

目录
task
Fine-Grained Visual Classification(细粒度视觉分类),以下简称FGVC。
相较于传统的目标检测和分类,有如下两个难点:
-
高类内方差(high intra-class variance):
图片中属于同一类别的对象通常呈现显著不同的姿态和视角。 -
低类间方差(low inter-class variance):
下属类(例如哈士奇和金毛两个下属类,都属于狗这一超类)之间的视觉差异往往是微妙的,因为它们属于同一超类别。
数据集
当前细粒度分类的主流数据集有三个:
- CUB-200-2011:鸟类数据集,200类11788张图像,每张图像包含15各部位的位置信息。(位置信息主要给基于部件的网络模型训练用)
- Stanford Cars:汽车数据集,196类16185张图像,不包含部件信息。
- FGVC-Aircraft:飞机数据集,102类10200张图像,不包含部件信息。
近两年大部分细粒度分类论文都以上述三个数据集作为benchmark。
AP-CNN
2021年2月刊登在IEEE的一篇细粒度分类的文章。
论文地址(下载需要校园网)
源码地址
整体结构


; 1、主要改进
1)Attention Pyramid(注意金字塔)
在FPN的基础上,对每一层feature map都使用注意力机制,形成一个自下而上的注意力层级结构,作者给其取名为 注意金字塔(Attention Pyramid),这个结构中每一层又包含两个部分,分别是 空间注意 和 通道注意,生成过程如下图所示:

- 每一层的通道注意由FPN中对应层的Feature map进行一次全局平均池化和两次全连接而成。
公式如下:A k ( c ) = σ ( W 2 ⋅ R e L U ( W 1 ⋅ G A P ( F k ) ) ) A^{(c)}_k=\sigma(W_2\cdot ReLU(W_1\cdot GAP(F_k)))A k (c )=σ(W 2 ⋅R e L U (W 1 ⋅G A P (F k ))) - 空间注意则由对应的Feature map进行一次33的反卷积,再做sigmoid而成。
公式如下:A k ( s ) = σ ( v c ∗ F k ) A^{(s)}_k=\sigma(v_cF_k)A k (s )=σ(v c ∗F k )
而 空间注意通常的做法是对特征层进行 最大池化和 平均池化,之后把这俩结果进行堆叠,再做1*1卷积,然后sigmoid,最后和原特征层相乘即可。
这个部分作者没有做消融实验,我认为作者是想要和之前已经存在的CBAM进行区别,所以进行反卷积,魔改了一下😓。
- 想要了解注意力机制原理的读者可以参考:注意力机制的实现
; 2) ROI引导的细化模块
流程图:

以上述注意金字塔得到的空间注意 A k s A^{s}_{k}A k s 作为掩膜,在每一层都生成对应数量的ROI(region of interest),效果如下:

之后根据这些生成的ROI做基于ROI的Dropblock和Zoom-in(过程省略,因为非常简单),得到最终的特征map Z k Z_k Z k .
最后再对 Z k Z_k Z k 做一次分类,将这次的结果和初始FPN经过注意力后得到的分类结果进行平均,得到最终结果。
2、与主流模型比较

; 3、可视化
首先在训练时加上可视化选项,cd到AP-CNN目录下,激活对应环境,输入:
python -m vindom.server
在本机指定的窗口(官方初始定义为8097)
出现如下提示:
浏览器打开本机对应端口:

然后运行训练文件,输入:
python train.py --visualize
- 记得要带上可视化选项。
如下提示,则开始训练。

此时观察到浏览器端口页面变为训练与测试图像的ROI和三层mask展示:
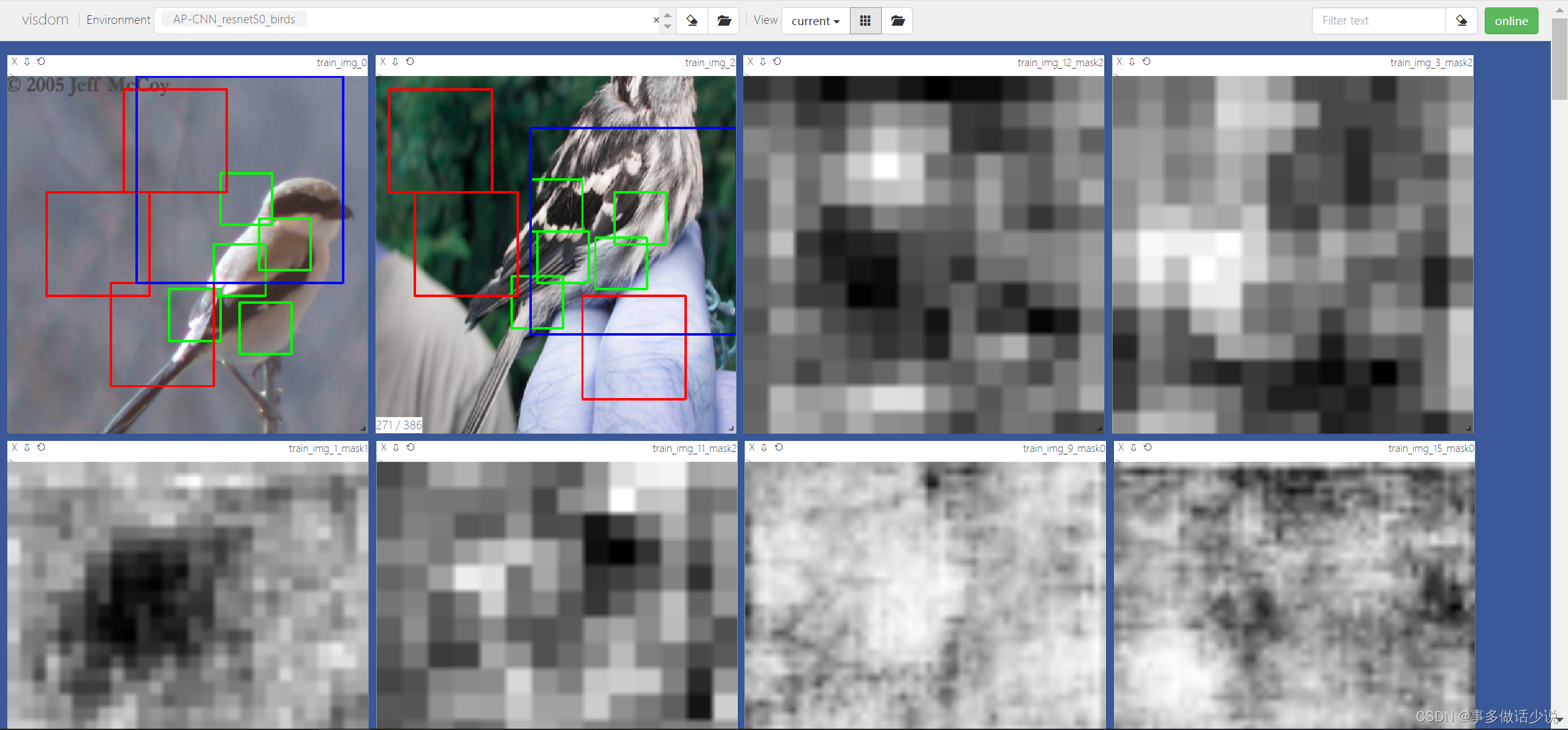
(顺序被我不小心打乱了😓,我还不会恢复…)
4、总结
- 本文其实没有任何的创新点,作者将 空间注意和 通道注意在FPN每一层都进行运用,得到了相较于 baseline:NTS在CUB-200-2011上0.9个点的精度提升。
- lego的方法值得学习和应用😏
Original: https://blog.csdn.net/no_pain_no_gain_/article/details/124494939
Author: 事多做话少说
Title: 【论文笔记】AP-CNN: Weakly Supervised Attention Pyramid Convolutional Neural Network for FGVC
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/690910/
转载文章受原作者版权保护。转载请注明原作者出处!