

文章目录


; 1. 简介
DPRNN提出的依据:因此如果出现超长的语音序列,使用传统的RNN模型将无法高效的处理。而一维卷积的感受野小于音频序列长度,因此无法进行utterance-level的语音分离。
DPRNN 是一种双路径递归神经网络,在深度模型上优化RNN,使其可以对极长的语音序列进行建模。其将较长的音频片段分成较小的块(chunk),迭代应用块内和块间操作。
当前时域的语音分离方法主要分为两个部分:自适应前端和直接回归
- 自适应前端方法:构建可学习的前端(Encoder)来代替STFT,生成类似时频图的特征作为分离模块的输入进行分离。这 个方法的好处是可以在窗口大小和前端基频数量方面有更多灵活的选择。代表模型为Conv-TasNet。
-
直接回归方法:通过一维卷积神经网络(1-D CNN)来学习混合语音到干净语音的映射关系,而无需明确的短时傅里叶变换。
-
模型架构

模型包含三个阶段:分段,块处理和重叠相加。
; 2.1 分段
该阶段将长序列输入数据分割成重叠的小块(chunk),并连接成3-D张量。
输入序列数据表示为W ∈ R N × L W \in R^{N \times L}W ∈R N ×L, 其中N表示特征维度(取决于Encoder部分的维度),L表示序列长度(时间步的长度)。将W分割成长度为K,块移(hop size)为P的块(chunk)。使用零扩展(zero-padding)处理第一个块和最后一个块。最终得到S个块,每块数据用D s ∈ R N × K D_s \in R^{N \times K}D s ∈R N ×K表示,所有块组成3-D张量T ∈ R N × K × S T \in R^{N \times K \times S}T ∈R N ×K ×S。
2.2 块处理
分块后的数据T输入到B个DPRNN块中进行处理。用b表示第b个DPRNN处理块,T b T_b T b 表示第b个处理块的输入数据。每个处理块包含块内处理和块间处理两个部分。块内处理是双向的,应用于输入数据的第二个维度,即在S个块的每个块内。

其中U b ∈ R H × K × S U_b \in R^{H \times K \times S}U b ∈R H ×K ×S表示RNN的输出,T b [ : , : , i ] ∈ R N × K T_b[:,:,i] \in R^{N \times K}T b [:,:,i ]∈R N ×K表示块i定义的序列。利用线性全连接层将U b U_b U b 转换回T b T_b T b 。


之后使用层归一化:
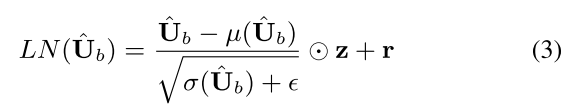
然后在LN层输出与块输入之间应用残差连接:

之后,T ^ b \hat{T}_b T ^b 作为块间RNN子模块的输入,块间RNN应用于输入数据的第三个维度:

块间处理中同样使用线性全连接、层归一化和残差连接。
; 2.3 重叠相加
将DPRNN处理的数据重叠相加,变换回原来的序列Q ∈ R N × L Q \in R^{N \times L}Q ∈R N ×L。
- 实验部分
采用Conv-TasNet相同的设置,encoder和decoder部分使用64个滤波器,separator部分使用6个DPRNN层,用BiLSTM实现,包含128个隐藏单元。
4秒长度的语音片段,训练100个周期,初始学习率1e-3,每两个周期衰减0.98,10个周期的early stop。Adam被用作优化器。 所有实验均使用最大L2范数为5的梯度削波。

Original: https://blog.csdn.net/aidanmo/article/details/123949566
Author: Aidanmomo
Title: DUAL-PATH RNN: EFFICIENT LONG SEQUENCE MODELING FOR TIME-DOMAIN SINGLE-CHANNEL SPEECH SEPARATIO
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/691733/
转载文章受原作者版权保护。转载请注明原作者出处!