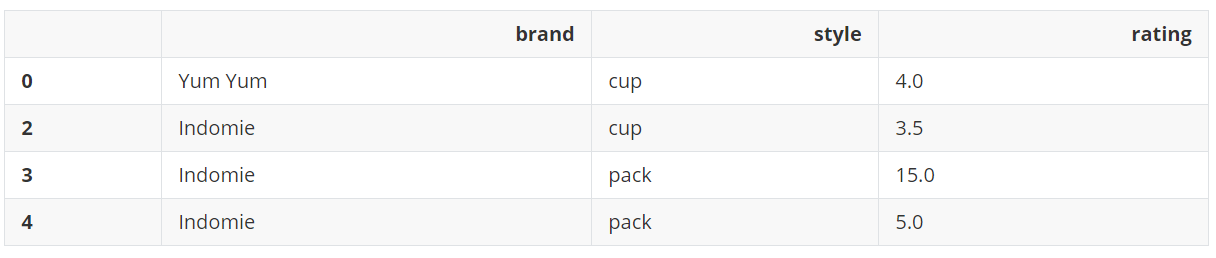
df.drop_duplicates(inplace=True)
df
输出:
用例5
删除所有列的重复项,重新设置行索引。
df.drop_duplicates(ignore_index=True)
输出:
Original: https://blog.csdn.net/qq_38727995/article/details/124479938
Author: 凯旋.Lau
Title: pandas进阶–Dataframe的drop_duplicates方法(数据去重)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/693827/
转载文章受原作者版权保护。转载请注明原作者出处!