



目录
; 导读
本篇文章来自西安交通大学的PhD Gang Liu,提出了基础的机器学习算法:树突网络,来自”Dendrite Net: A White-Box Module for Classification, Regression, and System Identification”,发表在IEEE TRANSACTIONS ON CYBERNETICS
首先,2020年1月,science上的一篇文章证明树突具有信息处理能力,比如and,or,not操作。过去的神经网络被Gang Liu定义为cell body net(胞体结构),神经网络没有考虑树突的信息处理过程,直接将信息加权求和后全部流入胞体。在实验中,DD呈现出一个相当重要的特性: 损失函数较大,但测试准确率却更高,这意味着DD是非常不容易出现过拟合的。
DD还具有其他优点:DD是一个很简单的结构,并且是白箱模型,可控精度,具有很低的计算复杂度,与神经网络可兼容。不得不说,Dendrite Net绝对是不可多得的好研究。在此特别感谢Gang Liu做出的贡献。
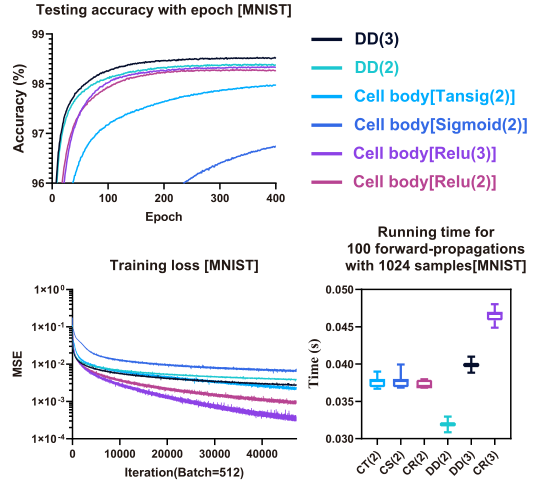
上图为使用Cell body Nets和DD对MNIST进行测试的准确性、训练损失和计算复杂度:
- 有趣的是,DD在更大的训练损失下显示出更高的测试准确性;
- DD表现出与DD模块数量相关的可控的训练损失,相比之下,随着迭代,细胞体训练损失持续下降,但准确性却不再变化;
- 随着DD模块数量的增加,训练损耗减少,测试精度增加;
- 相同数量的参数下,DD的计算复杂度明显较低;
树突模型表示为W X ∘ X WX\circ X W X ∘X,过去的cell body模型表示为f ( W X + b ) f(WX+b)f (W X +b )
引言
分类和回归是机器学习的基础问题,但ML还存在下面问题:机器学习算法通常是黑箱模型,内部的组件行为不易让人理解,这就导致超参数的调整是不可控制的(没有一个具体且明确的方向,只能凭借模糊的经验),如果能找到一个白箱模型,我们就能针对性地调整参数,从而更方便地获得优秀结果。
分类和回归均希望实现输入与输出之间的关系映射,只是分类的输出是离散值,回归的输出是连续值。
对于分类,DD认为,样本的特征逻辑关系决定样本类别,因此,每个类应该对应一个输出表达式,这个表达式可以看成是一个逻辑提取器,我们可以把逻辑提取器看成是带刻度的针管,数据集有多少个类,此处就有多少个针管。面对一个未知样本时,所有针管都去吸取,哪个得到的量多,样本就属于哪个针管。DD的目标是设计针管,并可控制其精度。
对于回归,输出值为连续值。在可解释研究的领域下,回归算法分为黑箱和白箱,白箱算法可以用于系统鉴别,但MLP,SVM这样的黑箱算法就不能用于系统鉴别。比较典型的白箱算法为多项式回归,但计算复杂度很高,不能计算得很精确。
DD的设计思想对应下图a。树突模块的数量对应逻辑提取器的精度,如图b,图b中的样本有3个特征。将图b的计算展开,如图c,可以看出,树突网络不包含非线性映射,仅存在矩阵乘法和哈达姆积(Hadamard product,元素对应相乘),展开式中,包含了各个特征之间的交互以及特征的高次幂的交互。
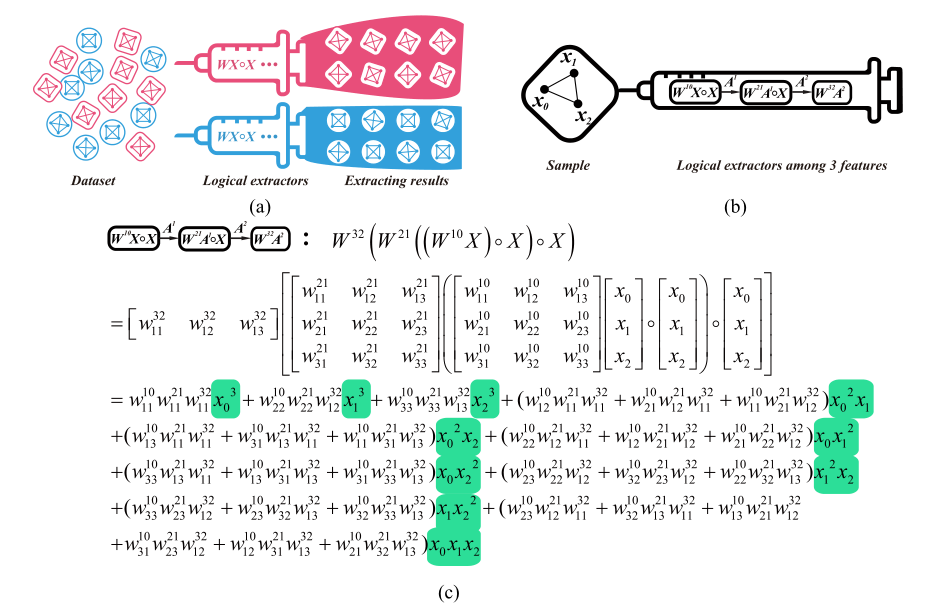
对于图c,W 32 W^{32}W 3 2实现了神经网络中的线性变换,( W 10 X ) ∘ X (W^{10}X)\circ X (W 1 0 X )∘X为第一层树突模块,W 21 ( ( W 10 X ) ∘ X ) ∘ X W^{21}((W^{10}X)\circ X)\circ X W 2 1 ((W 1 0 X )∘X )∘X为第二层树突模块。观察展开式,哈达姆积实现了高次幂, 高次幂多项式可以让表达式在不需要非线性函数的情况下达到非线性的效果(泰勒展开即为多项式展开近似任意函数),这是树突网络计算快速的巧妙之处。
DD模块的实现很简单,只需要一行代码:
X = W @ X * X
Dendrite Net
DD包含DD模块和线性模块,DD模块很直观:A l = W l , l − 1 A l − 1 ∘ X A^{l}=W^{l,l-1}A^{l-1}\circ X A l =W l ,l −1 A l −1 ∘X其中,A l − 1 A^{l-1}A l −1和A l A^{l}A l是模块的输入和输出。X X X为DD的原始输入。W l , l − 1 W^{l,l-1}W l ,l −1是第l − 1 l-1 l −1个模块到l l l个模块的线性变换权重。
多层DD的架构为:Y = W L , L − 1 [ ⋅ ⋅ ⋅ W l , l − 1 ( ⋅ ⋅ ⋅ W 21 ( W 10 X ∘ X ) ∘ X ⋅ ⋅ ) ∘ X ] Y=W^{L,L-1}[\cdot\cdot\cdot W^{l,l-1}(\cdot\cdot\cdot W^{21}(W^{10}X\circ X)\circ X\cdot\cdot)\circ X]Y =W L ,L −1 [⋅⋅⋅W l ,l −1 (⋅⋅⋅W 2 1 (W 1 0 X ∘X )∘X ⋅⋅)∘X ]最后一个模块为线性模块,L L L为模块的数量。DD的计算只包含矩阵乘法和Hadamard乘积。众所周知,Hadamard乘积的计算复杂度明显低于非线性函数。上面计算的图解为:
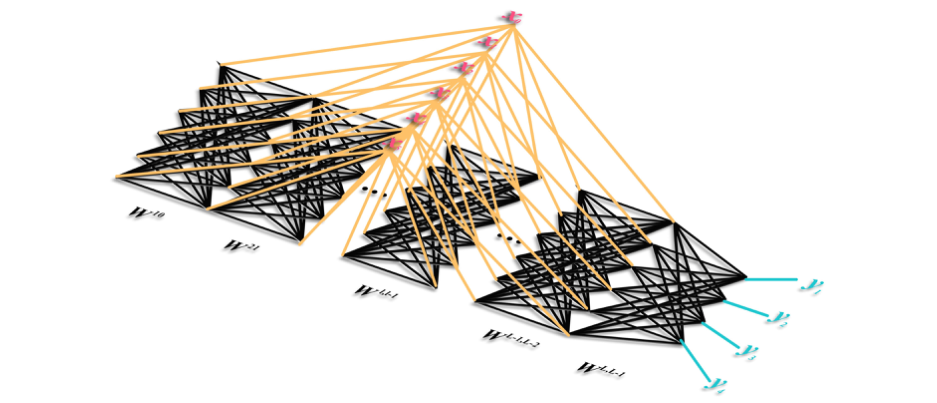
从输入信号X X X看上去,信息的计算是分散开的,犹如树突结构,故得名树突网络。模型的知识存储在突触之间的连接权重上。
树突模块的参数学习完全与反向传播算法兼容,故可以基于深度学习框架的自动求导机制训练。
; 系统鉴别System Identification
对于系统鉴别,DD与过去ML模型的不同在于,训练后的DD可以转化成输入和输出之间的关系谱,具有高透明度,是一个白盒模型。
比如,我们选择两个输入和一个输出的三模块DD,得到展开计算为:
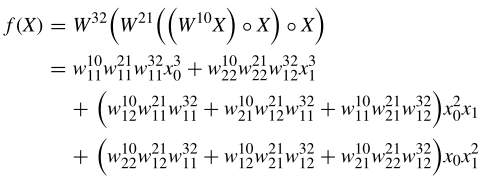
其中,x 0 x_{0}x 0 设置为1,因此,DD由常数项c c c,x 1 3 x_{1}^{3}x 1 3 ,x 1 x_{1}x 1 ,x 1 2 x_{1}^{2}x 1 2 四项构成,系数为这些项的权重。对于具有更多输入特征和树突模块的DD,结果可以表示为一个关系谱,其中项和系数分别是横坐标和纵坐标,类似于傅里叶谱。
为了测试上面的三模块DD是否类似于泰勒三阶展开,以f ( x ) = e x f(x)=e^{x}f (x )=e x为例。此外,将DD的输出与二阶、三阶和四阶多项式函数进行比较。为了更全面的比较,对每个DD使用200个不同的初始参数运行算法200次再去平均结果,如下图所示(左边的图是函数值的近似值。右图是真实系统和DD关系谱之间的比较)。这些结果表明了DD的三个性质:
- DD类似于泰勒展开;
- DD可以收敛到非常接近目标函数(系统);
- 当DD模块数量不足时,DD会寻找全局最优权值来接近系统,四阶函数运行200次后的相似识别结果证明了这一点(各自训练200次,对于x 2 x^{2}x 2处的响应值总是呈现出2比1的关系,说明DD的训练结果是全局最优的,否则200个关系谱不可能个个都很相似);
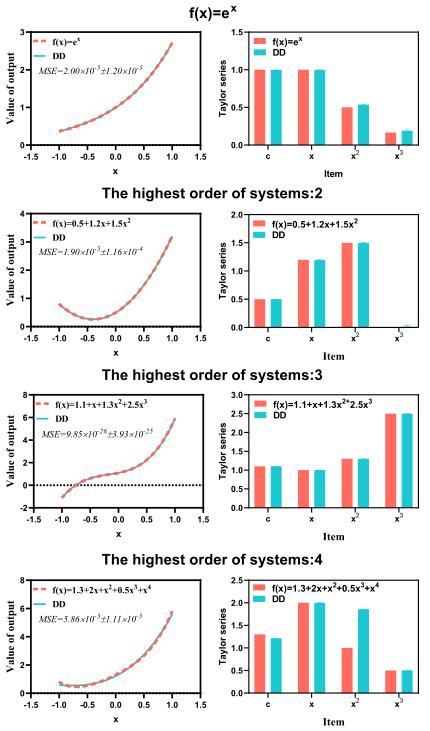
对于一个未知的系统,我们应该调整DD模块的数量来模拟真实的系统,然后将DD转换成输入输出空间之间的关系谱。
之所以说DD白盒是因为DD可以学习到系统函数的泰勒展开形式,关系谱可以作为验证和解释
对于DD精度可控的性质如下:
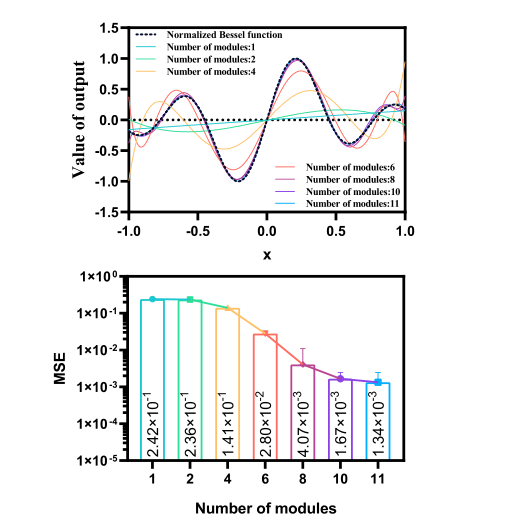
使用DD去拟合贝塞尔函数(即一个系统),当树突模块数量增加时,拟合精度越来越高,MSE损失越来越低,说明DD是精度可控制的优秀模型。
对于带噪声的多输入系统的鉴别,如下图,左边的图是系统加噪声后与DD在输出上的比较,右边的图是真实系统与DD的关系谱对比。在每一种信噪比(SNR)情况下,都训练DD200次以增强说服力。
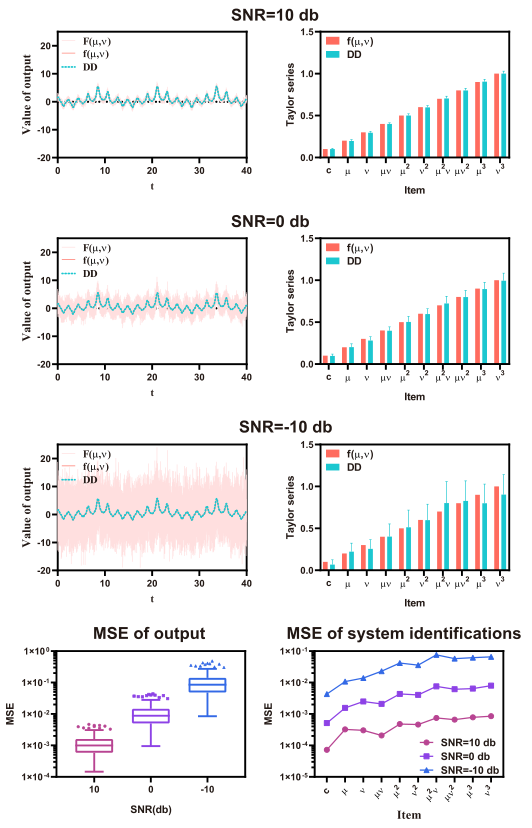
从上面 SNR=10,0,-10 情况中发现,DD可以精准地学习到噪声下的真实信号规律,证明DD具有优秀的抗噪声能力。
对于图MSE of output,随着信噪比的降低(噪声越来越强),MSE损失逐渐增大。
对于图MSE of system identifications,是关系谱上的MSE可视化,注意纵坐标是对数坐标,因此,图中三条线类似平行,实际反映的结果为越靠上的(靠近μ , v \mu,v μ,v高次幂的)斜率越陡峭,即越靠上的线条之间的间距越大(三条线之间的两个间距),越靠下的线条的间距越小。该图可以解释DD的泛化能力:
- 当增加噪声越来越强,高交互,高次特征(比如μ v 2 , μ 3 , v 3 \mu v^{2},\mu^{3},v^{3}μv 2 ,μ3 ,v 3)受到的影响较大,但低交互,低次特征受到的影响较小;
- 通常,高交互特征反映细节信息(细致信息),低交互特征反映大致轮廓级别信息;
- 综合以上两点发现:由于DD的低交互特征受噪声影响小,代表DD在轮廓级别信息上的拟合不会受到过大的影响,这是DD泛化能力强的原因。
相比之下,传统的cell body模型在训练中过度拟合细节信息(低层特征),导致其容易过拟合,不易泛化
回归与分类
对于回归,DD与神经网络在9个数据集上做了对比,分别在不同训练样本数量的训练后,在测试集上测试:
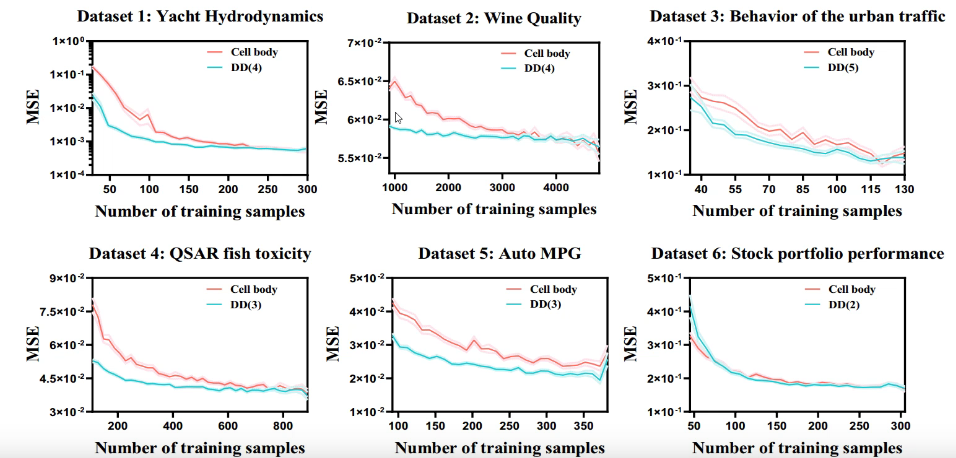
可见,DD在少样本的情况下优于cell body,随着数据量增加,DD的表现与cell body相似,证明DD不仅能适用于少量数据学习,也可用于大量数据学习。
对于分类,则选择了MNIST和FashionMNIST,将树突模块与cell body模块进行对比,分别嵌入到同一个架构中:
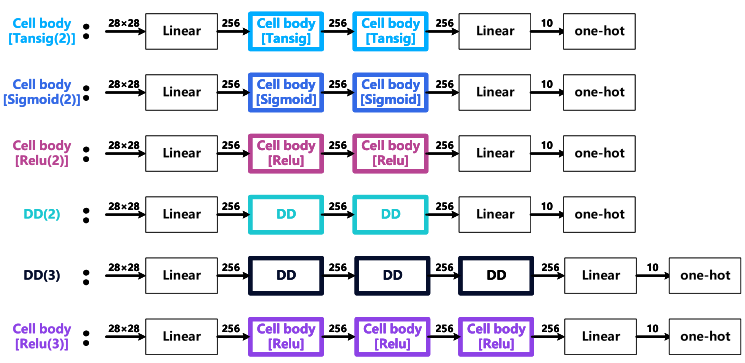
得到结果如下:
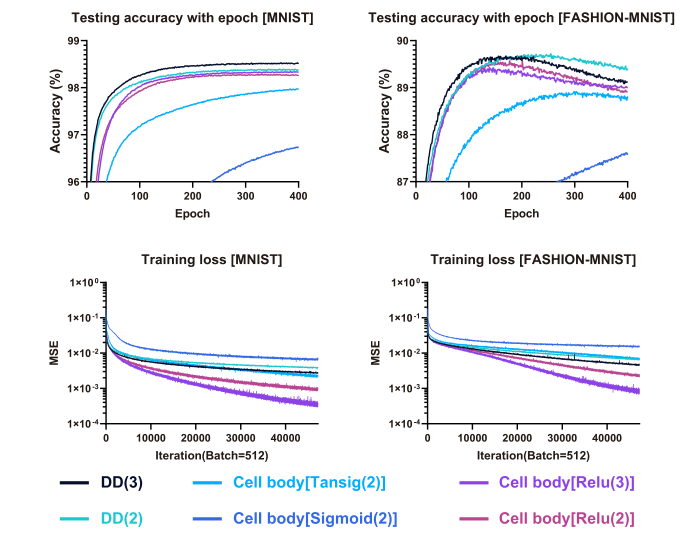
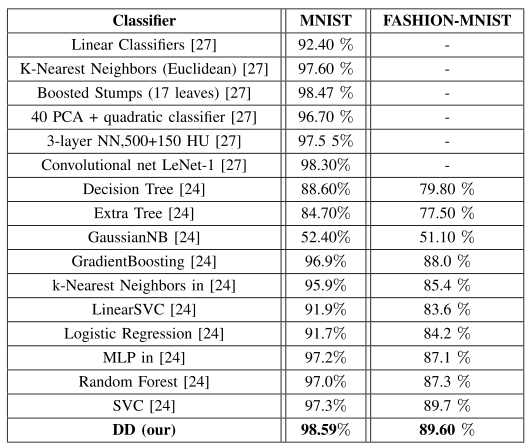
DD不仅收敛快,还具有更高的准确率, 并且DD的损失不会像cell body一样表现出持续降低的现象,这说明DD不容易出现过拟合问题,DD与其他算法的比较如下:
; 结论
作者提出了一个基本的机器学习算法,称为树突网络,DD是用于分类、回归和系统识别的白盒ML算法。DD的目的是设计精度可控的输入特征之间的逻辑表达式。作者强调了DD的白盒属性、可控制的精度以获得更好的泛化能力,以及较低的计算复杂度。实验结果是令人兴奋的,DD是开源的,每个人都可以验证这些。此外,对于基本算法来说,影响性能的因素很多,还有有待后期研究,将DD与更大的架构拼接。论文从基本定义出发,通过在相同条件下的比较,证明了DD的性质。DD模块简单美观。在未来,DD不仅作为其他基本的ML算法用于工程,而且作为深度学习的一个模块具有巨大的发展潜力。树突网络和细胞体网络的结合可能对现有的人工神经元或神经网络有改善作用。
个人理解
我们应该可以从文章中感受到一个信息,DD很大的一个改变在于使用哈达姆积代替非线性激活函数,基于哈达姆积的表达W X ∘ X WX\circ X W X ∘X巧妙地将展开式等价为特征之间的逻辑表达,自动实现了高次幂代替非线性映射的功能,各项前的权重则转为泰勒展开的系数,学习到这些系数就代表学习到了这个映射系统。
由于完全抛弃了显式的非线性激活,树突模块只存在矩阵乘法和哈达姆积,这让树突模块的计算效率非常高,并且易于训练。
W X ∘ X WX\circ X W X ∘X与f ( W x + b ) f(Wx+b)f (W x +b )相比,不需要指定非线性映射,这让树突模块的非线性学习所受的限制变得很小,也就是说可以根据高次幂多项式的形式自由去学习最本质的非线性映射,f ( ⋅ ) f(\cdot)f (⋅)不仅在学习非线性的过程中加入了人为限制,还可能存在很多冗余的非线性计算,不如泰勒展开形式的表达灵活。
Reference
Liu G, Wang J. Dendrite net: A white-box module for classification, regression, and system identification[J]. IEEE Transactions on Cybernetics, 2021.
Original: https://blog.csdn.net/qq_40943760/article/details/122378752
Author: tzc_fly
Title: 树突网络Dendrite Net
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/692423/
转载文章受原作者版权保护。转载请注明原作者出处!