

目录
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding
bert的两个步骤:预训练pre-training和微调fine-tuning
文本分类代码
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding
谷歌的小哥写出来的,据说是master,我辈楷模
文章逐段简介
每段摘要,读的时候带有目的去读
1.摘要(Abstract):与别的文章的区别是什么?效果有多好?
gpt是用左侧的信息去预测未来,bert是用左右两边的上下文的双向的信息(带掩码所以允许看左右的信息,相当于完形填空);
ELMO是基于RNN的架构的双向系统,bert是transformer,在应用的时候ELMO需要改下层架构,bert不用;
总而言之,就是吸取了ELMO可以双向的特点,又用了GPT的新的框架。
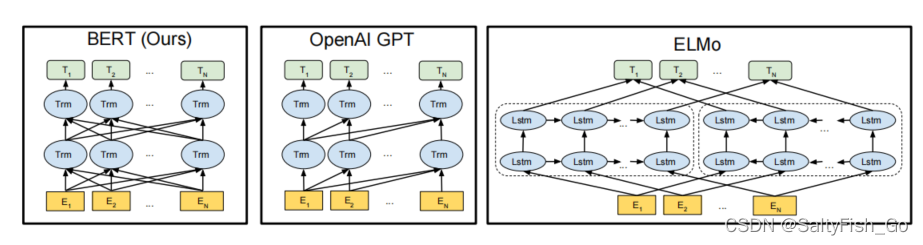

2.引言(Introduction):语言模型的简单介绍;摘要第一段的扩充;主要想法;如何解决所遇到的问题;
贡献点:双向信息的重要性(句子从左看到右,从右看到左)、在BERT上做微调效果很好、代码开源
3.结论(Conlusion):无监督的预训练很重要(在计算机视觉领域,在没有标签的数据集上做训练比在有标签的数据集上做训练效果会更好);主要贡献是将这些发现进一步推广到深度双向架构,使相同的预训练模型能够成功处理一系列的 NLP 任务。
在本篇论文的结论中最大贡献是双向性(在写一篇论文的时候,最好有一个卖点,而不是这里好那里也好)。
选了选双向性带来的不好是什么?做一个选择会得到一些,也会失去一些。
缺点是:与GPT(Improving Language Understanding by Generative Pre-Training)比,BERT用的是编码器,GPT用的是解码器。BERT做机器翻译、文本的摘要(生成类的任务)不好做。
但分类问题在NLP中更常见。
完整解决问题的思路:在一个很大的数据集上训练好一个很宽很深的模型,可以用在很多小的问题上,通过微调来全面提升小数据的性能(在计算机视觉领域用了很多年),模型越大,效果越好(很简单很暴力)。
Bert从入门到放弃
bert的贡献:提出了一个深的神经网络,通过大的数据集训练,应用在不同的Nlp任务上面,有了质的飞跃。
bert的两个步骤:预训练pre-training和微调 fine-tuning

预训练:模型在没有标号的数据上训练
微调:模型被初始化成与训练的哪个权重,所有的参数在微调的时候都使用代标号的数据参与训练
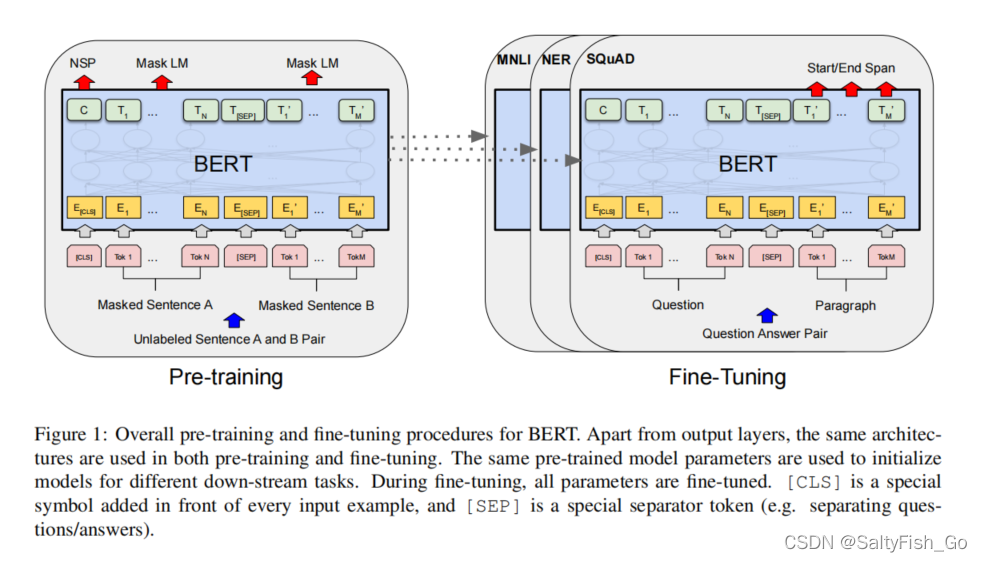
预训练的时候,输入的是没有标号的句子对sentence pair
微调:对于每个下游的任务,都有一个新的BERT模型,他的初始化参数都源自于预训练的权重。对于每个任务,有自己的带标号的数据,然后继续进行训练,得到每个任务自己的一套参数。
切词的方法——WordPiece embeddings

目的:
减小嵌入层的复杂度,如果按照空格分词的话,可能有个百万级的词典,这里的方法是,如果一个token出现的概率不大的话,就只 保留它的子序列(很有可能是个词根),也就是把一个比较长的词切成一个一个的片段,而且这些片段经常出现。
如何把两个句子放在一起:
一个序列不一定只有一个句子,也有可能是两个句子的连接,当这个序列是一个聚合序列时,第一个token是classifification token ([CLS]),用来识别聚合序列并作为序列的开始。
区分句子的两个方法:1、在第一个句子结束的时候插入一个特殊token(SEP);2、学一个嵌入层embedding(图中的E),来表示每个词是在第一个句子还是在第二个句子。
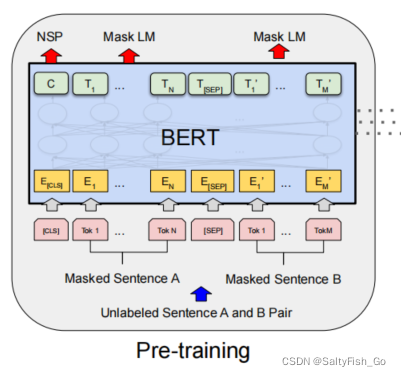
输入表示input representation
每个词元的输入是由三项组成:自身的token embedding,分割嵌入(在哪一个句子里)segmentation embedding,位置position embedding

预训练
task1 masked
在预训练的过程中把15%的词元换成mask,微调不换,因此预训练和微调看到数据不太一样,会产生一些问题,为了解决问题,采用了以下方法:
80%的数据真的进行mask
my dog is hairy → my dog is
10%的数据换成了随机词元
my dog is hairy → my dog is apple
10%的数据什么也不干,就标记一下预测
my dog is hairy → my dog is hariy
Task 2#: Next Sentence Prediction
为了让模型捕捉两个句子的联系,这里增加了Next Sentence Prediction的预训练方法,即给出两个句子A和B,B有一半的可能性是A的下一句话,训练模型来预测B是不是A的下一句话
Input = [CLS] the man went to [MASK] store [SEP]
penguin [MASK] are flight ## less birds [SEP]
Label = NotNext
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
训练模型,使模型具备理解长序列上下文的联系的能力
文本分类代码
学习的时候看到的代码,手把手带你做一个文本分类实战项目(模型+代码解读)_哔哩哔哩_bilibili,下次忘了可以回来看看每个代码块的作用。不过不是bert的,再出一个bert代码理解博客。
数据库生成
这个类是用来生成数据库,初始化函数把文本和标号分别叠加起来;
getitem函数的目的是为了 返回单条样本, 对于测试集就是返回单条样本的feature,如果是训练集就是返回一个样本的Feature+label
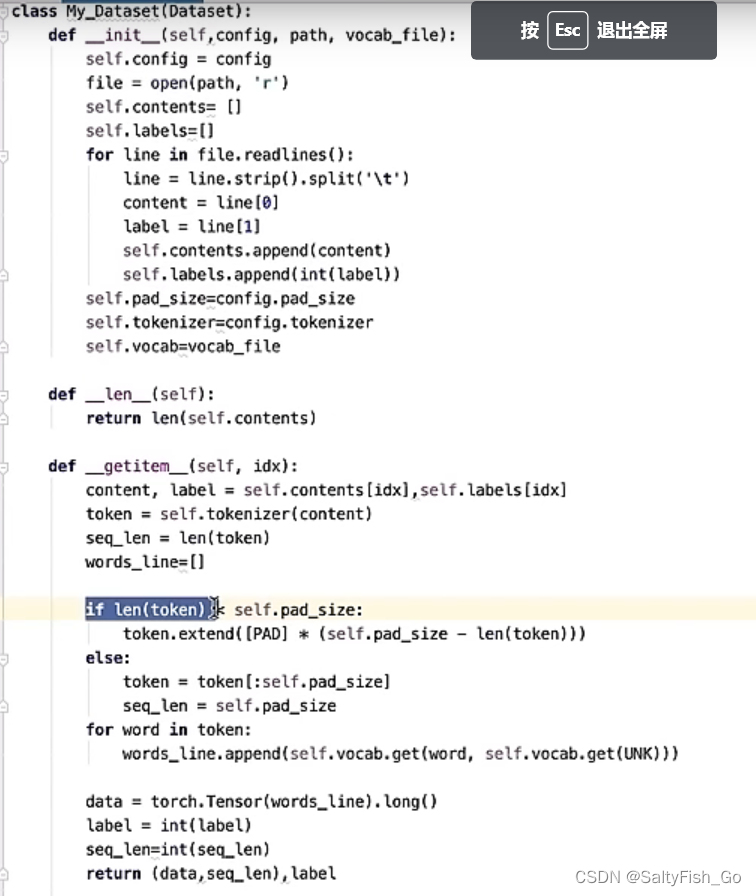
在数据预处理的时候定义到同一长度 ,如果数据不够长就pad补到32长度,如果大于32,就截断;然后再转化成tensor
定义模型

padding_idx=config.n_vocab-1把pad符号传进来,表明他不参与更新。
训练过程
首先定义优化器adam;
进入迭代器:数据放入模型得到输出,误差回传,更新,一百个batch打印一次效果。
挖坑环节
下面是给自己挖的坑,等着一点点自己回答吧,看心情更
- BERT分为哪两种任务,各自的作用是什么;
预训练pre-training和微调fine-tuning
2.在计算MLM预训练任务的损失函数的时候,参与计算的Tokens有哪些?是全部的15%的词汇还是15%词汇中真正被Mask的那些tokens?
参与计算的只有被mask的单词
计算的损失是把15%的masked的单词都计算了损失(不只是80%真正mask,也包括10%随机替换的和10%没有替换的)
3.在实现损失函数的时候,怎么确保没有被 Mask 的函数不参与到损失计算中去;
criterion = nn.CrossEntropyLoss(ignore_index=0)保证没有被masked的词汇没有被计算损失
4.BERT的三个Embedding为什么直接相加
包含了位置信息,token信息和segment(在第一个还是第二个句子中)信息
5.BERT的优缺点分别是什么?
优点:
” 大规模预训练“,” 更宽深层双向encoding“,” 带MASK的无监督训练“,” 注意力机制“,” fine-tuned模型“
-
多头的注意力机制和双向encoding让 BERT的无监督训练更有效,并且使得BERT可以构造更宽的深度模型:
-
把特定任务的 模型fine-tune放到后面去做,增大整个模型的 灵活性。
3. BERT无监督(自监督)的预训练,给了其他 连续型数据问题很多想象力
缺点:
- BERT在第一个预训练阶段,假设句子中多个单词被Mask掉,这些被Mask掉的单词之间没有任何关系,是条件独立的,然而有时候这些单词之间是有关系的,比如”New York is a city”,假设我们Mask住”New”和”York”两个词,那么给定”is a city”的条件下”New”和”York”并不独立,因为”New York”是一个实体,看到”New”则后面出现”York”的概率要比看到”Old”后面出现”York”概率要大得多。
BERT在预训练时会出现特殊的[MASK],但是它在下游的fine-tune中不会出现,这就造成了预训练和微调之间的不匹配,微调不出现[MASK]这个标记,模型好像就没有了着力点、不知从哪入手。所以只将80%的替换为[mask],但这也 只是缓解、不能解决。 - 另外还有一个缺点,是BERT在分词后做[MASK]会产生的一个问题,为了解决OOV的问题,我们通常会把一个词切分成更细粒度的WordPiece。BERT在Pretraining的时候是随机Mask这些WordPiece的,这就可能出现只Mask一个词的一部分的情况
6.你知道有哪些针对BERT的缺点做优化的模型?
ERNIE from Baidu
Basic-Level Masking: 跟bert一样对单字进行mask,很难学习到高层次的语义信息;
Phrase-Level Masking: 输入仍然是单字级别的,mask连续短语;
Entity-Level Masking: 首先进行实体识别,然后将识别出的实体进行mask。
7.BERT怎么用在生成模型中?
(1 封私信 / 80 条消息) 如何把BERT用在生成模型中? – 知乎 (zhihu.com)
Original: https://blog.csdn.net/weixin_45169380/article/details/124449323
Author: SaltyFish_Go
Title: Bert从入门到放弃——Bert文章精读(每部分的内容简介)及核心问题
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/690730/
转载文章受原作者版权保护。转载请注明原作者出处!