

训练中的剪枝操作
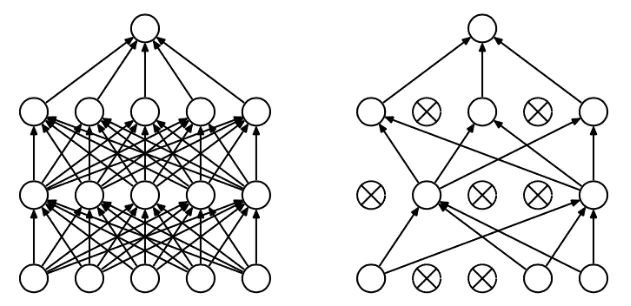
Dropout和DropConnect代表着非常经典的模型剪枝技术。
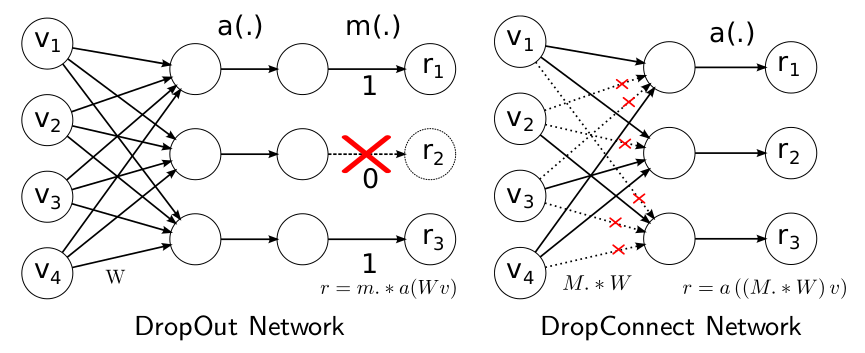
Dropout中随机的将一些神经元的输出置零,这就是神经元剪枝。DropConnect则随机的将一些神经元之间的连接置零,使得权重连接矩阵变得稀疏,这便是权重连接剪枝。
Dropout

Dropconnect
; 模型剪枝
上述两种方法就是最细粒度的剪枝技术,只是这个操作仅仅发生在训练中,对最终的模型不产生影响,因此没有被称为模型剪枝技术。
当然,模型剪枝不仅仅只有对神经元的剪枝和对权重连接的剪枝,根据粒度的不同,至少可以粗分为4个粒度。
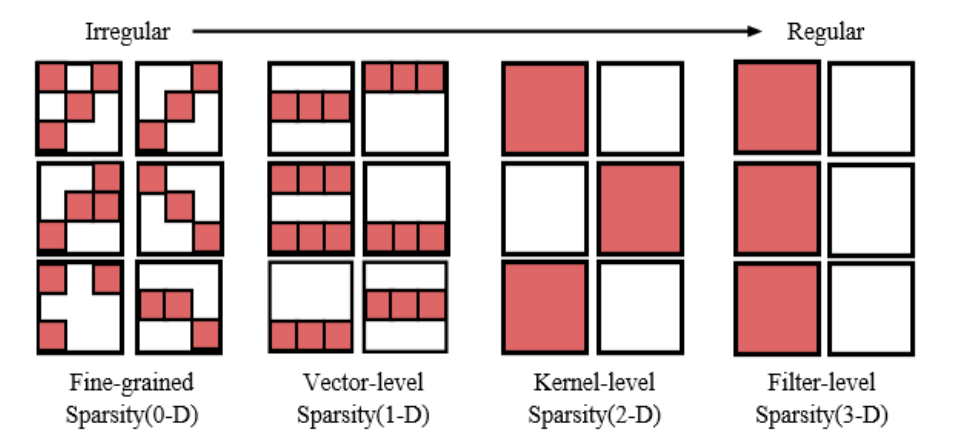
细粒度剪枝(fine-grained):即对连接或者神经元进行剪枝,它是粒度最小的剪枝。
向量剪枝(vector-level):它相对于细粒度剪枝粒度更大,属于对卷积核内部(intra-kernel)的剪枝。
核剪枝(kernel-level):即去除某个卷积核,它将丢弃对输入通道中对应计算通道的响应。
滤波器剪枝(Filter-level):对整个卷积核组进行剪枝,会造成推理过程中输出特征通道数的改变
细粒度剪枝(fine-grained),向量剪枝(vector-level),核剪枝(kernel-level)方法在参数量与模型性能之间取得了一定的平衡,但是网络的拓扑结构本身发生了变化,需要专门的算法设计来支持这种稀疏的运算,被称之为非结构化剪枝。
而滤波器剪枝(Filter-level)只改变了网络中的滤波器组和特征通道数目,所获得的模型不需要专门的算法设计就能够运行,被称为结构化剪枝。除此之外还有对整个网络层的剪枝,它可以被看作是滤波器剪枝(Filter-level)的变种,即所有的滤波器都丢弃。
细粒度剪枝算法
连接剪枝
对神经元和权重连接进行剪枝。
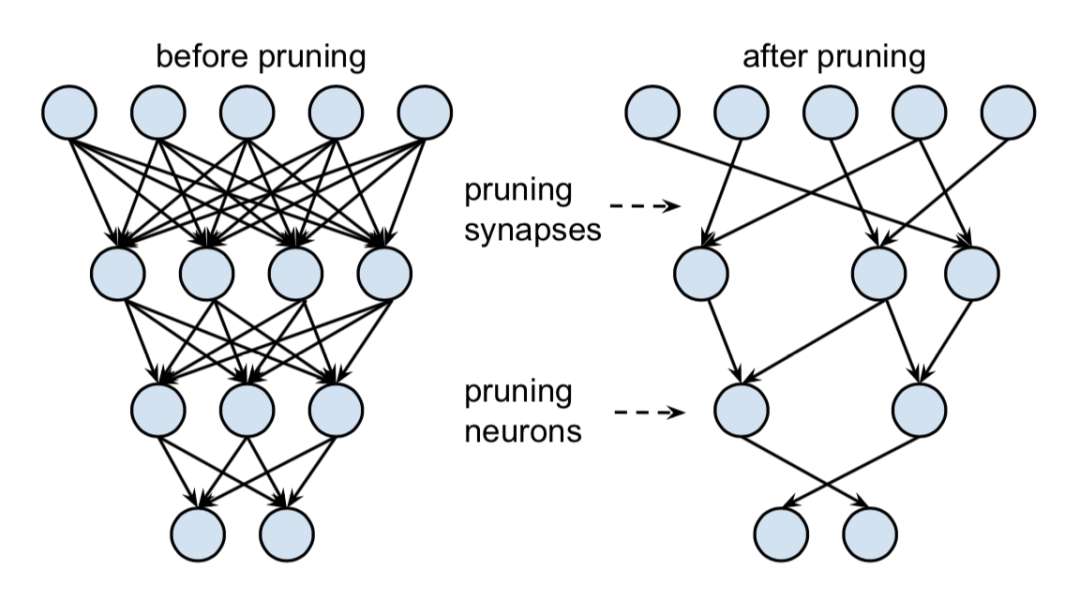
过程如下所示
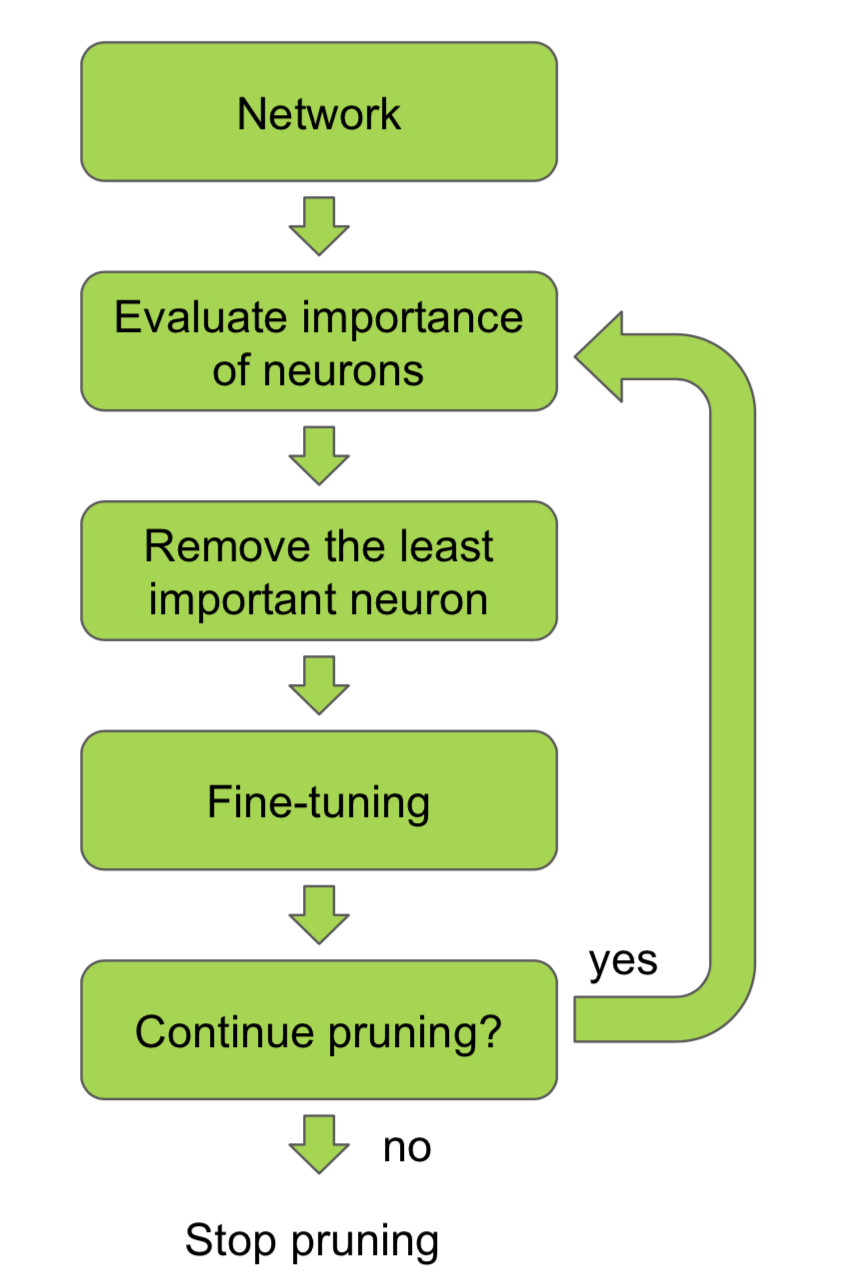
对于评估连接的重要性,这里我们介绍两个最典型的方法代表,其一是基于连接幅度的方法,其二是基于损失函数的方法。
由于特征的输出是由输入与权重相乘后进行加权,权重的幅度越小,对输出的贡献越小,因此一种最直观的连接剪枝方法就是基于权重的幅度,如L1/L2范数的大小。这样的方法只需要三个步骤就能完成剪枝:
第一步:训练一个基准模型。
第二步:对权重值的幅度进行排序,去掉低于一个预设阈值的连接,得到剪枝后的网络。
第三步:对剪枝后网络进行微调以恢复损失的性能,然后继续进行第二步,依次交替,直到满足终止条件,比如精度下降在一定范围内。
不过这种方法的缺陷是:一些在当前轮迭代中虽然作用很小,但是在其他轮迭代中又可能重要。
解决方法《Dynamic Network Surgery for Efficient DNNs》
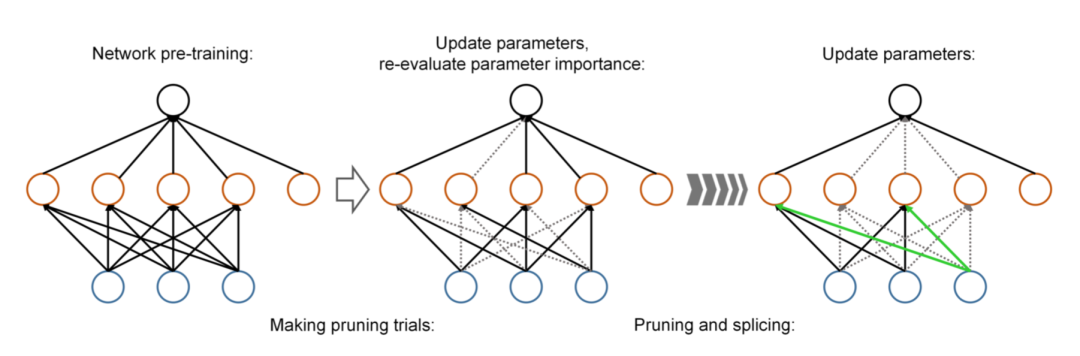
基于权重幅度的方法原理简单,但这是比较主观的经验,即认为权重大就重要性高,事实上未必如此。而另一种经典的连接剪枝方法就是基于优化目标,根据剪枝对优化目标的影响来对其重要性进行判断,以最优脑损伤(Optimal Brain Damage, OBD)方法为代表,这已经是上世纪90年代的技术了。
; 通道剪枝和卷积核剪枝虽然起到了相同的效果,不过剪枝的时候用以衡量的对象是不同的,通道剪枝是对BN层进行过滤,而卷积核剪枝是直接对卷积核本身进行筛选!!!
粗粒度剪枝核心技术(通道剪枝即卷积核剪枝)
通道剪枝算法有三个经典思路。第一个是基于重要性因子,即评估一个通道的有效性,再配合约束一些通道使得模型结构本身具有稀疏性,从而基于此进行剪枝。第二个是利用重建误差来指导剪枝,间接衡量一个通道对输出的影响。第三个是基于优化目标的变化来衡量通道的敏感性。下面我们重点介绍前两种。
《Learning efficient convolutional networks through network slimming》通过激活的稀疏性来判断一个通道的重要性,认为拥有更高稀疏性的通道更应该被去除。它使用batch normalization中的缩放因子γ来对不重要的通道进行裁剪,如下图:
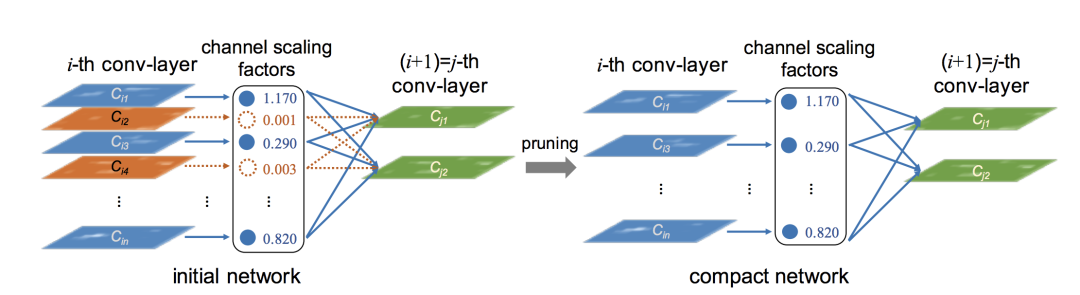
具体实现起来,就是在目标方程中增加一个关于γ的正则项,从而约束某些通道的重要性。
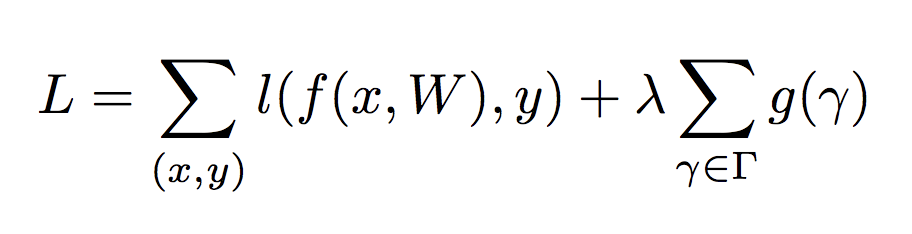
与基于权重幅度的方法来进行连接剪枝一样,基于重要性因子的方法主观性太强,而另一种思路就是基于输出重建误差的通道剪枝算法,它们根据输入特征图的各个通道对输出特征图的贡献大小来完成剪枝过程,可以直接反映剪枝前后特征的损失情况。
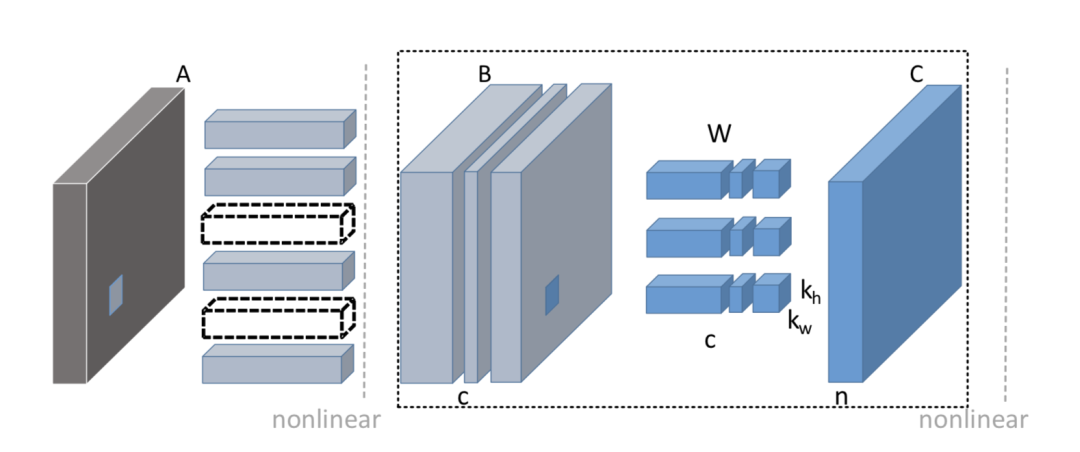
如上图,基于重建误差的剪枝算法,就是在剪掉当前层B的若干通道后,重建其输出特征图C使得损失信息最小。假如我们要将B的通道从c剪枝到c’,要求解的就是下面的问题,第一项是重建误差,第二项是正则项。
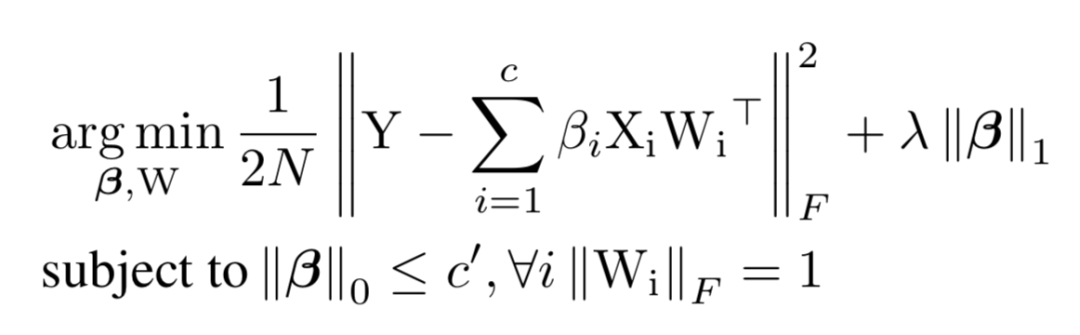
该问题可以分两步进行求解。
第一步:选择候选的裁剪通道。
我们可以对输入特征图按照卷积核的感受野进行多次随机采样,获得输入矩阵X,权重矩阵W,输出Y。然后将W用训练好的模型初始化,逐渐增大正则因子,每一次改变都进行若干次迭代,直到beta稳定,这是一个经典的LASSO回归问题求解。
第二步:固定beta求解W,完成最小化重建误差,需要更新使得下式最小。
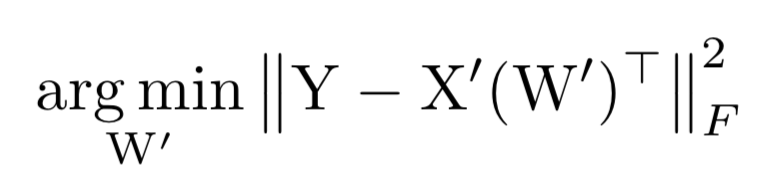
以上两个步骤交替进行优化,最后迭代完剪枝后,就可以得到新的权重。类似的框架还有ThiNet等。
以上就是粗粒度剪枝和细粒度剪枝中最主流的方法的一些介绍。
; 重要性因子的选择
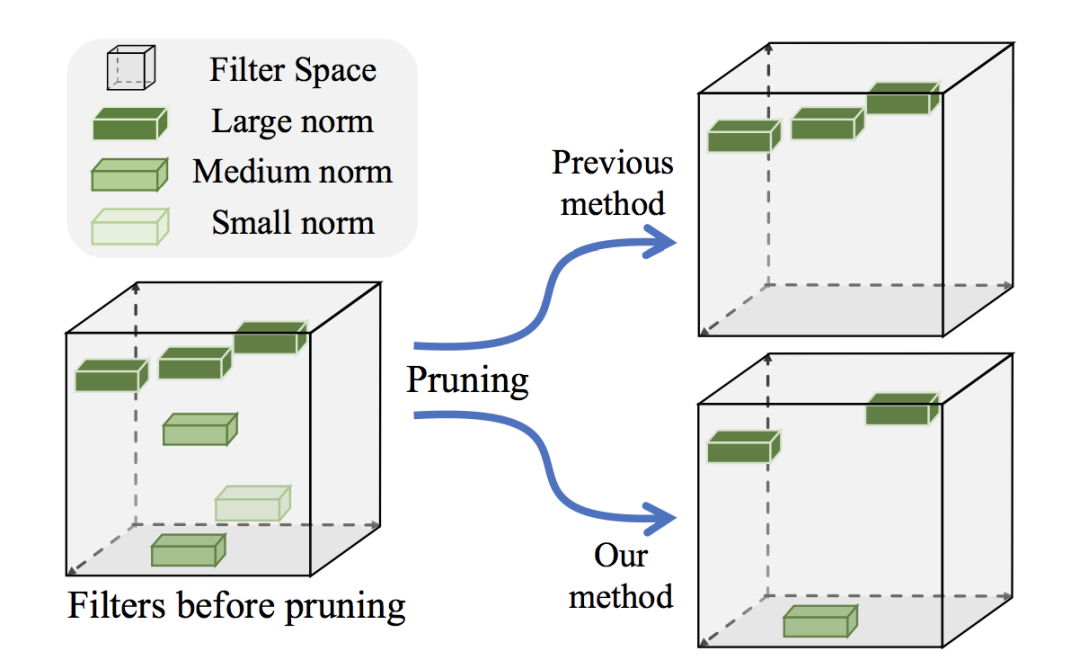
不管是连接剪枝还是通道剪枝,前面都提到了重要性因子,即我们通过某种准则来判断一个连接或者通道是否重要,比如范数。这是非常直观的思想,因为它们影响了输出的大小。但这类方法的假设前提条件太强,需要权重和激活值本身满足一定的分布。
Geometric Median方法就利用了几何中位数对范数进行替换,那是否有更多更好的指标呢?这非常值得关注。
剪枝流程优化
当前大部分框架都是逐层进行剪枝,而没有让各层之间进行联动,这其实是有问题的。因为在当前阶段冗余的模块,并不意味着对其他阶段也是冗余的。以NISP为代表的方法就通过反向传播来直接对整个网络神经元的重要性进行打分,一次性完成整个模型的剪枝。
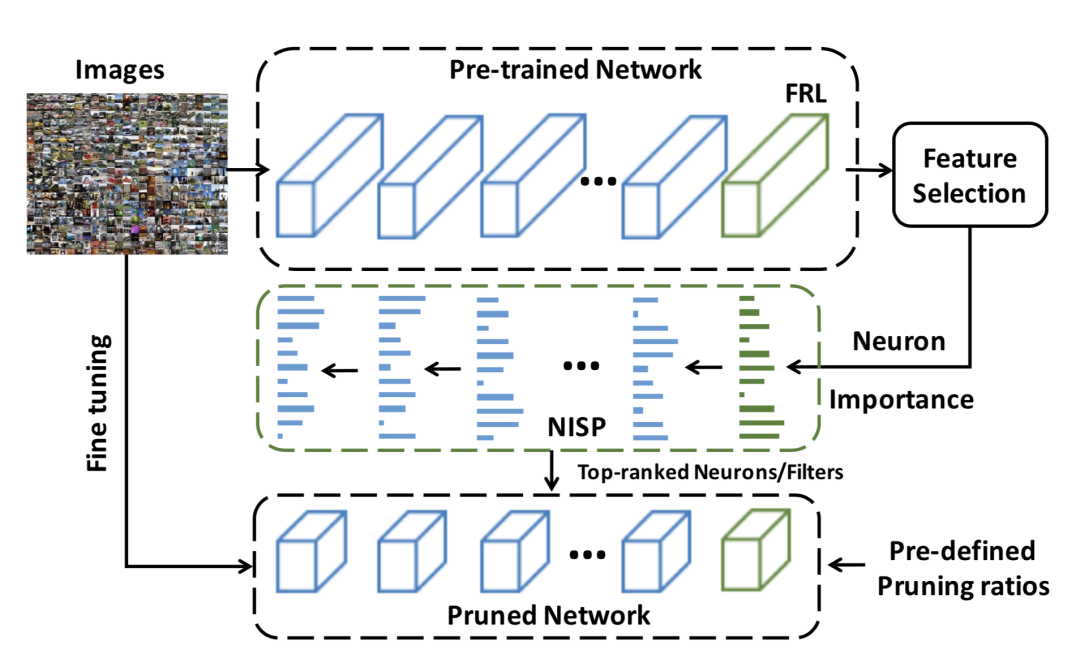
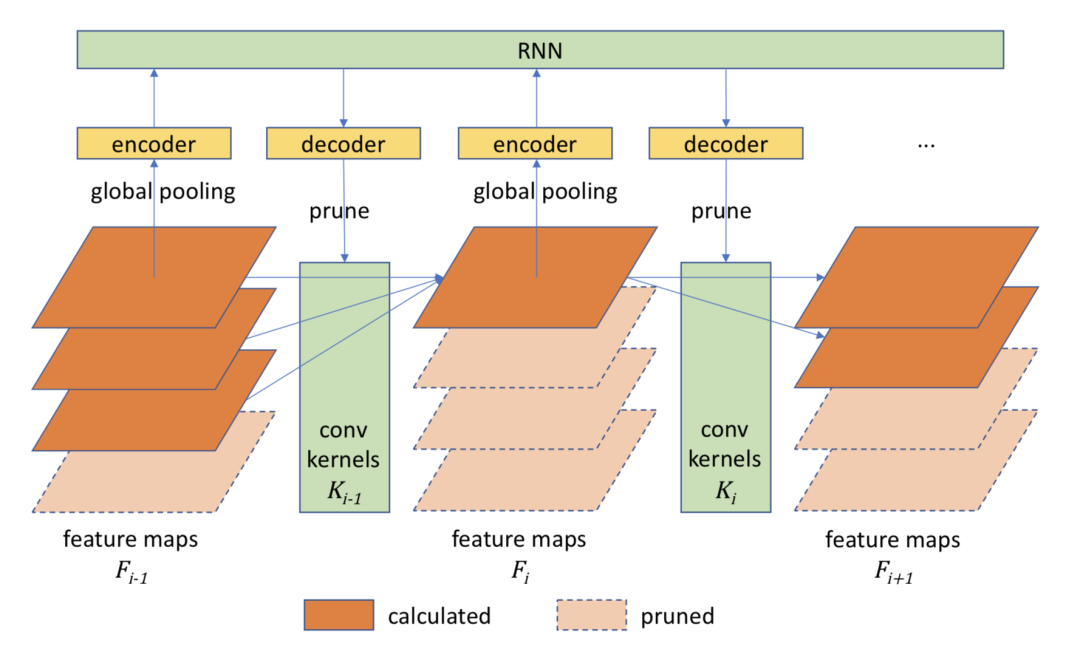
通常来说,模型在剪枝完后进行推理时不会发生变化,即对于所有的输入图片来说都是一样的计算量,但是有的样本简单,有的样本复杂,以前我们给大家介绍过动态推理框架,它们可以对不同的输入样本图配置不同的计算量,剪枝框架也可以采用这样的思路,以Runtime Neural Pruning [12]为代表。
; 自动化剪枝
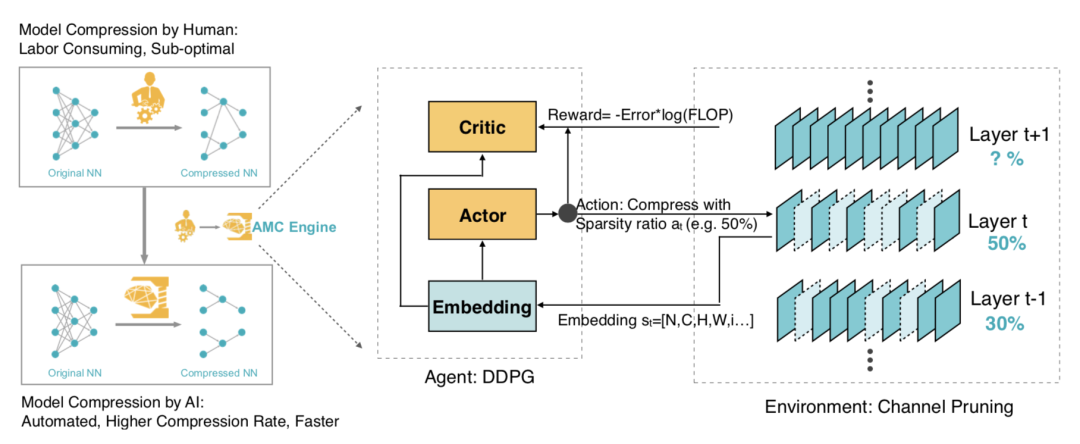
剪枝中我们通常遵循一些基本策略:比如在提取低级特征的参数较少的第一层中剪掉更少的参数,对冗余性更高的FC层剪掉更多的参数。然而,由于深度神经网络中的层不是孤立的,这些基于规则的剪枝策略并不是最优的,也不能从一个模型迁移到另一个模型,因此AutoML方法的应用也是非常自然的,AutoML for Model Compression(AMC)是其中的代表,我们以前也做过介绍。
Original: https://blog.csdn.net/weixin_44214375/article/details/121626594
Author: 做个人吧~
Title: 模型压缩-模型剪枝综述
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/690998/
转载文章受原作者版权保护。转载请注明原作者出处!