

二、Pandas数据框操作及数据提取
import pandas as pd
import numpy as np
- 数据框行列操作
1.1 创建DataFrame
data = {"col1":['Python', 'C', 'Java', 'R', 'SQL', 'PHP', 'Python', 'Java', 'C', 'Python'],
"col2":[6, 2, 6, 4, 2, 5, 8, 10, 3, 4],
"col3":[4, 2, 6, 2, 1, 2, 2, 3, 3, 6]}
df = pd.DataFrame(data)
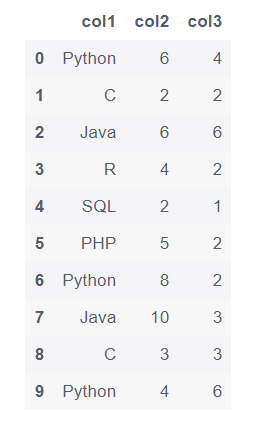
df

1.2 设置索引
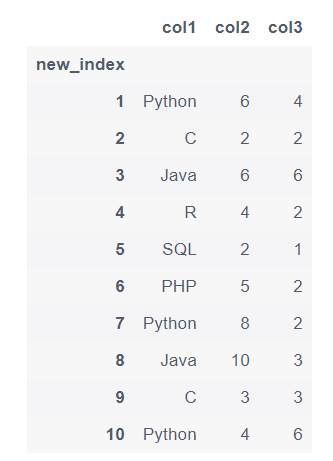
df['new_index'] = range(1,11)
df.set_index('new_index')
1.3 重置索引(行号)
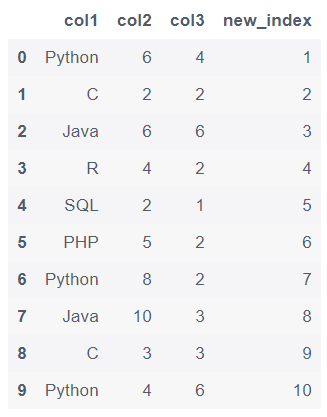
df.reset_index(drop=True,inplace = True)
df
1.4 更改列名
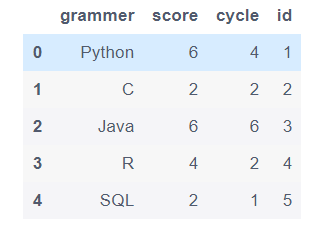
df.columns = ['grammer', 'score', 'cycle', 'id']
df.rename(columns={'col1':'grammer', 'col2':'score', 'col3':'cycle','new_index':'id'}, inplace=True)
df.head()
1.5 调整列顺序
(1) 将所有列倒序排列
df.iloc[:, ::-1]
df.iloc[:, [-1,-2,-3,-4]]
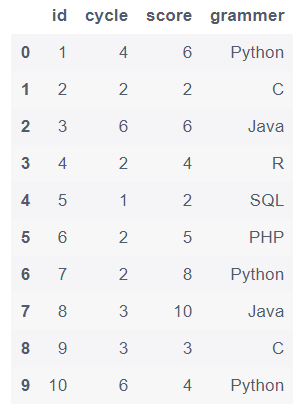
(2) 交换两列位置
temp = df['grammer']
df.drop(labels=['grammer'], axis=1, inplace=True)
df.insert(1, 'grammer', temp)
df
(3) 更改全部列顺序
order = df.columns[[0, 3, 1, 2]]
df = df[order]
df
1.6 删除行列
(1) 删除id这一列
del df['id']
df['id'] = range(1,11)
df.drop('id',axis=1, inplace=True)
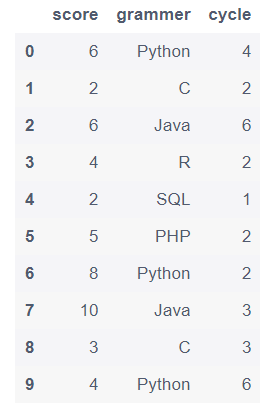
(2) 添加一行grammer=’css’数据,并删除该行
df.drop(labels=[df[df['grammer']=='css'].index[0]],axis=0,inplace=True)
df
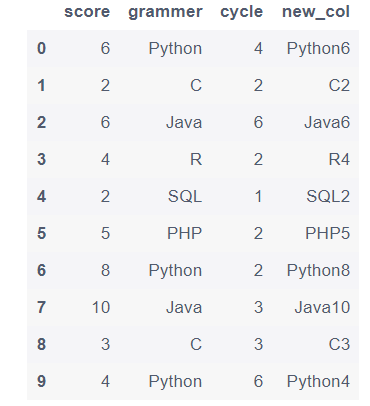
1.7 将grammer列和score列合并成新的一列
df['new_col'] = df['grammer'] + df['score'].map(str)
df
1.8 将数据按行的方式逆序输出
df.iloc[::-1, :]
- 数据读取与保存
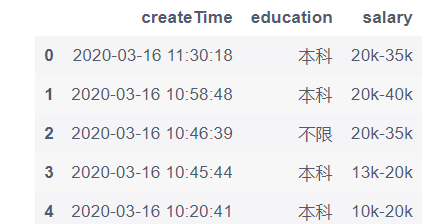
2.1 读取excel文件
excel = pd.read_excel('/home/mw/input/pandas1206855/pandas120.xlsx')
excel.head()
2.2 读取csv文件
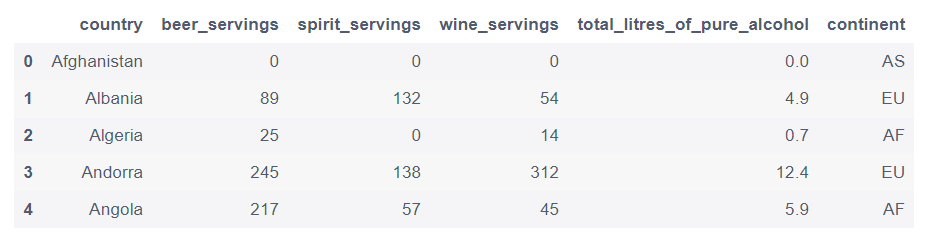
csv = pd.read_csv('/home/mw/input/pandas_exercise/pandas_exercise/exercise_data/drinks.csv')
csv.head()
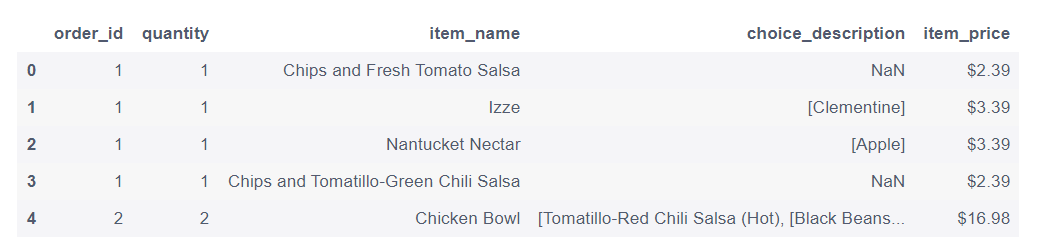
2.3 读取tsv文件
tsv = pd.read_csv('/home/mw/input/pandas_exercise/pandas_exercise/exercise_data/chipotle.tsv', sep = '\t')
tsv.head()
2.4 dataframe保存为csv文件
df.to_csv('course.csv')
2.5 读取时设置显示行列的参数:pd.set_option()
pd.set_option('display.max_columns', None)
pd.set_option('display.max_columns', 2)
pd.set_option('display.max_rows', None)
pd.set_option('display.max_rows', 10)
pd.set_option('display.float_format',lambda x: '%.2f'%x)
pd.set_option('display.width', 100)
pd.set_option('precision', 1)
pd.set_option('expand_frame_repr', False)
- 提取指定行列的数据
df = pd.read_excel('/home/mw/input/pandas1206855/pandas120.xlsx')
df.head()
3.1 提取第32行数据
df.loc[32]
df.iloc[32,:]
3.2 提取education这一列数据
df['education']
3.3 提取后两列(education, salary)数据
df[['education', 'salary']]
df.iloc[:, 1:]
3.4 提取第一列位置在1,10,15上的值
df.iloc[[1,10,15], 0]
df['createTime'][[1,10,15]]
df['createTime'].take([1,10,15])
- 提取重复值所在的行列数据
4.1 判断createTime列数据是否重复
df.createTime.duplicated()
4.2 判断数据框中所有行是否存在重复
df.duplicated()
4.3 判断education列和salary列数据是否重复(多列组合查询)
df.duplicated(subset = ['education','salary'])
4.4 判断重复索引所在行列数据
df.index.duplicated()
- 按指定条件提取元素值
这里为了运行后续代码,通过random函数随机添加一列数据;
import random
df['value'] = [random.randint(1,100) for i in range(len(df))]
df.head()
5.1 提取value列元素值大于90的行
df[df['value'] > 90]
5.3 提取某列最大值所在的行
df[df['value'] == df['value'].max()]
5.4 提取value和value1之和大于150的最后三行
df[(df['value'] + df['value1']) > 150].tail(3)
- 提取含空值的行列
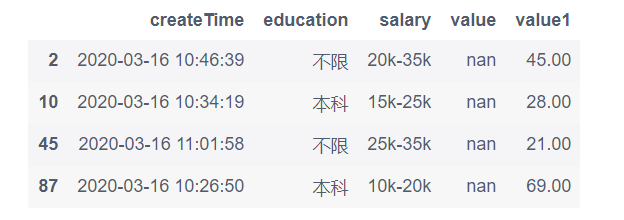
为了演示代码,这里设置一些值;
df.loc[[2,10,45,87], 'value'] = np.nan
df.loc[[19,30,55,97,114], 'value1'] = np.nan
df.loc[[24,52,67,120], 'education'] = 111
df.loc[[8,26,84], 'salary'] = '--'
6.1 提取value列含有空值的行
df[df['value'].isnull()]
6.2 提取每列缺失值的具体行数
for columname in df.columns:
if df[columname].count() != len(df):
loc = df[columname][df[columname].isnull().values == True].index.tolist()
print('列名:"{}",第{}行位置有缺失值'.format(columname, loc))

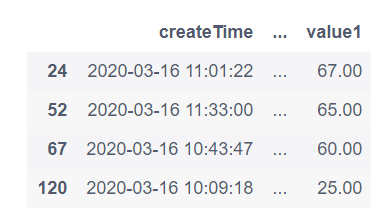
7. 提取某列不是数值或(包含)字符串的行
7.1 提取education列数值类型不是字符串的行
temp = pd.DataFrame()
for i in range(len(df)):
if type(df['education'][i]) != str:
temp = temp.append(df.loc[i])
temp
7.3 提取education列值为’硕士’的行`
df[df['education'] == '硕士']
results = df['education'].str.contains('硕士')
results.fillna(value=False, inplace=True)
df[results]
- 其他提取操作
8.1 提取学历为本科和硕士的数据,只显示学历和薪资两列
df[df['education'].isin(['本科', '硕士'])] [['education', 'salary']]
df.loc[df['education'].isin(['本科', '硕士']), ['education', 'salary']]
8.2 提取salary列以’25k’开头的行
df[df['salary'].str.match('25k')]
df[df['salary'].str.startswith('25k')]
8.3 提取value列中不在value1列出现的数字
df['value'][~df['value'].isin(df['value1'])]
8.4 提取value列和value1列出现频率最高的数字
temp = df['value'].append(df['value1'])
temp.value_counts(ascending=False)
temp.value_counts(ascending=False).index[:5]
8.5 提取value列中可以整除10的数字位置
df[df['value'] % 10 == 0].index
np.argwhere(np.array(df['value'] % 10 == 0))
作业练习:
df = pd.read_excel('/home/mw/input/pandas1206855/pandas120.xlsx')
df.head()
df1 = df[(df['salary']=='25k-35k') & (df['education']=='本科')]
df2 = df[df['salary'].str.endswith('40k')]
result = []
import re
for x in df['salary']:
result.append((int(re.split('[k-]', x)[0])+int(re.split('[k-]', x)[2]))/2)
df['result'] = result
df3 = df[df['result']>30][['createTime','education','salary']]
len(df3)
answer_2 = pd.concat([df1, df2, df3], axis=0)
data = pd.concat([answer_2.iloc[:,0],answer_2.iloc[:,1],answer_2.iloc[:,2]])
df = pd.DataFrame(data, columns=['answer'])
df['id'] = range(len(df))
df = df[['id', 'answer']]
df.to_csv('answer_2.csv', index=False, encoding='utf-8-sig')
学习资料:
https://www.heywhale.com/home/activity
Original: https://blog.csdn.net/Hexiaolian123/article/details/122583350
Author: 酸菜鱼摆摆
Title: 二、python中Pandas数据框操作及数据提取
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/693237/
转载文章受原作者版权保护。转载请注明原作者出处!