



一、简介
本文提出了一个新的具有注意聚集和双向相互学习(ABM)的HMER框架,如图所示。模型包括三个模块:特征提取、注意聚合和双向促进学习。

(1)在特征提取模块(FEM)中,使用DenseNet作为特征提取器,因为它在WAP中被证明是有效的,从数学表达式图像中提取特征信息。
(2)在注意聚合模块(AAM)中,提出了多尺度覆盖注意,对齐历史注意信息,在解码阶段有效地聚合不同大小的尺度特征,来识别数学表达式中不同大小的字符,从而提高了当前的识别精度,缓解了误差积累的问题。
(3)在双向相互学习模块(BML)中,提出了一种新的解码器框架,有两个方向相反的并行解码器分支(L2R和R2L),并使用相互蒸馏来促进彼此学习。在训练过程中,每个解码器分支不仅可以学习ground truth的latex序列,还可以学习另一个分支的预测,提高解码能力.
二、方法

Feature Extraction Module
使用密集连接的卷积网络(DenseNet)作为编码器,从输入图像中提取特征。输出H×W×D的三维特征图F。值得注意的是,这里将输出特征视为M维的向量a={a1,a2,…,aM},其中ai∈RD,M=H×W。
Attention Aggregation Module
注意机制引导解码器聚焦于输入图像的特定区域,基于覆盖的注意力可以更好地跟踪对齐信息,并指导一个模型,将更高的注意力概率分配给未翻译区域。本文提出了注意聚集模块(AAM),在覆盖注意力上聚合不同的感受野。与传统的注意力机制相比,AAM不仅关注局部区域的详细特征,而且还关注更大的感受野的全局信息。因此,AAM能产生更精细的信息对齐,并帮助模型捕获更准确的空间关系。与DWAP-msa相比,本文的注意机制需要更少的参数和计算。使用隐藏状态ˆht、特征图F和覆盖注意βt来计算上下文向量,过程如下:首先,
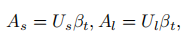 U_s和U_l分别表示小核和大核的卷积运算,βt表示过去所有注意概率之和,初始化为零向量,然后计算覆盖注意力αl为第l步时的注意力得分。当前的注意力图αt为Wˆh,Ws和Wl是可训练的权值矩阵,Uf是1×1卷积运算,hˆt表示等式中GRU生成的隐藏状态 。上下文向量记为ct,是特征内容信息a的加权和:其中αt,i是在步骤t时F的第i个特征的权重。
U_s和U_l分别表示小核和大核的卷积运算,βt表示过去所有注意概率之和,初始化为零向量,然后计算覆盖注意力αl为第l步时的注意力得分。当前的注意力图αt为Wˆh,Ws和Wl是可训练的权值矩阵,Uf是1×1卷积运算,hˆt表示等式中GRU生成的隐藏状态 。上下文向量记为ct,是特征内容信息a的加权和:其中αt,i是在步骤t时F的第i个特征的权重。
Bi-directional Mutual Learning Module
给定一个输入的数学表达式图像,传统的HMER方法从左到右解码(L2R),没有充分考虑长距离依赖性。因此,提出利用双流解码器将输入图像分成两个相反方向(L2R和R2L)的LaTex序列,然后相互学习解码信息。这两个分支具有相同的架构,只是在其解码方向上有所不同。L2R和R2L分支在步骤t处预测符号的概率计算如下:
 j
j

其中f1和f2分别代表单向的GRU单元。
对于两个分支输出的概率分布,作者引入自蒸馏思想,将两解码分支通过Kullback-Leibler (KL) 损失函数在每个时间步上对预测的软概率作为标签进行交互学习。对于k个字符类别,L2R的软概率分布定义为:

其中S是生成概率标签的温度参数。
由此可以得到L2R和R2L分支的KL距离为:

最终整体网络的目标为最小化两个分支的交叉熵损失与交互学习的KL损失之和:

三、实验与代码
两个不同的解码器分支被设置为不同的权重初始化方法。对于解码器,n=256,d=512,d=684和K=113(在111个标签基础上添加开始和结束符号)。损失函数λ=0.5。使用Adadelta优化器进行优化,其学习率从1开始,当WER在15个周期内不下降时,衰减幅度会小2倍。当学习率下降10倍时,训练就会停止。batchsize = 16。
与以前方法的比较,在训练过程中都没有使用数据增强。

消融实验,两个模块都可以提升准确率,并且两个模块的整体识别率相互促进。


文章所提出的两个方向(L2R 和 R2L)的 LaTeX 序列的覆盖注意力可视化过程。蓝色框表示当前时间步中正在解码的字符。

作者使用t-SNE进一步可视化CROHME 2014测试数据集上10个字符的特征分布。作者输入了所有之前的正确符号来解码当前的符号,并将分类器第一个全连接层之前的特征进行了可视化。可以看出,此方法的聚类效果更好。

python = 3.6 numpy = 1.19.4 torch = 1.6.0
除此之外,将双向交互学习应用在其他的解码器如GRU、LSTM、Transformer上,都可以在推理时不增加额外参数的前提下,很有效的提高它们的性能。
Original: https://blog.csdn.net/handsome_lionet/article/details/124101127
Author: Ashleyyyi
Title: 论文阅读:HMER via Attention Aggregation based Bi-directional Mutual Learning
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/691986/
转载文章受原作者版权保护。转载请注明原作者出处!