

摘要:算法模型基于动态多隐层LSTM RNN搭建,损失函数使用cross_entropy损失最大值,输入M维度、输出N维度。代码基于Python3.6.X和Tensorflow1.13.X实现。
- 前言
对于新零售、金融、供应链、在线教育、银行、证券等行业的产品而言,以数据为驱动的用户行为分析尤为重要。用户行为分析的目的是:推动产品迭代、实现精准营销,提供定制服务,驱动产品决策。
我们以新零售加油站业务场景为例开始,我们在去给车加油时,面临着花钱,还面临让人头疼的堵车和加油排队的等耗费时间的问题。通常,我们大概每周都有可能去一次加油站加油,还可能顺便进便利店买些非油物品,或者还能顺便洗车。
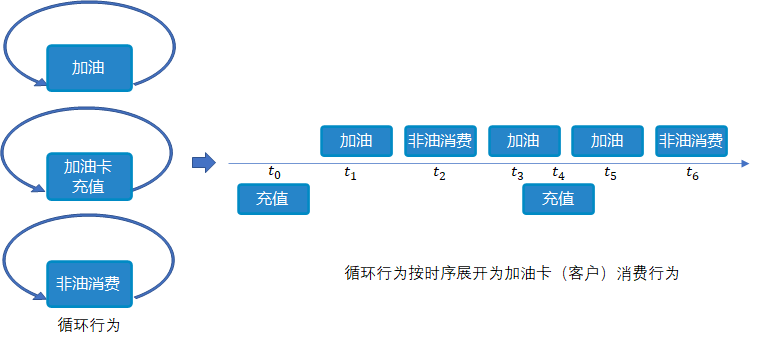

如上图所示的行为事件分析是根据运营关键指标,对用户特定事件加油卡交易数据进行分析。通过按时序追踪或记录用户行为事件,可以快速的了解到事件的趋势走向和加油客户的完成情况。
对于预测股票近期、未来的价格,也是属于时序交易行为分析范畴,我们比较容易获取股票交易数据,也比较明显的对标预测结果。现如今,业界有可参考使用CNN+LSTM算法做行为分析,股票价格预测的案例。由于新零售等业务缺少数据,我们先用股票数据研究算法模型。
; 2. 时序预测分析,深度学习LSTM算法概述
在深度学习中有适合处理序列数据的神经网络,那就是循环神经网络 RNN,在NLP上应用较多,效果也比较好,而在金融量化分析上也有所应用,特别是在行为分析、股票价格预测上也有较多的应用。我们这里不深入研究算法模型,仅从应用角度介绍关键内容。
2.1. 循环神经网络 RNN概述
循环神经网络(Rerrent Neural Network, RNN )出现于20世纪80年代,是指一个随着时间序列的推移,重复发生循环的简单神经网络结构,它由输入层、隐藏层、输出层组成。
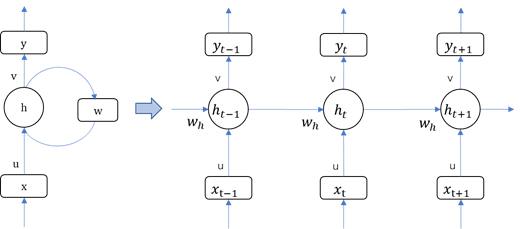
时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征。这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大小的值改变顺序后输入模型产生的结果是不同的。
RNN 是在有顺序的数据上进行学习的,为了记住这些数据,RNN 会像人一样产生对先前发生事件的记忆。
; 2.2. 长短期记忆循环神经网络LSTM概述
普通的 RNN 就像一个老爷爷,有时候比较健忘,为什么会这样呢?普通的RNN,对于输入使用手机软件的信息,要经过很长的路径才能抵达最后一个时间点。然后,我们得到误差,而且在反向传递得到的误差的时候,他在每一步都会乘以一个自己的参数W。如果这个W 是一个小于1 的数,经不断乘以误差,误差传到初始时间点也会是一个接近于零的数,误差相当于就消失了。我们把这个问题叫做梯度消失或者梯度弥散。反之如果W是一个大于1 的数,则到最后变成了无穷大的数,这种情况我们叫做剃度爆炸。这就是普通 RNN 没有办法回忆起久远记忆的原因。
LSTM 就是为了解决这个问题而诞生的,LSTM 和普通 RNN 相比,多出了三个控制器:输入门、输出门、遗忘门。如下图所示为LSTM内部的结果概况。

f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t=σ(W_f \cdot [h_{t-1},x_t ]+b_f )f t =σ(W f ⋅[h t −1 ,x t ]+b f )
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t=σ(W_i \cdot [h_{t-1},x_t ]+b_i )i t =σ(W i ⋅[h t −1 ,x t ]+b i )
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t=σ(W_o \cdot [h_{t-1},x_t ]+b_o )o t =σ(W o ⋅[h t −1 ,x t ]+b o )
C ~ t = t a n h ( W c ⋅ [ h t − 1 , x t ] + b c ) \tilde {C}t = tanh(W_c \cdot [h{t-1},x_t ]+b_c)C ~t =t a n h (W c ⋅[h t −1 ,x t ]+b c )
C t = f t × C t − 1 + i t × C ~ t C_t=f_t \times C_{t-1}+i_t \times \tilde {C}_t C t =f t ×C t −1 +i t ×C ~t
h t = o t × t a n h ( C t ) h_t = o_t \times tanh(C_t)h t =o t ×t a n h (C t )
其中,f t f_t f t 是遗忘门,i t i_t i t 是输入门,o t o_t o t 是输出门,C t C_t C t 是神经元状态,h t h_t h t 是隐藏层状态值,W和b分别是权重和偏置。
LSTM多出了一个控制全局的记忆,我们在图中表示为主线,相当于剧本中的主线剧情。而普通的 RNN体系就是分线剧情。我们先看输入的分线剧情对于剧终结果十分重要,输入控制就会将这个分线剧情按重要程度写入主线剧情进行分析,对于遗忘方面,如果此时的分线剧情更改了我们对之前剧情的想法,那么遗忘控制就会将之前的某些主线剧情忘记,按比例替换成现在的新剧情。LSTM 就像延缓记忆衰退的良药,可以带来更好的结果。
对于LSTM算法模型,输出states是个tuple,分别代表C t C_{t}C t 和h t h_{t}h t ,其中h t h_{t}h t 与outputs中对应的最后一个时刻(即最后一个cell)的输出相等。
- LSTM算法模型预测股票价格实践
3.1. 基于Tensorflow1.13.X构建LSTM回归模型
我们以类(class MultiLSTM)的方式定义LSTM RNN的主体结构,此RNN由3个组成部分 ( input_layer, cell, output_layer):
(1)定义输入层:
with tf.name_scope('inputs'):
self.xs = tf.placeholder(tf.float32, [None, n_steps, input_size], name='xs')
self.ys = tf.placeholder(tf.float32, [None, n_steps, output_size], name='ys')
self.batch_size = tf.placeholder(tf.int32, [], name='batch_size')
self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
其中,输入层另外包括batch_size(训练数据批次大小)和keep_prob(避免过拟合,不被删掉节点的概率)。
(2)定义隐藏层:
构建多隐层神经网络。
def add_multi_cell(self):
cell_list = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
with tf.name_scope('dropout'):
if self.is_training:
cell_list = tf.contrib.rnn.DropoutWrapper(cell_list, output_keep_prob=self.keep_prob)
tf.summary.scalar('dropout_keep_probability', self.keep_prob)
lstm_cell = [cell_list for _ in range(self.num_layers)]
lstm_cell = tf.contrib.rnn.MultiRNNCell(lstm_cell, state_is_tuple=True)
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
在RNN中进行dropout时,对于RNN的部分不进行dropout,仅在同一个t时刻中,多层cell之间传递信息的时候进行dropout。
tf.nn.dynamic_rnn(cell, inputs)中的 time_major 参数会针对不同 inputs 格式有不同的值:
- 如果 inputs 为 (batches, steps, inputs)则对应为 time_major=False; 如果 inputs
- 为 (steps, batches, inputs) 则对应为time_major=True;
(3)定义输出层:
输出层实现不带激活函数的全连接,也就是线性的y i = w i x i + b i y_i=w_ix_i+b_i y i =w i x i +b i 。
def add_output_layer(self):
l_out_x = tf.reshape(self.cell_outputs, [-1, self.cell_size], name='2_2D')
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size, ])
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(l_out_x, Ws_out) + bs_out
(4)定义损失函数:
使用tf.contrib.legacy_seq2seq.sequence_loss_by_example定义损失函数,由于是多输出模型,取均值将影响结果,我采用取最大值方案。
def compute_cost(self):
losses = tf.contrib.legacy_seq2seq.sequence_loss_by_example(
[tf.reshape(self.pred, [-1], name='reshape_pred')],
[tf.reshape(self.ys, [-1], name='reshape_target')],
[tf.ones([self.batch_size * self.n_steps*self.output_size], dtype=tf.float32)],
average_across_timesteps=True,
softmax_loss_function=self.ms_error,
name='losses'
)
with tf.name_scope('average_cost'):
self.cost = tf.reduce_max(losses, name='average_cost')
'''
self.cost = tf.div(
tf.reduce_sum(losses, name='losses_sum'),
self.batch_size_,
name='average_cost')
'''
tf.summary.scalar('cost', self.cost)
print('self.cost shape is {}'.format(self.cost.shape))
(5)搭建LSTM网络常见问题及注意事项:
- 多对多是 RNN 中最经典的结构,其输入、输出都是等长的序列数据;
- 在Tensorflow1.x的中,batch_size应设置为不定值,方便测试和模型应用时,不必再构造batch_size;
- 在做losse时,例如均方差过程中,注意数据个数为batch_size _n_steps_output_size;
- 由于数据集大小所限,当timestep过大,而训练集长度较小时,训练出来的模型进行预测会出现结果波动不大,呈一条直线的情况,建议缩短timestep。
至此,多层LSTM模型构建完成,整合代码如下
class MultiLSTM(object):
def __init__(self, n_steps, input_size, output_size, cell_size, batch_size,num_layers,is_training):
self.n_steps = n_steps
self.input_size = input_size
self.output_size = output_size
self.cell_size = cell_size
self.batch_size_ = batch_size
self.num_layers = num_layers
self.is_training = is_training
with tf.name_scope('inputs'):
self.xs = tf.placeholder(tf.float32, [None, n_steps, input_size], name='xs')
self.ys = tf.placeholder(tf.float32, [None, n_steps, output_size], name='ys')
self.batch_size = tf.placeholder(tf.int32, [], name='batch_size')
self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
with tf.variable_scope('in_hidden'):
self.add_input_layer()
with tf.variable_scope('Multi_LSTM'):
self.add_multi_cell()
with tf.variable_scope('out_hidden'):
self.add_output_layer()
with tf.name_scope('cost'):
self.compute_cost()
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(LR).minimize(self.cost)
def add_input_layer(self,):
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='2_2D')
Ws_in = self._weight_variable([self.input_size, self.cell_size])
bs_in = self._bias_variable([self.cell_size,])
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='2_3D')
def add_multi_cell(self):
cell_list = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
with tf.name_scope('dropout'):
if self.is_training:
cell_list = tf.contrib.rnn.DropoutWrapper(cell_list, output_keep_prob=self.keep_prob)
tf.summary.scalar('dropout_keep_probability', self.keep_prob)
lstm_cell = [cell_list for _ in range(self.num_layers)]
lstm_cell = tf.contrib.rnn.MultiRNNCell(lstm_cell, state_is_tuple=True)
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
l_out_x = tf.reshape(self.cell_outputs, [-1, self.cell_size], name='2_2D')
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size, ])
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(l_out_x, Ws_out) + bs_out
def compute_cost(self):
losses = tf.contrib.legacy_seq2seq.sequence_loss_by_example(
[tf.reshape(self.pred, [-1], name='reshape_pred')],
[tf.reshape(self.ys, [-1], name='reshape_target')],
[tf.ones([self.batch_size * self.n_steps*self.output_size], dtype=tf.float32)],
average_across_timesteps=True,
softmax_loss_function=self.ms_error,
name='losses'
)
with tf.name_scope('average_cost'):
self.cost = tf.reduce_max(losses, name='average_cost')
'''
self.cost = tf.div(
tf.reduce_sum(losses, name='losses_sum'),
self.batch_size_,
name='average_cost')
'''
tf.summary.scalar('cost', self.cost)
print('self.cost shape is {}'.format(self.cost.shape))
@staticmethod
def ms_error(labels, logits):
return tf.square(tf.subtract(labels, logits))
def _weight_variable(self, shape, name='weights'):
initializer = tf.random_normal_initializer(mean=0., stddev=1.,)
return tf.get_variable(shape=shape, initializer=initializer, name=name)
def _bias_variable(self, shape, name='biases'):
initializer = tf.constant_initializer(0.1)
return tf.get_variable(name=name, shape=shape, initializer=initializer)
注:
代码原型参考莫烦Python相关代码”LSTM回归“。
多隐层数量不同的写法,官方推荐为:
num_units = [128, 64]
cells = [BasicLSTMCell(num_units=n) for n in num_units]
stacked_rnn_cell = MultiRNNCell(cells)
3.2. 股票数据集
股票数据来自Tushare,是一个免费、开源的python财经数据接口包。我使用的是Pro版,其数据更稳定质量更好了,Pro依然是个开放的,免费的平台,推荐:Tushare大数据社区 分享此链接。
本实践案例使用后复权某股票数据,以及输入上证指数、深成指数、纳斯达克指数、道琼斯指数、恒生指数(由于计算机性能原因,只保留额外保留上证指数、深成指数)。

构建训练数据集,拆分出收盘股价、交易量、上证指数、深成指数为输出(OUTPUT_SIZE = 4),由于数据集时间序列比较少,时序取15组时序数据(TIME_STEPS = 15),从最早的时刻开始,逐个取15组全列数据为输入,15组后续15组4列为输出,则最后的输入为当前数据集最后日期减去15(PRED_SIZE=15)。
拆分数据集过程代码如下所示,其中包括最后15组数据为预测未来15天(PRED_SIZE=15)的输入数据。
def get_train_data():
df = pd.read_csv('share20210302.csv')
return df
def get_test_data():
df = pd.read_csv('share20210302.csv')
df = df.iloc[-TIME_STEPS:]
return df
def get_pred_data(y,z,sc):
yy = np.concatenate((y, z),axis=1)
y=sc.inverse_transform(yy)
return y
def set_datas(df,train=True,sc=None):
df['Year'] = df['trade_date'].apply(lambda x:int(str(x)[0:4]))
df['Month'] = df['trade_date'].apply(lambda x:int(str(x)[4:6]))
df['Day'] = df['trade_date'].apply(lambda x:int(str(x)[6:8]))
df['Week'] = df['trade_date'].apply(lambda x:datetime.datetime.strptime(str(x),'%Y%m%d').weekday())
df = df.drop('trade_date',axis=1)
col_name = df.columns.tolist()
col_name.remove('close1')
col_name.remove('close2')
col_name.remove('vol0')
col_name.insert(0,'close1')
col_name.insert(1,'close2')
col_name.insert(2,'vol0')
df = df[col_name]
if train:
sc = MinMaxScaler(feature_range= (0,1))
training_set = sc.fit_transform(df)
else:
training_set = sc.transform(df)
def get_batch(train_x,train_y):
data_len = len(train_x) - TIME_STEPS
seq = []
res = []
for i in range(data_len):
seq.append(train_x[i:i + TIME_STEPS])
res.append(train_y[i:i + TIME_STEPS])
seq ,res = np.array(seq),np.array(res)
return seq, res
if train:
seq, res = get_batch(training_set[:-PRED_SIZE], training_set[PRED_SIZE:][:,0:OUTPUT_SIZE])
else:
seq, res = training_set, training_set[:,0:OUTPUT_SIZE]
seq, res = seq[np.newaxis,:,:], res[np.newaxis,:,:]
return seq, res, training_set[:,OUTPUT_SIZE:],sc,col_name,df
注意事项:
训练集和测试集,在做归一化处理后,需要采用统一标准,也就是对MinMaxScaler用一次fit_transform,后续使用transform即可。(容易在这个小河沟里翻船!)
3.3. 模型训练及参数
在模型训练中,使用tf.data.Dataset.from_tensor_slices迭代器,分批次获取batche数据。训练过程日志数据记录到”logs”目录下,通过tensorboard工具查看。
import tensorflow as tf
import numpy as np
import pandas as pd
import datetime
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
BATCH_START = 0
TIME_STEPS = 15
BATCH_SIZE = 30
INPUT_SIZE = 25
OUTPUT_SIZE = 4
PRED_SIZE = 15
CELL_SIZE = 256
NUM_LAYERS = 3
LR = 0.00001
EPOSE = 40000
if __name__ == '__main__':
model = MultiLSTM(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE, NUM_LAYERS,True)
sess = tf.Session()
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("logs", sess.graph)
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
state = 0
xs = 0
df = get_train_data()
train_x,train_y,z,sc,col_name,df = set_datas(df,True)
dataset = tf.data.Dataset.from_tensor_slices((train_x,train_y))
dataset = dataset.batch(BATCH_SIZE).repeat()
iterator = dataset.make_initializable_iterator()
next_iterator = iterator.get_next()
losse = []
for i in range(EPOSE):
sess.run(iterator.initializer)
seq, res = sess.run(next_iterator)
if i == 0:
feed_dict = {
model.xs: seq,
model.ys: res,
model.batch_size:BATCH_SIZE,
model.keep_prob:0.75,
}
else:
feed_dict = {
model.xs: seq,
model.ys: res,
model.batch_size:BATCH_SIZE,
model.keep_prob:0.75,
model.cell_init_state: state
}
_, cost, state, pred = sess.run(
[model.train_op, model.cost, model.cell_final_state, model.pred],
feed_dict=feed_dict)
losse.append(cost)
if i % 20 == 0:
print('cost: ', round(cost, 5))
result = sess.run(merged, feed_dict)
writer.add_summary(result, i)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
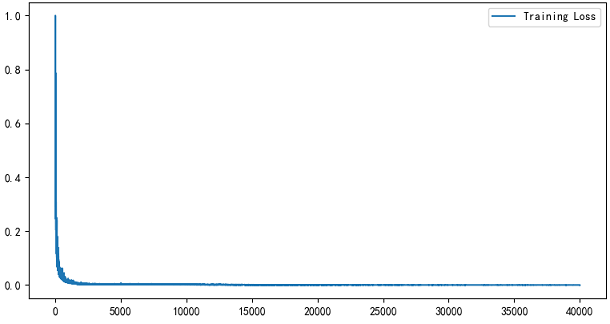
losse = np.array(losse)/max(losse)
plt.plot(losse, label='Training Loss')
plt.title('Training Loss')
plt.legend()
plt.show()
在命令行窗口中,进入当前程序目录,使用tensorboard –logdir logs命令。计算图如下:
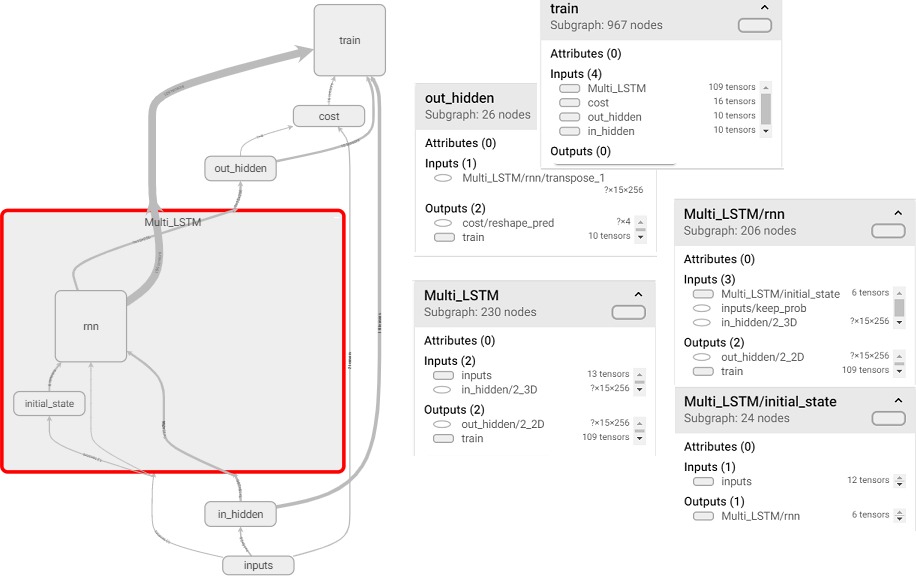
训练过程如下,cost值达到0.013X。
3.4. 预测结果及分析
使用数据集最后15条记录做为预测未来15天的输入,输出结果如下:
df = get_test_data()
seq,res,z,sc,col_name,df = set_datas(df,False,sc)
seq = seq.reshape(-1,TIME_STEPS,INPUT_SIZE)
share_close = df['close0'].values
share_vol = df['vol0'].values/10000
share_sh = df['close1'].values
share_sz = df['close2'].values
model.is_training = False
feed_dict = {
model.xs: seq,
model.batch_size:1,
model.keep_prob:1.0
}
pred = sess.run([model.pred], feed_dict=feed_dict)
y=get_pred_data(pred[0].reshape(TIME_STEPS,OUTPUT_SIZE),z,sc)
df= pd.DataFrame(y,columns=col_name)
df.to_csv('y.csv')
share_close1 = df['close0'].values
share_vol1 = df['vol0'].values/10000
share_sh1 = df['close1'].values
share_sz1 = df['close2'].values
share_close1 = np.concatenate((share_close[:PRED_SIZE],share_close1),axis=0)
share_vol1 = np.concatenate((share_vol[:PRED_SIZE],share_vol1),axis=0)
share_sh1 = np.concatenate((share_sh[:PRED_SIZE],share_sh1),axis=0)
share_sz1 = np.concatenate((share_sz[:PRED_SIZE],share_sz1),axis=0)
plt.plot(share_sh, label='收盘沪指指数')
plt.plot(share_sh1, label='预测收盘沪指指数')
plt.plot(share_sz, label='收盘深证指数')
plt.plot(share_sz1, label='预测收盘深证指数')
plt.plot(share_close, label='收盘实际值')
plt.plot(share_vol, label='成交量实际值')
plt.plot(share_vol1, label='成交量预测值')
plt.plot(share_close1, label='收盘预测值')
plt.title('Test Loss')
plt.legend()
plt.show()
预测结果是从下图中横坐标14开始,连续预测15天。输入数据时间序列中间经历过中国年假期,所选的数据集可能不合适。
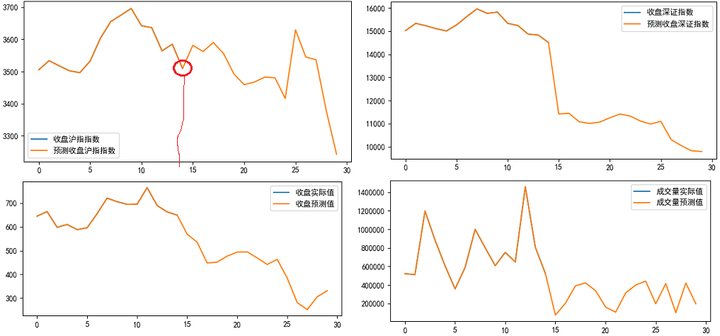
注意:由于前15天数据与输入重合,图像上覆盖使线略微变深,而看不出另一条线。
- 小结
最近,看到股票持续走低为我增强了信心,发现为行为分析准备的模型预研还是很有意义的。
多隐层,多输入、输出,而且输入、输出不同维度LSTM预测模型,在行为分析预测中,还是实际意义,如果结合上CNN或特征工程作为输入,将会有更好的结果。
对于RNN Cell中神经元数量设置,通过多轮训练实践,一般是输入的10倍以上,特别是数据集数量偏少情况下,更应多些。但是,这样将带来训练难度加大,周期变成的情况。
由于作者水平有限,欢迎反馈交流。
参考:
1.《什么是 LSTM 循环神经网络》莫烦PYTHON, 莫烦 ,2016年11月
2.《LSTM的训练和测试长度(batch_size)不一样报错的解决方案》CSDN博客 ,David-Chow ,2019年4月
3.《tf.nn.dynamic_rnn 详解》知乎 ,应钟有微 ,2018年8月
4.《用户研究:如何做用户行为分析?》人人都是产品经理,朱学敏,2019年12月
5.《基于Keras的LSTM多变量时间序列股票预测》CSDN博客 ,肖永威, 2020年4月
6.《TensorFlow1.4之LSTM的使用》51CTO博客 , mybabe0312 ,2019年2月
7.《LSTM中的参数计算》知乎 ,忆臻 ,2018年12月
Original: https://blog.csdn.net/xiaoyw/article/details/113922893
Author: 肖永威
Title: Tensorflow LSTM实现多维输入输出预测实践详解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/691032/
转载文章受原作者版权保护。转载请注明原作者出处!