

论文地址:https://arxiv.org/pdf/1904.07850.pdf
代码地址:CenterNet: Object detection, 3D detection, and pose estimation using center point detection
CenterNet 是2019年4月发布的,是一种基于关键点估计的目标检测方法。
目标作为点
Abstract
exhaustive:adj. 详尽的; orientation:方向; differentiable:可微的
competitively:adv. 竞争性地;sophisticated:复杂的
检测将对象识别为图像中轴对齐的框。大多数成功的目标检测器都能列举出可能的物体位置,并对每个位置进行分类。这是浪费、低效的,并且需要额外的后处理。在本文中,我们采用了一种不同的方法。我们将一个目标建模为一个单点,即其 bounding box的 中心点。我们的检测器使用关键点估计来找到 中心点,并回归到所有其他目标属性,如大小、3D定位、方向,甚至姿态。我们基于中心点的方法,CenterNet是端到端可微的,比相应的基于 bounding box 的检测器更简单、更快、更精确。CenterNet在MS COCO数据集上实现了最佳的速度-精度权衡,在142 FPS下有28.1%的AP,在52 FPS下有37.4%的AP,在multi-scale测试中在1.4 FPS下有45.1%的AP。我们使用相同的方法来估计KITTI基准中的 3D bounding box 和COCO关键点数据集上的人体姿态。我们的方法与复杂的多阶段方法相比具有竞争力,并且是实时运行的。
理解:
基于bounding box的目标检测: 浪费、低效和需要加入后处理;
本文把目标建模为bounding box的 中心点,使用关键点估计的方法找到 中心点,然后回归出目标其他属性,如大小等。
- Conclusion
总之,我们提出了 一种新的目标表示方法: 以点表示。我们的CenterNet目标检测器建立在成功的关键点估计网络之上,找到目标中心,然后回归到它们的大小。该算法具有简单、快速、准确、端到端可微分等特点,无需任何 NMS 后处理。这个想法是通用的,并且在简单的二维检测之外有广泛的应用。CenterNet可以在一次前向传播中估计一系列额外的目标属性,如姿态、3D方向、深度和范围。我们最初的实验是令人鼓舞的,并为实时目标识别和相关任务开辟了一个新的方向。
- Introduction
down-stream:下游; surveillance :监控;tightly encompasses:紧紧包围;extensive :大量的; specifying :说明
目标检测为许多视觉任务提供了动力,比如实例分割、姿态估计、跟踪和动作识别。它的下游应用有监控、自动驾驶、视觉答疑。当前的目标检测器通过一个紧密包围目标的轴对齐的 bounding box 来表示每个目标。然后将目标检测简化为大量潜在目标边界框的图像分类。对于每个边界框,分类器确定图像内容是特定的目标还是背景。One-stage 检测器在图像上滑动可能的bounding box(称为 anchors )的复杂排列,并直接对它们进行分类,而不指定box的内容。Two-stage 检测器重新计算每个潜在 box 的图像特征,然后对这些特征进行分类。后处理,即非极大值抑制,通过计算bounding box IoU消除对同一实例的重复检测。这种后处理很难求微分和训练,因此目前大多数检测器都不能端到端训练。尽管如此,在过去的五年中,这个想法已经取得了很好的实验上的成功。然而,基于滑动窗口的目标检测器有点浪费,因为它们需要枚举所有可能的目标定位和大小。
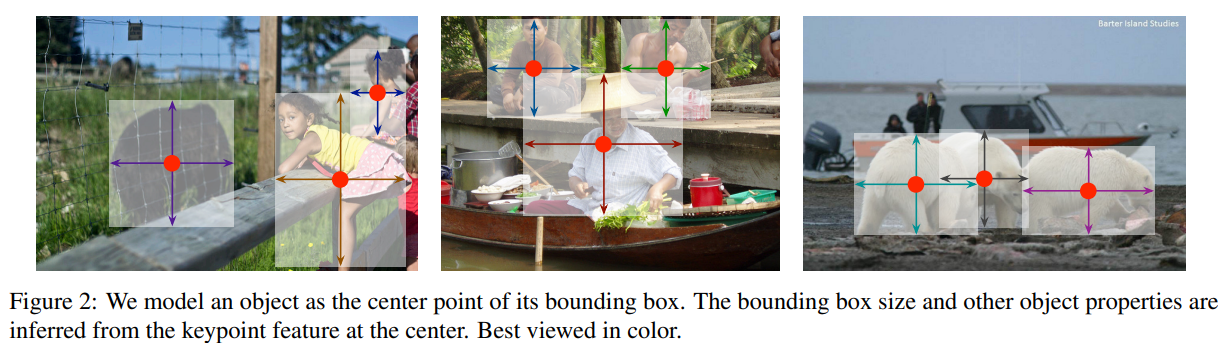

在本文中,我们提供了一种更简单、更有效的替代方案。我们用bounding box中心的一个点表示目标(见图2)。其他属性,如目标的大小、尺寸、3D范围、方向和姿态,然后直接从中心定位的图像特征回归得到。然后,目标检测成为一个标准的关键点估计问题。我们只需将输入图像输入到一个全卷积网络,它就会生成一张热图。这张热图中的峰值对应的是目标的中心。每个峰值处的图像特征预测目标的bounding box高度和宽度。该模型使用标准的密集监督学习进行训练。推理是一个单个网络前向传播,对后处理没有NMS。
我们的方法是通用的,可以扩展到其他任务,只需少量的努力。我们通过预测每个中心点的额外输出(见图4),提供了3D目标检测和多人人体姿态估计的实验。对于3D bounding box 的估计,我们回归到目标绝对深度、3D bounding box 大小和目标方向。对于人体的姿态估计,我们将 2D joint locations 作为离中心点的偏移量,在中心点位置直接回归到该偏移量。
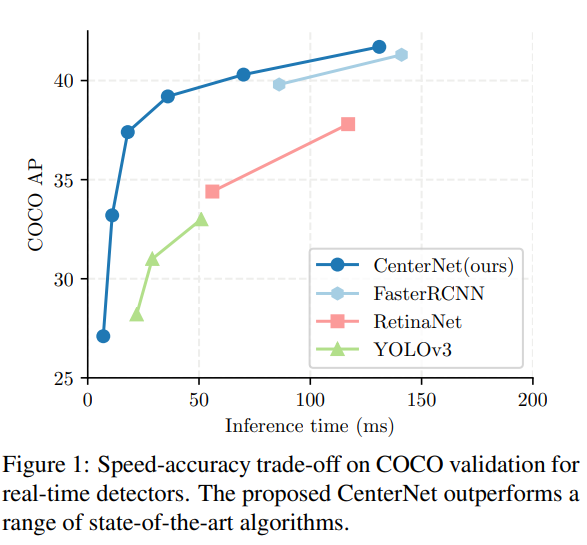
我们的方法CenterNet的简单性使它能够以非常高的速度运行(图1)。用一个简单的Resnet-18和up-convolutional层, 我们的网络运行在142 FPS与28.1%的COCO bounding box AP。使用精心设计的关键点检测网络,DLA-34,我们的网络以52 FPS达到37.4% COCO AP。我们的网络配备了最先进的关键点估计网络Hourglass-104和多尺度测试,在1.4 FPS下实现了45.1%的COCO AP。在3D bounding box 估计和人体姿态估计上,我们以更高的推理速度与最先进的技术进行竞争。有关代码在:https://github. com/xingyizhou/CenterNet.
- Related work
基于区域分类的目标检测:RCNN[是最早成功的深度目标检测器之一,它从一个大的区域候选集合中枚举目标位置,对其进行裁减,并使用深度网络对每个目标进行分类。Fast-RCNN裁减图像特征代替裁减图像区域,以节省计算。然而,这两种方法都依赖于缓慢的低水平建议区域方法。
基于隐式anchors的目标检测:Faster RCNN 在检测网络内生成建议区域。它对低分辨率图像网格周围的固定形状的bounding boxes(anchors)进行采样,并将它们分类为前景或背景。当一个 anchor 与任何真实框的IOU>0.7,那么被标记为前景;当一个 anchor 与任何真实框的IOU
Original: https://blog.csdn.net/hymn1993/article/details/124105004
Author: 理心炼丹
Title: 【目标检测】CenterNet
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/687688/
转载文章受原作者版权保护。转载请注明原作者出处!