



系列索引:菜菜的深度学习笔记 | 基于Python的理论与实现;
文章目录
*
– (一)Affine层
– (二)Softmax层
– (三)误差反向传播法的实现
–
+ 1.神经网络的全貌
+ 2.手撕两层网络
(一)Affine层
神经网络中矩阵的乘积运算中 对应维度的元素个数要保持一致
神经网络的正向传播中进行的矩阵的乘积运算在几何学领域被称为” 仿射变换“,因此这里将进行仿射变换的处理实现为”Affine层”。
按矩阵的各个元素进行计算时,步骤和以标量为对象的计算图相同。
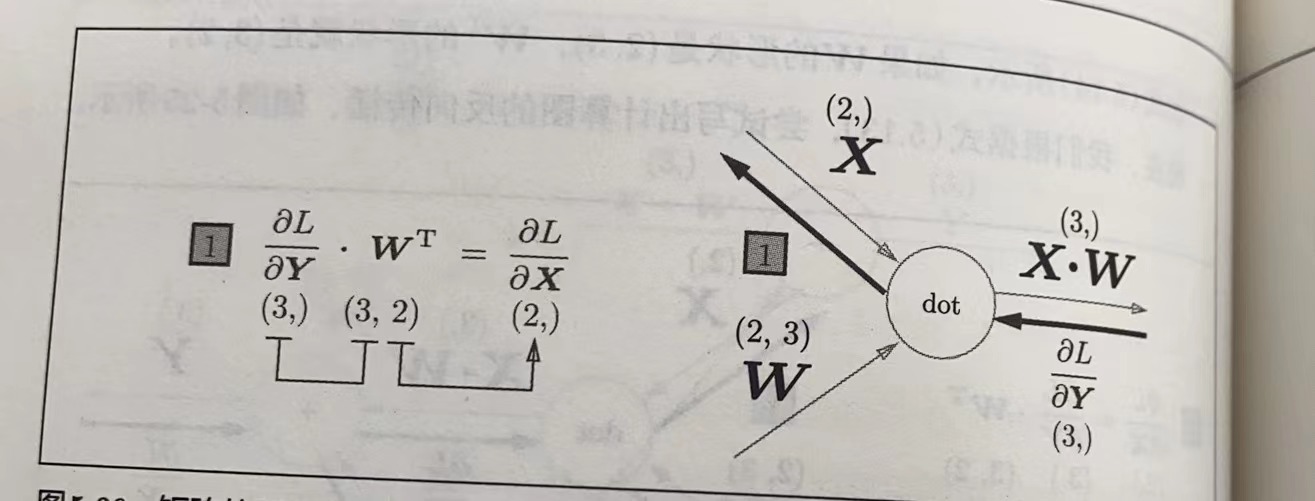
下图是
批版本的Affine层:
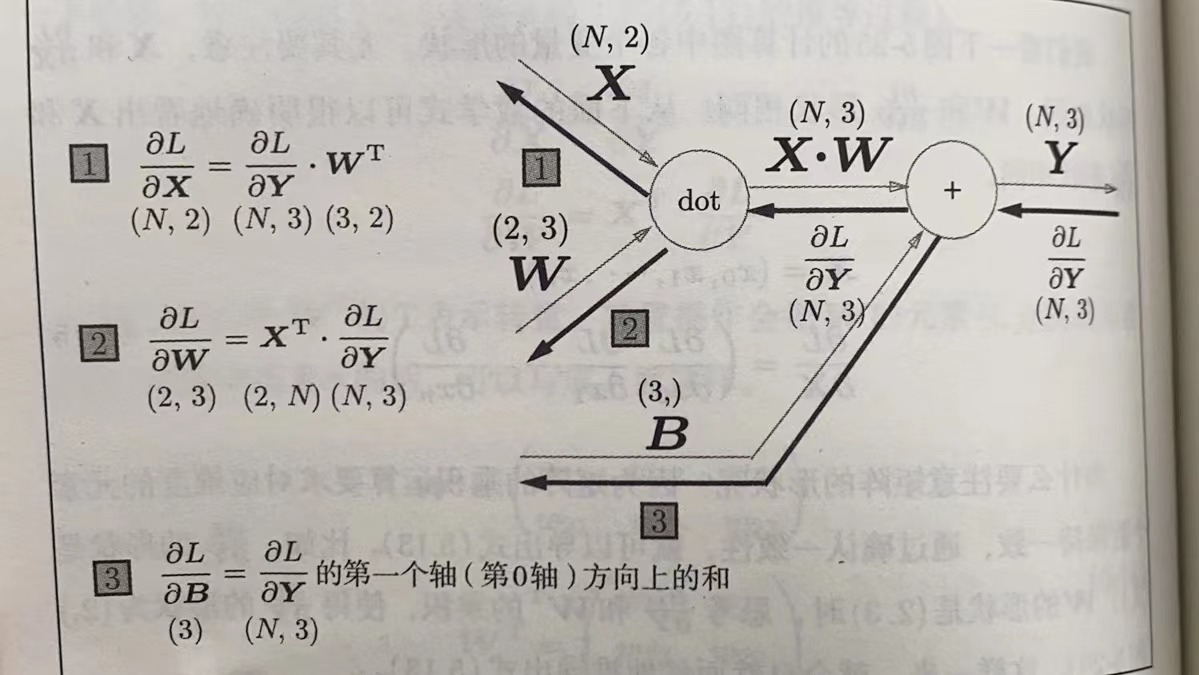
class Affine:
def __init__(self,W,b):
self.W = W
self.b = b
self.x = None
self.dW = None
self.db = None
def forward(self,x):
self.x = x
out = np.dot(x,self.W) + self.b
return out
def backward(self,dout):
dx = np.dot(dout,self.W.T)
self.dW = np.dot(self.x.T,dout)
self.db = np.sum(sout,axis=0)
return dx
(二)Softmax层
Softmax-with-Loss层位于 输出层,softmax函数会将输入值 正规化后在输出。
神经网络中进行的处理有 推理和 学习两个阶段,神经网络的推理通常不使用Softmax层,神经网络中未被正规化的输出结果被称为”得分”,此时只对得分最大值感兴趣,不过在学习阶段时需要softmax层。
神经网络的反向传播会将softmax层的输出与监督数据的差分表示的误差传递给前面的层,这是神经网络中的重要性质。
神经网络的目的就是 通过调整权重参数,使神经网络的输出接近监督标签。
使用交叉熵误差作为softmax函数的损失函数后,反向传播得到(y1-t1)这种形式的”漂亮”的结果, 使用”平方和误差”作为”恒等函数”的损失函数,反向传播才能得到这样的结果。
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None
self.t = None
def forward(self,x,t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y,self.t)
return self.loss
def backward(self,dout=1):
batch_size = self.t.shape[0]
dx = (self.y - self.t) / batch_size
return dx
(三)误差反向传播法的实现
1.神经网络的全貌
前提:神经网络有合适的权重和偏置,调整权重和偏置以便拟合训练数据的过程称为学习,分为以下四步骤。
- 步骤1(mini-batch) 从训练数据中随机选择一部分数据
- 步骤2(计算梯度) 计算损失函数关于各个权重参数的梯度
- 步骤3(更新参数) 将权重参数沿梯度方向进行微小的更新
- 步骤4(重复) 重复步骤1-3
2.手撕两层网络
import sys,os
sys.path.append(os.pardir)
import numpy as np
from common.layers import *
from common.gradient import numerical_gradient
from collections import OrderedDict
class TwoLayerNet:
def __init__(self,input_size,hidden_size,output_size,weight_init_std = 0.01):
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size,hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size,output_size)
self.params['b2'] = np.zeros(output_size)
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.lastLayer = SoftmaxWithLoss()
def predict(self,x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self,x,t):
y = self.predict(x)
return self.lastLayer.forward(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y,axies = 1)
if t.ndim != 1:
t = np.argmax(t, axis = 1)
accuracy = np.sum(y==t) / float(x,shape[0])
return accuracy
def numerical_gradient(self, x, t):
loss_W = lambda W:self.loss(x,t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
self.loss(x, t)
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
grads = {}
grads['W1'] = self.layers['Affine1'].dW
grads['b1'] = self.layers['Affine1'].db
grads['W2'] = self.layers['Affine2'].dW
grads['b2'] = self.layers['Affine2'].db
return grads
自己动手敲一遍效果比看十遍还要好!
下面看一段 微分求导法与 反向传播法的比较:
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
from twolayernet import TwoLayerNet
(x_train, t_train),(x_test, t_test) = load_mnist(normalize=True, one_hot_label= True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
x_batch = x_train[:3]
t_batch = t_train[:3]
grad_numerical = network.numerical_gradient(x_batch, t_batch)
grad_backprop = network.gradient(x_batch , t_batch)
for key in grad_numerical.keys():
diff = np.average(np.abs(grad_backprop[key] - grad_numerical[key]))
print(key+":"+str(diff))
W1:4.328233887775118e-10
b1:2.8681047496166956e-09
W2:6.111598311388141e-09
b2:1.3957577380263598e-07
可以看出数值微分和误差反向传播法求出的梯度 差非常小。
基于Python的理论与实现 系列持续更新,欢迎
点赞收藏+关注
上一篇:菜菜的深度学习笔记 | 基于Python的理论与实现(八)—>简单层的实现
下一篇:
本人水平有限,文章中不足之处欢迎下方👇评论区批评指正~
如果感觉对你有帮助,点个赞👍 支持一下吧 ~
不定期分享 有趣、有料、有营养内容,欢迎 订阅关注 🤝 我的博客 ,期待在这与你相遇 ~
Original: https://blog.csdn.net/Magic_Zsir/article/details/123447941
Author: 猿知
Title: 菜菜的深度学习笔记 | 基于Python的理论与实现(九)—>Affine层的实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/692043/
转载文章受原作者版权保护。转载请注明原作者出处!