

黑马头条排序模型进阶
7.1 神经网络基础与原理
学习目标
- 目标
- 了解感知机结构、作用以及优缺点
- 了解tensorflow playground的使用
- 说明感知机与神经网络的联系
- 说明神经网络的组成
- 说明神经网络的分类原理
- 说明softmax回归
- 说明交叉熵损失
- 应用
- 无
7.1.1 神经网络
人工神经网络( Artificial Neural Network, 简写为ANN)也简称为神经网络(NN)。是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)结构和功能的 计算模型。经典的神经网络结构包含三个层次的神经网络。 分别输入层,输出层以及隐藏层。


其中每层的圆圈代表一个神经元,隐藏层和输出层的神经元有输入的数据计算后输出,输入层的神经元只是输入。
- 神经网络的特点
- 每个连接都有个权值
- 同一层神经元之间没有连接
- 最后的输出结果对应的层也称之为 *全连接层
神经网络是深度学习的重要算法,用途在图像(如图像的分类、检测)和自然语言处理(如文本分类、聊天等)
那么为什么设计这样的结构呢?首先从一个最基础的结构说起,神经元。以前也称之为感知机。神经元就是要模拟人的神经元结构。

一个神经元通常具有多个 树突,主要用来接受传入信息;而 轴突只有一条,轴突尾端有许多轴突末梢可以给其他多个神经元传递信息。轴突末梢跟其他神经元的树突产生连接,从而传递信号。这个连接的位置在生物学上叫做” 突触“。
要理解神经网络,其实要从感知机开始。
; 7.1.1.1 感知机(PLA: Perceptron Learning Algorithm))
感知机就是模拟这样的大脑神经网络处理数据的过程。感知机模型如下图:

感知机是一种最基础的分类模型,前半部分类似于回归模型。感知机最基础是这样的函数,而逻辑回归用的sigmoid。 这个感知机具有连接的权重和偏置

我们通过一个平台去演示,就是tensorflow playground
7.1.2 playground使用

网址:http://playground.tensorflow.org
那么在这整个分类过程当中,是怎么做到这样的效果那要受益于神经网络的一些特点

要区分一个数据点是橙色的还是蓝色的,你该如何编写代码?也许你会像下面一样任意画一条对角线来分隔两组数据点,定义一个阈值以确定每个数据点属于哪一个组。
其中 b 是确定线的位置的阈值。通过分别为 x1 和 x2 赋予权重 w1 和 w2,你可以使你的代码的复用性更强。

此外,如果你调整 w1 和 w2 的值,你可以按你喜欢的方式调整线的角度。你也可以调整 b 的值来移动线的位置。所以你可以重复使用这个条件来分类任何可以被一条直线分类的数据集。但问题的关键是程序员必须为 w1、w2 和 b 找到合适的值——即所谓的参数值,然后指示计算机如何分类这些数据点。
; 7.1.2.1 playground简单两类分类结果

但是这种结构的线性的二分类器,但不能对非线性的数据并不能进行有效的分类。
感知机结构,能够很好去解决与、或等问题,但是并不能很好的解决异或等问题。我们通过一张图来看,有四个样本数据
与问题:每个样本的两个特征同时为1,结果为1
或问题:每个样本的两个特征一个为1,结果为1
异或:每个样本的两个特征相同为0, 不同为1
根据上述的规则来进行划分,我们很容易建立一个线性模型

; 相当于给出这样的数据


7.1.2.2 单神经元复杂的两类-playground演示

; 那么怎么解决这种问题呢?其实我们多增加几个感知机即可解决?也就是下图这样的结构,组成一层的结构?

7.1.2.3 多个神经元效果演示

神经网络的主要用途在于分类,那么整个神经网络分类的原理是怎么样的?我们还是围绕着损失、优化这两块去说。神经网络输出结果如何分类?

神经网络解决多分类问题最常用的方法是设置n个输出节点,其中n为类别的个数。
任意事件发生的概率都在0和1之间,且总有某一个事件发生(概率的和为1)。如果将分类问题中”一个样例属于某一个类别”看成一个概率事件,那么训练数据的正确答案就符合一个概率分布。如何将神经网络前向传播得到的结果也变成概率分布呢?Softmax回归就是一个常用的方法。
; 7.1.3 softmax回归
Softmax回归将神经网络输出转换成概率结果

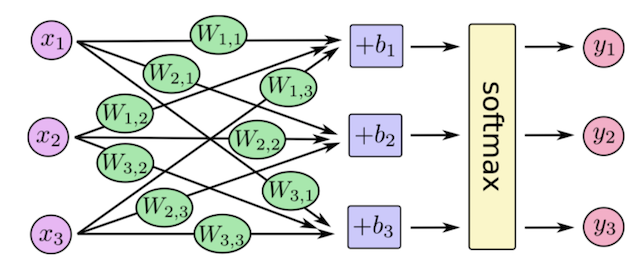

- softmax特点
如何理解这个公式的作用呢?看一下计算案例
假设输出结果为:2.3, 4.1, 5.6
softmax的计算输出结果为:
y1_p = e^2.3/(e^2.3+e^4.1+e^5.6)
y1_p = e^4.1/(e^2.3+e^4.1+e^5.6)
y1_p = e^5.6/(e^2.3+e^4.1+e^5.6)
这样就把神经网络的输出也变成了一个概率输出

那么如何去衡量神经网络预测的概率分布和真实答案的概率分布之间的距离?
7.1.4 交叉熵损失
7.1.4.1 公式

为了能够衡量距离,目标值需要进行one-hot编码,能与概率值一一对应,如下图

它的损失如何计算?
0log(0.10)+0log(0.05)+0log(0.15)+0log(0.10)+0log(0.05)+0log(0.20)+1log(0.10)+0log(0.05)+0log(0.10)+0log(0.10)
上述的结果为1log(0.10),那么为了减少这一个样本的损失。神经网络应该怎么做?所以会提高对应目标值为1的位置输出概率大小,由于softmax公式影响,其它的概率必定会减少。只要这样进行调整这样是不是就预测成功了!!!!!
提高对应目标值为1的位置输出概率大小
7.1.4.2 损失大小
神经网络最后的损失为平均每个样本的损失大小。对所有样本的损失求和取其平均值
7.1.5 梯度下降算法
目的:使损失函数的值找到最小值
方式:梯度下降
函数的梯度(gradient)指出了函数的最陡增长方向。 梯度的方向走,函数增长得就越快。那么按梯度的负方向走,函数值自然就降低得最快了。模型的训练目标即是寻找合适的 w 与 b 以最小化代价函数值。假设 w 与 b 都是一维实数,那么可以得到如下的 J 关于 w 与 b 的图:

可以看到,此成本函数 J 是一个 凸函数
参数w和b的更新公式为:
w := w – \alpha\frac{dJ(w, b)}{dw} w:= w− α d w d J(w, b),b := b – \alpha\frac{dJ(w, b)}{db} b:= b− α d b d J(w, b)
注:其中 α 表示学习速率,即每次更新的 w 的步伐长度。当 w 大于最优解 w′ 时,导数大于 0,那么 w 就会向更小的方向更新。反之当 w 小于最优解 w′ 时,导数小于 0,那么 w 就会向更大的方向更新。迭代直到收敛。
通过平面来理解梯度下降过程:

; 7.1.6 网络原理总结
我们不会详细地讨论可以如何使用反向传播和梯度下降等算法训练参数。 训练过程中的计算机会尝试一点点增大或减小每个参数,看其能如何减少相比于训练数据集的误差,以望能找到最优的权重、偏置参数组合。


7.1.7 Sequential构建简单单层神经网络模型
Sequential模型是层的线性堆栈。我们可以 Sequential通过将层实例列表传递给构造函数来创建模型:
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([
Dense(32, input_shape=(784,)),
])
同样可以用add方法来添加模型
model = Sequential()
model.add(Dense(32, input_dim=784))
7.2 案例:DNN进行分类
学习目标
- 目标
- 知道tf.data.Dataset的API使用
- 知道tf.feature_columnAPI使用
- 知道tf.estimatorAPI使用
- 应用
- 无
7.2.1 数据集介绍
对鸢尾花进行分类:概览
本文档中的示例程序构建并测试了一个模型,此模型根据鸢尾花的 花萼和 花瓣大小将其分为三种不同的品种。

从左到右:山鸢尾(提供者:Radomil,依据 CC BY-SA 3.0 使用)、变色鸢尾(提供者:Dlanglois,依据 CC BY-SA 3.0 使用)和维吉尼亚鸢尾(提供者:Frank Mayfield,依据 CC BY-SA 2.0 使用)。
数据集
鸢尾花数据集包含四个特征和一个目标值。这四个特征确定了单株鸢尾花的下列植物学特征:
- 花萼长度
- 花萼宽度
- 花瓣长度
- 花瓣宽度
该标签确定了鸢尾花品种,品种必须是下列任意一种:
- 山鸢尾 (0)
- 变色鸢尾 (1)
- 维吉尼亚鸢尾 (2)
我们的模型会将该标签表示为 int32 分类数据。
下表显示了数据集中的三个样本:
花萼长度花萼宽度花瓣长度花瓣宽度品种(标签)5.13.31.70.50(山鸢尾)5.02.33.31.01(变色鸢尾)6.42.85.62.22(维吉尼亚鸢尾)
; 7.2.2 构建模型
该程序会训练一个具有以下拓扑结构的深度神经网络分类器模型:
- 2 个隐藏层。
- 每个隐藏层包含 10 个节点。
下图展示了特征、隐藏层和预测(并未显示隐藏层中的所有节点):

Estimator 是从 tf.estimator.Estimator衍生而来的任何类。要根据预创建的 Estimator 编写 TensorFlow 程序,您必须执行下列任务:
- 1、 创建一个或多个输入函数。
- 2、定义模型的特征列。
- 3、实例化 Estimator,指定特征列和各种超参数。
- 5、在 Estimator 对象上调用一个或多个方法,传递适当的输入函数作为数据的来源。
7.2.3 数据获取与输入函数
在iris_data文件中通过
def load_data(y_name='Species'):
"""获取训练测试数据"""
train_path, test_path = maybe_download()
train = pd.read_csv(train_path, names=CSV_COLUMN_NAMES, header=0)
train_x, train_y = train, train.pop(y_name)
test = pd.read_csv(test_path, names=CSV_COLUMN_NAMES, header=0)
test_x, test_y = test, test.pop(y_name)
return (train_x, train_y), (test_x, test_y)
(train_x, train_y), (test_x, test_y) = iris_data.load_data()
输入函数是返回 tf.data.Dataset 对象的函数,此对象会输出下列含有两个元素的元组:
*
features
:Python 字典,其中:
– 每个键都是特征的名称。
– 每个值都是包含此特征所有值的数组。
* label – 包含每个样本的标签值的数组。
def input_evaluation_set():
features = {'SepalLength': np.array([6.4, 5.0]),
'SepalWidth': np.array([2.8, 2.3]),
'PetalLength': np.array([5.6, 3.3]),
'PetalWidth': np.array([2.2, 1.0])}
labels = np.array([2, 1])
return features, labels
输入函数可以以您需要的任何方式生成 features 字典和 label 列表。不过,我们建议使用 TensorFlow 的 Dataset API,它可以解析各种数据。概括来讲,Dataset API 包含下列类:

Dataset– 包含创建和转换数据集的方法的基类。您还可以通过该类从内存中的数据或 Python 生成器初始化数据集。TextLineDataset– 从文本文件中读取行。TFRecordDataset– 从 TFRecord 文件中读取记录。FixedLengthRecordDataset– 从二进制文件中读取具有固定大小的记录。Iterator– 提供一次访问一个数据集元素的方法。
def train_input_fn(features, labels, batch_size):
"""
"""
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
dataset = dataset.shuffle(1000).repeat().batch(batch_size)
return dataset
def eval_input_fn(features, labels, batch_size):
"""
"""
features = dict(features)
if labels is None:
inputs = features
else:
inputs = (features, labels)
dataset = tf.data.Dataset.from_tensor_slices(inputs)
dataset = dataset.batch(batch_size)
return dataset
dataset.make_one_shot_iterator().get_next()
7.2.3 特征处理tf.feature_colum
特征处理tf.feature_column
Estimator 的 feature_columns 参数来指定模型的输入。特征列在输入数据(由 input_fn返回)与模型之间架起了桥梁。要创建特征列,请调用 tf.feature_column 模块的函数。本文档介绍了该模块中的 9 个函数。如下图所示,除了 bucketized_column 外的函数要么返回一个 Categorical Column 对象,要么返回一个 Dense Column 对象。

要创建特征列,请调用 tf.feature_column 模块的函数。本文档介绍了该模块中的 9 个函数。如下图所示,除了 bucketized_column 外的函数要么返回一个 Categorical Column 对象,要么返回一个 Dense Column 对象。

- Numeric column(数值列)
Iris 分类器对所有输入特徵调用 tf.feature_column.numeric_column 函数:SepalLength、SepalWidth、PetalLength、PetalWidth
tf.feature_column 有许多可选参数。如果不指定可选参数,将默认指定该特征列的数值类型为 tf.float32。
numeric_feature_column = tf.feature_column.numeric_column(key="SepalLength")
- Bucketized column(分桶列)
通常,我们不直接将一个数值直接传给模型,而是根据数值范围将其值分为不同的 categories。上述功能可以通过 tf.feature_column.bucketized_column 实现。以表示房屋建造年份的原始数据为例。我们并非以标量数值列表示年份,而是将年份分成下列四个分桶:
首先,将原始输入转换为一个numeric column
numeric_feature_column = tf.feature_column.numeric_column("Year")
然后,按照边界[1960,1980,2000]将numeric column进行bucket
bucketized_feature_column = tf.feature_column.bucketized_column(
source_column = numeric_feature_column,
boundaries = [1960, 1980, 2000])
- Categorical identity column(类别标识列)
输入的列数据就是为固定的离散值,假设您想要表示整数范围 [0, 4)。在这种情况下,分类标识映射如下所示:

identity_feature_column = tf.feature_column.categorical_column_with_identity(
key='my_feature_b',
num_buckets=4)
- Categorical vocabulary column(类别词汇表)
我们不能直接向模型中输入字符串。我们必须首先将字符串映射为数值或类别值。Categorical vocabulary column 可以将字符串表示为 one_hot格式的向量。

vocabulary_feature_column =
tf.feature_column.categorical_column_with_vocabulary_list(
key=feature_name_from_input_fn,
vocabulary_list=["kitchenware", "electronics", "sports"])
- Hashed Column(哈希列)
处理的示例都包含很少的类别。但当类别的数量特别大时,我们不可能为每个词汇或整数设置单独的类别,因为这将会消耗非常大的内存。对于此类情况,我们可以反问自己:”我愿意为我的输入设置多少类别?
hashed_feature_column =
tf.feature_column.categorical_column_with_hash_bucket(
key = "some_feature",
hash_bucket_size = 100)

- 其它列处理
- Crossed column(组合列)
7.2.4 实例化 Estimator
鸢尾花分类本身问题不复杂,一般算法也能够解决。这里我么你选用DNN做测试tf.estimator.DNNClassifier 我们将如下所示地实例化此 Estimator:
我们已经有一个 Estimator 对象,现在可以调用方法来执行下列操作:
- 训练模型。
- 评估经过训练的模型。
- 使用经过训练的模型进行预测。
训练模型
通过调用 Estimator 的 train 方法训练模型,如下所示:
classifier.train(
input_fn=lambda:iris_data.train_input_fn(train_x, train_y, args.batch_size),
steps=args.train_steps)
我们将 input_fn 调用封装在 lambda 中以获取参数,同时提供一个不采用任何参数的输入函数,正如 Estimator 预计的那样。 steps 参数告知方法在训练多步后停止训练。
评估经过训练的模型
模型已经过训练,现在我们可以获取一些关于其效果的统计信息。以下代码块会评估经过训练的模型对测试数据进行预测的准确率:
eval_result = classifier.evaluate(
input_fn=lambda:iris_data.eval_input_fn(test_x, test_y, args.batch_size))
print('\nTest set accuracy: {accuracy:0.3f}\n'.format(**eval_result))
与我们对 train 方法的调用不同,我们没有传递 steps 参数来进行评估。我们的 eval_input_fn 只生成一个周期的数据。
运行此代码会生成以下输出(或类似输出):
Test set accuracy: 0.967
8.3 深度学习与排序模型发展
学习目标
- 目标
- 了解深度学习排序模型的发展
- 应用
- 无
8.3.1 模型发展
CTR/CVR预估经历了从传统机器学习模型到深度学习模型的过渡。下面先简单介绍下传统机器学习模型(GBDT、LR、到深度模型及应用,然后再详细介绍在深度学习模型的迭代。
LR

y(\mathbf{x}) = sigmoid(w_0+ \sum_{i=1}^n w_i x_i) y(x)= s i g m o i d(w_0+∑ _i=1 n w i x i)
LR可以视作单层单节点的”DNN”, 是一种宽而不深的结构,所有的特征直接作用在最后的输出结果上。模型优点是简单、可控性好,但是效果的好坏直接取决于特征工程的程度,需要非常精细的连续型、离散型、时间型等特征处理及特征组合。通常通过正则化等方式控制过拟合。
; FM & FFM
FM可以看做带特征交叉的LR,如下图所示:

y(\mathbf{x}) = w_0 + \sum_{i=1}^n w_i x_i + \sum_{i=1}^n \sum_{j=i+1}^n \langle \mathbf{v} {i, f_j}, \mathbf{v}{j, f_i} \rangle x_i x_j y(x)= w_0+∑ _i=1 n w i x i+∑ i=1 n∑ j= i+1 n⟨ v i, fj_, v j, _fi⟩ x i x**j
模型覆盖了LR的宽模型结构,同时也引入了交叉特征,增加模型的非线性,提升模型容量,能捕捉更多的信息,对于CTR预估等复杂场景有更好的捕捉。
- 特征交叉:
- 例子:年龄:[1990,2000],[2000,2010]
- 性别:male, female
- 交叉特征:male and [1990,2000],female and [1990,2000] ,male and [2000,2010], female and [2000, 2010]
DNN
实验表明从线性的LR到具备非线性交叉的FM,到具备Field信息交叉的FFM,模型复杂度(模型容量)的提升,带来的都是结果的提升。而LR和FM/FFM可以视作简单的浅层神经网络模型,基于下面一些考虑,我们在把CTR模型切换到深度学习神经网络模型:
- 通过改进模型结构, 加入深度结构,利用端到端的结构挖掘高阶非线性特征,以及浅层模型无法捕捉的潜在模式。
- 对于某些ID类特别稀疏的特征,可以在模型中学习到保持分布关系的稠密表达(embedding)。
- 充分利用图片和文本等在简单模型中不好利用的信息。
Wide & Deep
首先尝试的是Google提出的经典模型Wide & Deep Model,模型包含Wide和Deep两个部分(LR+DNN的结合)
- 其中Wide部分可以很好地学习样本中的高频部分,在LR中使用到的特征可以直接在这个部分使用,但对于没有见过的ID类特征,模型学习能力较差,同时合理的人工特征工程对于这个部分的表达有帮助。
- 根据人工经验、业务背景,将我们认为有价值的、显而易见的特征及特征组合,喂入Wide侧。
- Deep部分可以补充学习样本中的长尾部分,同时提高模型的泛化能力。Wide和Deep部分在这个端到端的模型里会联合训练。
- 通过embedding将tag向量化,变tag的精确匹配,为tag向量的模糊查找,使自己具备了良好的”扩展”能力。
8.3.2 类别特征在推荐系统中作用
注:深度学习的这一波热潮,发源于CNN在图像识别上所取得的巨大成功,后来才扩展到推荐、搜索等领域。但是实际上,推荐系统中所使用的深度学习与计算机视觉中用到的深度学习有很大不同。其中一个重要不同,就是图像都是稠密特征,而推荐、搜索中大量用到的是稀疏的类别/ID类特
优点:
- LR, DNN在底层还是一个线性模型,但是实际工业中, 标签y与特征x之间较少存在线性关系,而往往是分段的。以”点击率历史曝光次数”之间的关系为例,之前曝光过1、2次的时候,”点击率历史曝光次数”之间一般是正相关的,再多曝光1、2次,用户由于好奇,没准就点击了;但是,如果已经曝光过8、9次了,由于用户已经失去了新鲜感,越多曝光,用户越不可能再点,这时”点击率~历史曝光次数”就表现出负相关性。因此,categorical特征相比于numeric特征,更加符合现实场景。
- 推荐、搜索一般都是基于用户、商品的标签画像系统,而标签大多数都是categorical的
- 稀疏的类别/ID类特征,可以 稀疏地存储、传输、运算,提升运算效率。
缺点:
稀疏的categorical/ID类特征,也有着 单个特征表达能力弱、特征组合爆炸、分布不均匀导致受训程度不均匀的缺点。为此,一系列的新技术被提出来:
- 算法上,FTRL这样的算法,充分利用输入的稀疏性在线更新模型,训练出的模型也是稀疏的,便于快速预测。
- TensorFlow Feature Column类,除了一个numeric_column是处理实数特征的,其实的都是围绕处理categorical特征的,封装了常见的分桶、交叉、哈希等操作。
- 深度学习与交叉特征的应用也会增加效果
5.8 排序模型进阶-FTRL
学习目标
- 目标
- 无
- 应用
- 无
5.8.1 问题
在实际项目的时候,经常会遇到训练数据非常大导致一些算法实际上不能操作的问题。比如在推荐行业中,因为DSP的请求数据量特别大,一个星期的数据往往有上百G,这种级别的数据在训练的时候,直接套用一些算法框架是没办法训练的,基本上在特征工程的阶段就一筹莫展。通常采用采样、截断的方式获取更小的数据集,或者使用大数据集群的方式进行训练,但是这两种方式在作者看来目前存在两个问题:
- 采样数据或者截断数据的方式,非常的依赖前期的数据分析以及经验。
- 大数据集群的方式,目前spark原生支持的机器学习模型比较少;使用第三方的算法模型的话,需要spark集群的2.3以上;而且spark训练出来的模型往往比较复杂,实际线上运行的时候,对内存以及QPS的压力比较大。

; 5.8.2 在线优化算法-Online-learning
- 模型更新周期慢,不能有效反映线上的变化,最快小时级别,一般是天级别甚至周级别。
- 模型参数少,预测的效果差;模型参数多线上predict的时候需要内存大,QPS无法保证。
- 对1采用On-line-learning的算法。
- 对2采用一些优化的方法,在保证精度的前提下,尽量获取稀疏解,从而降低模型参数的数量。
比较出名的在线最优化的方法有:
- TG(Truncated Gradient)
- FOBOS(Forward-Backward Splitting)
- RDA(Regularized Dual Averaging)
- *FTRL(Follow the Regularized Leader)
SGD算法是常用的online learning算法,它能学习出不错的模型,但学出的模型不是稀疏的。为此,学术界和工业界都在研究这样一种online learning算法,它能学习出有效的且稀疏的模型
5.8.2 FTRL
- 一种获得稀疏模型的优化方法
5.8.3 离线数据训练FTRL模型
- 目的:通过离线TFRecords样本数据,训练FTRL模型
- 步骤:
- 1、构建模型
- 2、构建TFRecords的输入数据
- 3、train训练以及预测测试
完整代码:
import tensorflow as tf
from tensorflow.python import keras
class LrWithFtrl(object):
"""LR以FTRL方式优化
"""
def __init__(self):
self.model = keras.Sequential([
keras.layers.Dense(1, activation='sigmoid', input_shape=(121,))
])
@staticmethod
def read_ctr_records():
def parse_tfrecords_function(example_proto):
features = {
"label": tf.FixedLenFeature([], tf.int64),
"feature": tf.FixedLenFeature([], tf.string)
}
parsed_features = tf.parse_single_example(example_proto, features)
feature = tf.decode_raw(parsed_features['feature'], tf.float64)
feature = tf.reshape(tf.cast(feature, tf.float32), [1, 121])
label = tf.reshape(tf.cast(parsed_features['label'], tf.float32), [1, 1])
return feature, label
dataset = tf.data.TFRecordDataset(["./train_ctr_201904.tfrecords"])
dataset = dataset.map(parse_tfrecords_function)
dataset = dataset.shuffle(buffer_size=10000)
dataset = dataset.repeat(10000)
return dataset
def train(self, dataset):
self.model.compile(optimizer=tf.train.FtrlOptimizer(0.03, l1_regularization_strength=0.01,
l2_regularization_strength=0.01),
loss='binary_crossentropy',
metrics=['binary_accuracy'])
self.model.fit(dataset, steps_per_epoch=10000, epochs=10)
self.model.summary()
self.model.save_weights('./ckpt/ctr_lr_ftrl.h5')
def predict(self, inputs):
"""预测
:return:
"""
self.model.load_weights('/root/toutiao_project/reco_sys/offline/models/ckpt/ctr_lr_ftrl.h5')
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
predictions = self.model.predict(sess.run(inputs))
return predictions
if __name__ == '__main__':
lwf = LrWithFtrl()
dataset = lwf.read_ctr_records()
inputs, labels = dataset.make_one_shot_iterator().get_next()
print(inputs, labels)
lwf.predict(inputs)
在线预测
def lrftrl_sort_service(reco_set, temp, hbu):
"""
排序返回推荐文章
:param reco_set:召回合并过滤后的结果
:param temp: 参数
:param hbu: Hbase工具
:return:
"""
print(344565)
try:
user_feature = eval(hbu.get_table_row('ctr_feature_user',
'{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode()))
logger.info("{} INFO get user user_id:{} channel:{} profile data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
except Exception as e:
user_feature = []
logger.info("{} WARN get user user_id:{} channel:{} profile data failed".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
reco_set = [13295, 44020, 14335, 4402, 2, 14839, 44024, 18427, 43997, 17375]
if user_feature and reco_set:
result = []
for article_id in reco_set:
try:
article_feature = eval(hbu.get_table_row('ctr_feature_article',
'{}'.format(article_id).encode(),
'article:{}'.format(article_id).encode()))
except Exception as e:
article_feature = []
if not article_feature:
article_feature = [0.0] * 111
f = []
f.extend(user_feature)
f.extend(article_feature)
result.append(f)
arr = np.array(result)
lwf = LrWithFtrl()
print(tf.convert_to_tensor(np.reshape(arr, [len(reco_set), 121])))
predictions = lwf.predict(tf.constant(arr))
df = pd.DataFrame(np.concatenate((np.array(reco_set).reshape(len(reco_set), 1), predictions),
axis=1),
columns=['article_id', 'prob'])
df_sort = df.sort_values(by=['prob'], ascending=True)
if len(df_sort) > 100:
reco_set = list(df_sort.iloc[:100, 0])
reco_set = list(df_sort.iloc[:, 0])
return reco_set
5.8.4 TensorFlow FTRL 读取训练
- 训练数据说明
- 原始特征用MurmurHash3的方式,将特征id隐射到(Long.MinValue, Long.MaxValue)范围
- 保存成One-Hot的数据格式
- 算法参数
- lambda1:L1正则系数,参考值:10 ~ 15
- lambda2:L2正则系数,参考值:10 ~ 15
- alpha:FTRL参数,参考值:0.1
- beta:FTRL参数,参考值:1.0
- batchSize: mini-batch的大小,参考值:10000
8.5 排序模型进阶-Wide&Deep
学习目标
- 目标
- 无
- 应用
- 无
8.5.1 wide&deep

- Wide部分的输入特征:
- raw input features and transformed features
- notice: W&D这里的cross-product transformation:
- 只在离散特征之间做组合,不管是文本策略型的,还是离散值的;没有连续值特征的啥事,至少在W&D的paper里面是这样使用的。
- Deep部分的输入特征:
- raw input+embeding处理
-
对 非连续值之外的特征做embedding处理,这里都是策略特征,就是乘以个embedding-matrix。在TensorFlow里面的接口是:tf.feature_column.embedding_column,默认trainable=True.
-
对 连续值特征的处理是:将其按照累积分布函数P(X≤x),压缩至[0,1]内。
- notice:** Wide部分用FTRL+L1来训练;Deep部分用AdaGrad来训练。
- Wide&Deep在TensorFlow里面的API接口为:tf.estimator.DNNLinearCombinedClassifier
代码:
import tensorflow as tf
from tensorflow.python import keras
class WDL(object):
"""wide&deep模型
"""
def __init__(self):
pass
@staticmethod
def read_ctr_records():
def parse_tfrecords_function(example_proto):
features = {
"label": tf.FixedLenFeature([], tf.int64),
"feature": tf.FixedLenFeature([], tf.string)
}
parsed_features = tf.parse_single_example(example_proto, features)
feature = tf.decode_raw(parsed_features['feature'], tf.float64)
feature = tf.reshape(tf.cast(feature, tf.float32), [1, 121])
channel_id = tf.cast(tf.slice(feature, [0, 0], [1, 1]), tf.int32)
vector = tf.reduce_sum(tf.slice(feature, [0, 1], [1, 100]), axis=1, keep_dims=True)
user_weights = tf.reduce_sum(tf.slice(feature, [0, 101], [1, 10]), axis=1, keep_dims=True)
article_weights = tf.reduce_sum(tf.slice(feature, [0, 111], [1, 10]), axis=1, keep_dims=True)
label = tf.reshape(tf.cast(parsed_features['label'], tf.float32), [1, 1])
FEATURE_COLUMNS = ['channel_id', 'vector', 'user_weigths', 'article_weights']
tensor_list = [channel_id, vector, user_weights, article_weights]
feature_dict = dict(zip(FEATURE_COLUMNS, tensor_list))
return feature_dict, label
dataset = tf.data.TFRecordDataset(["./train_ctr_201905.tfrecords"])
dataset = dataset.map(parse_tfrecords_function)
dataset = dataset.shuffle(buffer_size=10000)
dataset = dataset.repeat(10000)
return dataset.make_one_shot_iterator().get_next()
def build_estimator(self):
"""建立模型
:param dataset:
:return:
"""
article_id = tf.feature_column.categorical_column_with_identity('channel_id', num_buckets=25)
vector = tf.feature_column.numeric_column('vector')
user_weigths = tf.feature_column.numeric_column('user_weigths')
article_weights = tf.feature_column.numeric_column('article_weights')
wide_columns = [article_id]
deep_columns = [tf.feature_column.embedding_column(article_id, dimension=25),
vector, user_weigths, article_weights]
estimator = tf.estimator.DNNLinearCombinedClassifier(model_dir="./ckpt/wide_and_deep",
linear_feature_columns=wide_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[1024, 512, 256])
return estimator
if __name__ == '__main__':
wdl = WDL()
estimator = wdl.build_estimator()
estimator.train(input_fn=wdl.read_ctr_records, steps=10000)
WDL模型导出
3.2 线上预估
线上流量是模型效果的试金石。离线训练好的模型只有参与到线上真实流量预估,才能发挥其价值。在演化的过程中,我们开发了一套稳定可靠的线上预估体系,提高了模型迭代的效率。
模型同步
我们开发了一个高可用的同步组件:用户只需要提供线下训练好的模型的HDFS路径,该组件会自动同步到线上服务机器上。该组件基于HTTPFS实现,它是美团离线计算组提供的HDFS的HTTP方式访问接口。同步过程如下:
- 同步前,检查模型md5文件,只有该文件更新了,才需要同步。
- 同步时,随机链接HTTPFS机器并限制下载速度。
- 同步后,校验模型文件md5值并备份旧模型。
同步过程中,如果发生错误或者超时,都会触发报警并重试。依赖这一组件,我们实现了在2min内可靠的将模型文件同步到线上。
模型计算
当前我们线上有两套并行的预估计算服务。
基于TF Serving的模型服务
TF Serving是TensorFlow官方提供的一套用于在线实时预估的框架。它的突出优点是:和TensorFlow无缝链接,具有很好的扩展性。使用TF serving可以快速支持RNN、LSTM、GAN等多种网络结构,而不需要额外开发代码。这非常有利于我们模型快速实验和迭代。
使用这种方式,线上服务需要将特征发送给TF Serving,这不可避免引入了网络IO,给带宽和预估时延带来压力。我们尝试了以下优化,效果显著。
- 并发请求。一个请求会召回很多符合条件的广告。在客户端多个广告并发请求TF Serving,可以有效降低整体预估时延。
- 特征ID化。通过将字符串类型的特征名哈希到64位整型空间,可以有效减少传输的数据量,降低使用的带宽。
导出代码:
导出serving_model
wide_columns = [tf.feature_column.categorical_column_with_identity('channel_id', num_buckets=25)]
deep_columns = [tf.feature_column.embedding_column(tf.feature_column.categorical_column_with_identity('channel_id', num_buckets=25), dimension=25),
tf.feature_column.numeric_column('vector'),
tf.feature_column.numeric_column('user_weigths'),
tf.feature_column.numeric_column('article_weights')
]
columns = wide_columns + deep_columns
feature_spec = tf.feature_column.make_parse_example_spec(columns)
serving_input_receiver_fn = tf.estimator.export.build_parsing_serving_input_receiver_fn(feature_spec)
estimator.export_savedmodel("./serving_model/wdl/", serving_input_receiver_fn)
7.7 TensorFlow Serving模型部署
学习目标
- 目标
- 无
- 应用
- 应用TensorFlow Serving完成模型服务运行
7.7.1 TensorFlow Serving
TensorFlow Serving是一种灵活的高性能服务系统,适用于机器学习模型,专为生产环境而设计。TensorFlow Serving可以轻松部署新算法和实验,同时保持相同的服务器架构和API。TensorFlow Serving提供与TensorFlow模型的开箱即用集成,但可以轻松扩展以提供其他类型的模型和数据。

; 7.7.1.1 安装Tensorflow Serving
安装过程详细参考官网
https://www.tensorflow.org/serving/setup
- 使用Docker安装进行,首先你的电脑当中已经安装过docker容器
- 下载桌面版本:https://www.docker.com/products/docker-desktop
7.7.2 TensorFlow Serving Docker
- 获取最新TF Serving docker镜像
docker pull tensorflow/serving
- 查看docker镜像
docker images
- 运行tf serving(即创建一个docker容器来运行)
docker run -p 8501:8501 -p 8500:8500 --mount type=bind,source=/home/ubuntu/detectedmodel/commodity,target=/models/commodity -e MODEL_NAME=commodity -t tensorflow/serving
说明:
– -p 8501:8501 为端口映射, -p 主机端口:docker容器程序(tf serving)使用端口,访问主机8501端口就相当于访问了tf serving程序的8501端口
– tf serving 使用8501端口对外提供HTTP服务,使用8500对外提供gRPC服务,这里同时开放了两个端口的使用
– --mount type=bind,source=/home/ubuntu/detectedmodel/commodity,target=/models/commodity 为文件映射,将主机(source)的模型文件映射到docker容器程序(target)的位置,以便tf serving使用模型, target参数为 /models/我的模型
– -e MODEL_NAME=commodity设置了一个环境变量,名为 MODEL_NAME,此变量被tf serving读取,用来按名字寻找模型,与上面target参数中 我的模型对应
– -t 为tf serving创建一个伪终端,供程序运行
– tensorflow/serving为镜像名
7.7.3 案例操作:wdl模型服务运行
- 1、运行命令
docker run -p 8501:8501 -p 8500:8500 --mount type=bind,source=/root/toutiao_project/reco_sys/server/models/serving_model/wdl,target=/models/wdl -e MODEL_NAME=wdl -t tensorflow/serving
- 2、查看是否运行
itcast:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ed3a36a07ba8 tensorflow/serving "/usr/bin/tf_serving..." About a minute ago Up About a minute
- 8 排序模型在线测试
学习目标
- 目标
- 无
- 应用
- 应用TensorFlow Serving apis完成在线模型的获取排序测试
代码:
import tensorflow as tf
from grpc.beta import implementations
from tensorflow_serving.apis import prediction_service_pb2_grpc
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import classification_pb2
import os
import sys
import grpc
from server.utils import HBaseUtils
from server import poolll
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
print(BASE_DIR)
sys.path.insert(0, os.path.join(BASE_DIR))
def wdl_sort_service():
"""
wide&deep进行排序预测
:param reco_set:
:param temp:
:param hbu:
:return:
"""
hbu = HBaseUtils(poolll)
try:
user_feature = eval(hbu.get_table_row('ctr_feature_user',
'{}'.format(1115629498121846784).encode(),
'channel:{}'.format(18).encode()))
except Exception as e:
user_feature = []
if user_feature:
result = []
examples = []
for article_id in [17749, 17748, 44371, 44368]:
try:
article_feature = eval(hbu.get_table_row('ctr_feature_article',
'{}'.format(article_id).encode(),
'article:{}'.format(article_id).encode()))
except Exception as e:
article_feature = [0.0] * 111
channel_id = int(article_feature[0])
vector = np.mean(article_feature[11:])
user_feature = np.mean(user_feature)
article_feature = np.mean(article_feature[1:11])
example = tf.train.Example(features=tf.train.Features(feature={
"channel_id": tf.train.Feature(int64_list=tf.train.Int64List(value=[channel_id])),
"vector": tf.train.Feature(float_list=tf.train.FloatList(value=[vector])),
'user_weigths': tf.train.Feature(float_list=tf.train.FloatList(value=[user_feature])),
'article_weights': tf.train.Feature(float_list=tf.train.FloatList(value=[article_feature])),
}))
examples.append(example)
with grpc.insecure_channel('127.0.0.1:8500') as channel:
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = classification_pb2.ClassificationRequest()
request.model_spec.name = 'wdl'
request.input.example_list.examples.extend(examples)
response = stub.Classify(request, 10.0)
print(response)
return None
if __name__ == '__main__':
wdl_sort_service()
s=tf.train.Features(feature={
"channel_id": tf.train.Feature(int64_list=tf.train.Int64List(value=[channel_id])),
"vector": tf.train.Feature(float_list=tf.train.FloatList(value=[vector])),
'user_weigths': tf.train.Feature(float_list=tf.train.FloatList(value=[user_feature])),
'article_weights': tf.train.Feature(float_list=tf.train.FloatList(value=[article_feature])),
}))
examples.append(example)
with grpc.insecure_channel('127.0.0.1:8500') as channel:
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = classification_pb2.ClassificationRequest()
request.model_spec.name = 'wdl'
request.input.example_list.examples.extend(examples)
response = stub.Classify(request, 10.0)
print(response)
return None
if __name__ == '__main__':
wdl_sort_service()
Original: https://blog.csdn.net/fegus/article/details/124423938
Author: 办公模板库 素材蛙
Title: Python黑马头条推荐系统第五天 头条排序模型进阶-神经网络
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/691469/
转载文章受原作者版权保护。转载请注明原作者出处!