

视频链接:《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
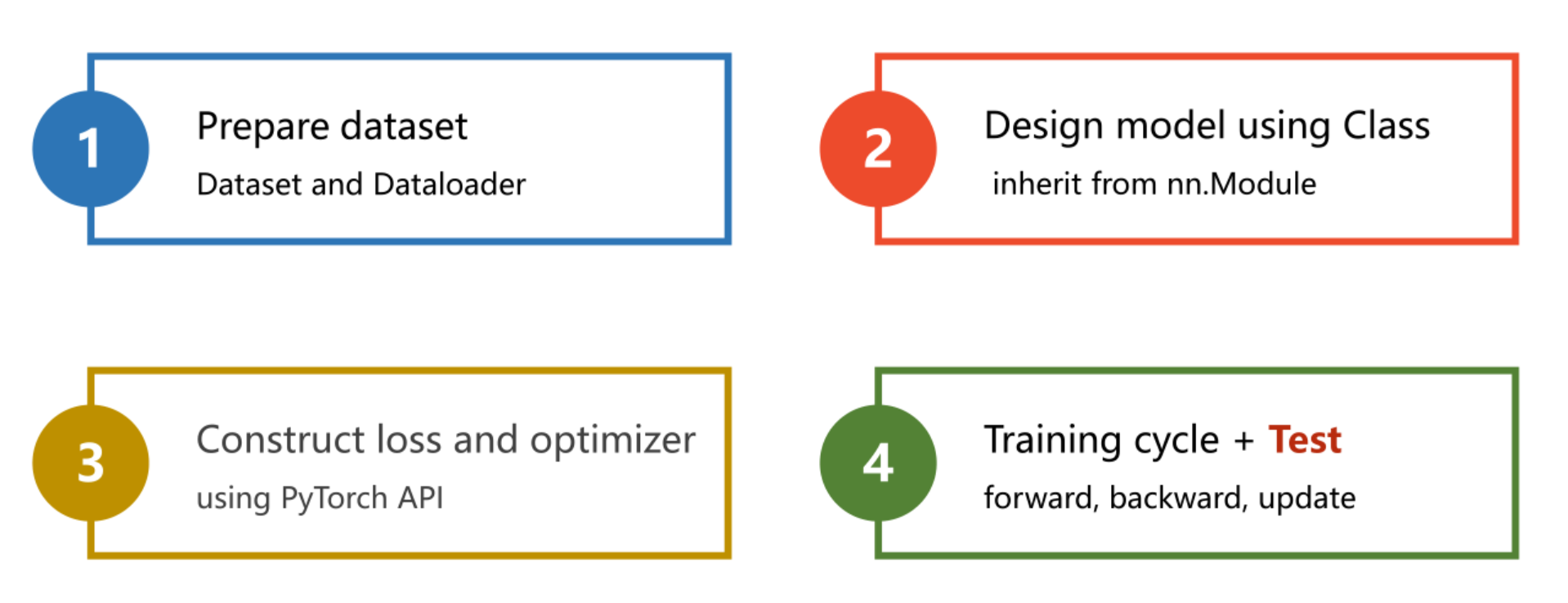
思路:
- 准备数据集
- 设计模型类
- 构造损失函数和优化器
- 训练和测试

1.准备数据集:
因为MNIST是torchvision.datasets自带的数据集,是torch.utils.data.Dataset的子类,因此可以直接使用数据加载器DataLoader。
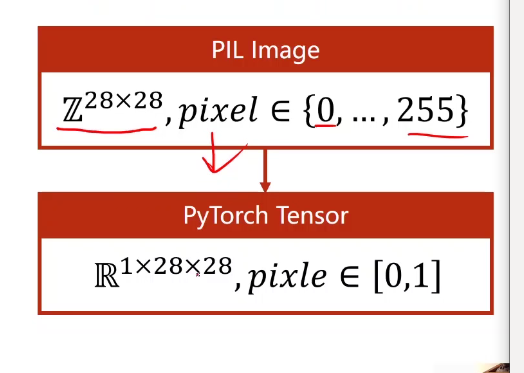
- MNIST里面的数据是PIL image,所以需要把它转换为PyTorch里面的张量形式。我们都进来的图像张量一般都是(W,H,C),而PyTorch的一般格式是(C,H,W)(C为通道数,H为高,W为宽),(W,H,C)–>(C,H,W)。采用transforms.ToTensor()方法。
- MNIST数据集里面的值处于0~255之间,为了更好地进行模型的训练,我们对其采用归一化处理,使其值处于0~1内。采用transforms.Normalize()方法。
因此在加载数据集时,我们应完成以上两步操作,再使用数据加载器。代码如下:
这是一个手写数字识别的多分类问题
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader
import torch
import torch.nn.functional as F
1、准备数据集
处理数据
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
batch_size = 64
训练集
mnist_train = MNIST(root='../dataset/minist', train=True, transform=transform, download=True)
train_loader = DataLoader(dataset=mnist_train, shuffle=True, batch_size=batch_size)
测试集
mnist_test = MNIST(root='../dataset/minist', train=False, transform=transform, download=True)
test_loader = DataLoader(dataset=mnist_test, shuffle=True, batch_size=batch_size)
2.设计模型类
设计模型类的注意事项:
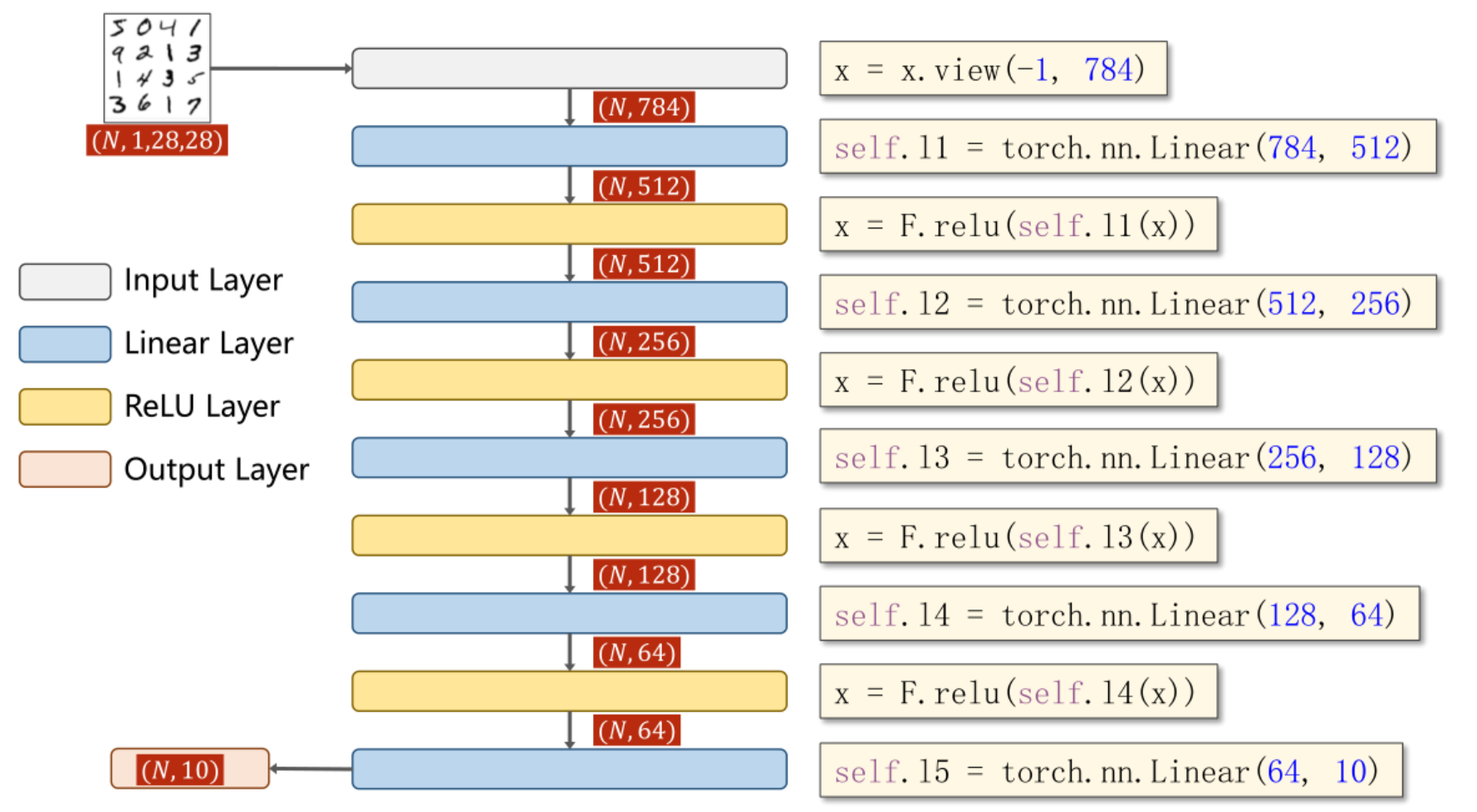
- 因为我们之前把数据集转换成了PyTorch的数据格式(N,C,H ,W ),但是别忘了神经网络的输入要求我们是一个二维的矩阵,因此我们必须将数据格式(N,C,H ,W )—>(N,CHW),对应代码中的x = x.view(-1,784)
- 这里除了最后一层,其他层我们使用的激活函数为relu()函数
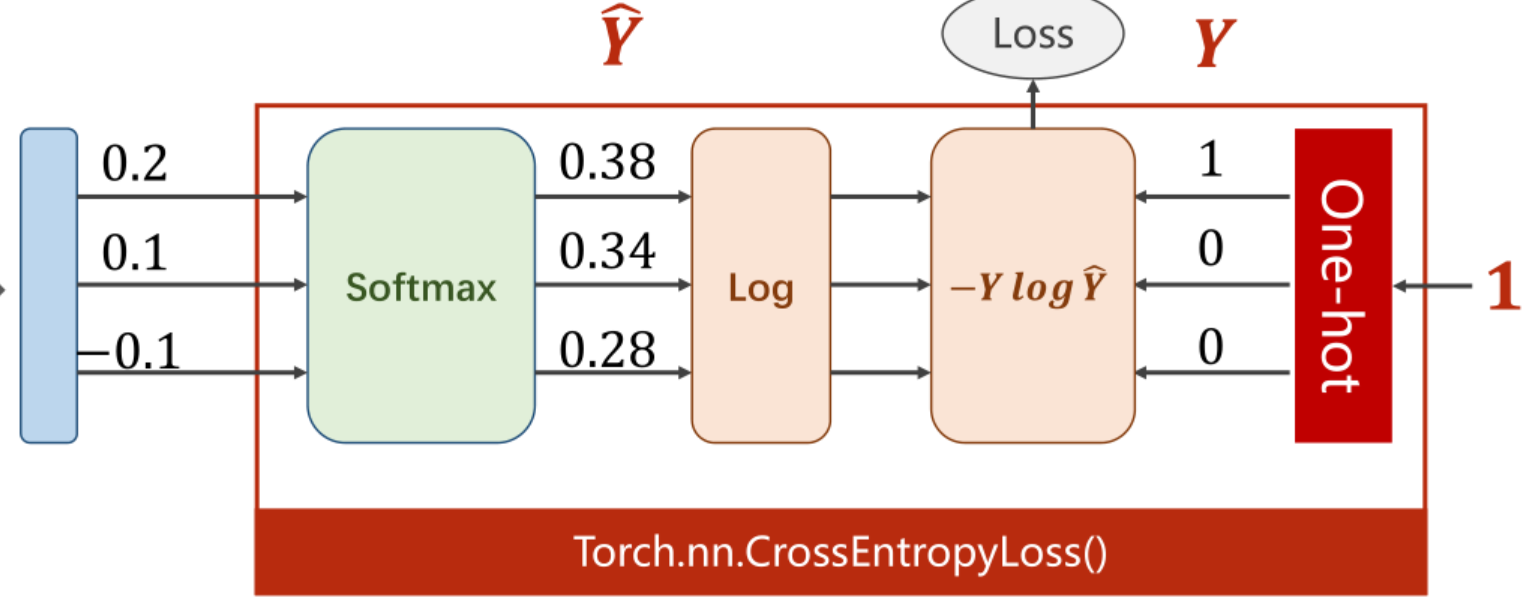
- 多分类的最后一层使用的激活函数为Softmax(),输出的特征数为类别数,是每个输出值>0,且所有和为1,损失函数为交叉熵误差(负对数似然),PyTorch中为torch.nn.CrossEntropyLoss(),交叉熵损失把从Softmax函数到求损失这整个过程都包括了,所以我们如果使用交叉熵损失,那么神经网络的最后一层我们是不用使用激活函数的,如图所示:
下面是模型类的实现代码:
2、设计模型类
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
# 生成层
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
# 注意事项1
x = x.view(-1, 784)
# 注意事项2
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
# 注意事项3
x = self.l5(x)
return x
3.构造损失函数和优化器
这里我们使用的损失函数为交叉熵误差
model = Net()
3、构造损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
4.训练和测试
我们这里将一个训练周期和一个测试周期分别封装成了一个方法,这样可以提高代码的复用性。代码如下:
训练代码如下:
4、训练和测试
定义训练方法,一个训练周期
def train(epoch):
running_loss = 0.0
for idx, (inputs, target) in enumerate(train_loader, 0):
# 这里的代码与之前没有区别
# 正向
y_pred = model(inputs)
loss = criterion(y_pred, target)
# 反向
optimizer.zero_grad()
loss.backward()
# 更新
optimizer.step()
running_loss += loss.item()
if idx % 300 == 299: # 每300次打印一次平均损失,因为idx是从0开始的,所以%299,而不是300
print(f'epoch={epoch + 1},batch_idx={idx + 1},loss={running_loss / 300}')
running_loss = 0.0
测试代码如下:
定义测试方法,一个测试周期
def test():
# 所有预测正确的样本数
correct_num = 0
# 所有样本的数量
total = 0
# 测试时,我们不需要计算梯度,因此可以加上这一句,不需要梯度追踪
with torch.no_grad():
for images, labels in test_loader:
# 获得预测值
outputs = model(images)
# 获取dim=1的最大值的位置,该位置就代表所预测的标签值
_, predicted = torch.max(outputs.data, dim=1)
# 累加每批次的样本数,以获得一个测试周期所有的样本数
total += labels.size(0)
# 累加每批次的预测正确的样本数,以获得一个测试周期的所有预测正确的样本数
correct_num += (predicted == labels).sum().item()
print(f'Accuracy on test set:{100 * correct_num/total}%') # 打印一个测试周期的正确率
if __name__ == '__main__':
# 训练周期为10次,每次训练所有的训练集样本数,并测试
for epoch in range(10):
train(epoch)
test()
以上所有的代码就写完了,下面的全部的代码总和,并给出输出结果:
这是一个手写数字识别的多分类问题
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader
import torch
import torch.nn.functional as F
1、准备数据集
处理数据
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
batch_size = 64
训练集
mnist_train = MNIST(root='../dataset/minist', train=True, transform=transform, download=True)
train_loader = DataLoader(dataset=mnist_train, shuffle=True, batch_size=batch_size)
测试集
mnist_test = MNIST(root='../dataset/minist', train=False, transform=transform, download=True)
test_loader = DataLoader(dataset=mnist_test, shuffle=True, batch_size=batch_size)
2、设计模型类
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
# 生成层
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
# 注意事项1
x = x.view(-1, 784)
# 注意事项2
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
# 注意事项3
x = self.l5(x)
return x
model = Net()
3、构造损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
4、训练和测试
定义训练方法,一个训练周期
def train(epoch):
running_loss = 0.0
for idx, (inputs, target) in enumerate(train_loader, 0):
# 这里的代码与之前没有区别
# 正向
y_pred = model(inputs)
loss = criterion(y_pred, target)
# 反向
optimizer.zero_grad()
loss.backward()
# 更新
optimizer.step()
running_loss += loss.item()
if idx % 300 == 299: # 每300次打印一次平均损失,因为idx是从0开始的,所以%299,而不是300
print(f'epoch={epoch + 1},batch_idx={idx + 1},loss={running_loss / 300}')
running_loss = 0.0
定义测试方法,一个测试周期
def test():
# 所有预测正确的样本数
correct_num = 0
# 所有样本的数量
total = 0
# 测试时,我们不需要计算梯度,因此可以加上这一句,不需要梯度追踪
with torch.no_grad():
for images, labels in test_loader:
# 获得预测值
outputs = model(images)
# 获取dim=1的最大值的位置,该位置就代表所预测的标签值
_, predicted = torch.max(outputs.data, dim=1)
# 累加每批次的样本数,以获得一个测试周期所有的样本数
total += labels.size(0)
# 累加每批次的预测正确的样本数,以获得一个测试周期的所有预测正确的样本数
correct_num += (predicted == labels).sum().item()
print(f'Accuracy on test set:{100 * correct_num/total}%') # 打印一个测试周期的正确率
if __name__ == '__main__':
# 训练周期为10次,每次训练所有的训练集样本数,并测试
for epoch in range(10):
train(epoch)
test()
结果如下:(结果并未全部给出)
epoch=1,batch_idx=300,loss=2.185831303993861
epoch=1,batch_idx=600,loss=0.9028161239624023
epoch=1,batch_idx=900,loss=0.4859987227121989
Accuracy on test set:88.26%
epoch=2,batch_idx=300,loss=0.34666957701245943
epoch=2,batch_idx=600,loss=0.2818286288777987
epoch=2,batch_idx=900,loss=0.23189411964267492
Accuracy on test set:94.17%
……..
epoch=7,batch_idx=300,loss=0.055408267891034486
epoch=7,batch_idx=600,loss=0.061728662827517836
epoch=7,batch_idx=900,loss=0.06610782677152505
Accuracy on test set:97.48%
epoch=8,batch_idx=300,loss=0.04807355252560228
epoch=8,batch_idx=600,loss=0.051277296949798865
epoch=8,batch_idx=900,loss=0.047160824784853804
Accuracy on test set:97.43%
epoch=9,batch_idx=300,loss=0.03567605647413681
epoch=9,batch_idx=600,loss=0.04471589110791683
epoch=9,batch_idx=900,loss=0.04066507628730809
Accuracy on test set:97.65%
epoch=10,batch_idx=300,loss=0.02855320817286459
epoch=10,batch_idx=600,loss=0.03323486545394796
epoch=10,batch_idx=900,loss=0.035332622032923006
Accuracy on test set:97.79%
本人还是一名学生,如有错误,请指出,谢谢哈!!
Original: https://blog.csdn.net/weixin_62321421/article/details/121435225
Author: pig774
Title: PyTorch深度学习实践 第九讲 多分类问题 手写数字识别(训练+测试) 超详细
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/690810/
转载文章受原作者版权保护。转载请注明原作者出处!