

Unknown-Aware Object Detection: Learning What You Don’t Know from Videos in the Wild
- 1. Motivation
- 2. Overview of the object detection framework
* - 2.1 Spatial-Temporal Unknown Distillation
– - 2.2 Unknown-Aware Training Objective
– - 3. Experiments
Paper: https://arxiv.org/abs/2203.03800
Code: https://github.com/deeplearning-wisc/stud
- Motivation
在本文中,作者提出了一种新的未知感知目标检测框架,该框架通过时空未知提取(STUD)从野外视频中提取未知对象,并有意义地正则化模型的决策边界。视频数据自然地捕获了模型运行的开放世界环境,并封装了已知和未知对象的混合物;见图1(b)。例如,建筑物和树木(OOD)可能会出现在驾驶视频中,尽管它们没有明确标注用于培训车辆和行人的物体检测器(ID)。我们的方法类似于化学中的蒸馏概念,即”从混合物中分离物质的过程”[46]。虽然经典的目标检测模型主要使用标记的已知对象进行训练,但我们试图通过联合优化目标检测和OOD检测性能,利用未知对象进行模型正则化。
简单来说,就是为了识别出训练数据中没有标注的目标,将这些未在数据集中出现的目标记为OOD,从而解决误报的问题。
- Overview of the object detection framework
具体地说,我们的框架由两部分组成,解决了 (1)从视频中提取各种未知对象 和 (2)用提取的未知对象正则化对象检测器的挑战。为了解决第一个问题,
我们介绍了一种新的时空未知提取方法,它可以自动构造各种未知对象(第3.1节)。在空间维度上,对于一帧中的每个ID对象,我们基于OOD度量识别参考帧中的未知对象候选。然后,我们通过线性组合特征空间中的选定对象,并通过相异度度量进行加权,来提取未知对象。因此,提取出的未知对象在多个对象上的分布比使用单个对象时更为多样。在时间维度上,我们提出了从多个视频帧中聚集未知对象,从而捕获时间维度上额外的未知多样性。
利用提取的未知对象,我们进一步采用未知感知训练目标(第3.2节)。与普通的对象检测不同,我们用正则化来训练对象检测。我们的正则化有助于学习ID和OOD对象之间更保守的决策边界,这有助于在推理过程中标记不可见的OOD对象。为了实现这一点,正则化对比塑造了不确定性表面,从而为ID对象产生更大的概率分数,反之亦然,从而在测试中实现有效的OOD检测。


; 2.1 Spatial-Temporal Unknown Distillation
2.1.1 Spatial unknown distillation
在空间维度上,对于给定帧中的每个ID对象,我们通过参考帧中对象特征的线性组合,通过相异度度量加权,创建未知的对应对象。与使用单个对象相比,使用多个对象捕获的未知量分布更为多样。STUD对提案生成器的特征输出进行操作,以计算相异性。具体地,我们考虑在时间戳T 0 T_0 T 0 和T 1 T_1 T 1 上的一对帧X 0 X_0 X 0 、X 1 X_1 X 1 ,分别指定指定的关键帧和参考帧。对于对象(x,b),我们将其特征表示为h(x,b)∈ Rm,其中m是特征尺寸。我们收集了一组对象特征h ( x 0 , b i ) i = 1 N 0 {h(x_0,b_i)}{i=1}^{N_0}h (x 0 ,b i )i =1 N 0 和h ( x 1 , b j ) j = 1 N 1 {h(x_1,b_j)}{j=1}^{N_1}h (x 1 ,b j )j =1 N 1 ,其客观性得分高于阈值。我们使用两个特征之间的L2距离进行相异性测量:

其中,h ˆ ( x 0 , b i ) hˆ(x_0,b_i)h ˆ(x 0 ,b i )和h ˆ ( x 1 , b j ) hˆ(x_1,b_j)h ˆ(x 1 ,b j )是小网络使用对象特征h(x,b)作为输入获得的编码特征向量。在我们的实验中,编码器由两个内核大小为3×3的卷积层和一个平均池层组成。s i , j s_{i,j}s i ,j 越大,物体特征越不相似。相异性测量结果如图3所示。参考框架中的OOD对象,如路灯和广告牌,具有更显著的差异性。

最后,我们对x 1 x_1 x 1 帧的对象特征进行加权平均。使用多个对象可以捕获未知量的不同分布。权重α定义为不相似性得分的归一化指数:
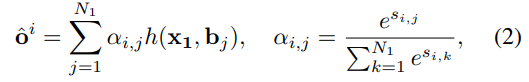
其中o i o^{i}o i是(在特征空间中)提取的未知对象,对应于第x 0 x_0 x 0 帧处的第i个对象。
; 2.1.2 Temporal unknown distillation
我们的空间未知提取机制在单个参考帧上运行,可以扩展到多个视频帧来捕获时间维度中未知的额外多样性。例如,考虑在高速公路上行驶的汽车的视频,我们观察到更多的帧,可以观察到更多未知的物体,例如树木、建筑物和岩石。
给定时间戳t 0 t_0 t 0 处的帧x 0 x_0 x 0 ,我们建议从多个帧中提取未知对象x 1 , . . . . , x T x_1, …., x_T x 1 ,….,x T 。我们在[ t 0 − R 、 t 0 + R ] [t_0 – R、 t_0+R][t 0 −R 、t 0 +R ]范围内随机抽样T帧 。作为一种特殊情况,T=1降低到之前的对帧设置。为了提取时空未知对象,我们将T帧中的对象特征向量连接起来,然后通过方程(1)测量它们与x 0 x_0 x 0 帧中对象的相异度。对于第x 0 x_0 x 0 帧中的第i个对象,未知对应物定义如下:

式中,α i , j α_{i,j}αi ,j 表示方程式2中定义的归一化不相似性分数。
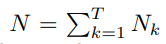
在第4.3节的后面,我们提供了关于帧采样范围R和所选帧数T的综合消融研究,并展示了时间聚集对改进OOD检测的好处。
2.1.3 Unknown candidate object selection
未知蒸馏的一个关键步骤是过滤参考帧x 1 x_1 x 1 中可能是ID对象或简单背景的未知。如果没有选择,模型可能会被混淆,从而将提取出的未知对象从ID对象中分离出来,或者在训练过程中快速记忆简单的OOD模式。为了防止这种情况发生,我们根据能量分数对提议进行预过滤,然后将选定的提议用于时空未知蒸馏。研究表明,在图像分类中,能量分数是一个有效的OOD数据指标[36]。为了计算目标检测网络的能量分数,我们将目标特征h ( x 1 , b j ) j = 1 N 1 {h(x_1,b_j)}^{N1}{j=1}h (x 1 ,b j )j =1 N 1 提供给预测头,并遵循以下定义:
式中f k ( h ( x 1 , b j ) ; w p r e d ) f_k(h(x_1, b_j);w{pred})f k (h (x 1 ,b j );w p r e d )是k-way分类分支的logit输出。更高的能量意味着更多的活力,反之亦然。然后,我们选择能量分数较低的物体,即所有物体中的百分位限制于 p% ≤Rank(E(x1, bj ))/N1 ≤ q% 。如果有多个帧x 1 x_1 x 1 、x 2 x_2 x 2 …,x T x_T x T ,在时间聚集之前,在每个单独的帧上执行对象选择。第4.3节提供了关于能量过滤效果和选择百分比的消融研究。
; 2.2 Unknown-Aware Training Objective
利用第3.1节中提取的未知对象,我们现在介绍未知感知对象检测的培训目标。我们的关键思想是在执行目标检测任务的同时,对模型进行正则化,以便为ID对象生成较低的不确定性分数,为未知对象生成较高的不确定性分数。总体目标函数定义为:

式中,β是结合检测损失L d e t L_{det}L d e t 和不确定度正则化损失L u n L_{un}L u n 确定性时的标度权重。接下来,我们将详细介绍这一点。
2.2.1 Uncertainty regularization
继Du等人[8]之后,我们采用了一个损失函数,对比塑造了不确定性表面,放大了已知ID对象和未知OOD对象之间的可分性。为了测量不确定性,我们使用等式(4)中的能量分数,该分数来自分类分支的输出。这里,我们计算ID对象和提取的未知对象特征E ( o ˆ ) E(oˆ)E (o ˆ)的能量分数E ( x , b ) E(x,b)E (x ,b )。然后将不确定性得分传递到具有权重系数θu的logistic回归分类器中,该分类器预测ID对象( x , b ) (x,b)(x ,b )的高概率和未知对象o ˆ oˆo ˆ的低概率。正则化损失计算如下:

其中O包含所有未知物体特征(c.f.第3.1节)。在图4(a)中,我们展示了Youtube VIS数据集上训练过程中的不确定性正则化和不确定性[66]。收敛后,图4(b)显示ID和提取的未知对象的能量分数分布。 这表明STUD可以正确收敛,并且能够分离提取的未知对象和ID对象。

与普通对象检测器的L d e t L_det L d e t相比,我们的损失旨在帮助学习ID和OOD对象之间更保守的决策边界,这有助于在测试中标记未看到的OOD对象。我们继续描述测试时间OOD检测程序。
; 2.2.2 Test-time OOD detection
在推理过程中,我们使用逻辑回归不确定性分支的输出进行OOD检测。特别是,给定一个测试输入x,对象检测器产生一个框预测b。预测对象(x, b)的不确定性得分由下式给出:

对于OOD检测,我们使用通用阈值机制来区分ID和OOD对象:

选择阈值γ通常是为了正确分类大部分ID数据(例如95%)。对于分类为ID的对象,可以像往常一样使用预测头获得边界框和类预测。我们的方法总结在算法1中。

2.2.3 Synergy between unknown distillation and contrastive regularization
未知蒸馏(第3.1节)和对比正则化(第3.2节)的两个关键组成部分协同工作。首先,一组经过充分提取的未知对象可以改进基于能量的对比正则化,并帮助学习已知和未知对象之间更准确的决策边界。其次,由于对比不确定性损失扩大了已知和未知对象之间的能量差距,未知蒸馏模块可以从更准确的未知对象选择中受益(通过基于能量的过滤)。当这两个部分的表现令人满意时,整个训练过程就会收敛。
- Experiments


Original: https://blog.csdn.net/mary_0830/article/details/123477761
Author: Liaojiajia-2020
Title: CVPR2022 | 论文阅读—Unknown-Aware Object Detection: Learning What You Don’t Know from Videos in the Wild
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/686429/
转载文章受原作者版权保护。转载请注明原作者出处!