

温馨提示:文末有 CSDN 平台官方提供的学长 Wechat / QQ 名片 :)
- 项目简介
本课题设计的高校舆情分析系统基本内容包括:(1)使用爬虫技术将贴吧中的热门话题爬取出来并存储到mysql数据库中。(2)系统内容包括用数据可视化的样式将高校的热门贴吧的热点帖子展现出来。(3)筛选重点舆情信息,利用python第三方包wordcloud将重点信息以云图的的方式展现出来(4)利用lambda算法实时计算并对网页内容进行内容实时抽取,情感词分析并进行网页舆情结果存储。(5)通过离线计算,系统需要对历史数据进行回溯,结合人工标注等方式优化情感词库,对一些实时计算的结果进行矫正等。
- 高校舆情数据抓取
利用 python 的 request + beautifulsoup 等工具包实现对某高校的贴吧进行发帖数据的抓取:
。。。。。。
# 采集某贴吧列表数据
def spider_tieba_list(self, url):
print(url)
response = requests.get(url, headers=self.headers)
try:
response_txt = str(response.content, 'utf-8')
except Exception as e:
response_txt = str(response.content, 'gbk')
# response_txt = str(response.content,'utf-8')
bs64_str = re.findall(
'[.\n\S\s]*?',
response_txt)
bs64_str = ''.join(bs64_str).replace(
'', '')
html = etree.HTML(bs64_str)
# 标题列表
title_list = html.xpath('//div[@class="threadlist_title pull_left j_th_tit "]/a[1]/@title')
# 链接列表
link_list = html.xpath('//div[@class="threadlist_title pull_left j_th_tit "]/a[1]/@href')
# 发帖人
creator_list = html.xpath('//div[@class="threadlist_author pull_right"]/span[@class="tb_icon_author "]/@title')
# 发帖时间
create_time_list = html.xpath('//div[@class="threadlist_author pull_right"]/span[@class="pull-right is_show_create_time"]/text()')
for i in range(len(title_list)):
item = dict()
item['create_time'] = create_time_list[i]
if item['create_time'] == '广告':
continue
item['create_time'] = self.get_time_convert(item['create_time'])
item['title'] = self.filter_emoji(title_list[i])
item['link'] = 'https://tieba.xxxx.com' + link_list[i]
item['creator'] = self.filter_emoji(creator_list[i]).replace('主题作者: ', '')
item['content'] = self.filter_emoji(item['title'])
item['school'] = self.tieba_name
self.tieba_items.append(item)
# 保存帖子数据
self.saver.writelines([json.dumps(item, ensure_ascii=False) + '\n' for item in self.tieba_items])
self.saver.flush()
self.tieba_items.clear()
# 如果有下一页继续采集下一页
nex_page = html.xpath('//a[@class="next pagination-item "]/@href')
if len(nex_page) > 0:
next_url = 'https:' + nex_page[0]
# 抓取 10000 条数据
if float(next_url.split('=')[-1]) < 2000:
self.spider_tieba_list(next_url)
。。。。。。
- 基于大数据的高校舆情数据分析系统
3.1 系统首页与注册登录


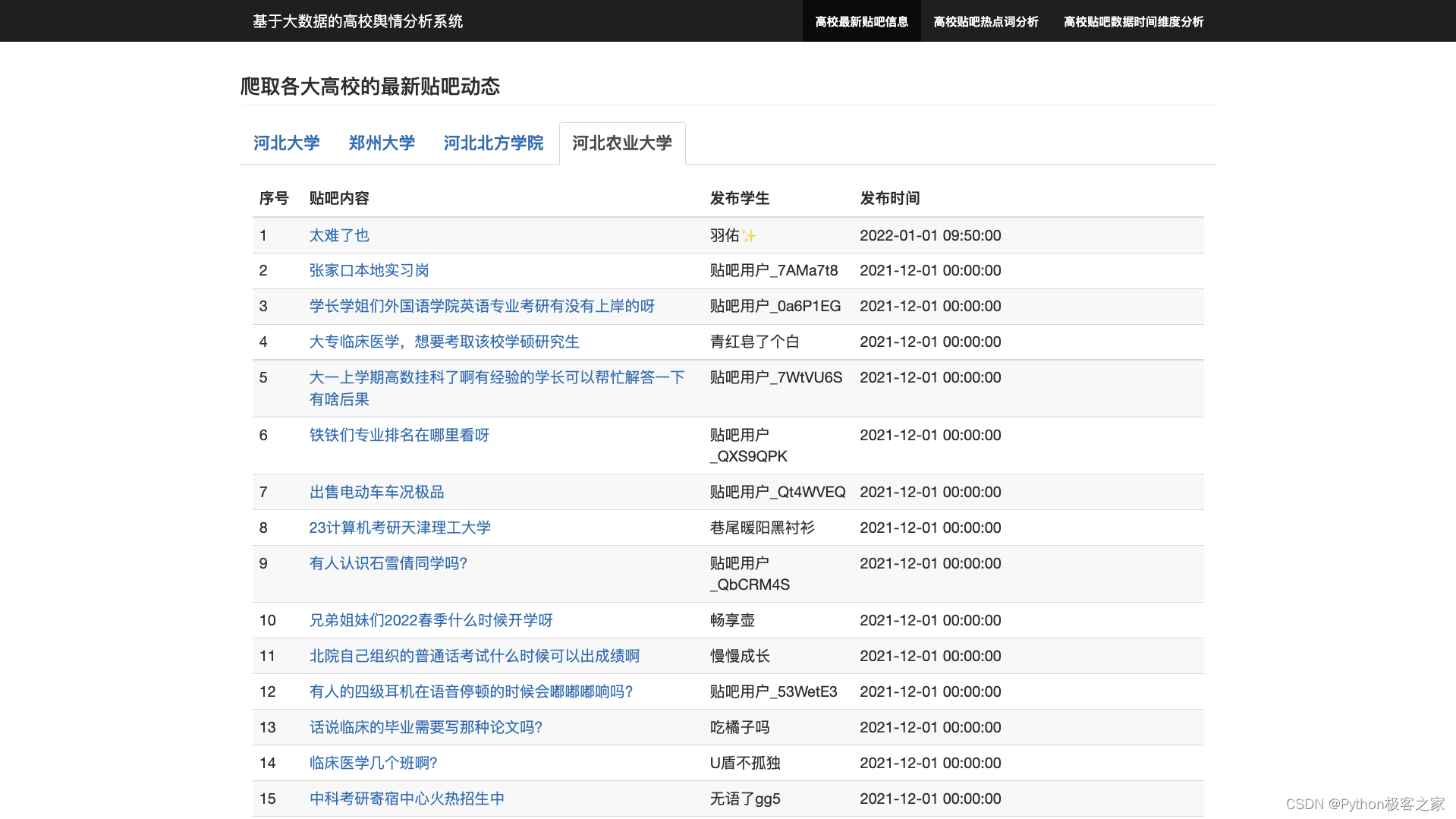
3.2 高校最新贴吧信息展示
对学生发帖文本内容进行文本清洗,去除停用词、标点符号等不能表征舆情效果的词汇,通过词频的统计并构建话题词群:
def tiebas_words_analysis(school):
cate_df = tiebas_df[tiebas_df['school'] == school]
word_count = {}
for key_words in cate_df['title_cut']:
for word in key_words:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
wordclout_dict = sorted(word_count.items(), key=lambda d: d[1], reverse=True)
wordclout_dict = [{"name": k[0], "value": k[1]} for k in wordclout_dict if k[1] > 3]
# 选取 top10 的词作为话题词群
top_keywords = [w['name'] for w in wordclout_dict[:10]][::-1]
top_keyword_counts = [w['value'] for w in wordclout_dict[:10]][::-1]

3.4 高校贴吧数据时间维度分析


- 结论
本项目利用网络爬虫从某高校贴吧抓取某几个大学学生发帖的数据,包括发帖内容、发帖时间、用户名等信息,对数据完成清洗并结构化存储到数据库中,利用 flask 搭建后台系统,对外提供标准化的 restful api 接口,前端利用 bootstrap + html + css + JavaScript + echarts 实现对数据的可视化分析。系统可实现对高校舆情的监视,查看学生发帖的时间分布情况,近期关注的热点词等功能。
欢迎大家 点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
技术交流认准下方 CSDN 官方提供的学长 Wechat / QQ 名片 :)
精彩专栏推荐订阅:
1. Python 毕设精品实战案例
2. 自然语言处理 NLP 精品实战案例
3. 计算机视觉 CV 精品实战案例

Original: https://blog.csdn.net/andrew_extra/article/details/125535607
Author: Python极客之家
Title: 基于大数据的高校贴吧舆情数据分析系统
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/693708/
转载文章受原作者版权保护。转载请注明原作者出处!