

从 pytorch到nlp
第一章 pytorch 之构建神经网络
文章目录
前言
作为人工智能的一项重要分支,自然语言处理在各个领域得到了广泛应用,pytorch是学习自然语言处理的一个深度学习框架之一,本文记录一下小杜的学习笔记
一、构建神经网络的具体流程
1 定义一个拥有可学习参数的神经网络
2 遍历训练数据集
3 处理数据使其流经神经网络
4计算损失
5将网络参数的梯度进行反向传播
6依一定的规则更新网络权重
二、代码及其解读
1.模型构建
代码是在jupyter notebook 上运行
图解
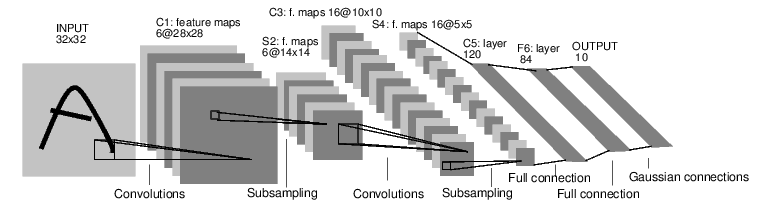

代码如下(示例):
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
#定义Net的初始化函数,这个函数定义了该神经网络的基本结构
def __init__(self):
super(Net,self).__init__()#对继承自父类的属性进行初始化 复制并使用Net的父类的初始化方法,即先运行nn.Module的初始化函数
self.conv1=nn.Conv2d(1,6,3)#输入1 输出6 卷积核是3*3 表示提取6个特征,得到6个feature map
self.conv2=nn.Conv2d(6,16,3)#输入6输出16
#全连接层定义了三层线性转换,16*6*6就是把这16个二维数组拍扁了后一维向量的size
self.fc1=nn.Linear(16*6*6,120)
self.fc2=nn.Linear(120,84)
self.fc3=nn.Linear(84,10)
#Linear有三个参数,分别是输入特征数,输出特征数以及是否使用偏置(默认为True)。
#默认情况下Linear会自动生成权重参数和偏置,所以在模型中不需要单独定义权重参数,
#并且Linear提供比原先自定义权重参数时使用的randn随机正太分布更好的参数初始化方法
def forward(self,x):
x=F.max_pool2d(F.relu(self.conv1(x)),(2,2))#将x放入卷积层中 用激活函数relu激活 在2*2池化窗口进行最大池化
x=F.max_pool2d(F.relu(self.conv2(x)),2)#经历第二个卷积层
x=x.view(-1,self.num_flat_features(x))#通过这个view()函数我们把二维数据变成了一维向量。 Convolution Layer和Fully Connected Layer的对接
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self,x)##使用num_flat_features函数计算张量x的总特征量
size=x.size[1:]
num_features=1
for s in size:
num_features*=s #累乘
return num_features
net=Net()
net
运行结果

这里显示了实例化类 打印出来网络结构
这里我们的神经网络有五层 两个卷积层 三个全连接层
2.查看模型参数
params = list(net.parameters())
print(len(params))
params[0].size()
params
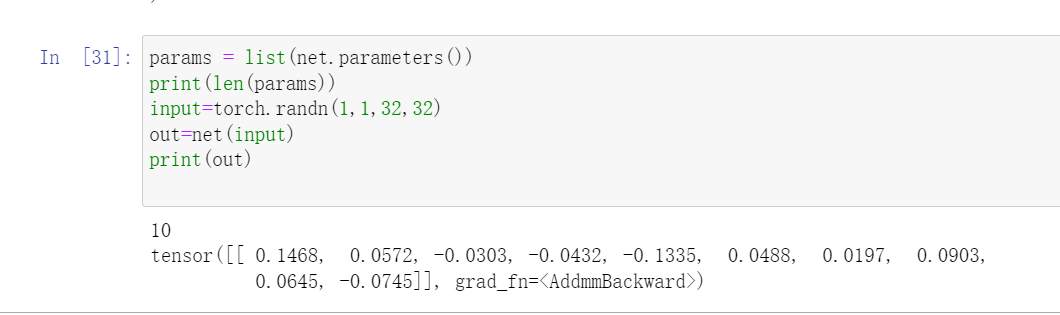
假设输入图像维度是32 _32 输出参数是十个参数 大小1_10
然后就可以
3.损失函数
损失函数可以通过 输入(input,target)和标签的差值进行计算
torch.nn 中有很多损失函数 比如 nn.MSEloss 计算均方误差损失评估模型
代码如下(示例):
output = net(input)
target = torch.randn(10)
target = target.view(1, -1)
criterion = nn.MSELoss()
loss = criterion(output, target)
print(loss)

计算流程图 input ->conv2d->relu-> maxpool2d ->conv2d->relu->relumaxpool2d->view->linear->relu->linear->relu->linear->MSEloss->loss
反向传播 从有右向左
调用loss.backward()时,在整个计算图都会多loss进行微分,所有requires_grad=True的tensor张量的.都会累加到grad属性中。
不断追溯
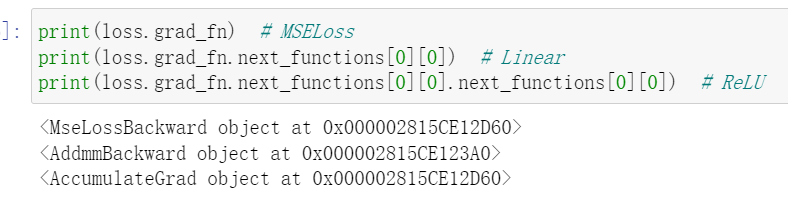
4.反向传播
有了输出张量 就可以 进行 梯度归零(net.zero_grad()将其所有参数(包括子模块的参数)的梯度设置为零调用backward()函数之前都要将梯度清零,因为如果梯度不清零,pytorch中会将上次计算的梯度和本次计算的梯度累加。)
和 反向传播 net.zero_grad() out.backward(torch.randn(1,10))
调用 loss.backward() ,观察conv1 层bias的梯度反向传播前后的变化
net.zero_grad()
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)

5.更新网络参数
随即梯度下降SGD
weight = weight – learning_rate * gradient
import torch.optim as optim
optimizer = optim.SGD(net.parameters(), lr=0.01)
optimizer.zero_grad()
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step()
总结
以上就是今天要讲的内容
我们学习了构建一个神经网络的典型流程
1.学习了损失函数的定义
采用torch.nn.MSEloss均方误差
通过loss.backward()进行反向传播时整张计算图将对loss进行自动求导所有属性require_grad=Ture 的Tensor将被参与到梯度求导运算中梯度累加到tensor属性。grad中
2. 学习了反向传播的计算方法
loss.backward()
进行 梯度归零(net.zero_grad()将其所有参数(包括子模块的参数)的梯 度设置为零调用backward()函数之前都要将梯度清零,因为如果梯度不清零,pytorch中会将上次计算的梯度和本次计算的梯度累加。
net.zero_grad()
out.backward()
3. 学习了参数的更新方法
定义优化器来执行参数的优化更行
optimizer = optim.SGD(net.parameters(), lr=0.01)
4.通过优化器来执行具体的参数更新
optimizer.step() # 真正的执行
Original: https://blog.csdn.net/qq_53536373/article/details/123707927
Author: 小杜今天学AI了吗
Title: pytorch入门——构建神经网络
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/688271/
转载文章受原作者版权保护。转载请注明原作者出处!