

在神经网络的学习中,其中一个重要目的就是找到 使损失函数的值尽可能小的参数,为了找到这个最优参数,我们使用梯度(导数)作为线索,沿着梯度方向来更新参数,并重复这个步骤,从而逐渐靠近最优参数,这个过程叫做随机梯度下降法(SGD,Stochastic Gradient Descent),有兴趣的可以参阅下面我以前写的关于SGD的文章
Python随机梯度下降法(一)![]()
 https://blog.csdn.net/weixin_41896770/article/details/119950830 ;
https://blog.csdn.net/weixin_41896770/article/details/119950830 ;
Python随机梯度下降法(二)![]() https://blog.csdn.net/weixin_41896770/article/details/120074804 ;
https://blog.csdn.net/weixin_41896770/article/details/120074804 ;
Python随机梯度下降法(三)![]() https://blog.csdn.net/weixin_41896770/article/details/120151414 ;
https://blog.csdn.net/weixin_41896770/article/details/120151414 ;
Python随机梯度下降法(四)【完结篇】![]() https://blog.csdn.net/weixin_41896770/article/details/120264473 ;
https://blog.csdn.net/weixin_41896770/article/details/120264473 ;
这篇文章主要介绍另外几种寻找最优参数的方法,做一个比较,在此之前,我们先来看一个 探险家的故事:有一个奇怪的探险家,想在一片广袤的干旱地带,寻找到 最深的谷底,对于正常人来说这件事情不难,但是这次探险有两个条件,一个是不准看地图,另外一个就是蒙着眼睛,什么都不看。这样的前提条件,如何去寻找呢?那这个时候地面的坡度就是一个很重要的因素了,通过脚底来感受地面的倾斜状况,那么只需要朝着所在位置最大坡度的方向前进就好,再重复这个步骤,这样就可以找到最深的谷底了。
这个故事大家已经知道,其实是属于一个随机梯度下降的方法(SGD),现在我们通过等高线来模拟这个搜索路径
common.optimizer.py【后面的方法都在这个文件中】
import numpy as np
class SGD:
'''随机梯度下降法,lr是学习率'''
def __init__(self,lr=0.01):
self.lr=lr
def update(self,params,grads):
for i in params.keys():
params[i]-=self.lr*grads[i]
parameter_optimizers.py 【】
SGD的数学式: (其中 W 是权重参数, 是学习率, 是损失函数关于权重的梯度)
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
from common.optimizer import *
def f(x,y):
return 1/20*x**2 + y**2
def df(x,y):
'''f函数的偏导数'''
return 1/10*x,2*y
params={}
params['x'],params['y']=-7,2#从(-7,2)的位置开始搜索
grads={}
grads['x'],grads['y']=0,0
mySGD=SGD(lr=0.9)
x_temp=[]
y_temp=[]
for i in range(30):
x_temp.append(params['x'])
y_temp.append(params['y'])
grads['x'],grads['y']=df(params['x'],params['y'])
mySGD.update(params,grads)
#画函数f的等高线
x=np.arange(-10,10,0.01)
y=np.arange(-5,5,0.01)
X,Y=np.meshgrid(x,y)
Z=f(X,Y)
plt.plot(x_temp,y_temp,'o-',color='red')
plt.contour(X,Y,Z)
plt.plot(0,0,'+')
plt.show()
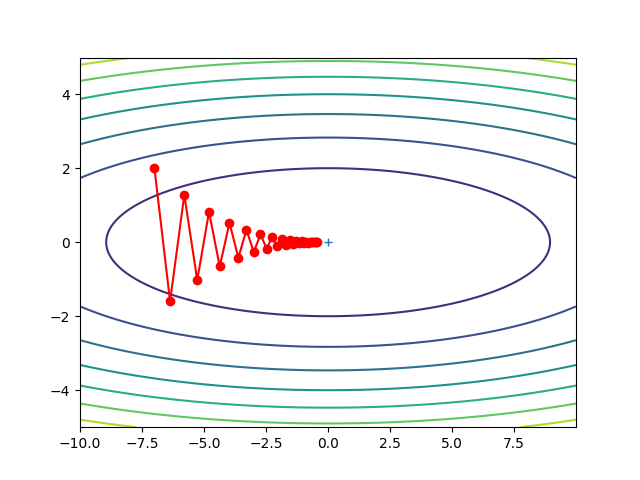
从图中可以看出搜索路径呈现”之”字形往(0,0)方向移动,效率比较低,现在我们把另外三个方法Momentum,AdaGrad,Adam,放在一起进行比较。
Momentum:
数学式:
和前面SGD公式一样,其中 W 是权重参数,
是学习率,是损失函数关于权重的梯度,α变量类似地面摩擦力,设定0.9之类的值,v变量,对应物理的速度,表示物体在梯度方向上受力,在这个力的作用下,物体的速度增加这一物理法则。其中v以字典型变量的形式保存与参数结构相同的数据
class Momentum:
'''动量SGD,模拟小球在地面滚动'''
def __init__(self,lr=0.01,momentum=0.9):
self.lr=lr
self.momentum=momentum
self.v=None
def update(self,params,grads):
if self.v is None:
self.v={}
for k,v in params.items():
self.v[k]=np.zeros_like(v)
for k in params.keys():
self.v[k]=self.momentum*self.v[k]-self.lr*grads[k]
params[k]+=self.v[k]
AdaGrad:
数学式:
和前面公式比较,多了一个h的参数,这个参数是保存所有 梯度值的平方和(矩阵的乘法),由于在神经网络的学习中,学习率的值很重要,过小会导致花费时间过多,过大就会导致学习发散而不能正确进行,所以在更新参数的时候,乘以一个
可以调整学习的尺度,换句话说就是参数的元素中变动较大的元素,学习率将变小。
class AdaGrad:
'''调节学习率的SGD'''
def __init__(self,lr=0.01):
self.lr=lr
self.h=None
def update(self,params,grads):
if self.h is None:
self.h={}
for k,v in params.items():
self.h[k]=np.zeros_like(v)
for k in params.keys():
self.h[k]=self.h[k]+grads[k]*grads[k]
params[k]-=self.lr*grads[k]/(np.sqrt(self.h[k])+1e-7)#加一个微小值防止为0
Adam:
数学式:
是AdaGrad和Momentum方法的融合,稍微复杂点,这个方法的目的就是类似小球滚动,而且通过调节更新参数让小球左右晃动的程度有所减轻。
class Adam:
'''融合Momentum和AdaGrad'''
def __init__(self,lr=0.01,beta1=0.9,beta2=0.999):
self.lr=lr
self.beta1=beta1
self.beta2=beta2
self.iter=0
self.m=None
self.v=None
def update(self,params,grads):
if self.m is None:
self.m,self.v={},{}
for k,v in params.items():
self.m[k]=np.zeros_like(v)
self.v[k]=np.zeros_like(v)
self.iter+=1
lr_t=self.lr*np.sqrt(1.0-self.beta2**self.iter)/(1.0-self.beta1**self.iter)
for k in params.keys():
self.m[k]=self.beta1*self.m[k]+(1-self.beta1)*grads[k]
self.v[k]=self.beta2*self.v[k]+(1-self.beta2)*(grads[k]**2)
params[k]-=lr_t*self.m[k]/(np.sqrt(self.v[k])+1e-7)
我们将四个方法画图显示:
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
from common.optimizer import *
def f(x,y):
return 1/20*x**2 + y**2
def df(x,y):
'''f函数的偏导数'''
return 1/10*x,2*y
params={}
#params['x'],params['y']=-7,2#从(-7,2)的位置开始搜索
grads={}
grads['x'],grads['y']=0,0
#使用有序字典保存四种方法,分别遍历进行画图
mySGDDict=OrderedDict()
mySGDDict['SGD']=SGD(lr=0.9)
mySGDDict['Momentum']=Momentum(lr=0.1)
mySGDDict['AdaGrad']=AdaGrad(lr=1.5)
mySGDDict['Aam']=Adam(lr=0.3)
idx=1
for k in mySGDDict:
mySGD=mySGDDict[k]
x_temp=[]
y_temp=[]
params['x'],params['y']=-7,2#分别从(-7,2)的位置开始搜索
for i in range(30):
x_temp.append(params['x'])
y_temp.append(params['y'])
grads['x'],grads['y']=df(params['x'],params['y'])
mySGD.update(params,grads)
#画函数f的等高线
x=np.arange(-10,10,0.01)
y=np.arange(-5,5,0.01)
X,Y=np.meshgrid(x,y)
Z=f(X,Y)
plt.subplot(2,2,idx)#画子图
idx+=1
plt.plot(x_temp,y_temp,'o-',color='red')
plt.contour(X,Y,Z)
plt.plot(0,0,'+')
plt.title(k)
plt.show()
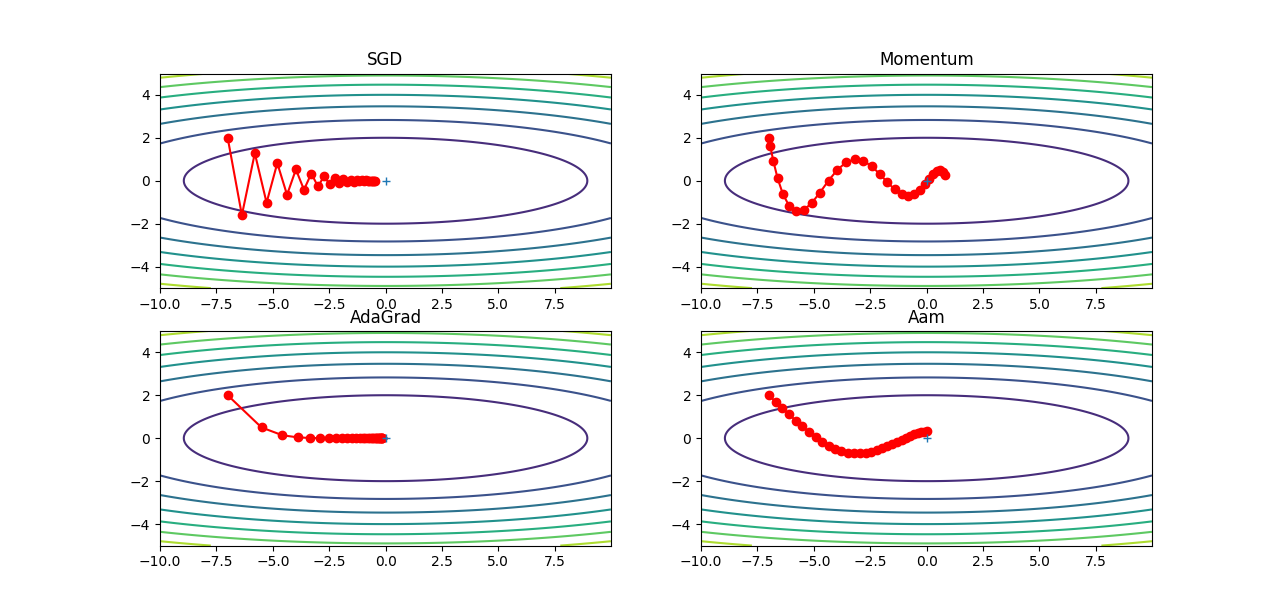
Original: https://blog.csdn.net/weixin_41896770/article/details/121375510
Author: 寅恪光潜
Title: 神经网络技巧篇之寻找最优参数的方法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/691623/
转载文章受原作者版权保护。转载请注明原作者出处!