

目录
一、背景:员工技能培训真的是浪费时间吗
假设你是一家大企业的老板,你希望知道员工技能培训对员工生产率的提升有多大帮助。已知参加培训的员工有500人,于是你又随机抽取了500个未参加培训的员工,观察两组之间生产率的差值(ATE),并打算以此作为培训对生产率提升的因果效应。结果发现,两组员工的生产率相差不大,于是你得出”员工培训都是浪费时间”的结论。
试问,这个老板得到的结论正确吗?我们且不说结论本身是否正确,但是可以确定老板得到结论的过程缺乏科学性(不满足CIA假设)。因为我们知道这两组员工本身生产能力可能就有差别,参加培训的员工往往都是技能水平不足想要提升的,而技能优秀的员工一般都不会参加培训。直接将两组生产率作差值忽略了两组员工本身技能水平的差异,这样计算得到的因果效应会偏小。那该怎么做才能得到正确的结论呢?
最理想的做法是说,让参加了培训的张三再倒退回参加培训前的时间点(回溯),然后不参加培训再过一遍人生,看看这两个人生的张三生产率有什么差异(ATT)。很明显,时光无法倒流,最真实的因果效应只停留在理论层面。但是可以退而求其次,尽最大努力去寻找一个没有参加培训的李四,他在各方面都和张三是一样的(替身),简直是张三的翻版。于是我们通过比较张三和李四生产率的差异,也能够得出比较准确的因果效应(ATT估计值)。那么该如何寻找李四呢?
二、PSM的原理及python实现
1、PSM的原理
这里倾向得分匹配(PSM,Propensity Score Matching)就要登场了。PSM通俗理解是说,首先计算每个人参加培训的倾向性,然后根据倾向性最相似的原则,为每个参加培训的人匹配未参加培训的人,最后计算两组人群的均值差异作为ATT的估计值(因果效应)。下面是PSM的详细步骤:
1.1 计算倾向性得分
关于PSM倾向性得分的计算方式,不能用简单的欧氏距离来计算是因为欧氏距离对每个协变量的权重是一样的,当协变量维度很高时会影响得分的计算效果。一般用LR来计算倾向性得分,因为LR能够赋予协变量不同的权重。还有很多方法比如用Propensity Tree来计算得分等等。
1.2 匹配对照组样本
倾向性得分计算完成后,还需要为实验组的每个样本,从对照组中采集合适的样本去做匹配。PSM匹配环节有以下几个要点:
1)采样方式,有放回or无放回采样:从对照组抽取样本去匹配实验组样本时,被抽到的对照组样本是否允许放回。
2)匹配方式,局部最优or全局最优:应当追求为实验组每个样本找到的替身都是最匹配的(局部最优),还是整体来看实验组找到的替身是最匹配的(全局最优)。
3)匹配数量,一对一or一对多:一个实验组样本匹配一个对照组样本(一对一,偏差小,方差大),还是一个实验组用户匹配多个对照组用户(一对多,偏差大,方差小)。
4)匹配质量,有卡尺or无卡尺:实验组和对照组做匹配时,他们之间相似度是否需要限制在一定范围内(有卡尺),还是只要当前对照组样本是最匹配的即可(无卡尺)。
1.3 平衡性检查
如何衡量PSM的匹配效果?或者说怎么判断PSM后实验组和对照组是否是同质的呢?下面介绍3种评估平衡性的方法:
1)观察法:直接做协变量分布的直方图或QQ-Plot,观察实验组和对照组的协变量是否符合同一分布。
2)量化法:计算每个混淆变量的标准化差值(stddiff),stddiff越小说明混淆变量在实验组和对照组间越均衡,因果效应的估计值也就越可靠。
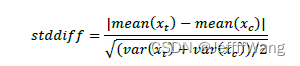

3)卡方检验:每个协变量和treatment做卡方检验,若检验通过(p>0.05)则说明协变量和treatment是相互独立的,检验未通过(p
Original: https://blog.csdn.net/JeffffWang/article/details/126175255
Author: JeffffWang
Title: 因果推断-PSM的原理及python实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/693267/
转载文章受原作者版权保护。转载请注明原作者出处!