

一、RNN模型 与 NLP应用 —— 数据预处理
前言
本文为 王树森教授的《RNN模型与NLP应用》授课学习笔记
数据处理简介:
主要为文本数据的处理过程. 文本数据包含数值化描述(Numeric Features), 和类别化描述(Categorical Features).
数值化描述如年龄, 数值之间是有大小关系的, 比如50岁比30岁大.
类别化描述如性别、国籍, 需要转化为数值化描述, 才能被计算机处理.
类别化描述使用one-hot编码方式, 可以避免大小之分, 其中0作为保留编码, 用于表示缺失的或者未知的数据. one-hot向量的长度由类别数量决定, 且one-hot编码形成的输入矩阵非常稀疏, 因此存储和计算效率低.
文本处理的步骤(1.-5.):
- Tokenization(Text to Words) – 单词分割
词分割, 将文本分割成单独的序列词汇 Token.
要注意: 大写是否要转为小写(Apple or apple);移除断句符, the、a、of等;错误拼写修正(goood or good).


2. Build Dictionary – 统计频率
即计算每个单词出现的频率. 然后按照词频由高到低进行排序. 排序后, 每个单词的索引, 可以用于表示该单词. 文本中单词的集合, 被称为词汇表, vocabulary. 保留词汇表中的高频词, 删除低频词, 因为低频词有可能是名字、错误拼写. 另一方面, 去掉低频词, 可以有效降低词汇表one-hot编码的维度, 减小overfiting的可能. 由于去掉了低频词, 文本词分割后, 进行one-hot编码时, 会出现词汇表中没有的词(如被去掉的低频词), 可以忽略或者用0编码.

3. One-Hot Encoding
将文本, 转为用词汇表索引表示的sequence, 如有必要, 将索引进一步转为one-hot 编码, 编码后每个单词都是vocabulary个维度.

4. Align Sequences – 对齐 Sequences
由于不同的训练样本(文本)有长有短, 它们转为sequence后也有长有短. 为了把所有的文本存储在tensor中, 必须要求所有文本都一样长.

设置一个固定长度, 如果长于这个长度的文本, 截取开头或者末尾; 如果短于这个长度的文本, 用0补齐.

5. Word Embedding: word to vector

由于one-hot的编码方式, 具有稀疏、效率低的特点, 所以进一步进行转化word embedding:

Embedding编码矩阵P: 将单个ont-hot映射为单个词向量
其中, e i e_i e i 为第i i i个单词的one-hot编码, d d d为设置的词向量维度(为超参数), v v v为词汇表的长度, P P P是可学习的参数矩阵, x i x_i x i 为词向量.
如果e i e_i e i 中第3个元素为1, 则x_i就是P T P^T P T中的第3列(即P^T的每一列都是词向量). 所以P P P的每一行为一个词向量x i x_i x i . 用P P P对e i e_i e i 进行二次编码, 大大降低了e i e_i e i 的维度.
参数矩阵P P P是从训练文本中学习出来的, 所以P P P是带有感情色彩的特征提取矩阵. 如果正面词的one-hot经过矩阵映P射得到的词向量x i x_i x i 为二维向量, 则词性相同的词都分布在一起, 并且词性相反的词距离很远, 中性词分布在中间且远离褒义词和负面词.
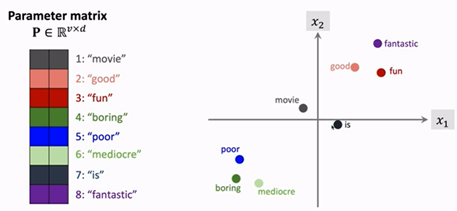
; 使用逻辑回归(LR)训练情感分类: – 效果不好
from keras.models import Sequential
from keras.layers import Flatten, Dense, Embedding
embedding_dim = 8
word_num = 20
model = Sequential()
model.add(Embedding(vocabulary, embedding_dim, input_length=word_num))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.summary()
from keras import optimizers
epochs = 50
model.compile(optimizer=optimizers.RMSprop(lr=0.0001),
loss='binary_crossentropy', metrics=['acc'])
history = model.fit(x_train, y_train, epochs=epochs,
batch_size=32, validation_data=(x_vaild, y_vaild))
loss_and_acc = model.evaluate(x_test, labels_test)

Simple RNN
FCN和ConvNet的限制: one-to-one模型, 一个输入对一个输出
- 一次性输入的是整个样本数据
- 固定输入和输出
RNN为 many-to-one 或者 many-to-many 输入和输出的长度不固定. RNN适合小规模问题可以, 大规模问题需要用Transformer. Simple RNN的详情见: 二、RNN模型 与 NLP应用 —— Simple RNN.
Original: https://blog.csdn.net/weixin_43667730/article/details/124248771
Author: 地瓜你个大番薯
Title: 一、RNN模型 与 NLP应用 —— 数据预处理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/691215/
转载文章受原作者版权保护。转载请注明原作者出处!