

目录
- 1. 环境
- 2. 获取数据集
- 3. FATE任务
* - 3.1 上传数据
-
3.2 模型训练
– -
环境
-
本文实验内容是前几篇文章的延续,同样在FATE1.6.0版本下进行。
- 实际开发和研究过程中,总是需要自定义实现模型的,这里查看了一下FATE1.6.0带的版本
-
FATE1.6.0
- Python 3.6.5
- pytorch 1.4.0
- tensorflow 2.3.4
- keras 2.4.0
-
获取数据集
-
本文使用的数据集是AI入门的手写数字识别数据集MNIST,从kaggle上下载csv格式的数据集,拷贝到虚拟机中
- 该数据集中6w条训练数据和1w条测试数据
- 为了模拟横向联邦学习,将训练数据对半切分为mnist_1_train.csv和mnist_2_train.csv
- FATE训练时需要数据集有id,为数据集增加id字段,并将label字段修改为y
import pandas as pd
train = pd.read_csv("data/mnist_train.csv")
test = pd.read_csv("data/mnist_test.csv")
train['idx'] = range(train.shape[0])
idx = train['idx']
train.drop(labels=['idx'], axis=1, inplace=True)
train.insert(0, 'idx', idx)
train = train.rename(columns={"label":"y"})
y = train["y"]
train.drop(labels=["y"], axis=1, inplace=True)
train.insert(train.shape[1], "y", y)
train = train.sample(frac=1)
train_1 = train.iloc[:30000]
train_2 = train.iloc[30000:]
train_1.to_csv("data/mnist_1_train.csv", index=False, header=True)
train_2.to_csv("data/mnist_2_train.csv", index=False, header=True)
test['idx'] = range(test.shape[0])
idx_test = test['idx']
test.drop(labels=['idx'], axis=1, inplace=True)
test.insert(0, 'idx', idx)
test = test.rename(columns={"label":"y"})
y_test = test["y"]
test.drop(labels=["y"], axis=1, inplace=True)
test.insert(test.shape[1], "y", y_test)
test.to_csv("mnist_test.csv", index=False, header=True)
- FATE任务
3.1 上传数据
- 配置conf文件
{
"file": "workspace/HFL_nn/data/mnist_2_train.csv",
"table_name": "homo_guest_mnist_train",
"namespace": "experiment",
"head": 1,
"partition": 8,
"work_mode": 0,
"backend": 0
}
{
"file": "workspace/HFL_nn/data/mnist_1_train.csv",
"table_name": "homo_host_mnist_train",
"namespace": "experiment",
"head": 1,
"partition": 8,
"work_mode": 0,
"backend": 0
}
- 上传数据
workspace/HFL_lr/ 是我建立在fate根目录下的目录
$ flow data upload -c workspace/HFL_nn/upload_train_host_conf.json
$ flow data upload -c workspace/HFL_nn/upload_train_guest_conf.json
3.2 模型训练
3.2.1 定义模型
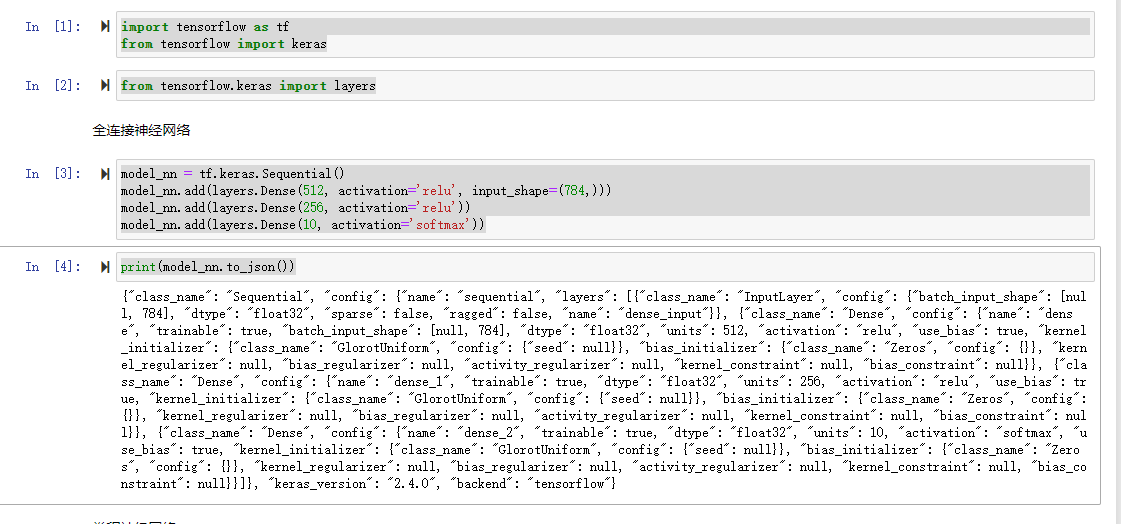
- 这里采用keras定义全连接神经网络
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
model_nn = tf.keras.Sequential()
model_nn.add(layers.Dense(512, activation='relu', input_shape=(784,)))
model_nn.add(layers.Dense(256, activation='relu'))
model_nn.add(layers.Dense(10, activation='softmax'))
print(model_nn.to_json())

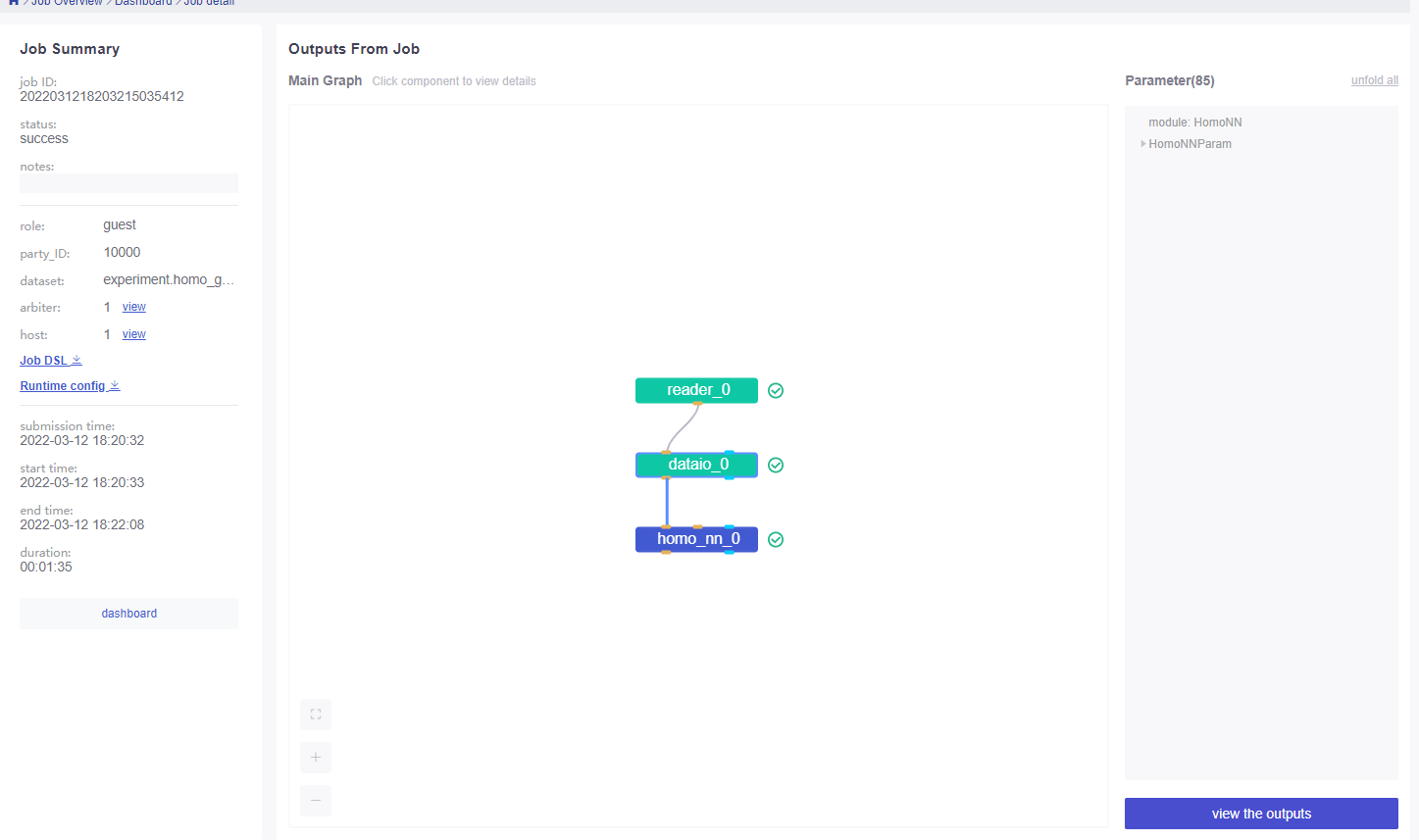
3.2.2 配置DSL文件(v2版本)
- 示例文件在/examples/dsl/v2/homo_nn/test_homo_dnn_single_layer_dsl.json,直接拿来使用
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": ["data"]
}
},
"dataio_0": {
"module": "DataIO",
"input": {
"data": {
"data": ["reader_0.data"]
}
},
"output": {
"data": ["data"],
"model": ["model"]
}
},
"homo_nn_0": {
"module": "HomoNN",
"input": {
"data": {
"train_data": ["dataio_0.data"]
}
},
"output": {
"data": ["data"],
"model": ["model"]
}
}
}
}
3.2.3 配置conf文件
- 示例文件在/examples/dsl/v2/homo_nn/test_homo_dnn_single_layer_conf.json
- 修改
- 根据自身情况,修改各个角色的party_id
- job_parameters.common中, work_mode(0为单机,1为集群)
- 修改component_parameters.roles各个数据源,对应上传数据时定义的name和namespace
- 将在3.2.1中定义的模型拷贝到nn_define项
- 在homo_nn_0中增加”encode_label”:true,表示使用one-hot
- 修改loss为categorical_crossentropy
- 调参
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 10000
},
"role": {
"arbiter": [10000],
"host": [10000],
"guest": [10000]
},
"job_parameters": {
"common": {
"work_mode": 0,
"backend": 0
}
},
"component_parameters": {
"common": {
"dataio_0": {
"with_label": true
},
"homo_nn_0": {
"encode_label":true,
"max_iter": 20,
"batch_size": -1,
"early_stop": {
"early_stop": "diff",
"eps": 0.0001
},
"optimizer": {
"learning_rate": 0.0015,
"decay": 0.0,
"beta_1": 0.9,
"beta_2": 0.999,
"epsilon": 1e-07,
"amsgrad": false,
"optimizer": "Adam"
},
"loss": "categorical_crossentropy",
"metrics": ["accuracy", "AUC"],
"nn_define": {"class_name": "Sequential", "config": {"name": "sequential", "layers": [{"class_name": "InputLayer", "config": {"batch_input_shape": [null, 784], "dtype": "float32", "sparse": false, "ragged": false, "name": "dense_input"}}, {"class_name": "Dense", "config": {"name": "dense", "trainable": true, "batch_input_shape": [null, 784], "dtype": "float32", "units": 512, "activation": "relu", "use_bias": true, "kernel_initializer": {"class_name": "GlorotUniform", "config": {"seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}, {"class_name": "Dense", "config": {"name": "dense_1", "trainable": true, "dtype": "float32", "units": 256, "activation": "relu", "use_bias": true, "kernel_initializer": {"class_name": "GlorotUniform", "config": {"seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}, {"class_name": "Dense", "config": {"name": "dense_2", "trainable": true, "dtype": "float32", "units": 10, "activation": "softmax", "use_bias": true, "kernel_initializer": {"class_name": "GlorotUniform", "config": {"seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}]}, "keras_version": "2.4.0", "backend": "tensorflow"},
"config_type": "keras"
}
},
"role": {
"host": {
"0": {
"reader_0": {
"table": {
"name": "homo_host_mnist_train",
"namespace": "experiment"
}
},
"dataio_0": {
"with_label": true
}
}
},
"guest": {
"0": {
"reader_0": {
"table": {
"name": "homo_guest_mnist_train",
"namespace": "experiment"
}
},
"dataio_0": {
"with_label": true,
"output_format": "dense"
}
}
}
}
}
}
3.2.4 提交任务,训练模型
$ flow job submit -c workspace/HFL_nn/test_homo_dnn_single_layer_conf.json -d workspace/HFL_nn/test_homo_dnn_single_layer_dsl.json

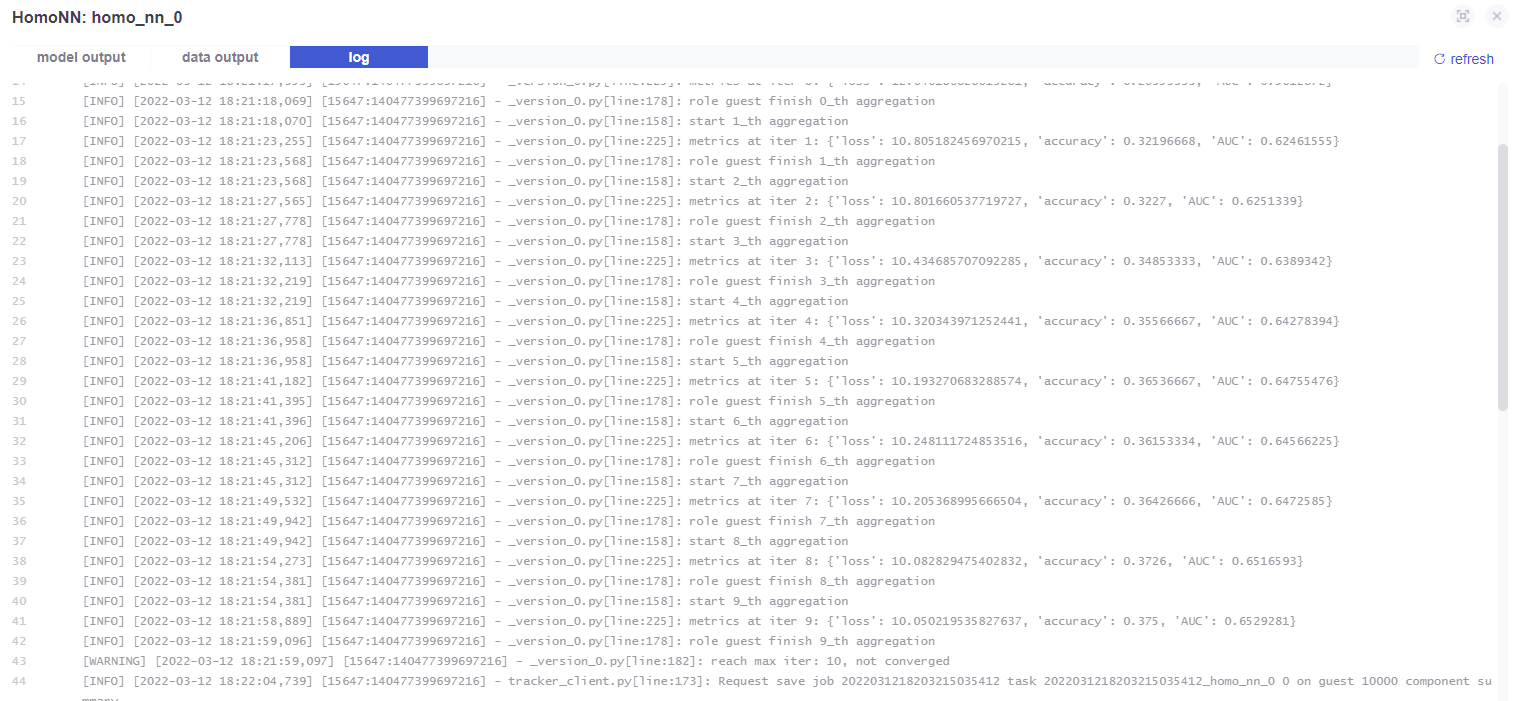
- 查看日志,可以看到模型的训练过程,若出现过早停止,调整参数后重新训练
Original: https://blog.csdn.net/Sisyphus_98/article/details/122998129
Author: HarrisonWu42
Title: 【联邦学习FATE框架实战】(三)MNIST神经网络(Keras)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/691012/
转载文章受原作者版权保护。转载请注明原作者出处!