

超分辨率学习记录
*
– 超分定义
– 经典模型
–
+ 前上采样-SRCNN
+ 后上采样–FSRCNN
这篇博客主要内容来自于天池网站的超分辨率理论基础,同时对于其中涉及的学术名词也进行了解释,作为自己学习的记录(注:所有名词右上方带*的下面都有详细解释),博客还会一直更新
超分定义
超分辨率(Super-Resolution)即通过硬件或软件的方法提高原有图像的分辨率,通过一系列低分辨率的图像来得到一幅高分辨率的图像过程就是超分辨率重建。譬如想把一张图片做四倍超分,那实际上做的事情就是如何把一个像素点扩展成四个像素点,并且在扩展中保留更多的细节。目前超分大多采用深度学习的方式,但也有传统方法,如最常用且在超分里经常出现的bicubic双立方插值,直接利用数学公式,将当前像素点与周围相邻像素点融合进行插值,从而将一个点扩充成四个点,但这样做的效果往往不是很好。
在超分任务中,一般会有低分辨率(LR)-高分辨率(HR)图像对作为训练集,LR作为输入,HR作为label用于计算loss,下图就是一个例子,左边是LR(186×273)右边是HR(744×1092)


; 经典模型
主流框架分为两种: 前上采样和 后上采样
前上采样就是在网络一开始的时候就上采样,后采样是最后才开始进行上采样
前上采样
前上采样-SRCNN
最经典的代表就是超分模型开山之作SRCNN,因为SRCNN的整个流程与稀疏编码*方法相同,所以它也被看作是使用CNN实现了稀疏编码的方案

共三个阶段:
- Patch extraction and representation:提取特征-卷积+激活
从低分辨率图像中提取多个patch,经过卷积变为多维向量,所有特征向量组成特征矩阵,类比稀疏编码中的重叠图像块的构建 - Non-linear mapping:卷积+激活,将n1维特征矩阵转化为n2维特征矩阵,类比稀疏编码中的低分辨率字典映射到高分辨率字典 (我个人理解就是从一组基换到了另一组基*)
- Reconstruction:卷积,将特征矩阵还原为超分图像
损失函数:MSE
优点:相比于传统方法具有较大的感受野
缺点:由于整个网络在高分辨率空间进行计算,因此计算量大,而且噪声容易被放大
; 后上采样–FSRCNN
这里介绍一下FSRCNN
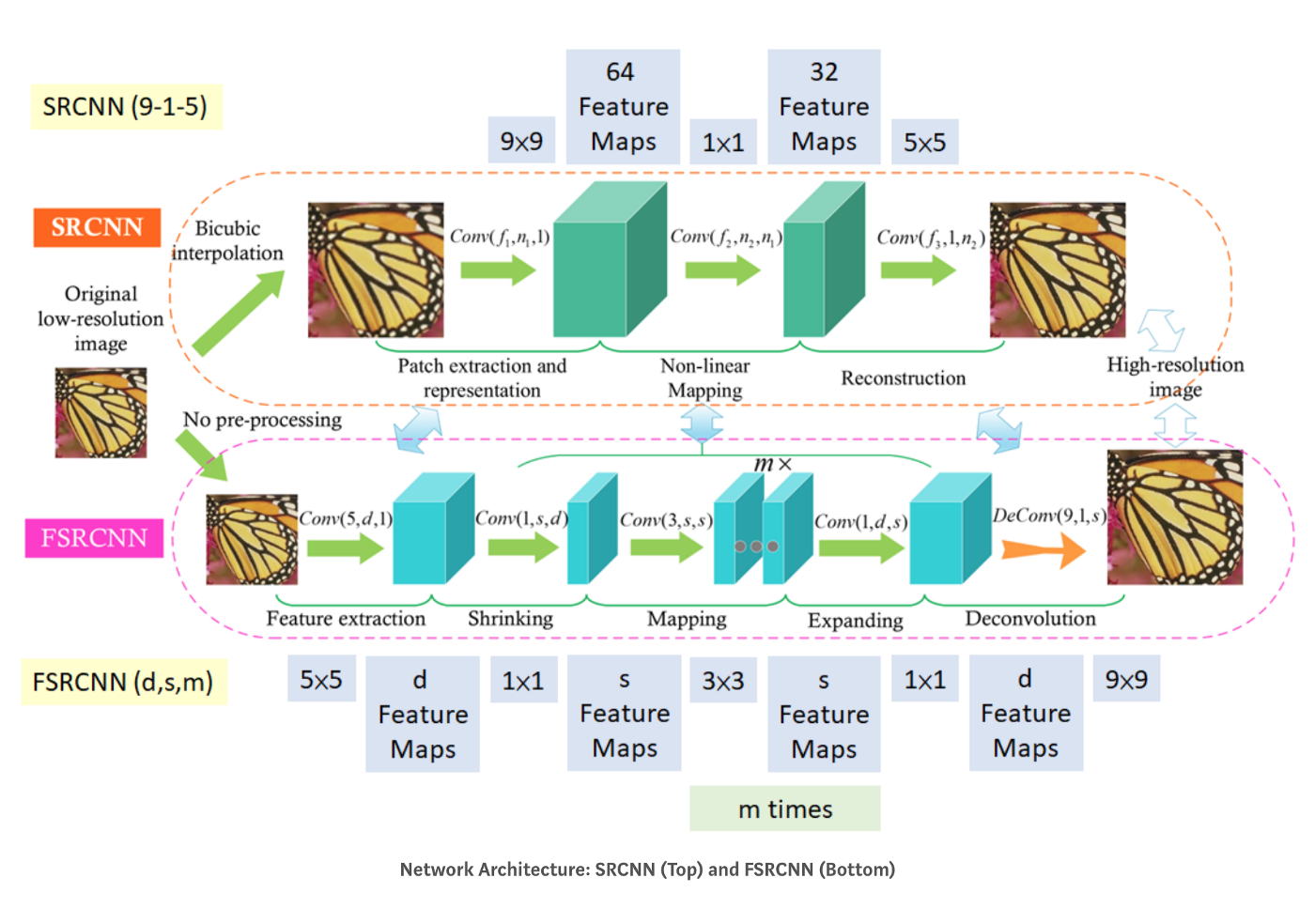
图的上方是SRCNN,下方是FSRCNN,可以看到FSRCNN并没有一上来就上采样,而是维持在低分辨率,然后压缩,减少维度,之后恢复,反卷积,FSRCNN最大的特点就是全程在低分辨率而且中间还有降维,所以模型比较轻量
除了FSRCNN还想说一下pixel shuffle,也是上采样的一种方式,pixel shuffle可以减少因为采样率不足而导致的棋盘效应
这里需要介绍sub-pixel,输入图和特征图的尺寸一样,但是特征图的通道数是输入图通道的r^2倍,r在这里表示放大倍数,之后通过周期筛选,完成下面的转变


- *定义
通过学习训练,找到一组 基,使得每个输入样本都可以用这些基的线性组合表示,基前面的系数就是输入样本的 特征,而稀疏编码要求只需要较少的几个基就可以将信号表示出来

- *满足条件
下图为编码示意图,若满足
- 系数a是稀疏*的
- 且通常具有比x更高的维数f(x)非线性
- x’=g(a),重建后的x与x’相似
则可认为该编码方式a=f(x)为稀疏编码

- *代价函数
该系统对应代价函数为:
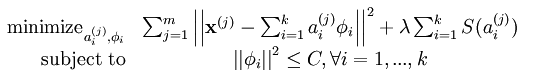
该代价函数对系数和基都做了约束,公式的来源是为了找到一组基,使输入样本的出现概率与输入样本的经验分布概率尽量相等,也就是让他们的KL距离*尽量小
- 过程
送入训练样本–>学习得到基–>测试阶段通过凸优化方法求得特征值(基前面的系数)
1) Training阶段:给定一系列的样本图片[x1, x 2, …],我们需要学习得到一组基[Φ1, Φ2, …],也就是字典。
稀疏编码是k-means算法的变体,其训练过程也差不多(EM算法的思想:如果要优化的目标函数包含两个变量,如L(W, B),那么我们可以先固定W,调整B使得L最小,然后再固定B,调整W使L最小,这样迭代交替,不断将L推向最小值。)
训练过程就是一个重复迭代的过程,按上面所说,我们交替的更改a和Φ使得下面这个目标函数最小。
每次迭代分两步:
a)固定字典Φ[k],然后调整a[k],使得上式,即目标函数最小(即解LASSO问题)。
b)然后固定住a [k],调整Φ [k],使得上式,即目标函数最小(即解凸QP问题)。
不断迭代,直至收敛。这样就可以得到一组可以良好表示这一系列x的基,也就是字典。
2) Coding阶段:给定一个新的图片x,由上面得到的字典,通过解一个LASSO问题*得到稀疏向量a(注:此时已经得到字典)。这个稀疏向量就是这个输入向量x的一个稀疏表达了。
KL距离

稀疏矩阵
稀疏矩阵是一个几乎由零值组成的矩阵。稀疏矩阵与大多数非零值的矩阵不同,非零值的矩阵被称为稠密矩阵。
LASSO回归模型

Original: https://blog.csdn.net/hhjoerrrr/article/details/123867793
Author: 桥卉呀
Title: 超分辨率学习记录
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/692515/
转载文章受原作者版权保护。转载请注明原作者出处!