

一:CityScapes格式数据集制作
1:labelme安装指南 github:labelme
第一步:下载 安装

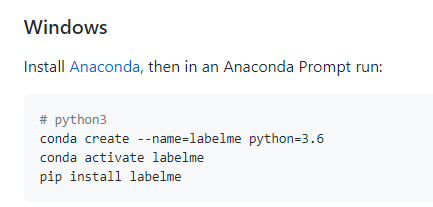
第二步:创建环境 安装依赖 基于Anaconda

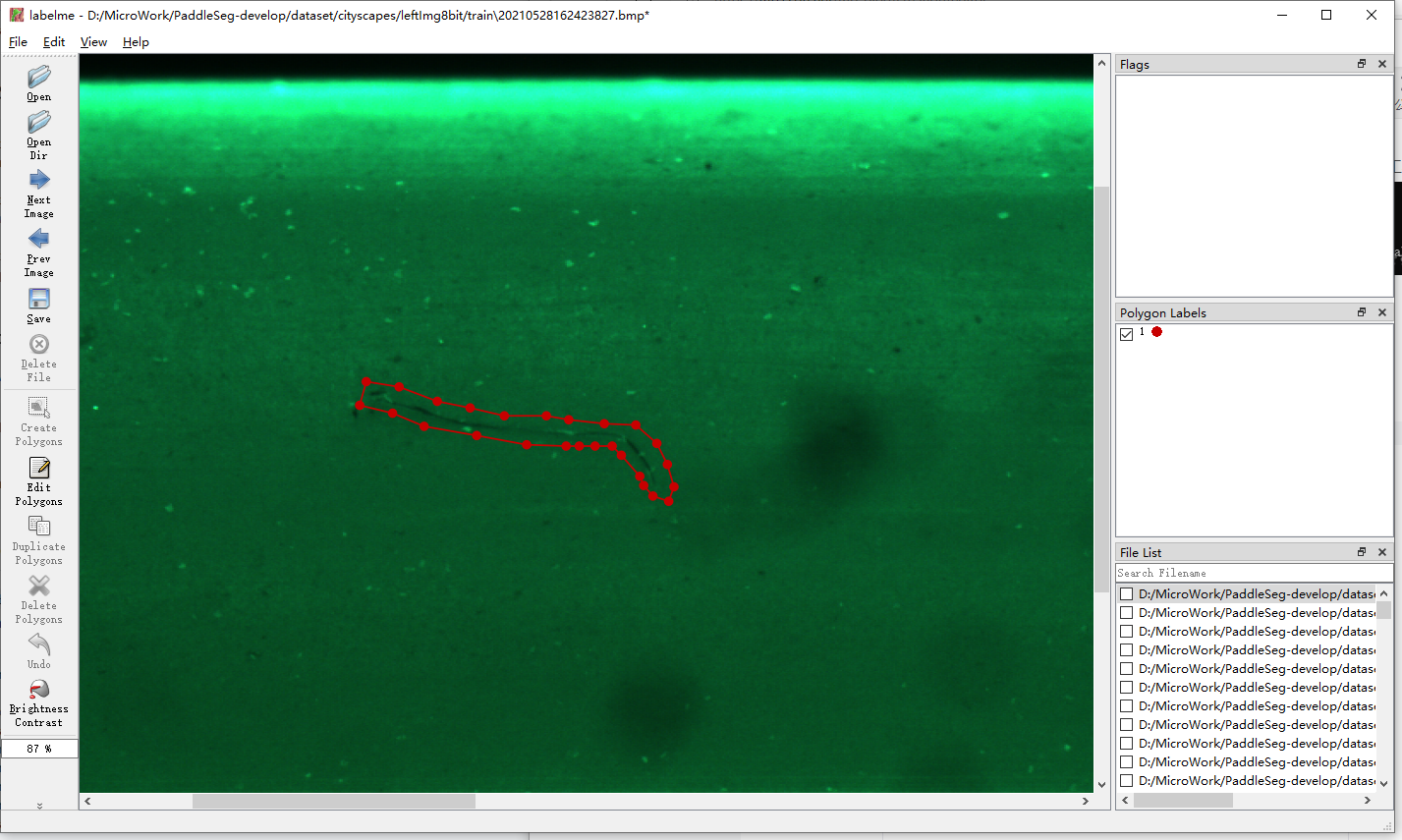
2:数据标注
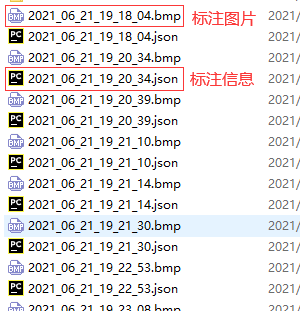
标注后生成的文件格式
输入以下命令,将 .json文件转换为训练所需的mask
python tools/labelme2seg.py <path to label_json_file>
</path>
其中, <path to label_json_file></path>为图片以及LabelMe产出的json文件所在文件夹的目录,同时也是转换后的标注集所在文件夹的目录。如下图所示。
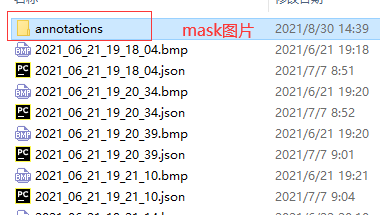
将.json文件另外存到一个文件夹备用 ,将图片和mask文件按照下面目录结构放置
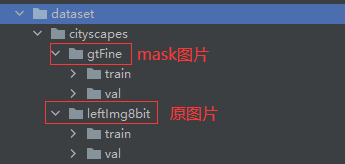
gtFine:图片标注
–train:用来训练
–val: 用来评估
leftImg8bit: 原始图片
–train:用来训练
–val: 用来评估
图片放置好以后 执行一下命令生成索引序列 用于训练
python tools/create_dataset_list.py
–folder leftImg8bit gtFine
–second_folder train val
–format bmp png
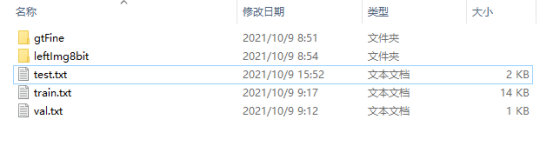
最终生成的只有 train.txt val.txt test.txt可以自己制作 没有也不影响训练
二:模型训练
第一步:配置文件
自己建立一个myselfdata.yml 下面是我自己建立的 不同的模型需要的配置文件不同根据报错可自行添加
batch_size: 1
iters: 8000
train_dataset:
type: Dataset
dataset_root: dataset/cityscapes
train_path: dataset/cityscapes/train.txt
num_classes: 19 #训练类别数目
transforms:
- type: ResizeStepScaling
min_scale_factor: 0.5
max_scale_factor: 2.0
scale_step_size: 0.25
- type: RandomPaddingCrop
crop_size: [1624, 594]
- type: RandomHorizontalFlip
- type: RandomDistort
brightness_range: 0.4
contrast_range: 0.4
saturation_range: 0.4
- type: Normalize
mode: train
val_dataset:
type: Dataset
dataset_root: dataset/cityscapes
val_path: dataset/cityscapes/val.txt
num_classes: 19
transforms:
- type: Resize
target_size: [1624, 594] # [3096, 1100]
- type: Normalize
mode: val
optimizer:
type: sgd
momentum: 0.9
weight_decay: 4.0e-5
lr_scheduler:
type: PolynomialDecay
learning_rate: 0.01
end_lr: 0
power: 0.9
loss:
types:
- type: CrossEntropyLoss
coef: [1]
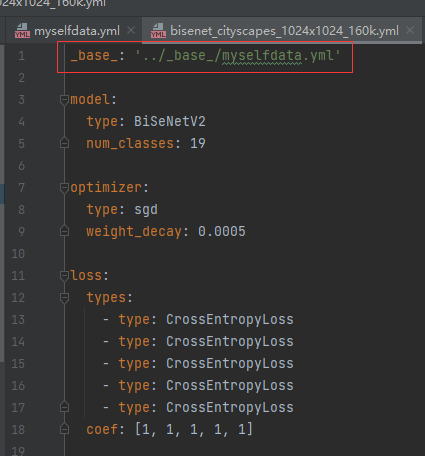
第二步:下面以bisenet_cityscapes_1024x1024_160k.yml模型为例。
打开配置文件,修改_base_的配置文件引用,如下图所示
第三步:开始训练
export CUDA_VISIBLE_DEVICES=0 # 设置1张可用的卡
windows下请执行以下命令
set CUDA_VISIBLE_DEVICES=0
python train.py \
–config configs/bisenet/bisenet_cityscapes_1024x1024_160k.yml
–do_eval \
–use_vdl \
–save_interval 500 \
–save_dir output
恢复训练
python train.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--resume_model output/iter_500 \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output
可视化预测
python predict.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--model_path output/iter_1000/model.pdparams \
--image_path dataset/optic_disc_seg/JPEGImages/H0003.jpg \
--save_dir output/result
Original: https://blog.csdn.net/weixin_39931579/article/details/120985795
Author: 私はいつも好きです樱岛麻衣
Title: 【PaddleSeg】使用自己制作的CityScapes数据集训练模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/692179/
转载文章受原作者版权保护。转载请注明原作者出处!