

- 作业要求:
手写体数字识别
数据集:MNIST
数据集下载网址:http://yann.lecun.com/exdb/mnist/
参考网址: https://zhuanlan.zhihu.com/p/101262336
https://blog.csdn.net/panrenlong/article/details/81736754
深度神经网络方法(任选):CNN、RNN、GNN、LSTM、MM、GCN……
典型结构(任选):AlexNet、VGG、GoogleNet……
目标:只有一个,让网络跑起来
2. 数据理解与获取:
MNIST数据集是由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。
获取方法一:
官方网站下载:http://yann.lecun.com/exdb/mnist/
一共4个文件,训练集、训练集标签、测试集、测试集标签
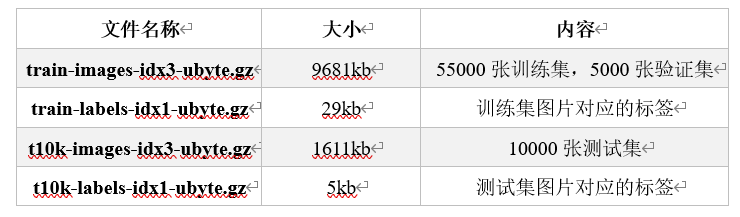

获取方法二:
使用TensorFlow中input_data.py脚本来读取数据及标签,使用这种方式时,可以不用事先下载好数据集,会自动下载并存放到指定的位置。
3. 实现思路
使用tensorflow编写卷积神经网络(CNN)代码进行MNIST数据集的手写数字识别,整体采用Alexnet网络架构搭建神经网络,由于MNIST影像大小为28 x 28,所以网络结构做了相应调整,从而适应数据。MNIST训练集数据用于模型训练,计算训练集准确率,训练好模型将其保存在model文件夹,使用MNIST测试集进行模型测试,计算测试集准确率,总体测试准确率在96%以上。
4. 网络架构介绍——AlexNet
Alexnet架构本质上与Lenet架构相同,Alexnet将CNN卷积神经网络的基本原理应用到更深,更宽的网络中。
对比Lenet架构:
① 更大的池化窗口,使用最大池化层
② 更大的卷积核窗口和步长
③ 新加了三层卷积层,更多的输出通道
Alexnet架构主要使用到的新技术如下:
(1) 使用ReLu作为CNN的激活函数,标准的CNN模型采用tanh或sigmoid激活函数,但是在进行梯度下降时,神经元梯度会趋于饱和,参数更新速度慢,在进行梯度下降计算时,Relu函数的训练速度更快,错误率更低。
(2) 训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合,以0.5的概率对每个隐层神经元的输出设为0,那些”失活的”的神经元不再进行前向传播并且不参与反向传播。dropout在前两个全连接层中使用,非常有效避免了过拟合。
(3) 在CNN中采用重叠的最大池化,此前CNN中普遍使用平均池化,Alexnet网络架构全部采用最大池化,避免平均池化的模糊化效果。并且Alexnet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4) 提出了LRU层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
AlexNet网络架构示意图:
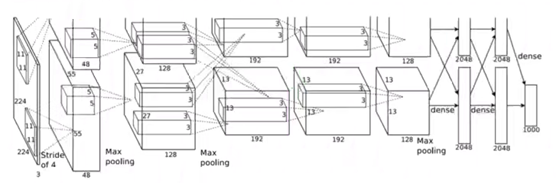
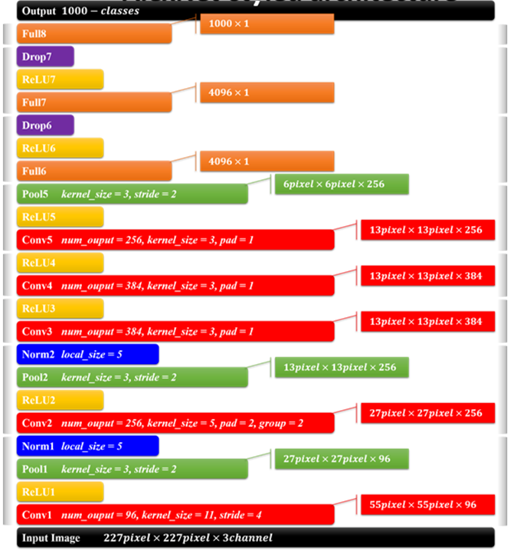
AlexNet网络架构各层处理细节示意图:

Alexnet网络架构层级处理流程图:
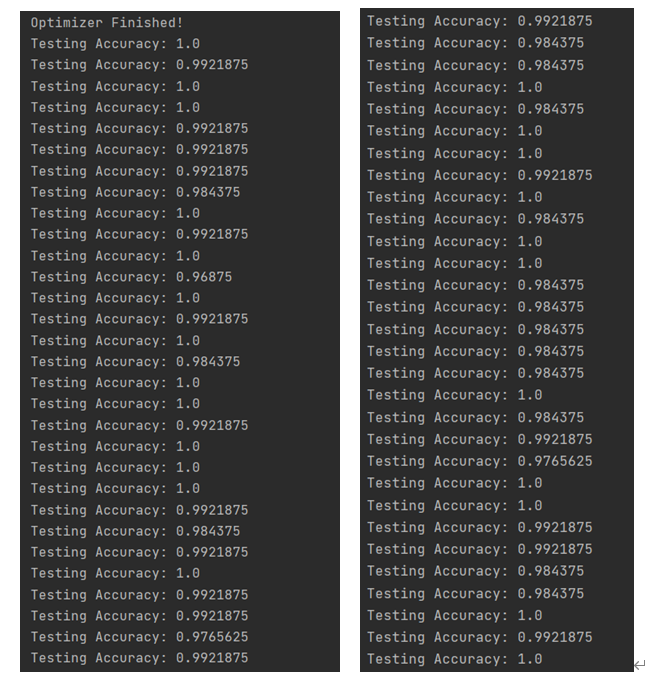
5. 运行结果截图
测试集测试结果,输出测试准确率,整体在96%以上:
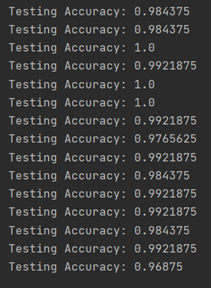
6. 核心代码和说明
(1) 定义的超参数
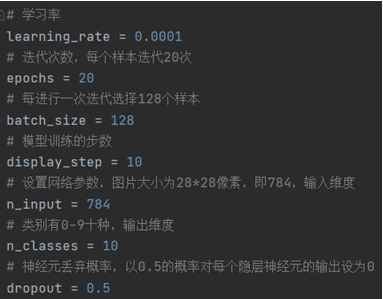
(2) 模型结构
input-输入数据:MNIST
数据集被分为两部分:60000行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test),每张图片是28 _28_1,输入数字是1 _784的数据,经过reshape后,维度格式为[28,28,1]
第1层卷积,卷积大小变化为28_28—>28 _28
池化大小变化为28_28—>14 _14
归一化大小变化为 14_14—>14 _14
第2层卷积,卷积大小变化为14_14—>14 _14
池化大小变化为14_14—>7 _7
归一化大小变化为 7_7—>7 _7
第3层卷积,卷积大小变化为 7_7—> 7 _7
第4层卷积,卷积大小变化为 7_7—> 7 _7
第5层卷积,卷积大小变化为 7_7—> 7 _7
池化大小变为 7_7—>4 _4
归一化大小为7_7—>7 _7
第1层全连接层 ‘wd1’: shape为4_4*256
dropout丢弃层
第2层全连接层
dropout丢弃层
output输出层
mnist = input_data.read_data_sets("mnist_sets", one_hot=True)
print("数据下载完成!")
learning_rate = 0.0001
epochs = 20
batch_size = 128
display_step = 10
n_input = 784
n_classes = 10
dropout = 0.5
x = tf.placeholder(tf.float32, [None, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
weights = {
'wc1': weight_var('wc1', [11, 11, 1, 96]),
'wc2': weight_var('wc2', [5, 5, 96, 256]),
'wc3': weight_var('wc3', [3, 3, 256, 384]),
'wc4': weight_var('wc4', [3, 3, 384, 384]),
'wc5': weight_var('wc5', [3, 3, 384, 256]),
'wd1': weight_var('wd1', [4 * 4 * 256, 4096]),
'wd2': weight_var('wd2', [4096, 4096]),
'out_w': weight_var('out_w', [4096, 10])
}
biases = {
'bc1': bias_var('bc1', [96]),
'bc2': bias_var('bc2', [256]),
'bc3': bias_var('bc3', [384]),
'bc4': bias_var('bc4', [384]),
'bc5': bias_var('bc5', [256]),
'bd1': bias_var('bd1', [4096]),
'bd2': bias_var('bd2', [4096]),
'out_b': bias_var('out_b', [n_classes])
}
def conv2d(name, x, W, b, strides=1, padding='SAME'):
x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding=padding)
x = tf.nn.bias_add(x, b)
return tf.nn.relu(x, name=name)
def maxpool2d(name, x, k=3, s=2, padding='SAME'):
return tf.nn.max_pool(x, ksize=[1, k, k, 1], strides=[1, s, s, 1], padding=padding, name=name)
def norm(name, l_input, lsize=5):
return tf.nn.lrn(l_input, lsize, bias=1.0, alpha=0.0001, beta=0.75, name=name)
def weight_var(name, shape):
return tf.get_variable(name=name, shape=shape, initializer=tf.contrib.layers.xavier_initializer())
def bias_var(name, shape):
return tf.get_variable(name=name, shape=shape, initializer=tf.constant_initializer(0))
def alexnet(x, weights, biases, dropout):
x = tf.reshape(x, shape=[-1, 28, 28, 1])
conv1 = conv2d('conv1', x, weights['wc1'], biases['bc1'], padding='SAME')
pool1 = maxpool2d('pool1', conv1, k=3, s=2, padding='SAME')
norm1 = norm('norm1', pool1, lsize=5)
conv2 = conv2d('conv2', norm1, weights['wc2'], biases['bc2'], padding='SAME')
pool2 = maxpool2d('pool2', conv2, k=3, s=2, padding='SAME')
norm2 = norm('norm2', pool2, lsize=5)
conv3 = conv2d('conv3', norm2, weights['wc3'], biases['bc3'], padding='SAME')
conv4 = conv2d('conv4', conv3, weights['wc4'], biases['bc4'], padding='SAME')
conv5 = conv2d('conv5', conv4, weights['wc5'], biases['bc5'], padding='SAME')
pool5 = maxpool2d('pool5', conv5, k=3, s=2, padding='SAME')
norm5 = norm('norm5', pool5, lsize=5)
fc1 = tf.reshape(norm5, [-1, weights['wd1'].get_shape().as_list()[0]])
fc1 = tf.add(tf.matmul(fc1, weights['wd1']), biases['bd1'])
fc1 = tf.nn.relu(fc1)
fc1 = tf.nn.dropout(fc1, dropout)
fc2 = tf.add(tf.matmul(fc1, weights['wd2']), biases['bd2'])
fc2 = tf.nn.relu(fc2)
fc2 = tf.nn.dropout(fc2, dropout)
out = tf.add(tf.matmul(fc2, weights['out_w']), biases['out_b'])
return out
pred = alexnet(x, weights, biases, dropout)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
step = 1
for epoch in range(epochs + 1):
for _ in range(mnist.train.num_examples // batch_size):
step += 1
batch_x, batch_y = mnist.train.next_batch(batch_size)
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y})
if step % display_step == 0:
loss, acc = sess.run([cost, accuracy], feed_dict={x: batch_x, y: batch_y})
print("Epoch " + str(epoch) + ", Minibatch Loss=" + \
"{:.6f}".format(loss) + ", Training Accuracy= " + \
"{:.5f}".format(acc))
print("Optimizer Finished!")
saver.save(sess, model + "/model.ckpt", global_step=epoch)
for _ in range(mnist.test.num_examples // batch_size):
batch_x, batch_y = mnist.test.next_batch(batch_size)
print("Testing Accuracy:", sess.run(accuracy, feed_dict={x: batch_x, y: batch_y}))
- 完整代码
import tensorflow as tf
import os
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("mnist_sets", one_hot=True)
print("数据下载完成!")
learning_rate = 0.0001
epochs = 20
batch_size = 128
display_step = 10
n_input = 784
n_classes = 10
dropout = 0.5
x = tf.placeholder(tf.float32, [None, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
def conv2d(name, x, W, b, strides=1, padding='SAME'):
x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding=padding)
x = tf.nn.bias_add(x, b)
return tf.nn.relu(x, name=name)
def maxpool2d(name, x, k=3, s=2, padding='SAME'):
return tf.nn.max_pool(x, ksize=[1, k, k, 1], strides=[1, s, s, 1], padding=padding, name=name)
def norm(name, l_input, lsize=5):
return tf.nn.lrn(l_input, lsize, bias=1.0, alpha=0.0001, beta=0.75, name=name)
def weight_var(name, shape):
return tf.get_variable(name=name, shape=shape, initializer=tf.contrib.layers.xavier_initializer())
def bias_var(name, shape):
return tf.get_variable(name=name, shape=shape, initializer=tf.constant_initializer(0))
weights = {
'wc1': weight_var('wc1', [11, 11, 1, 96]),
'wc2': weight_var('wc2', [5, 5, 96, 256]),
'wc3': weight_var('wc3', [3, 3, 256, 384]),
'wc4': weight_var('wc4', [3, 3, 384, 384]),
'wc5': weight_var('wc5', [3, 3, 384, 256]),
'wd1': weight_var('wd1', [4 * 4 * 256, 4096]),
'wd2': weight_var('wd2', [4096, 4096]),
'out_w': weight_var('out_w', [4096, 10])
}
biases = {
'bc1': bias_var('bc1', [96]),
'bc2': bias_var('bc2', [256]),
'bc3': bias_var('bc3', [384]),
'bc4': bias_var('bc4', [384]),
'bc5': bias_var('bc5', [256]),
'bd1': bias_var('bd1', [4096]),
'bd2': bias_var('bd2', [4096]),
'out_b': bias_var('out_b', [n_classes])
}
def alexnet(x, weights, biases, dropout):
x = tf.reshape(x, shape=[-1, 28, 28, 1])
conv1 = conv2d('conv1', x, weights['wc1'], biases['bc1'], padding='SAME')
pool1 = maxpool2d('pool1', conv1, k=3, s=2, padding='SAME')
norm1 = norm('norm1', pool1, lsize=5)
conv2 = conv2d('conv2', norm1, weights['wc2'], biases['bc2'], padding='SAME')
pool2 = maxpool2d('pool2', conv2, k=3, s=2, padding='SAME')
norm2 = norm('norm2', pool2, lsize=5)
conv3 = conv2d('conv3', norm2, weights['wc3'], biases['bc3'], padding='SAME')
conv4 = conv2d('conv4', conv3, weights['wc4'], biases['bc4'], padding='SAME')
conv5 = conv2d('conv5', conv4, weights['wc5'], biases['bc5'], padding='SAME')
pool5 = maxpool2d('pool5', conv5, k=3, s=2, padding='SAME')
norm5 = norm('norm5', pool5, lsize=5)
fc1 = tf.reshape(norm5, [-1, weights['wd1'].get_shape().as_list()[0]])
fc1 = tf.add(tf.matmul(fc1, weights['wd1']), biases['bd1'])
fc1 = tf.nn.relu(fc1)
fc1 = tf.nn.dropout(fc1, dropout)
fc2 = tf.add(tf.matmul(fc1, weights['wd2']), biases['bd2'])
fc2 = tf.nn.relu(fc2)
fc2 = tf.nn.dropout(fc2, dropout)
out = tf.add(tf.matmul(fc2, weights['out_w']), biases['out_b'])
return out
pred = alexnet(x, weights, biases, dropout)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
saver = tf.train.Saver()
model = "./model"
if not os.path.exists(model):
os.makedirs(model)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
step = 1
for epoch in range(epochs + 1):
for _ in range(mnist.train.num_examples // batch_size):
step += 1
batch_x, batch_y = mnist.train.next_batch(batch_size)
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y})
if step % display_step == 0:
loss, acc = sess.run([cost, accuracy], feed_dict={x: batch_x, y: batch_y})
print("Epoch " + str(epoch) + ", Minibatch Loss=" + \
"{:.6f}".format(loss) + ", Training Accuracy= " + \
"{:.5f}".format(acc))
print("Optimizer Finished!")
saver.save(sess, model + "/model.ckpt", global_step=epoch)
for _ in range(mnist.test.num_examples // batch_size):
batch_x, batch_y = mnist.test.next_batch(batch_size)
print("Testing Accuracy:", sess.run(accuracy, feed_dict={x: batch_x, y: batch_y}))
Original: https://blog.csdn.net/weixin_46443403/article/details/122916444
Author: tick-tick
Title: 手写数字识别:CNN-AlexNet
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/690299/
转载文章受原作者版权保护。转载请注明原作者出处!