

目标检测—全卷积实现
文章目录
首先照例分享学习资源:
带你逐行手写单目标检测算法,从数据到模型搭建、训练、预测_哔哩哔哩_bilibili
一.相关知识点的学习
二分类交叉熵:
其实现的公式:
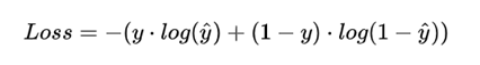

上式中带上标的y表示预测值(0-1之间),是网络的预测结果,y是真实值,因为是二分类,所以y的值只分0和1
; MSE:
KSE(均方误差)函数一般用来检测模型的预测值和真实值之间的偏差。
其实现公式为:
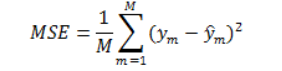
其值越大,表面预测的效果越差,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。
多分类交叉熵:
其实现公式为:
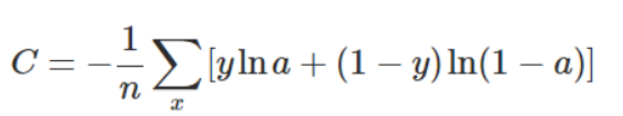
在上式中,C是损失值
n是求平均用的,所以是样本数量,也就是batchsize(每批训练的数量);
x是预测向量维度,因为需要在输出的特征向量维度上一个个计算并求和;
y是onehot编码后的真实值 对应x维度上的标签,是1或0;
a是onehot格式输出的预测标签,是0~1的值,a经过了softmax激活,所以a的和值为1。
其中(onehot编码)独热编码即 One-Hot 编码,又称一位有效编码。其方法是使用 N位 状态寄存器来对 N个状态 进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。
; FCN网络:
首先,FCN和CNN的区别在于把CNN最后的全连接转换成卷积层,其次,FCN网络可以接受任意尺寸的输入图像,并采用反卷积层对最后一个卷积层的feature map(特征图)进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
二.代码实现目标检测
二分类:sigmoid函数
回归问题:不需要激活
多分类问题:输出层使用softmax
(1)数据预处理
import os.path
import torch
import cv2
from torch.utils.data import Dataset
import numpy as np
class MyDataset(Dataset):
def __init__(self,root,is_Train = True):
self.dataset = []
dir = 'train' if is_Train else "test"
sub_dir = os.path.join(root,dir)
print("The current picture is from ",sub_dir)
img_list = os.listdir(sub_dir)
for i in img_list:
img_dir = os.path.join(sub_dir,i)
self.dataset.append(img_dir)
def __len__(self):
return len(self.dataset)
def __getitem__(self,index):
data = self.dataset[index]
img = cv2.imread(data)/255
new_img = torch.tensor(img).permute(2,0,1)
data_list = data.split('.')
label = int(data_list[1])
position = data_list[2:6]
position = [int(i)/300 for i in position]
sort = int(data_list[6])-1
return np.float32(new_img),np.float32(label),np.float32(position),np.int(sort)
if __name__ == '__main__':
data = MyDataset('F:\Artificial Intelligence\Target detection\yellow_data\yellow_data',is_Train=False)
for i in data:
print(i)
上述代码中,主要注意讲sort的标签从1-20转换为0-19
(2).网络搭建
from torch import nn
import torch
class My_net(nn.Module):
def __init__(self):
super(My_net,self).__init__()
self.layers = nn.Sequential(
nn.Conv2d(3,11,3),
nn.LeakyReLU(),
nn.MaxPool2d(3),
nn.Conv2d(11, 22, 3),
nn.LeakyReLU(),
nn.MaxPool2d(2),
nn.Conv2d(22, 32, 3),
nn.LeakyReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3),
nn.LeakyReLU(),
nn.Conv2d(64, 128, 3),
nn.LeakyReLU(),
)
self.label_layer = nn.Sequential(
nn.Conv2d(128,1,19),
nn.LeakyReLU()
)
self.position_layer = nn.Sequential(
nn.Conv2d(128,4,19),
nn.LeakyReLU()
)
self.sort_layer = nn.Sequential(
nn.Conv2d(128,20,19),
nn.LeakyReLU()
)
def forward(self,x):
out = self.layers(x)
label = self.label_layer(out)
label = torch.squeeze(label,dim = 2)
label = torch.squeeze(label, dim=2)
label = torch.squeeze(label, dim=1)
position = self.position_layer(out)
position = torch.squeeze(position,dim = 2)
position = torch.squeeze(position,dim = 2)
sort = self.sort_layer(out)
sort = torch.squeeze(sort,dim = 2)
sort = torch.squeeze(sort, dim=2)
return label,position,sort
if __name__ == '__main__':
net = My_net()
x = torch.randn(3,3,300,300)
print(net(x)[0].shape)
print(net(x)[1].shape)
print(net(x)[2].shape)
注意对应维度的转换。
(3).训练函数编写
from net import My_net
from data import MyDataset
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torch import nn,optim
import torch
import datetime
import os
import warnings
warnings.filterwarnings('ignore')
Device = 'cuda'
class train:
def __init__(self,root,weight):
self.summaryWriter = SummaryWriter('logs')
self.train_dataset = MyDataset(root = root,is_Train=True)
self.test_dataset = MyDataset(root = root,is_Train=False)
self.train_dataLoader = DataLoader(self.train_dataset,batch_size=50,shuffle=True)
self.test_dataLoader = DataLoader(self.test_dataset,batch_size=50,shuffle=True)
self.net = My_net().to(Device)
if os.path.exists(weight):
self.net.load_state_dict(torch.load(weight))
self.opt = optim.Adam(self.net.parameters())
self.label_loss_fun = nn.BCEWithLogitsLoss()
self.position_loss_fun = nn.MSELoss()
self.sort_loss_fun = nn.CrossEntropyLoss()
self.train = True
self.text = True
def __call__(self):
index1,index2 = 0,0
for epoch in range(1000):
if self.train:
for i,(img,label,position,sort) in enumerate(self.train_dataLoader):
self.net.train()
img,label,position,sort = img.to(Device),label.to(Device),position.to(Device),sort.to(Device)
out_label,out_position,out_sort = self.net(img)
label_loss = self.label_loss_fun(out_label,label)
position_loss = self.position_loss_fun(out_position,position)
sort = sort[torch.where(sort>=0)]
out_sort = out_sort[torch.where(sort>=0)]
sort_loss = self.sort_loss_fun(out_sort,sort)
train_loss = 0.2 * label_loss + position_loss * 0.6 + 0.2 * sort_loss
self.opt.zero_grad()
train_loss.backward()
self.opt.step()
if i%10 == 0:
print('train_loss{i}=====>',train_loss.item())
self.summaryWriter.add_scalar('train_loss',train_loss,index1)
index1+=1
date_time = str(datetime.datetime.now()).replace(' ', '-').replace(':', '_').replace('.', '_')
torch.save(self.net.state_dict(), f'param/{date_time}-{epoch}.pt')
if self.text:
sum_sort_acc,sum_label_acc = 0,0
for i, (img, label, position, sort) in enumerate(self.train_dataLoader):
self.net.train()
img, label, position, sort = img.to(Device), label.to(Device), position.to(Device), sort.to(Device)
out_label, out_position, out_sort = self.net(img)
label_loss = self.label_loss_fun(out_label, label)
position_loss = self.position_loss_fun(out_position, position)
sort = sort[torch.where(sort >= 0)]
out_sort = out_sort[torch.where(sort >= 0)]
sort_loss = self.sort_loss_fun(out_sort, sort)
test_loss = label_loss + position_loss + sort_loss
out_label = torch.tensor(torch.sigmoid(out_label))
out_label[torch.where(out_label>=0.5)] = 1
out_label[torch.where(out_label < 0.5)] = 0
out_sort = torch.argmax(torch.softmax(out_sort,dim = 1))
label_acc=torch.mean(torch.eq(out_label,label).float())
sum_label_acc+=label_acc
sort_acc = torch.mean(torch.eq(out_sort,sort).float())
sum_sort_acc += sort_acc
if i % 10 == 0:
print('test_loss{i}=====>', test_loss.item())
self.summaryWriter.add_scalar('test_loss', test_loss, index2)
index2 += 1
avg_sort_acc = sum_sort_acc/i
avg_label_acc = sum_label_acc/i
print(f'avg_sort_acc{epoch}===>',avg_sort_acc)
print(f'avg_label_acc{epoch}===>', avg_sort_acc)
self.summaryWriter.add_scalar('avg_sort_acc',avg_sort_acc,epoch)
self.summaryWriter.add_scalar('avg_label_acc', avg_label_acc, epoch)
if __name__ == '__main__':
train = train('F:\Artificial Intelligence\Target detection\yellow_data\yellow_data','param/2021-10-19-23_38_55_992635-0.pt')
train()
若未有weight文件的话,先注释掉weight部分,否则代码无法运行,具体可以看分享的学习资料。
(4).预测函数
import os
import torch
import cv2
from net import My_net
if __name__ == '__main__':
img_name = os.listdir(r'F:\Artificial Intelligence\\Target detection\yellow_data\yellow_data\\test')
for i in img_name:
img_dir = os.path.join(r'F:\Artificial Intelligence\\Target detection\yellow_data\yellow_data\\test',i)
img = cv2.imread(img_dir)
position = i.split('.')[2:6]
sort = i.split('.')[6]
position = [int(j) for j in position]
cv2.rectangle(img,(position[0],position[1]),(position[2],position[3]),(0,255,0),thickness = 2)
cv2.putText(img,sort,(position[0],position[1]-3),cv2.FONT_HERSHEY_SIMPLEX,2,(0,255,0),thickness = 2)
model = My_net()
model.load_state_dict(torch.load('param/2021-10-20-08_13_42_378776-0.pt'))
new_img = torch.tensor(img).permute(2,0,1)
new_img = torch.unsqueeze(new_img,dim = 0)/255
out_label,out_sort,out_position = model(new_img)
out_label = torch.sigmoid(out_label)
out_sort = torch.argmax(torch.softmax(out_sort,dim = 1))
out_position = out_position[0]*300
out_position = [int(i) for i in out_position]
if out_label.item()>0.5:
cv2.rectangle(img,(out_position[0],out_position[1]),(out_position[2],out_position[3]),(0,255,0))
cv2.putText(img,str(out_sort.item()),(out_position[0],out_position[1]),cv2.FONT_HERSHEY_SIMPLEX,2,(0,0,255))
cv2.imshow('img',img)
cv2.waitKey(500)
cv2.destroyAllWindows()
10.20学习总结
Original: https://blog.csdn.net/qq_52533790/article/details/120872424
Author: 风声向寂
Title: 目标检测—全卷积实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/687710/
转载文章受原作者版权保护。转载请注明原作者出处!