

标题 TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head forObject Detection on Drone-captured Scenarios
发表时间 2021
期刊 IEEE/CVF International Conference on Computer Vision (ICCV) Workshops
作者 Xingkui Zhu, Shuchang Lyu, Xu Wang, Qi Zhao(北航)
介绍


提出了一种基于 YOLOv5 [21] 的改进模型 TPH-YOLOv5 来解决上述三个问题。使用 TPHYOLOv5 的检测流水线概览如图 2 所示。我们分别使用 CSPDarknet53 [52, 2] 和路径聚合网络 (PANet [33]) 作为 TPH-YOLOv5 的骨干和颈部,沿用了原始版本。在头部部分,我们首先引入一个用于微小物体检测的头部。 TPH-YOLOv5 总共包含四个检测头,分别用于检测微小、小型、中型、大型物体。然后,我们用 Transformer Prediction Heads (TPH) [7, 49] 替换原始预测头,以探索预测潜力。为了在大覆盖的图像中找到注意区域,我们采用卷积块注意模块(CBAM [54])沿通道和空间维度顺序生成注意图。与 YOLOv5 相比,我们改进的 TPH-YOLOv5 可以更好地处理无人机拍摄的图像。
为了进一步提高 TPH-YOLOv5 的性能,我们采用了 bag of tricks(图 2)。具体来说,我们在训练过程中采用了数据增强,这促进了对图像中物体尺寸急剧变化的适应。我们还在推理过程中添加了多尺度测试(ms-testing)和多模型集成策略,以获得更有说服力的检测结果。此外,通过对故障案例的可视化,我们发现我们提出的架构具有出色的定位能力,但分类能力较差,尤其是在”三轮车”和”雨篷-三轮车”等一些相似类别上。为了解决这个问题,我们提供了一个自训练分类器(ResNet18 [17]),使用从训练数据中裁剪的图像块作为分类训练集。使用自训练分类器,我们的方法在 AP 值上有 0.8%∼1.0% 的改进。
我们的贡献如下:
• 我们增加了一个预测头来处理对象的大规模方差。
• 我们将Transformer Prediction Heads (TPH) 集成到YOLOv5 中,可以准确定位高密度场景中的对象。
• 我们将CBAM 集成到YOLOv5 中,这可以帮助网络在具有大区域覆盖的图像中找到感兴趣的区域。
• 我们为无人机捕获场景中的对象检测任务提供有用的技巧包并过滤一些无用的技巧。
• 我们使用自训练分类器来提高对一些混淆类别的分类能力。
• 在 VisDrone2021 测试挑战数据集上,我们提出的 TPH-YOLOv5 达到 39.18% (AP),比 DPNetV3(之前的 SOTA 方法)高出 1.81%。在 VisDrone2021 DET 挑战赛中,TPH-YOLOv5 获得第 5 名,与第 1 名机型相比差距较小。
; 网络结构
TPH-YOLOv5 的框架如图 3 所示。我们修改了原始的 YOLOv5,使其专门用于 VisDrone2021 数据集。

(1)微小物体的预测头。
我们研究了 VisDrone2021 数据集,发现它包含许多非常小的实例,因此我们增加了一个预测头来检测微小物体。结合其他三个预测头,我们的四头结构可以缓解剧烈的物体尺度变化带来的负面影响。如图 3 所示,我们添加的预测头(head No.1)是从对微小物体更敏感的低级高分辨率特征图生成的。添加一个额外的检测头后,虽然计算和内存成本增加,但微小物体检测的性能得到了很大的提升。
(2)变压器编码器块。
受vision transformer的启发,我们用transformer编码器块替换了原始版本 YOLOv5 中的一些卷积块和 CSP 瓶颈块。结构如图 4 所示。与 CSPDarknet53 中的原始瓶颈块相比,我们认为 Transformer 编码器块可以捕获全局信息和丰富的上下文信息。每个转换器编码器包含两个子层。第一个子层是一个多头注意力层,第二个(MLP)是一个全连接层。每个子层之间使用残差连接。 Transformer 编码器块增加了捕获不同本地信息的能力。它还可以通过自我注意机制探索特征表示潜力[50]。在 VisDrone2021 数据集上,transformer 编码器块在高密度遮挡对象上具有更好的性能。
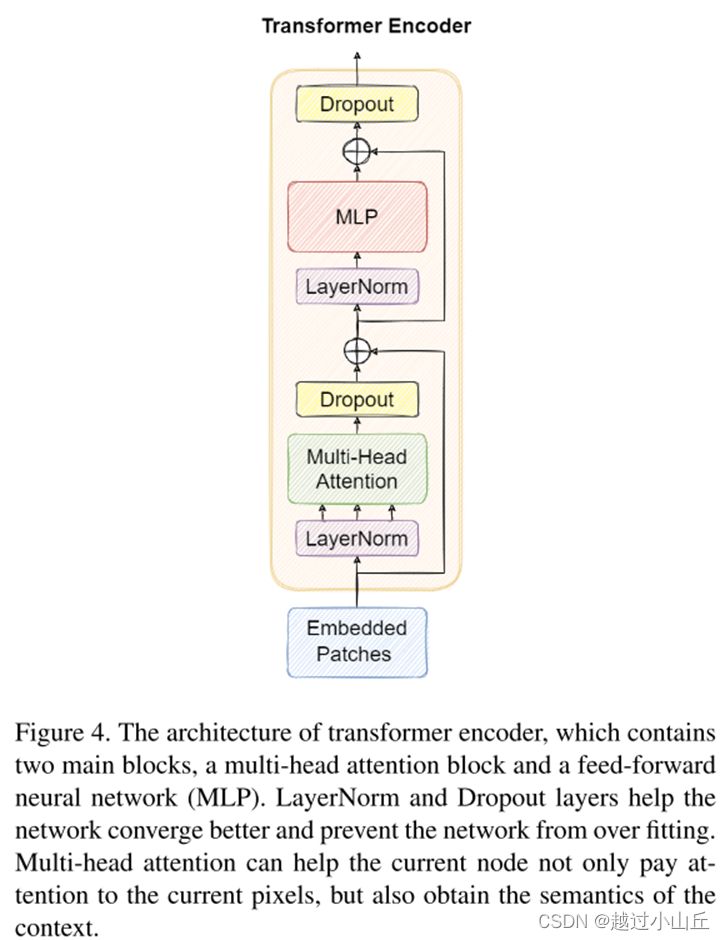
(Transformer 编码器的架构,它包含两个主要块,一个多头注意力块和一个前馈神经网络 (MLP)。 LayerNorm 和 Dropout 层有助于网络更好地收敛并防止网络过度拟合。多头注意力可以帮助当前节点不仅关注当前像素,还可以获取上下文的语义。)
基于 YOLOv5,我们只在头部应用了 Transformer 编码器块来形成 Transformer Prediction Head (TPH) 和主干的末端。因为网络末端的特征图分辨率低。在低分辨率特征图上应用 TPH 可以降低昂贵的计算和内存成本。此外,当我们扩大输入图像的分辨率时,我们可以选择在早期层移除一些 TPH 块以使训练过程可用。
(3)卷积块注意模块(CBAM)。
CBAM [54] 是一个简单但有效的注意力模块。它是一个轻量级模块,可以集成到大多数著名的 CNN 架构中,并且可以以端到端的方式进行训练。给定一个特征图,CBAM 沿通道和空间两个独立维度依次推断注意力图,然后将注意力图与输入特征图相乘以执行自适应特征细化。 CBAM模块的结构如图5所示。根据论文[54]中的实验,在不同的分类和检测数据集上将CBAM集成到不同的模型中后,模型的性能得到了很大的提高,这证明了本模块的有效性。在无人机拍摄的图像上,大面积的覆盖区域总是包含令人困惑的地理元素。使用 CBAM 可以提取注意力区域,帮助 TPH-YOLOv5 抵抗混乱的信息,专注于有用的目标对象。
(4)MS-测试和模型集成。
我们根据模型集成的不同视角训练了五种不同的模型。在推理阶段,我们首先对单个模型执行 ms-testing 策略。 ms-testing的实现细节是以下三个步骤。 1)将测试图像缩放到1.3倍。 2)将图像分别缩小到1倍、0.83倍、0.67倍。 3)水平翻转图像。最后,我们将六幅不同尺度的图像输入 TPH-YOLOv5,并使用 NMS 融合测试预测。在不同的模型上,我们执行相同的 ms-testing 操作,并通过 WBF 融合最后五个预测得到最终结果。
(5)自训练分类器。
在使用 TPH-YOLOv5 训练 VisDrone2021 数据集后,我们测试了 test-dev 数据集,然后通过可视化失败案例分析结果,得出 TPH-YOLOv5 具有出色的定位能力但分类能力较差的结论。我们进一步探索了如图 6 所示的混淆矩阵,并观察到诸如三轮车和雨篷-三轮车等一些困难类别的精度非常低。因此,我们提出了一个额外的自训练分类器。首先,我们通过裁剪真实边界框并将每个图像块的大小调整为 64×64 来构建训练集。然后我们选择 ResNet18 [17] 作为分类器网络。如实验结果所示,在这种自训练分类器的帮助下,我们的方法在 AP 值上得到了大约 0.8%~1.0% 的改进。

在IOU阈值为0.45,置信度阈值为0.25的情况下,建立混淆矩阵。
结果



; 代码
https://github.com/cv516Buaa/tph-yolov5
Original: https://blog.csdn.net/qq_38766127/article/details/126934229
Author: 越过小山丘
Title: TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head forObject Detection on Drone-captur
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/686419/
转载文章受原作者版权保护。转载请注明原作者出处!