

1.数据集
数据集地址:https://www.kaggle.com/slothkong/10-monkey-species
采用kaggle上的猴子数据集,包含两个文件:训练集和验证集。每个文件夹包含10个标记为n0-n9的猴子。图像尺寸为400×300像素或更大,并且为JPEG格式(近1400张图像)。

图片样本
图片类别标签,训练集,验证集划分说明
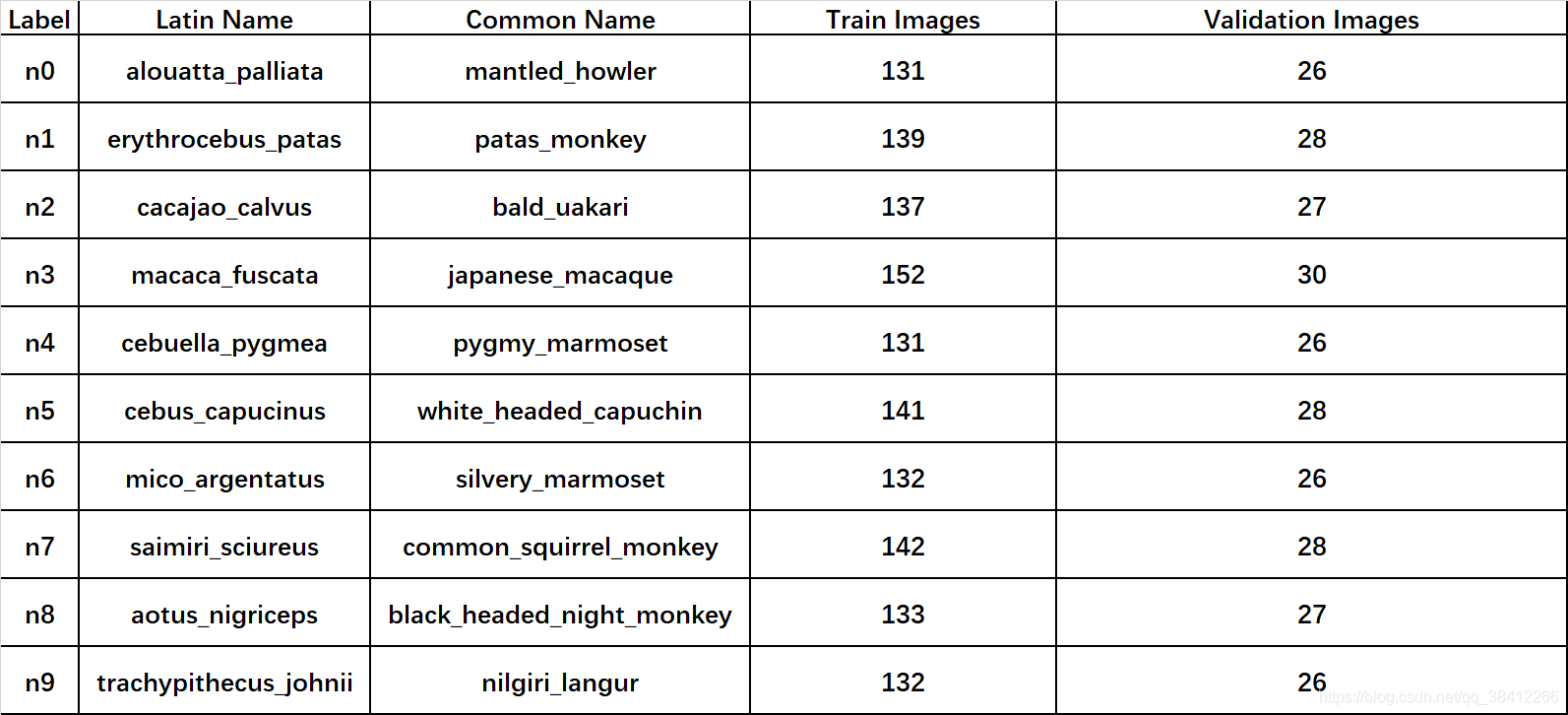
; 2.代码
2.1 定义需要的库
import os
import sys
import json
import time
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from tqdm import tqdm
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
2.2 定义训练验证函数
def train_and_val(epochs, model, train_loader, val_loader, criterion, optimizer):
torch.cuda.empty_cache()
train_loss = []
val_loss = []
train_acc = []
val_acc = []
best_acc = 0
model.to(device)
fit_time = time.time()
for e in range(epochs):
since = time.time()
running_loss = 0
training_acc = 0
with tqdm(total=len(train_loader)) as pbar:
for image, label in train_loader:
model.train()
optimizer.zero_grad()
image = image.to(device)
label = label.to(device)
output = model(image)
loss = criterion(output, label)
predict_t = torch.max(output, dim=1)[1]
loss.backward()
optimizer.step()
running_loss += loss.item()
training_acc += torch.eq(predict_t, label).sum().item()
pbar.update(1)
model.eval()
val_losses = 0
validation_acc = 0
with torch.no_grad():
with tqdm(total=len(val_loader)) as pb:
for image, label in val_loader:
image = image.to(device)
label = label.to(device)
output = model(image)
loss = criterion(output, label)
predict_v = torch.max(output, dim=1)[1]
val_losses += loss.item()
validation_acc += torch.eq(predict_v, label).sum().item()
pb.update(1)
train_loss.append(running_loss / len(train_dataset))
val_loss.append(val_losses / len(val_dataset))
train_acc.append(training_acc / len(train_dataset))
val_acc.append(validation_acc / len(val_dataset))
torch.save(model, "last.pth")
if best_acc<(validation_acc / len(val_dataset)):
torch.save(model, "best.pth")
print("Epoch:{}/{}..".format(e + 1, epochs),
"Train Acc: {:.3f}..".format(training_acc / len(train_dataset)),
"Val Acc: {:.3f}..".format(validation_acc / len(val_dataset)),
"Train Loss: {:.3f}..".format(running_loss / len(train_dataset)),
"Val Loss: {:.3f}..".format(val_losses / len(val_dataset)),
"Time: {:.2f}s".format((time.time() - since)))
history = {'train_loss': train_loss, 'val_loss': val_loss,'train_acc': train_acc, 'val_acc': val_acc}
print('Total time: {:.2f} m'.format((time.time() - fit_time) / 60))
return history
2.3定义ResNet网络
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(width)
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=10,
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet34(num_classes=10, include_top=True):
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet50(num_classes=10, include_top=True):
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=10, include_top=True):
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
def resnext50_32x4d(num_classes=10, include_top=True):
groups = 32
width_per_group = 4
return ResNet(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def resnext101_32x8d(num_classes=10, include_top=True):
groups = 32
width_per_group = 8
return ResNet(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
2.4 设置训练集和验证集
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
BATCH_SIZE = 16
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
train_dataset = datasets.ImageFolder("../input/10-monkey-species/training/training/", transform=data_transform["train"])
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True,
num_workers=2)
val_dataset = datasets.ImageFolder("../input/10-monkey-species/validation/validation/", transform=data_transform["val"])
val_loader = torch.utils.data.DataLoader(dataset=val_dataset, batch_size=BATCH_SIZE, shuffle=False,
num_workers=2)
2.5 开始训练
net = resnet34()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
epoch = 60
history = train_and_val(epoch, net, train_loader, val_loader, loss_function, optimizer)
执行结果
Epoch:55/60.. Train Acc: 0.813.. Val Acc: 0.860.. Train Loss: 0.038.. Val Loss: 0.029.. Time: 38.40s
100%|██████████| 69/69 [00:28<00:00, 2.38it/s]
100%|██████████| 17/17 [00:09<00:00, 1.81it/s]
Epoch:56/60.. Train Acc: 0.830.. Val Acc: 0.882.. Train Loss: 0.031.. Val Loss: 0.025.. Time: 38.84s
100%|██████████| 69/69 [00:27<00:00, 2.48it/s]
100%|██████████| 17/17 [00:09<00:00, 1.78it/s]
Epoch:57/60.. Train Acc: 0.843.. Val Acc: 0.871.. Train Loss: 0.031.. Val Loss: 0.025.. Time: 37.80s
100%|██████████| 69/69 [00:28<00:00, 2.39it/s]
100%|██████████| 17/17 [00:09<00:00, 1.86it/s]
Epoch:58/60.. Train Acc: 0.829.. Val Acc: 0.827.. Train Loss: 0.030.. Val Loss: 0.035.. Time: 38.49s
100%|██████████| 69/69 [00:28<00:00, 2.39it/s]
100%|██████████| 17/17 [00:09<00:00, 1.86it/s]
Epoch:59/60.. Train Acc: 0.852.. Val Acc: 0.853.. Train Loss: 0.029.. Val Loss: 0.031.. Time: 38.42s
100%|██████████| 69/69 [00:28<00:00, 2.39it/s]
100%|██████████| 17/17 [00:08<00:00, 1.90it/s]
Epoch:60/60.. Train Acc: 0.826.. Val Acc: 0.831.. Train Loss: 0.032.. Val Loss: 0.035.. Time: 38.25s
Total time: 38.95 m
2.6 打印准确率以及loss曲线
def plot_loss(x, history):
plt.plot(x, history['val_loss'], label='val', marker='o')
plt.plot(x, history['train_loss'], label='train', marker='o')
plt.title('Loss per epoch')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(), plt.grid()
plt.show()
def plot_acc(x, history):
plt.plot(x, history['train_acc'], label='train_acc', marker='x')
plt.plot(x, history['val_acc'], label='val_acc', marker='x')
plt.title('Score per epoch')
plt.ylabel('score')
plt.xlabel('epoch')
plt.legend(), plt.grid()
plt.show()
plot_loss(np.arange(0,epoch), history)
plot_acc(np.arange(0,epoch), history)
执行结果
loss曲线

准确率曲线

; 2.7 查看每一类的准确率
classes = ('n0', 'n1', 'n2', 'n3', 'n4', 'n5', 'n6', 'n7', 'n8', 'n9')
class_correct = [0.] * 10
class_total = [0.] * 10
y_test, y_pred = [] , []
X_test = []
with torch.no_grad():
for images, labels in val_loader:
X_test.extend([_ for _ in images])
outputs = model(images.to(device))
_, predicted = torch.max(outputs, 1)
predicted = predicted.cpu()
c = (predicted == labels).squeeze()
for i, label in enumerate(labels):
class_correct[label] += c[i].item()
class_total[label] += 1
y_pred.extend(predicted.numpy())
y_test.extend(labels.cpu().numpy())
for i in range(10):
print(f"Acuracy of {classes[i]:5s}: {100*class_correct[i]/class_total[i]:2.0f}%")
执行结果
Acuracy of n0 : 77%
Acuracy of n1 : 86%
Acuracy of n2 : 85%
Acuracy of n3 : 87%
Acuracy of n4 : 85%
Acuracy of n5 : 89%
Acuracy of n6 : 73%
Acuracy of n7 : 75%
Acuracy of n8 : 89%
Acuracy of n9 : 85%
2.8 查看precision,recall和f1-score
from sklearn.metrics import confusion_matrix, classification_report
ac = accuracy_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)
cr = classification_report(y_test, y_pred, target_names=classes)
print("Accuracy is :",ac)
print(cr)
执行结果
Accuracy is : 0.8308823529411765
precision recall f1-score support
n0 0.77 0.77 0.77 26
n1 0.69 0.86 0.76 28
n2 1.00 0.85 0.92 27
n3 0.93 0.87 0.90 30
n4 0.88 0.85 0.86 26
n5 0.81 0.89 0.85 28
n6 0.90 0.73 0.81 26
n7 0.84 0.75 0.79 28
n8 0.89 0.89 0.89 27
n9 0.71 0.85 0.77 26
accuracy 0.83 272
macro avg 0.84 0.83 0.83 272
weighted avg 0.84 0.83 0.83 272
2.9 查看混淆矩阵
import seaborn as sns, pandas as pd
labels = pd.DataFrame(cm).applymap(lambda v: f"{v}" if v!=0 else f"")
plt.figure(figsize=(7,5))
sns.heatmap(cm, annot=labels, fmt='s', xticklabels=classes, yticklabels=classes, linewidths=0.1 )
plt.show()
执行结果

; 3.模型部署在Android
3.1 导出onnx模型
INPUT_DICT = './weight/best.pth'
OUT_ONNX = './weight/best.onnx'
x = torch.randn(1, 3, 224, 224)
input_names = ["input"]
out_names = ["output"]
model= torch.load(INPUT_DICT, map_location=torch.device('cpu'))
model.eval()
torch.onnx._export(model, x, OUT_ONNX, export_params=True, training=False, input_names=input_names, output_names=out_names)
print('please run: python -m onnxsim test.onnx test_sim.onnx\n')
3.2 将onnx模型简化
python -m onnxsim best.onnx best_sim.onnx

3.3 使用ncnn进行转化
3.3.1 首先转化为.param和.bin文件
onnx2ncnn.exe best_sim.onnx res.param res.bin

3.3.2 将.param和.bin文件加密
ncnn2mem.exe res.param res.bin res.id.h res.mem.h

3.4 最终效果

测试的时候发现,将图片稍微裁剪一下,猴子区域占整幅图像的比例大一点效果较好。
; 代码已开源
1.完整训练代码:https://github.com/yaoyi30/ResNet_Image_Classification_PyTorch
2.安卓代码:https://github.com/yaoyi30/ResNet_ncnn_android
Original: https://blog.csdn.net/qq_38412266/article/details/112868835
Author: 姚先生97
Title: PyTorch ResNet实现图像分类(从模型的训练到Android部署)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/690172/
转载文章受原作者版权保护。转载请注明原作者出处!