

1、摘要
本文主要讲解:PSO粒子群优化-LSTM-优化神经网络神经元个数dropout和batch_size,目标为对沪深300价格进行预测
主要思路:
- PSO Parameters :粒子数量、搜索维度、所有粒子的位置和速度、个体经历的最佳位置和全局最佳位置、每个个体的历史最佳适应值
- LSTM Parameters 神经网络第一层神经元个数、神经网络第二层神经元个数、dropout比率、batch_size
- 开始搜索:初始粒子适应度计算、计算初始全局最优、计算适应值、初始全局最优参数、适应度函数、更新个体最优、更新全局最优、全局最优参数
- 训练模型,使用PSO找到的最好的全局最优参数
- plt.show()
2、数据介绍
[‘SP’, ‘High’, ‘Low’, ‘KP’, ‘QSP’, ‘ZDE’, ‘ZDF’, ‘CJL’]

需要数据的话去我其他文章找到我的联系方式,有偿
数据链接
; 3、相关技术
PSO好的地方就是论文多,好写引用文献
不过说实话,算法优化我并不推荐用PSO,虽然说PSO的论文多,但是都被用烂了,AutoML-NNI,hyperopt,optuna,ray都是很好很先进的优化框架,里面集成了很多效果非常好的优化算法,推荐大家学习。
4、完整代码和步骤
代码输出如下:
主运行程序入口
import random
import time
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from keras.models import Sequential
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from tensorflow.python.keras.models import Sequential
batch_size = 128
epochs = 2
steps = 10
def process_data():
dataset = pd.read_csv("D:\项目\量化交易\沪深300/hs300.csv", engine='python', parse_dates=['date'], index_col=['date'])
columns = ['SP', 'High', 'Low', 'KP', 'QSP', 'ZDE', 'ZDF', 'CJL']
for col in columns:
scaler = MinMaxScaler()
dataset[col] = scaler.fit_transform(dataset[col].values.reshape(-1, 1))
X = dataset.drop(columns=['SP'], axis=1)
y = dataset['SP']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.24, shuffle=False, random_state=666)
return X_train, y_train, X_test, y_test
def create_dataset(X, y, seq_len=10):
features = []
targets = []
for i in range(0, len(X) - seq_len, 1):
data = X.iloc[i:i + seq_len]
label = y.iloc[i + seq_len]
features.append(data)
targets.append(label)
return np.array(features), np.array(targets)
X_train, y_train, X_test, y_test = process_data()
train_dataset, train_labels = create_dataset(X_train, y_train, seq_len=10)
X_test, y_test = create_dataset(X_test, y_test, seq_len=10)
from tensorflow.keras import Sequential, layers
def build_model(neurons, dropout):
model = Sequential([
layers.LSTM(units=neurons, input_shape=train_dataset.shape[-2:], return_sequences=True),
layers.Dropout(dropout),
layers.LSTM(units=256, return_sequences=True),
layers.Dropout(dropout),
layers.LSTM(units=128, return_sequences=True),
layers.LSTM(units=32),
layers.Dense(1)
])
return model
def training(X):
neurons = int(X[0])
dropout = round(X[1], 6)
batch_size = int(X[2])
model = build_model(neurons, dropout)
model.compile(optimizer='adam',
loss='mse')
model.fit(
train_dataset,
train_labels,
batch_size=batch_size,
epochs=1,
validation_data=(X_test, y_test),
verbose=1)
model.save(
'neurons' + str(int(X[0])) + '_dropout' + str(dropout) + '_batch_size' + str(batch_size) + '.h5')
pred = model.predict(X_test)
le = len(pred)
y_t = y_test.reshape(-1, 1)
return pred, le, y_t
def function(ps, test, le):
ss = sum(((abs(test - ps)) / test) / le)
return ss
MAX_EPISODES = 2
MAX_EP_STEPS = 2
c1 = 1
c2 = 1
w = 0.5
pN = 1
dim = 3
X = np.zeros((pN, dim))
V = np.zeros((pN, dim))
pbest = np.zeros((pN, dim))
gbest = np.zeros(dim)
p_fit = np.zeros(pN)
print(p_fit.shape)
print(p_fit.shape)
t1 = time.time()
'''
神经网络第一层神经元个数: 256-259
dropout比率: 0.03-0.19
batch_size: 64-128
'''
UP = [259, 0.19, 128]
DOWN = [256, 0.03, 64]
for i_episode in range(MAX_EPISODES):
"""初始化s"""
random.seed(8)
fit = -1e5
print("计算初始全局最优")
for i in range(pN):
for j in range(dim):
V[i][j] = random.uniform(0, 1)
if j == 1:
X[i][j] = random.uniform(DOWN[j], UP[j])
else:
X[i][j] = round(random.randint(DOWN[j], UP[j]), 0)
pbest[i] = X[i]
le, pred, y_t = training(X[i])
NN = 1
tmp = function(pred, y_t, le)
p_fit[i] = tmp
if tmp > fit:
fit = tmp
gbest = X[i]
print("初始全局最优参数:{:}".format(gbest))
fitness = []
for j in range(MAX_EP_STEPS):
fit2 = []
plt.title("第{}次迭代".format(i_episode))
for i in range(pN):
le, pred, y_t = training(X[i])
temp = function(pred, y_t, le)
fit2.append(temp / 1000)
if temp > p_fit[i]:
p_fit[i] = temp
pbest[i] = X[i]
if p_fit[i] > fit:
gbest = X[i]
fit = p_fit[i]
print("搜索步数:{:}".format(j))
print("个体最优参数:{:}".format(pbest))
print("全局最优参数:{:}".format(gbest))
for i in range(pN):
V[i] = w * V[i] + c1 * random.uniform(0, 1) * (pbest[i] - X[i]) + c2 * random.uniform(0, 1) * (gbest - X[i])
ww = 1
for k in range(dim):
if DOWN[k] < X[i][k] + V[i][k] < UP[k]:
continue
else:
ww = 0
X[i] = X[i] + V[i] * ww
fitness.append(fit)
print('Running time: ', time.time() - t1)
neurons = int(gbest[0])
dropout = gbest[1]
batch_size = int(gbest[2])
model = build_model(neurons, dropout)
model.compile(optimizer='adam',
loss='mse')
model.summary()
history = model.fit(train_dataset, train_labels, epochs=epochs, batch_size=batch_size, verbose=2)
test_preds = model.predict(X_test)
test_preds = test_preds[:, 0]
score = r2_score(y_test, test_preds)
print("r^2 值为: ", score)
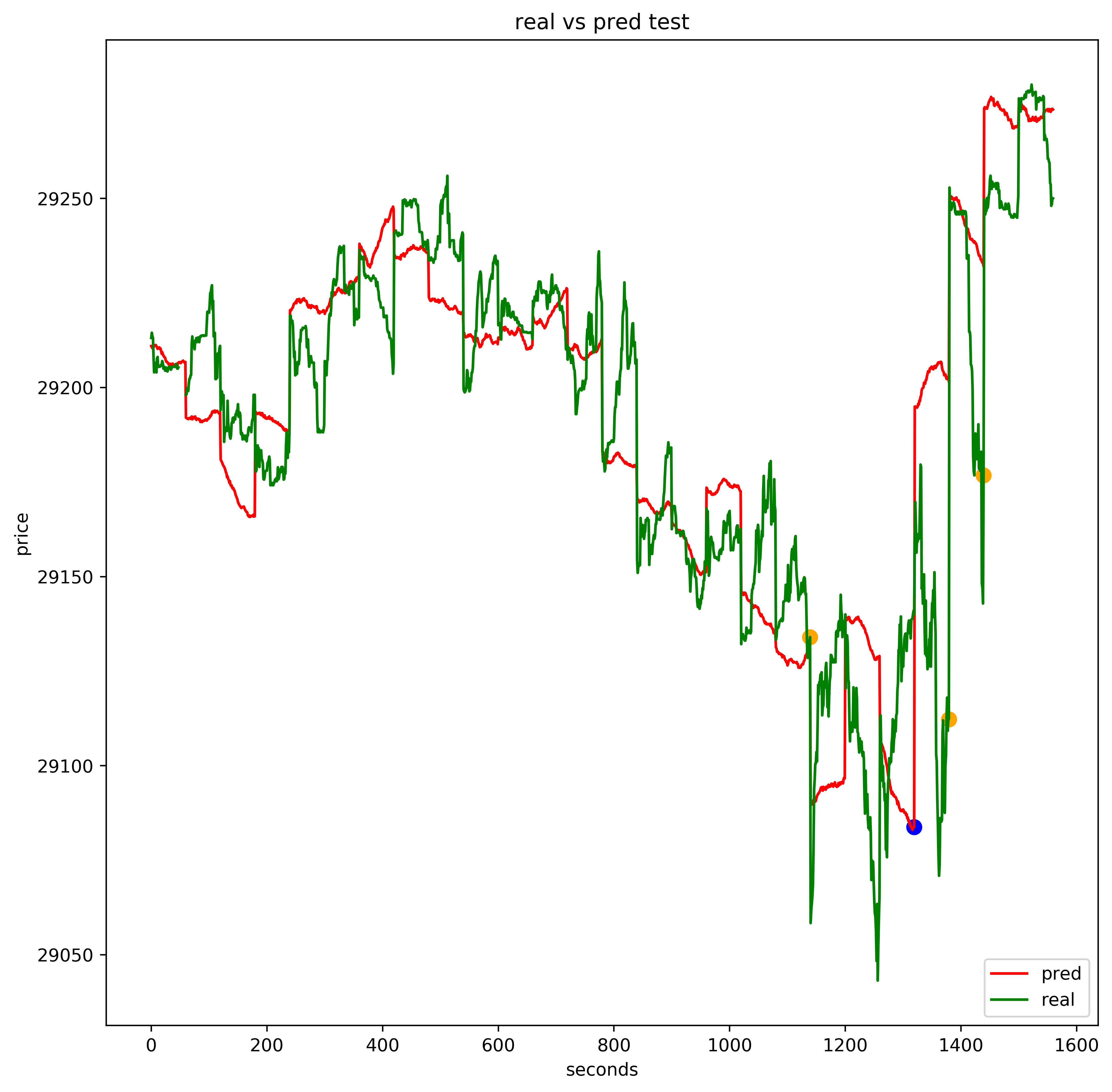
plt.figure(figsize=(16,8))
plt.plot(y_test[:1149], label="True value")
plt.plot(test_preds[:1149], label="Pred value")
plt.legend(loc='best')
plt.show()
plt.figure(figsize=(16,8))
plt.plot(history.history['loss'], label='train loss')
plt.legend(loc='best')
plt.show()
from sklearn import metrics
print(metrics.mean_squared_error(y_test,test_preds))
print(np.sqrt(metrics.mean_squared_error(y_test,test_preds)))
print(metrics.mean_absolute_error(y_test,test_preds))
代码比较复杂,如需帮忙请私聊
完整代码和数据链接
5、学习链接
PSO粒子群优化-LSTM-pyswarms框架-实现期货价格预测
https://pypi.org/project/pyswarms/
ljvmiranda921/pyswarms
PySwarms(Python粒子群优化工具包)的使用:GlobalBestPSO例子解析
Original: https://blog.csdn.net/qq_30803353/article/details/122462049
Author: AI信仰者
Title: PSO粒子群优化-LSTM-优化神经网络神经元个数dropout和batch_size
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/688050/
转载文章受原作者版权保护。转载请注明原作者出处!