

如何从零开始将神经网络移植到FPGA(ZYNQ7020)加速推理
前言
本片文章用于对零基础的小白使用,仅供参考,大神绕道。AI一直都是做算法的热点,作为多少研究生都想蹭一蹭热度,本文就神经网络的移植到FPGA做一个简单的教程。使用FPGA做前向的推理而不是训练,训练还是在PC机上完成的,通过训练得到的权重文件然后再去移植到FPGA。
1.神经网络
深度神经网络应该是最简单的一种网络结构了,相比CNN没有卷积相关的参数,仅仅只有几层网络结构,深度神经网络就不多说了,DNN,之所以不多说的原因就是这个东西应该很容易理解,毕竟不是很难的算法,现在前沿的算法估计都没人去研究DNN相关的了。不懂的可以上网去搜索相关的原理包括、前向传播、反向传播、梯度下降等等。既然要移植神经网络,总要有一个神经网络了吧。既然是入门那就用入门的鼻祖–手写字了,首先需要弄一个手写字的神经网络。
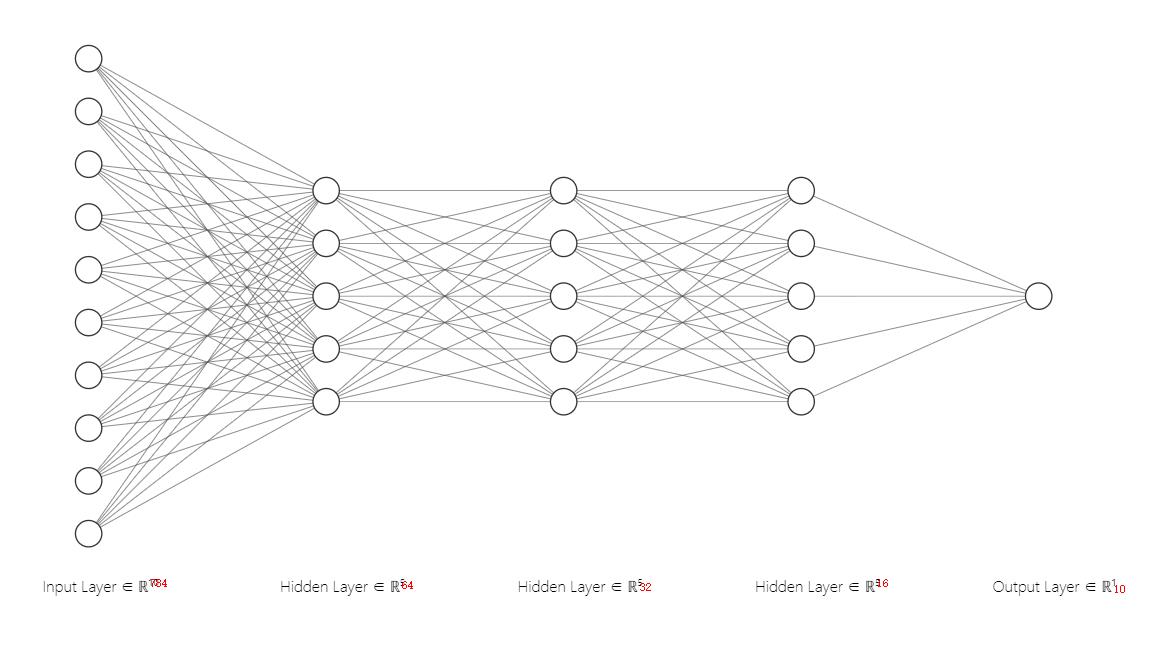

很简单的三层
; 1.1如何规划神经网络的结构
1.神经网络的结构可以自己去规划,没必要和本文的一模一样,也可以使用主流的框架去做,比如tensorflow等,本文使用了三层隐藏层网络,输入层为784,隐藏层1为64,2为32,3为16.。三层网络可做到识别率95%以上。
2.其实网络刚一开始用的隐藏层为256、128、32,这样的识别精度更高,能达到98%,但是后面去移植到FPGA中发现权重参数太多了,FPGA的Bram资源远远不够用,所以对网络的结构进行删减。把网络结构调整的简单了一下,再FPGA中能够实现了,精度也不至于削减 的这么多,足够了。
3.激活函数用的sigmod函数,这个也不用多说,了解过的应该都知道是臭了大街 的了。一个神经网络从输入输出都要自己设定好。本文的输入28 _28,输出10_1.对应每一层的权重数量为[64][784] 、[64][64]、[10][32]、偏置项[64]、[32]、[10]。
4.保存到数据类型采用的是float类型数据,每个权重按照4字节存储。
1.2mnist数据集
这部分数据集没什么好说的,使用官网的文件解析出来把数据读取,然后使用数据集去训练。只不过注意的是,在使用过程中,将数据集中的参数提取了出来保存为.dat格式的文件,便于使用FPGA预测单张图片。另外就是每张图片的参数原始参数是0-255,最后都归一化到了0-1之间。
1.3 有关权重文件的保存
本文中的权重文件分开保存,对每一层的weight、bias等文件分别保存成独立的文件,weightx.dat与biasx.dat,之所以这样保存的原因是使用HLS语言开发时,可以使用#include参数读取权重文件等。当然,对在PC上完成的训练与测试,输出保存的权重文件只有保存了1个文件。这个可以在源代码中查看,本文全部开源。相关代码可以从本文链接下载也以从github下载。
2.FPGA实现
FPGA实现是一个重要的地方,本出不主要是去探究实现神经网络的各种方法。个人觉得,FPGA去实现神经网络最关键的地方就是设定好一种架构,包括数据的传输、临时存储、结果读取。比如,我PS做控制,调取PL资源做网络推理,那么PS与PL之间的交互九世纪最重要的,可以通过AXI协议、可以通过BRAM等等,这样就要考虑板子的资源够不够用,一个好的架构不同的方式必然会带来不一样的效果。本文中实现使用HLS完成的加速IP核设计,实现ARM+HLS调用的硬件结构。
2.1HLS加速IP核设计
HLS直白了就是直接使用高级语言描述硬件电路,不得不说这种方式开发真的是省时间效率,但是综合出来的电路质量是差一些,后期优化一下可能会更好,一下代码没有经过优化,使用流水线优化下FOR循环效果会更好,废话不多说直接上代码:
#include <math.h>
#include "hls_mnist.h"
void Sigmoid( float *a,int size)
{
for(int i = 0; i < size; i++)
a[i] = 1/(1 + expf(-a[i]));
}
void mnist_nn_predict( float input[784],float output[10])
{
#pragma HLS INTERFACE s_axilite port=return bundle=CRTL_BUS
#pragma HLS INTERFACE bram port=input
#pragma HLS INTERFACE bram port=output
int max_idx = 0;
const float weight1[64][784] = {
#include "weight1.dat"
};
const float weight2[32][64] = {
#include "weight2.dat"
};
const float weight3[10][32] = {
#include "weight3.dat"
};
const float bias1[64] = {
#include "bias1.dat"
};
const float bias2[32] = {
#include "bias2.dat"
};
const float bias3[10] = {
#include "bias3.dat"
};
int k ,j,i;
float output1[64];
float output2[32];
float output3[10];
float z1 = 0.0;
float z2 = 0.0;
float z3 = 0.0;
for( k = 0; k < 64; k++)
{
z1 = 0.0;
for( j = 0; j < 784; j++)
z1 += weight1[k][j] * input[j];
z1 += bias1[k];
output1[k] = z1;
}
Sigmoid(output1,64);
for( k = 0; k < 32; k++)
{
z2= 0.0;
for( j = 0; j < 64; j++)
z2 += weight2[k][j] * output1[j];
z2 += bias2[k];
output2[k] = z2;
}
Sigmoid(output2,32);
for( k = 0; k < 10; k++)
{
z3 = 0.0;
for( j = 0; j < 32; j++)
z3 += weight3[k][j] * output2[j];
z3 += bias3[k];
output3[k] = z3;
}
Sigmoid(output3,10);
for( k = 0; k < 10; k++)
output[k] = output3[k];
for( i = 0; i < 10; i++) {
if(output[i] > output[max_idx]) {
max_idx = i;
}
}
}
1.简简单单的三层网络,最后输出结果为10个分类结果0-9,当然稍加修改可以直接获取单个识别的结果。
2.开头的前三行是把HLS入参综合成BRAM接口,之所以设计成BRAM的接口是因为调用IP核时,可以直接访问BRAM的地址获取数据,当然也可以综合成AXI_slave类型的接口,具体大家可以去试一下,至于返回值综合成了AXI的接口。
3.对于for循环部分大家可以使用 directive相关参数优化加入流水线去改变延时,源码中的没有经过优化,延时非常大,加入了流水线优化是非常明显的,这个可以自行去试一下。
4.#include用法可以直接将文件的参数加载到数组中,这个对于HLS编译来说是可以执行的,这种用法大家可以百度下GCC-E相关 的解释,预处理文件。
3.ARM调用IP核
3.1硬件设计
如图
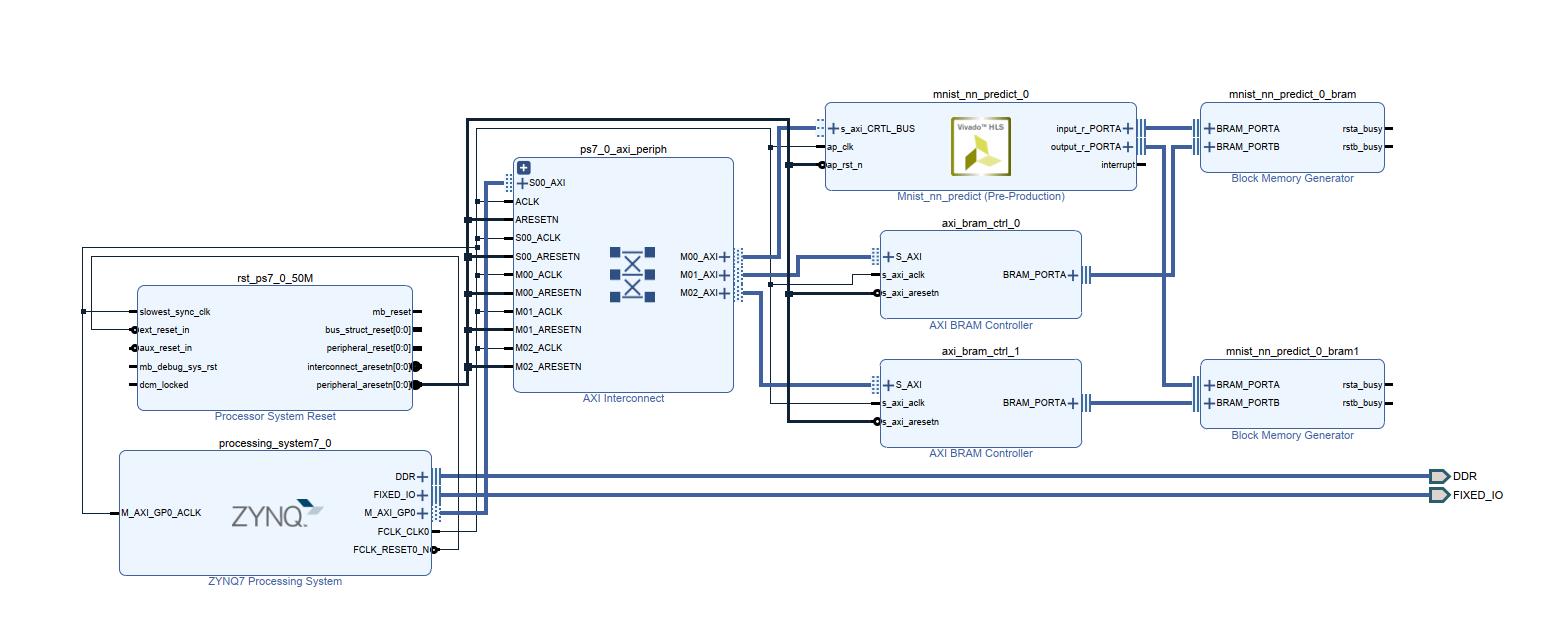
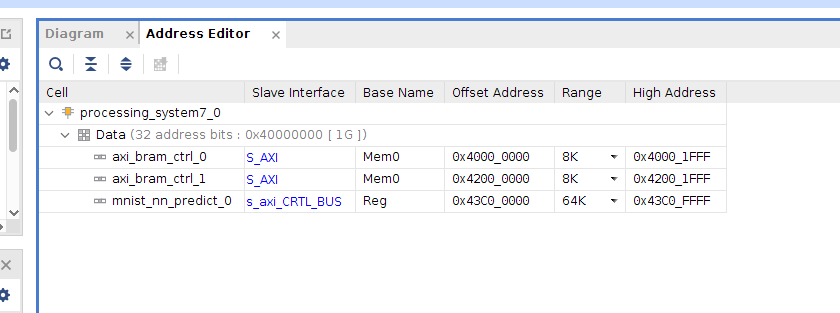
1.首先添加ps处理器硬件,使能串口(用于调试输出)、SD卡引脚(用于从读取手写字数据文件)、axi GP master 等
2.添加HLS的手写字识别 IP核
3.添加BRAM1,双端口,添加BRAM控制器1,两个端口分别连接HLS的IP的INPUT端接口、和BRAM控制器1,BRAM控制器1链接PS处理器,该处Bram1用于存放输入数据,该处的数据是PS端从SD卡读取手写字数据文件后写入,然后HLS IP核从该处读取手写字数据识别计算。。根据实际存放的数据可以计算出该BRAM1的大小,根据计算出来的大小再分配BRAM的。地址深度等。此处的地址深度大于等于手写字图片的数据量。
4添加BRAM2,双端口,添加BRAM控制器2,一个端口链接HLS IP核的输出端OUTPUT,用于存放IP核识别结果。共计10个数;一个端口通过BRAM控制器2连接到PS端,用于PS端读取输出结果串口打印输出。以上便完成了整体的硬件设计。
; 3.1SDK裸机调用IP核
设计完硬件电路,便开始使用SDK写应用函数。对于PL资源来说,算是PS的一个外设,再使用的时候也是,把PL当成PS的其中一个外设,通过寄存器地址读取就可以了。
由于需要使用SD卡存取手写字,所以需要使用fatfs文件系统,在创建SDK应用的时候,需要将文件系统添加到BSP中。
#include "xparameters.h"
#include "xil_printf.h"
#include "ff.h"
#include "xdevcfg.h"
#include <stdio.h>
#include <stdlib.h>
#include "platform.h"
#include "xil_printf.h"
#include "xil_io.h"
#include "xmnist_nn_predict.h"
#define FILE_NAME "1.dat"
const char src_str[30] = "www.openedv.com";
static FATFS fatfs;
u32 float_to_u32(float value)
{
u32 result;
union float_byte
{
float v;
u8 byte[4];
}data;
data.v =value ;
result = (data.byte[3]<<24)+(data.byte[2]<<16)+(data.byte[1]<<8)+(data.byte[0]<<0);
return result;
}
float u32_to_float(u32 value)
{
return *((float*)&value);
}
int platform_init_fs()
{
FRESULT status;
TCHAR *Path = "0:/";
BYTE work[FF_MAX_SS];
status = f_mount(&fatfs, Path, 0);
if (status != FR_OK) {
xil_printf("Volume is not FAT formated; formating FAT\r\n");
}
return 0;
}
int sd_mount()
{
FRESULT status;
status = platform_init_fs();
if(status){
xil_printf("ERROR: f_mount returned %d!\n",status);
return XST_FAILURE;
}
return XST_SUCCESS;
}
int sd_write_data(char *file_name,u32 src_addr,u32 byte_len)
{
FIL fil;
UINT bw;
f_open(&fil,file_name,FA_CREATE_ALWAYS | FA_WRITE);
f_lseek(&fil, 0);
f_write(&fil,(void*) src_addr,byte_len,&bw);
f_close(&fil);
return 0;
}
int sd_read_data(char *file_name,u32 src_addr,u32 byte_len)
{
FIL fil;
UINT br;
f_open(&fil,file_name,FA_READ);
f_lseek(&fil,0);
f_read(&fil,(void*)src_addr,byte_len,&br);
f_close(&fil);
return br;
}
int main()
{
FIL fil;
int flielen,br;
char dest_str[5000] = "";
char dest_str0[5000] = "";
char dest_str1[784][10] = {{0}};
float f_buff;
char buff[10] = {0};
float data[784] = {0};
char *p;
u32 result, revs;;
int status,len,i,k;
int n = 0;
Xil_DCacheDisable();
printf("sd_mount start\n");
status = sd_mount();
if(status != XST_SUCCESS)
{
printf("sd_mount failed\n");
return 0;
}
f_open(&fil,FILE_NAME,FA_READ);
f_lseek(&fil,0);
f_read(&fil,(void*)dest_str,5000,&br);
p = strtok(dest_str,",\n\r");
memcpy(dest_str1[0],p,strlen(p));
i =1;
while( p != NULL )
{
p = strtok(NULL, ",\n\r");
memcpy(dest_str1[i++],p,strlen(p));
}
for(i=0;i<784;i++)
{
data[i] = atof(dest_str1[i]);
}
printf("data show:\n");
for( k=0;k<28;k++)
{
for( i=0;i<28;i++)
{
printf("%.0f",data[n++]);
}
printf("\n");
}
for(i=0;i<784;i++)
{
result = float_to_u32(data[i]);
Xil_Out32(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR+i*4,result);
}
XMnist_nn_predict HlsXMem_test;
XMnist_nn_predict_Config *ExamplePtr;
printf("Look Up the device configuration.\n");
ExamplePtr = XMnist_nn_predict_LookupConfig(XPAR_MNIST_NN_PREDICT_0_DEVICE_ID);
if (!ExamplePtr)
{
printf("ERROR: Lookup of accelerator configuration failed.\n\r");
return XST_FAILURE;
}
printf("Initialize the Device\n");
status = XMnist_nn_predict_CfgInitialize(&HlsXMem_test, ExamplePtr);
if (status != XST_SUCCESS)
{
printf("ERROR: Could not initialize accelerator.\n\r");
return(-1);
}
XMnist_nn_predict_Start(&HlsXMem_test);
while (XMnist_nn_predict_IsDone(&HlsXMem_test) == 0);
for(i=0;i<10;i++)
{
revs=Xil_In32(XPAR_AXI_BRAM_CTRL_1_S_AXI_BASEADDR+4*i);
float recvf = u32_to_float(revs);
printf("recongnize result:%f\n",recvf);
}
printf("all vision over\n");
cleanup_platform();
return 0;
}
整个代码流程如上,需要
1.初始化平台参数,
2.初始化挂载SD卡,前提是SD卡已经格式化为fat32文件格式,如果 SD没有被格式,可以使用fatfs的f_mkfs函数格式化SD卡
3.初始化查找表,调用HLS驱动函数。HLS生成RTL IP核文件后会自动生成驱动函数,生成的驱动函数以及相关的调用方式都是固定的,基本上就是初始化相关结构体,然后调用函数,获取结果,相关的驱动函数可以去SDK头文件中查找。
4.调用驱动函数获取结果
注意点:xlinx驱动函数传递的数据一般都使用u32数据类型,也就是unsigned int ,在使用SDK相关参数传递的时候对于浮点型数据float要转成unsigned int 进行传输,具体原理大家可以看ieee 754标准。
结果图

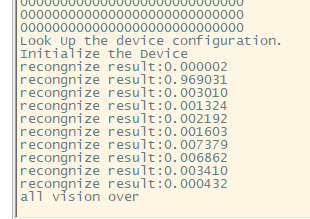
查看串口输出可以看到,第一个输出是图片归一化后的数据,第二章图是输出结果的10个分类展示0-9的probability,识别结果为1
以上便是将神经网络移植到FPGA中的全部过程,以上可能还有部分细节没有表述到,也有可能出现纰漏,还请指正,源码将会开源,有想要工程文件的可以去github下载,
后续工作一将
该IP核移植到linux下,使用linux驱动,毕竟现在嵌入式开发主流还是Linux,
使用纯verilog来实现该IP,HLS开发周期很短,但是优化上远不止纯硬件描述语言。
github: link.
—-from SDU CNSATM team
Original: https://blog.csdn.net/u012116328/article/details/117246023
Author: Jarvis码员
Title: 如何从零开始将神经网络移植到FPGA(ZYNQ7020)加速
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/688150/
转载文章受原作者版权保护。转载请注明原作者出处!