

文章目录
前言
上一章介绍了目标检测的入门,这一章就目标检测近些年的发展做一个介绍。
关于目标检测具体怎么分,谁和谁一家其实有两种分类:基于anchor和stage。
关于anchor在我自己的一篇文章中有提到这个FCOS,根据是否需要anchor主要分为anchor-based和anchor-free两大流派。
关于stage又可以划分为one-stage和two-stage。
因为内容太多,我这里分为四个章节去讲。
tips:因为东西太太太多了,还有其他事情要忙,自己也在慢慢补起来~
Stage
它们的主要区别
- one-stage网络速度要快很多
- two-stage网络准确率高
one-stage
one-stage目标检测算法(也称one-shot object detectors),其特点是一步到位,速度相对较快。one-stage检测方法,仅仅需要送入网络 一次就可以预测出所有的边界框,因而速度较快,非常适合移动端。最典型的one-stage检测算法包括YOLO系列,SSD(anchor box)。
two-stage
two-stage检测算法将检测问题划分为两个阶段,首先产生候选区域(region proposals),然后对候选区域分类(一般还需要对位置精修),这一类的典型代表是R-CNN(Selective Search), Fast R-CNN(利用卷积和池化过程近似滑窗), Faster R-CNN(anchor box),Mask R-CNN家族。他们识别错误率低,漏识别率也较低,但速度较慢,不能满足实时检测场景。
针对两个区别做以下总结:
速度快慢总结
one-stage网络生成的ancor框只是一个逻辑结构,或者只是一个数据块,只需要对这个数据块进行分类和回归就可以,不会像two-stage网络那样,生成的 ancor框会映射到feature map的区域(rcnn除外),然后将该区域重新输入到全连接层进行分类和回归,每个ancor映射的区域都要进行这样的分类和回归,所以它非常耗时。为什么two-stage网络更准确—-正负样本不均衡问题
rcnn它是首先在原图上利用Selective Search(过分割+分层聚类)生成若干个候选区域,这个候选区域表示可能会是目标的候选区域,注意,这样的候选区域肯定不会特别多,然后再把这些候选框送到分类和回归网络中进行分类和回归, fast-rcnn其实差不多,只不过它不是最开始将原图的这些候选区域送到网络中,而是在最后一个feature map将这个候选区域提出来,进行分类和回归。再来看 faster-rcnn,在这里出现了anchor box概念,虽然faster-rcnn它最终一个feature map它是每个像素点产生9个ancor,生成的anchor在rpn网络结束后,再经过IoU阈值的筛选,筛选后的候选区域经过RoI送到最终的分类和回归网络中进行训练,所以不管是rcnn还是fast-rcnn还是faster-rcnn,它们最终进行训练的ancor其实并不多,几百到几千,不会存在特别严重的正负样本不均衡问题。 但是我们再来看yolo系列网络,就拿yolo3来说吧,它有三种尺度,13×13,26×26,52×52,每种尺度的每个像素点生成三种ancor,那么它最终生成的ancor数目就是(13×13+26×26+52×52)*3 = 10647个ancor,而真正负责预测的可能每种尺度的就那么几个,假如一张图片有3个目标,那么每种尺度有三个ancor负责预测,那么10647个ancor中总共也只有9个ancor负责预测,也就是正样本,其余的10638个ancor都是背景ancor,这存在一个严重的正负样本失衡问题,虽然位置损失,类别损失,这10638个ancor不需要参与,但是目标置信度损失,背景ancor参与了,因为总的损失 = 位置损失 + 目标置信度损失 + 类别损失,所以背景ancor对总的损失有了很大的贡献,但是我们其实不希望这样的,我们更希望的是非背景的ancor对总的损失贡献大一些,这样不利于正常负责预测ancor的学习,而two-stage网络就不存在这样的问题,two-stage网络最终参与训练的或者计算损失的也只有2000个或者300个,它不会有多大的样本不均衡问题,不管是正样本还是负样本对损失的贡献几乎都差不多,所以网络会更有利于负责预测ancor的学习,所以它最终的准确性肯定要高些
one-stage
one-stage检测器的大致发展路线:
- SSD(2015)->RetinaNet(2017)-NAS-FPN(2019.05)->EfficientDet(2019.11)
- Yolo v1->Yolo v2->Yolo v3->Yolo v4->Yolo v5->…
SSD
网络结构图
下面是SSD模型的精简版和细节版


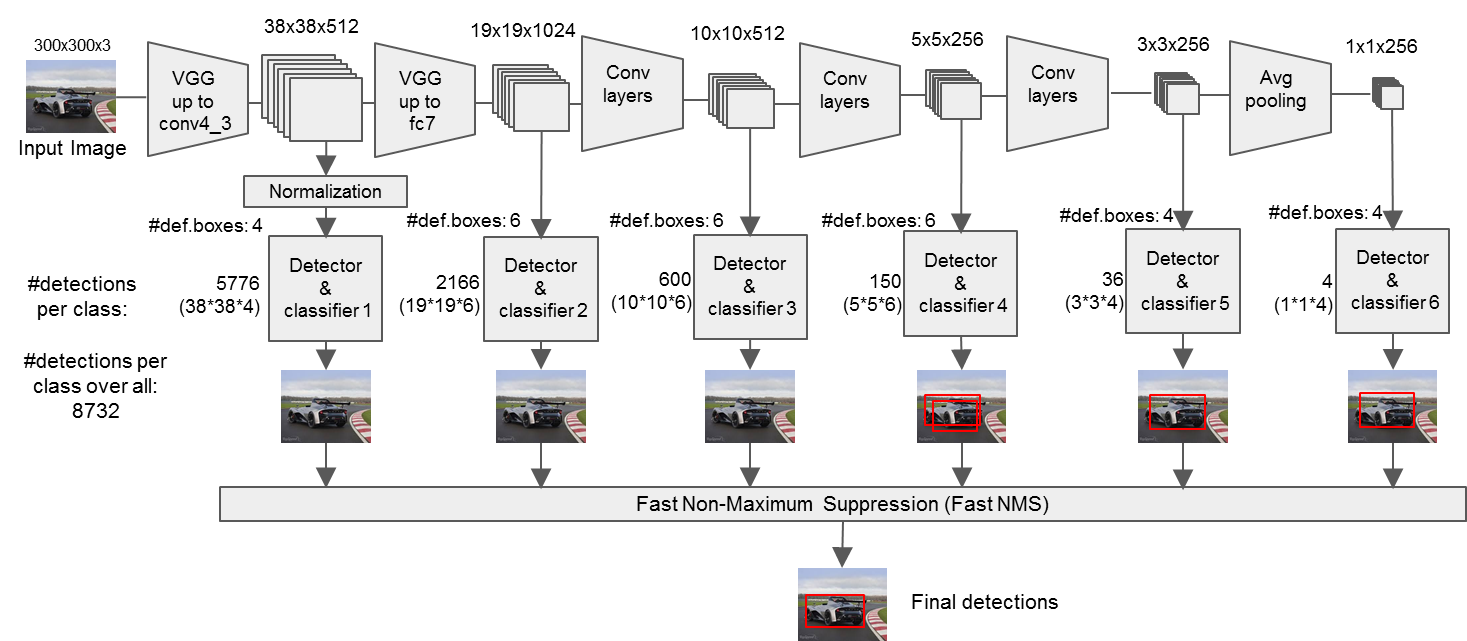
采用VGG16作为backbone,作了以下修改:
- 分别将VGG16的全连接层FC6和FC7转换成 3×3 的卷积层 Conv6和 1×1 的卷积层Conv7
- 去掉所有的Dropout层和FC8层
- 同时将池化层pool5由原来的 stride=2 的 2×2 变成stride=1的 3×3
- 添加了Atrous算法(hole算法),目的获得更加密集的得分映射
- 然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测
; 特点
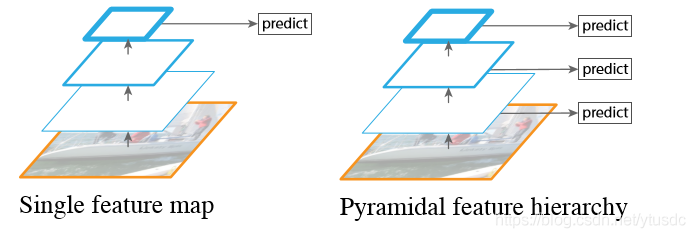
为什么要多尺度预测,是因为 浅层卷积层对边缘更加感兴趣,可以获得一些细节信息(位置信息),而深层网络对由浅层特征构成的复杂特征更感兴趣,可以获得一些语义信息,对于检测任务而言,一幅图像中的目标有复杂的有简单的,对于简单的patch我们利用浅层网络的特征就可以将其检测出来,对于复杂的patch我们利用深层网络的特征就可以将其检测出来,因此,如果我们同时在不同的feature map上面进行目标检测,理论上面应该会获得更好的检测效果。
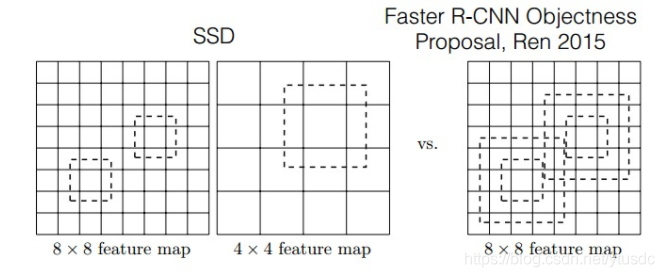
对于BB(bounding boxes)的生成,Faster-rcnn和SSD有不同的策略,但是都是为了同一个目的,产生不同尺度,不同形状的BB,用来检测物体。对于Faster-rcnn而言,其在特定层的Feature map上面的每一点生成9个预定义好的BB,然后进行ROI Pooling和检测获得相应的BB,然后进行回归和分类操作来进行初步检测;而SSD则在不同的特征层的feature map上的每个点同时获取6个(有的层是4个)不同的BB,然后将这些BB结合起来,最后经过NMS处理获得最后的BB。
损失函数
损失函数 = confidence loss + location loss
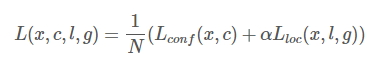
SSD中的confidence loss是在多类别置信度©上的softmax loss,而location loss(位置回归)是典型的smooth L1 loss
; YOLOv1
论文标题:You Only Look Once: Unified, Real-Time Object Detection
论文地址:https://arxiv.org/abs/1506.02640
网络结构图
Darknet实际上也是YOLO作者实现的一个backbone网络,其改进对象主要是GoogleNet,将GoogleNet中的Inception结构改成了串行的结构,从而使得网络速度更快,而效果仅仅损失了一点。可以看到下面的网络结构有24个卷积层,外加2个全连接层。
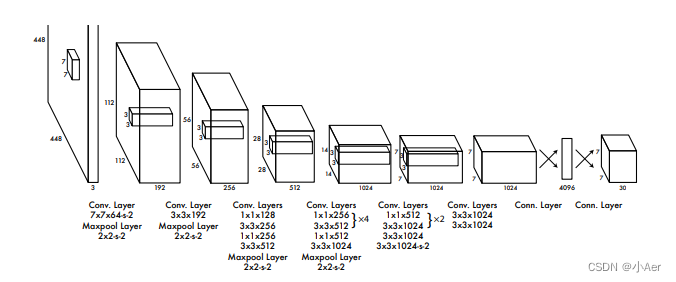
给出 输出更加详细的图像:
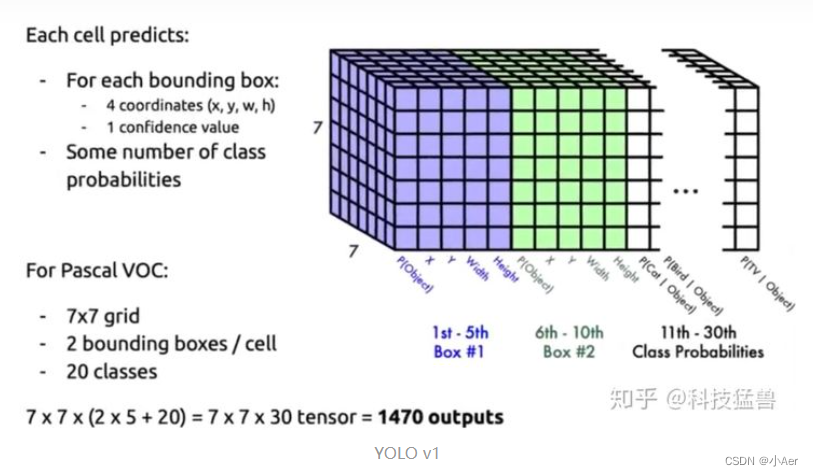
可以看到三点:
- 7*7的划分
- 2个bounding boxes,用来预测大小目标
- 20个类别(one-hot的形式)
; 特点
- 采用Leaky Relu激活函数
- dropout
- 将detection视为回归问题,仅使用一个neural network同时预测bounding box的位置和类别,因此速度很快。
- 使用NMS解决多个目标情况
- 使用one-hot解决多类的目标(20个类别)
- 使用2个五元组(c,x,y,w,h),一个负责回归大目标,一个负责回归小目标,同样添加one-hot vector,one-hot就是[0,1],[1,0]这样子。
损失函数

- 前2行计算前景的geo_loss。
- 第3行计算前景的confidence_loss。
- 第4行计算背景的confidence_loss。
- 第5行计算分类损失class_loss。
; 优缺点
YOLO的优点不用多说,其作为当时最快的实时目标检测算法横空出世,SSD是在其后出来的,正式打开了one-stage目标检测算法的大门,虽然精度仍然不如Faster RCNN等,但是其速度很高,适合工程界研究改造。
当然其缺点也有很多:
- YOLOv1采用了7×7的网格划分模式,每个网格只能预测两个同类别的目标框,那么就无法预测密集场景下的目标位置,如:拥挤人群;
- YOLOv1的网格划分方式会影响每个目标的边界定位准确度,因为目标一般是跨网格区域的,如果目标只有一小部分在某个网格,那么可能就会被忽略;
- NMS本身漏洞,NMS会将相邻的目标框去重。
- 没有计算背景的geo_loss,只计算了前景的geo_loss,这个问题YOLO v1回避了,依然存在。
YOLOv2
论文题目:YOLO9000: Better, Faster, Stronger
论文地址:https://arxiv.org/abs/1612.08242
YOLOv2也被称作YOLO9000,其相对于YOLOv1提升了很多,正如作者所说:Better、Faster、Stronger。其行文很容易理解,我们直接通过创新点来了解其与YOLOv1的区别。
改进
YOLO v1虽然快,但是预测的框不准确,很多目标找不到:
- 预测的框不准确:准确度不足。
- 很多目标找不到:recall不足。
针对两个问题做出两个改进:
YOLO v2改预测偏移量,直接预测位置会导致神经网络在一开始训练时不稳定,使用偏移量会使得训练过程更加稳定,性能指标提升了5%左右。
位置上不使用Anchor框,宽高上使用Anchor框。以上就是YOLO v2的一个改进。

网络结构
- Training for classfication–Darknet19
YOLOv2在YOLOv1中的backbone网络基础上借鉴了VGG网络中的卷积方式,利用多个小卷积核替代大卷积核,并且利用1×1卷积核代替全连接层,这样做的好处的特征图每个位置共享参数,然后利用卷积核个数弥补参数组合多样性:
layer filters size input output
0 conv 32 3 x 3 / 1 256 x 256 x 3 -> 256 x 256 x 32 0.113 BFLOPs
1 max 2 x 2 / 2 256 x 256 x 32 -> 128 x 128 x 32
2 conv 64 3 x 3 / 1 128 x 128 x 32 -> 128 x 128 x 64 0.604 BFLOPs
3 max 2 x 2 / 2 128 x 128 x 64 -> 64 x 64 x 64
4 conv 128 3 x 3 / 1 64 x 64 x 64 -> 64 x 64 x 128 0.604 BFLOPs
5 conv 64 1 x 1 / 1 64 x 64 x 128 -> 64 x 64 x 64 0.067 BFLOPs
6 conv 128 3 x 3 / 1 64 x 64 x 64 -> 64 x 64 x 128 0.604 BFLOPs
7 max 2 x 2 / 2 64 x 64 x 128 -> 32 x 32 x 128
8 conv 256 3 x 3 / 1 32 x 32 x 128 -> 32 x 32 x 256 0.604 BFLOPs
9 conv 128 1 x 1 / 1 32 x 32 x 256 -> 32 x 32 x 128 0.067 BFLOPs
10 conv 256 3 x 3 / 1 32 x 32 x 128 -> 32 x 32 x 256 0.604 BFLOPs
11 max 2 x 2 / 2 32 x 32 x 256 -> 16 x 16 x 256
12 conv 512 3 x 3 / 1 16 x 16 x 256 -> 16 x 16 x 512 0.604 BFLOPs
13 conv 256 1 x 1 / 1 16 x 16 x 512 -> 16 x 16 x 256 0.067 BFLOPs
14 conv 512 3 x 3 / 1 16 x 16 x 256 -> 16 x 16 x 512 0.604 BFLOPs
15 conv 256 1 x 1 / 1 16 x 16 x 512 -> 16 x 16 x 256 0.067 BFLOPs
16 conv 512 3 x 3 / 1 16 x 16 x 256 -> 16 x 16 x 512 0.604 BFLOPs
17 max 2 x 2 / 2 16 x 16 x 512 -> 8 x 8 x 512
18 conv 1024 3 x 3 / 1 8 x 8 x 512 -> 8 x 8 x1024 0.604 BFLOPs
19 conv 512 1 x 1 / 1 8 x 8 x1024 -> 8 x 8 x 512 0.067 BFLOPs
20 conv 1024 3 x 3 / 1 8 x 8 x 512 -> 8 x 8 x1024 0.604 BFLOPs
21 conv 512 1 x 1 / 1 8 x 8 x1024 -> 8 x 8 x 512 0.067 BFLOPs
22 conv 1024 3 x 3 / 1 8 x 8 x 512 -> 8 x 8 x1024 0.604 BFLOPs
23 conv 1000 1 x 1 / 1 8 x 8 x1024 -> 8 x 8 x1000 0.131 BFLOPs
24 avg 8 x 8 x1000 -> 1000
25 softmax 1000
我们可以看到其中有19个卷积层和5个max pooling层,所以称其为Darknet19。作者利用该网络重新再Imagenet上训练了,相对于yolov1中的backbone网络,参数量更少,计算速度更快,效果更好。
-
Training for Detection
-
有了backbone骨干网络之后,作者剔除了Darknet19的最后一个卷积层,然后额外添加了几个卷积层
- 出现了两个新层reorg和route,route的层的作用就是将选定层按照通道拼接在一起,而reorg层的作用就是将特征图均匀划分为 4 份,从而使得两组特征图可以拼接。
最终的网络结构:
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32
1 max 2 x 2 / 2 416 x 416 x 32 -> 208 x 208 x 32
2 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64
3 max 2 x 2 / 2 208 x 208 x 64 -> 104 x 104 x 64
4 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128
5 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64
6 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128
7 max 2 x 2 / 2 104 x 104 x 128 -> 52 x 52 x 128
8 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
9 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
10 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
11 max 2 x 2 / 2 52 x 52 x 256 -> 26 x 26 x 256
12 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
13 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
14 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
15 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
16 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
17 max 2 x 2 / 2 26 x 26 x 512 -> 13 x 13 x 512
18 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024
19 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512
20 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024
21 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512
22 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024
23 conv 1024 3 x 3 / 1 13 x 13 x1024 -> 13 x 13 x1024
24 conv 1024 3 x 3 / 1 13 x 13 x1024 -> 13 x 13 x1024
25 route 16
26 reorg / 2 26 x 26 x 512 -> 13 x 13 x2048
27 route 26 24
28 conv 1024 3 x 3 / 1 13 x 13 x3072 -> 13 x 13 x1024
29 conv 425 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 425
30 detection
- 全卷积网络
综上可知,YOLOv2是一个全卷积网络,与YOLOv1相同,利用感受野的概念,我们可以认为是将原图划分为了多个网格区域,且区域半径为32,所以说输入大小必须是32的倍数。另外全卷积网络的好处在于可以有任意分辨率的输入,因为全连接层参数依赖前后两层的尺寸,而卷积层参数只有卷积核,与前后层尺寸无关,所以更为方便了。
特点
- 上面讲到的网络结构的改变
- 相对于YOLOv1,YOLOv2将dropout替换成了效果更好的batch normalization,在每个卷积层计算之前利用batch normalization进行批归一化:
- 为了让网络能适应不同分辨率的输入,在训练过程中,每10个batches会随机选择一种分辨率输入,即利用图像插值对图像进行放缩,由于训练速度的要求以及分辨率必须是32倍数,所以训练过程中选择的分辨率分别为:320, 352, …, 608。
- YOLOv2相对于YOLOv1的定位架构最大的改变在于提出了anchor boxes概念,从直接预测目标相对网格区域的偏移量到预测anchor box的修正量,有了先验长宽比的约束,可以减少很多不规则的目标定位。
- softmax
YOLOv2中对于每个类别的概率输出进行了softmax归一化。 - 学习率
YOLOv2的学习率变化方式与YOLOv1类似:
损失函数
计算损失有个地方需要注意:前12800步我们会优化预测的(x,y,w,h)与anchor的(x,y,w,h)的距离+预测的(x,y,w,h)与GT的(x,y,w,h)的距离,12800步之后就只优化预测的(x,y,w,h)与GT的(x,y,w,h)的距离,为啥?因为这时的预测结果已经较为准确了,anchor已经满足我了我们了,而在一开始预测不准的时候,用上anchor可以加速训练。
优缺点
YOLOv2相对来说在每个网格内预测了更多的目标框,并且每个目标框可以不用为同一类,而每个目标都有着属于自己的分类概率,这些使得预测结果更加丰富。另外,由于anchor box的加入,使得YOLOv2的定位精度更加准确。不过,其对于YOLOv1的许多问题依旧没有解决,当然那些也是很多目标检测算法的通病。那么随着anchor box的加入所带来的新问题是:
- anchor box的个数以及参数都属于超参数,因此会影响训练结果;
- 由于anchor box在每个网格内都需要计算一次损失函数,然而每个正确预测的目标框才能匹配一个比较好的先验anchor,也就是说,对于YOLOv2中的5种anchor box,相当于强行引入了4倍多的负样本,在本来就样本不均衡的情况下,加重了不均衡程度,从而使得训练难度增大;
- 由于IOU和NMS的存在,会出现两个人很靠近或重叠时,检测框变成了中间的矩形框,然后由于NMS存在,其他的相邻的框则会被剔除。要想避免这种情况,就应该在损失函数中加入相关的判定。
- YOLO v2做了这么多改进,整体性能大幅度提高,但是小目标检测仍然是YOLO v2的痛。直到kaiming大神的ResNet出现,backbone可以更深了,所以darknet53诞生。
YOLOv3
论文题目:YOLOv3: An Incremental Improvement
论文地址:https://arxiv.org/abs/1804.02767
网络结构Darknet-53
YOLOv3中又提出了一种新的backbone网络——Darknet-53。其架构如下:
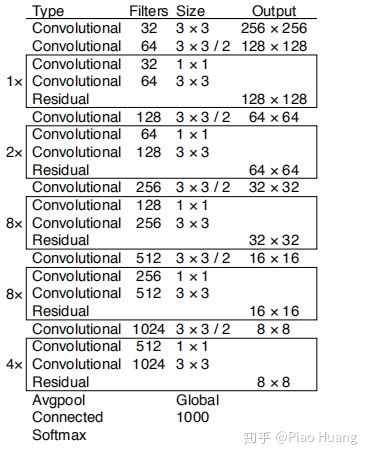
可以看到,新增了Residual模块,可能是因为网络太深了
; 特点
- 网络结构的改变
- YOLOv3增加了top down 的多级预测,解决了yolo颗粒度粗,对小目标无力的问题。
- Anchor Boxes改进
YOLOv2中是直接预测了目标框相对网格点左上角的偏移,以及anchor box的修正量,而在YOLOv3中同样是利用K-means聚类得到了9组anchor box,只不过YOLOv2中用的是相对比例,而YOLOv3中用的是绝对大小。那么鉴于我们之前提到的anchor box带来的样本不平衡问题,以及绝对大小可能会出现超出图像边界的情况,作者加入了新的判断条件,即对于每个目标预测结果只选择与groundtruth的IOU最大/超过0.5的anchor,不考虑其他的anchor,从而大大减少了样本不均衡情况。 - YOLOv3中取消了对于分类概率的联合分布softmax,而是采用了logistic函数,因为有一些数据集的中的目标存在多标签,而softmax函数会让各个标签相互抑制。
YOLOv4
论文题目:YOLOv4: Optimal Speed and Accuracy of Object Detection
论文地址:https://arxiv.org/abs/2004.10934
改进
检测头的改进
YOLO v4的作者换成了Alexey Bochkovskiy大神,检测头总的来说还是多尺度的,3个尺度,分别负责大中小目标。只不过多了一些细节的改进:
- Using multi-anchors for single ground truth
之前的YOLO v3是1个anchor负责一个GT,YOLO v4中用多个anchor去负责一个GT。方法是:对于 G T j GT_j G T j 来说,只要 I o U ( a n c h o r i , G T j ) > t h r e s h o l d IoU(anchor_i,GT_j)>threshold I o U (a n c h o r i ,G T j )>t h r e s h o l d ,就让 a n c h o r i anchor_i a n c h o r i 去负责 G T j GT_j G T j 。
这就相当于你anchor框的数量没变,但是选择的正样本的比例增加了,就缓解了正负样本不均衡的问题。
- Eliminate_grid sensitivity

; CIoU-loss
之前的YOLO v2,YOLO v3在计算geo_loss时都是用的MSE Loss,之后人们开始使用IoU Loss。后来IoU有了更多的改进详解IoU、GIoU、DIoU、CIoU、EIoU:
所以最终的演化过程是:
MSE Loss >>> IoU Loss >>> GIoU Loss >>> DIoU Loss >>> CIoU Loss
五个基本组件
Yolov4的五个基本组件:
- CBM:Yolov4网络结构中的最小组件,由+Conv+Bn+Mish激活函数三者组成。
- CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
- Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
- CSPX:借鉴CSPNet网络结构,由三个卷积层和X个Res unint模块Concate组成。
- SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
损失函数

; YOLOv5
论文题目:TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios
论文地址:https://arxiv.org/abs/2108.11539
改进
检测头的改进:
head部分没有任何改动,和yolov3和yolov4完全相同,也是三个输出头,stride分别是8,16,32,大输出特征图检测小物体,小输出特征图检测大物体。
但采用了自适应anchor,而且这个功能还可以手动打开/关掉,具体是什么意思呢?
加上了自适应anchor的功能,个人感觉YOLO v5其实变成了2阶段方法。
先回顾下之前的检测器得到anchor的方法:
Yolo v2 v3 v4:聚类得到anchor,不是完全基于anchor的,w,h是基于anchor的,而x,y是基于grid的坐标,所以人家叫location prediction。
之前anchor是固定的,自适应anchor利用网络的学习功能,让 ( x A , y A , w A , h A ) (x_A,y_A,w_A,h_A)(x A ,y A ,w A ,h A ) 也是可以学习的。
五个基本组件
Yolov5的基本组件:
- Focus:基本上就是YOLO v2的passthrough。
- CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
- CSP1_X:借鉴CSPNet网络结构,由三个卷积层和X个Res unint模块Concate组成。
- CSP2_X:不再用Res unint模块,而是改为CBL。
- SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合,如图13所示。
提特征的网络变短了,速度更快。
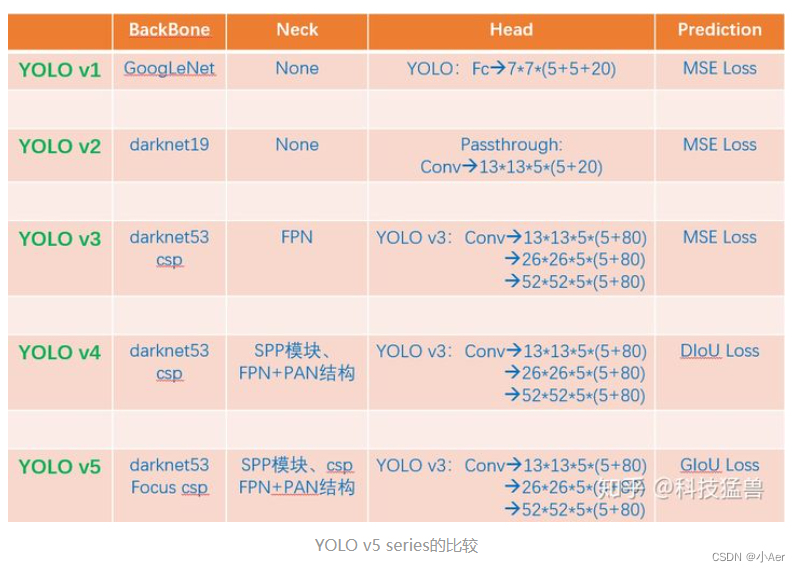
YOLO对比
这里引用知乎大佬的图片吧(文中也引用了,在最后链接都给出了)
; Inference
[0] https://blog.csdn.net/andyjkt/article/details/108582515
[1] https://blog.csdn.net/qq_28949847/article/details/106329569?spm=1001.2014.3001.5506
[2] https://blog.csdn.net/gaoyu1253401563/article/details/86485851
[3] SSD-https://blog.csdn.net/ytusdc/article/details/86577939
[4] YOLOv1-v3
[5] 你一定从未看过如此通俗易懂的YOLO系列(从v1到v5)模型解读 (上)
[6] 你一定从未看过如此通俗易懂的YOLO系列(从v1到v5)模型解读 (中)
[7] 你一定从未看过如此通俗易懂的YOLO系列(从v1到v5)模型解读 (下)
Original: https://blog.csdn.net/qq_41542989/article/details/124414859
Author: 小Aer
Title: 目标检测的进阶-one stage
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/687424/
转载文章受原作者版权保护。转载请注明原作者出处!