

行为识别C3D代码(pytorch)实现过程及常见错误
1.C3D网络代码
C3D(pytorch)实现代码链接:
2.C3D代码复现过程
(1)环境版本要求
pytorch:3.5及以上
opencv:3.4.2(我是这样的,其他低点的版本应该也可以)
tensorboard:2.4
scikit-learn:0.23.2
(2)数据集的制作


建议:如果代码中mypath路径不想更改的话,新建一个文件夹(/path/to/),存放UCF-101知道的路径是/path/to/UCF-101。
(很重要)注意:所有的路径尤其是mypath.py的路径不能有中文,中文会导致cv.imread出错,无法将图片存储到文件夹中。
现在网上下载UCF-101数据集超级慢,如果大家需要可以 加关注,留qq邮箱,给你发UCF-101压缩包。
目前UCF-101数据集不能发送原因:
(1)因为该数据集在某盘属于敏感文件不能发送;
(2)QQ邮箱中只能发送最大3g文件,而UCF-101是6g文件。
解决方法(获取UCF-101的两种方法):
- 需要我本人自己将其压缩分卷成10个700mb压缩包,大家下载十个压缩包后必须要把这10个压缩包放在一个文件夹内,解压任意一个文件即可全部解压。最后就成为一个完整的 UCF-101数据集。 下载这10个UCF-101压缩包的地址:UCF-101的十个压缩包
- 需要我本人自己将其压缩分卷成10个700mb压缩包,然后一个一个的以邮箱的形式发送给大家,大家下载十个压缩包后必须要把这10个压缩包放在一个文件夹内,解压任意一个文件即可全部解压。最后就成为一个完整的 UCF-101数据集。
最后谢谢大家的关注!!!
(3)下载预训练model
预训练model下载地址:
预训练model
接下来在之前所创建好的文件下(/path/to)下再创建一个Models文件夹存放预训练模型,最终的预训练模型是/path/to/Models/ucf101-caffe.pth
(4)处理UCF-101数据集
处理UCF-101数据集就是将视频按一定的帧次分割成一张一张图片。该代码所在处是dataset.py。
首先对mypath.py进行修改因为之前创建了文件夹,所以root-dir和model_dir的路径不用更改。只需要在/path/to/文件夹下创建一个VAR文件夹,再VAR文件夹中创建UCF-101,最终的路径是/path/to/VAR/ucf101。这个路径就是out_dir的路径,所以mypath里面的路径不需要更改了。
对dataset.py代码更改如下图:



这些改完之后,运行database.py,处理时间比较长,可以先做点其他的事情。最后分割图片后的结果如图:

(5)对inference.py和train.py文件改动
接下来就是在预训练之前所做的代码改动问题了,按我写的代码改动即可。
先对inference.py更改
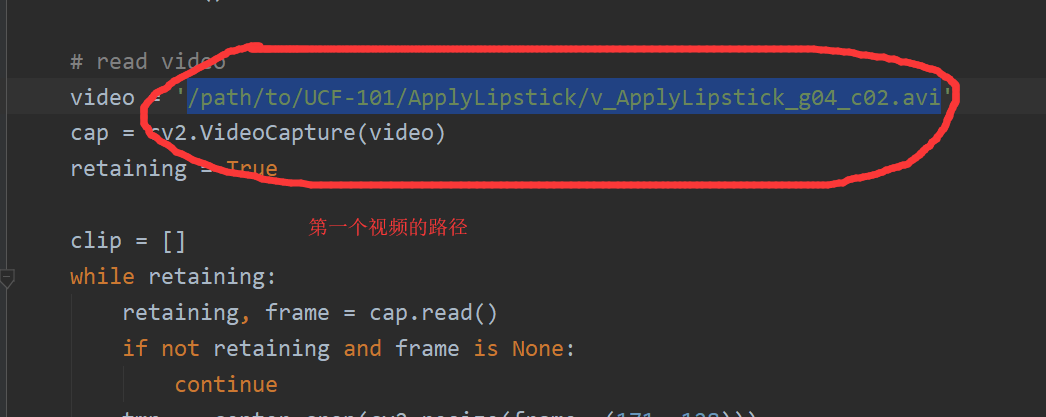
对train.py的更改
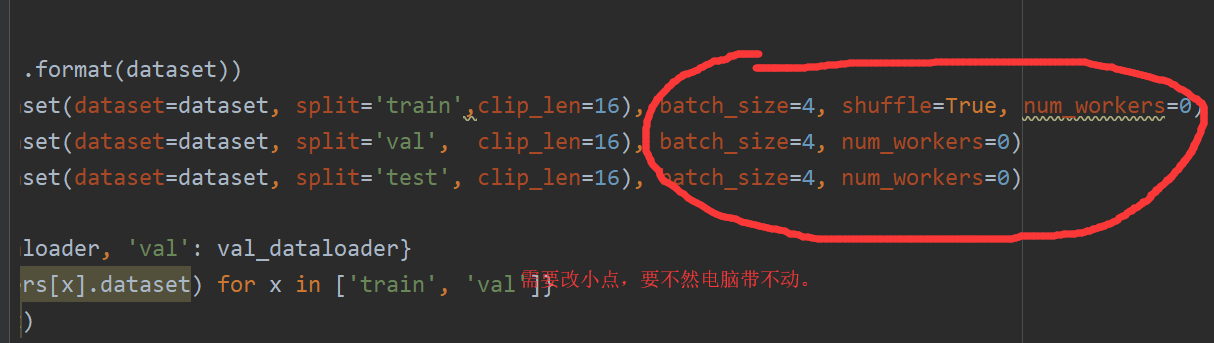
已更改完成
(6)运行程序
在命令行:train.py即可,视频处理完之后,将process的True改为False,以后直接训练即可,不需要再次对视频处理为图片。
最后运行程序如下图

C3D的复现完成,谢谢大家留言评论
; 常见错误
1.os.listdir(os.path.join(self.output_dir, ‘train’, video_class, video)))[0])
IndexError: list index out of range。
问题原因:表示没有将视频分割的图片存储到文件夹中。
解决方法:mypath的路径都是英文的,不能出现中文,否则cv,write的时候图片写不进文件夹中去。
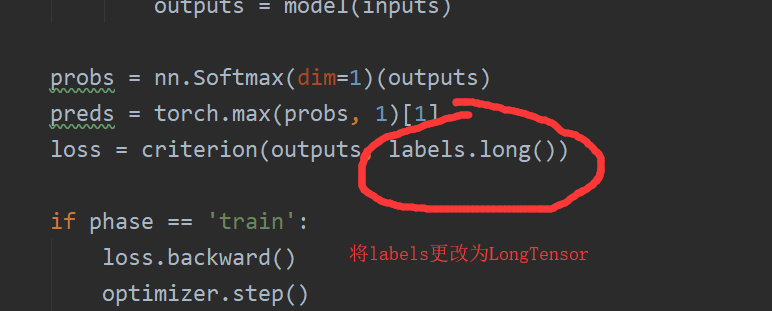
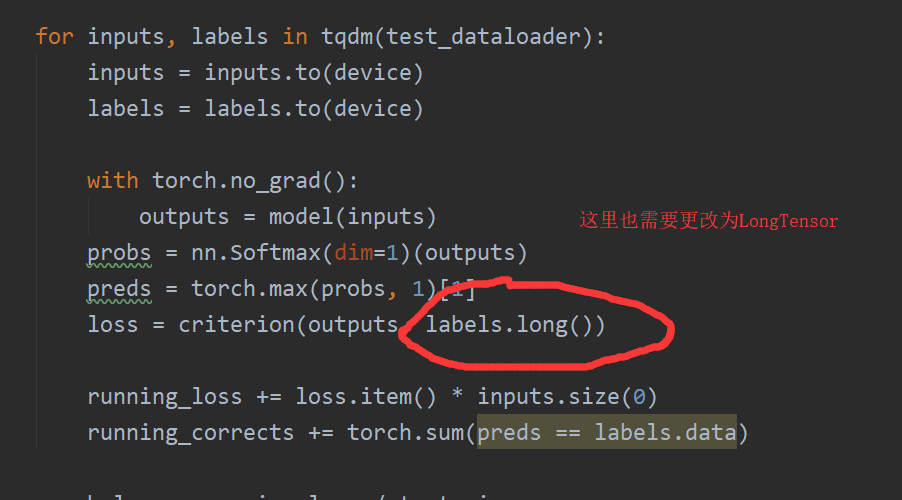
2.LongTensor的问题
问题原因:标签的类型应该是LongTensor,而不是Tensor,故需要更改、
解决方法:看以上的train.py的更改图片。
3.GPU内存不够,处理数据太大问题
问题原因:batch_size太大
解决方法:按照以上train.py中第一张图片的batch_size更改。
谢谢大家,有什么问题留言即可。一起加油!!!
Original: https://blog.csdn.net/yuanhaopeng123/article/details/113459528
Author: 深度学习强化学习爱好者
Title: 行为识别C3D代码(pytorch)实现过程及常见错误
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/688861/
转载文章受原作者版权保护。转载请注明原作者出处!