

引言
原文连接:GoogLeNet
为了提升网络的性能可以选择增加网络深度和宽度,问题:
- 导致带来 大量的参数
- 较深的网络需要 更多的数据,容易产生 过拟合现象
- 增加网络的深度 也容易带来 梯度消失现象
·
网络创新:
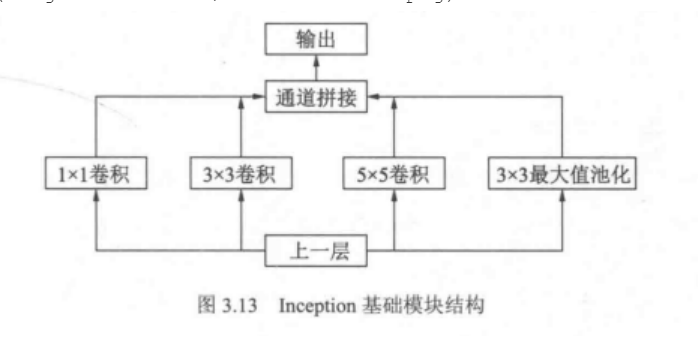
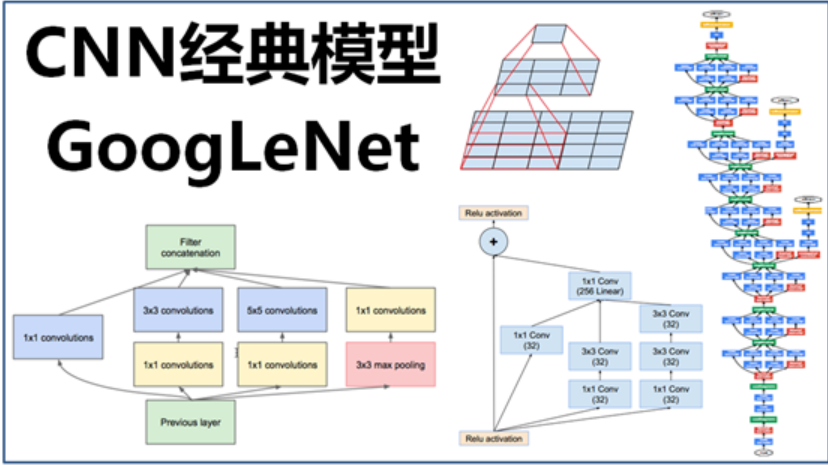
局部特征结构:inception模块
- 对特征并行地执行多个大小不同的卷积和池化运算,最后拼接到一起。
- 优点:
1 * 1 3*3 5 * 5 卷积运算对应不同的特征图区域,可以得到更好的图像表征信息 - 注意:每个分支所得的特征矩阵高和宽必须相同
初级:

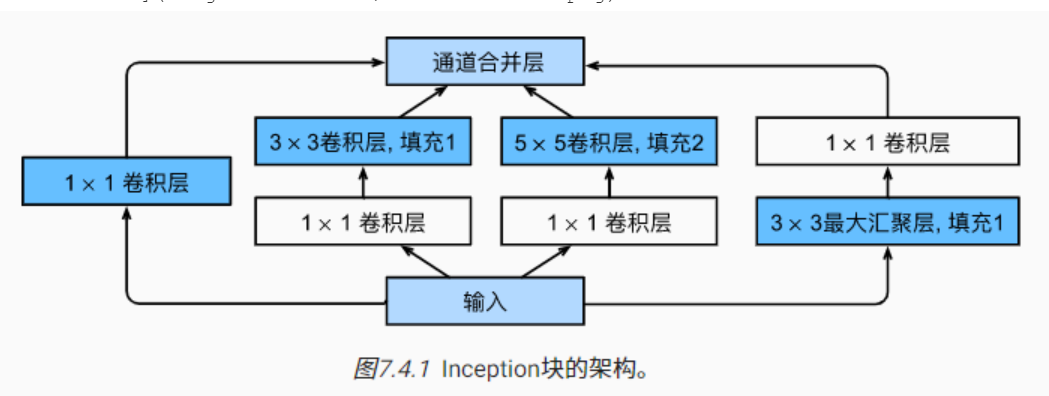
改进inception v1:
- 运用到了多个1 * 1的卷积模块
- inception v1的参数量是AlexNet 的1/12 , VGGNet的1/3 ,适合处理大规模的数据
inception.py
import torch
from torch import nn
from torch.nn.functional import relu
class BasicConv2d(nn.Module):
'''定义一个conv2d和Relu的基础卷积类'''
def __init__(self,in_channels,out_channels,kernel_size,padding):
super(BasicConv2d,self).__init__()
self.conv = nn.Conv2d(in_channels,out_channels,kernel_size,padding)
def forward(self,x):
x = self.conv(x)
x = relu(x,inplace=True)
return x
class Inceptionv1(nn.Module):
"""初始化时需要提供各个子模块的通道数的大小"""
def __init__(self,in_dim,hid_1_1,hid_2_1,hid_2_3,hid_3_1,out_3_5,out_4_1):
super(Inceptionv1,self).__init__()
#分别定义四个子模块的网络
self.branch1X1 = BasicConv2d(in_channels=in_dim,out_channels=hid_1_1,kernel_size=1)
self.branch3X3 = nn.Sequential(
BasicConv2d(in_channels=in_dim,out_channels=hid_2_1,kernel_size=1),
BasicConv2d(in_channels=hid_2_1,out_channels=hid_2_3,kernel_size=3,padding=1)
)
self.branch5X5 = nn.Sequential(
BasicConv2d(in_channels=in_dim,out_channels=hid_3_1,kernel_size=1),
BasicConv2d(in_channels=hid_3_1,out_channels=out_3_5,kernel_size=5,padding=2)
)
self.branch_pool = nn.Sequential(
nn.MaxPool2d(kernel_size=3,stride=1,padding=1),
BasicConv2d(in_channels=in_dim,out_channels=out_4_1,kernel_size=1)
)
def forward(self,x):
p1 = self.branch1X1(x)
p2= self.branch3X3(x)
p3 = self.branch5X5(x)
p4 = self.branch_pool(x)
#将四个模块按通道的维度进行拼接
outputs = torch.cat((p1,p2,p3,p4),dim=1)
return outputs
net = Inceptionv1(3,64,32,64,64,96,32)
print(net)
inputsize = torch.randn(1,3,256,256)
print(inputsize.size())
output = net(inputsize)
print(output.size())
输出结构:
Inceptionv1(
#使用1x1的卷积 输出通道64
(branch1X1): BasicConv2d(
(conv): Conv2d(3, 64, kernel_size=(1, 1), stride=(1, 1))
)
#1x1 和 3x3 输出通道64
(branch3X3): Sequential(
(0): BasicConv2d(
(conv): Conv2d(3, 32, kernel_size=(1, 1), stride=(1, 1))
)
(1): BasicConv2d(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
#1x1 5x5 输出通道96
(branch5X5): Sequential(
(0): BasicConv2d(
(conv): Conv2d(3, 64, kernel_size=(1, 1), stride=(1, 1))
)
(1): BasicConv2d(
(conv): Conv2d(64, 96, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
)
)
#最大池化 输出通道32
(branch_pool): Sequential(
(0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(1): BasicConv2d(
(conv): Conv2d(3, 32, kernel_size=(1, 1), stride=(1, 1))
)
)
)
torch.Size([1, 3, 256, 256])
#输出通道是输入通道的和 256 = 64+64+96+32
torch.Size([1, 256, 256, 256])
进程已结束,退出代码0
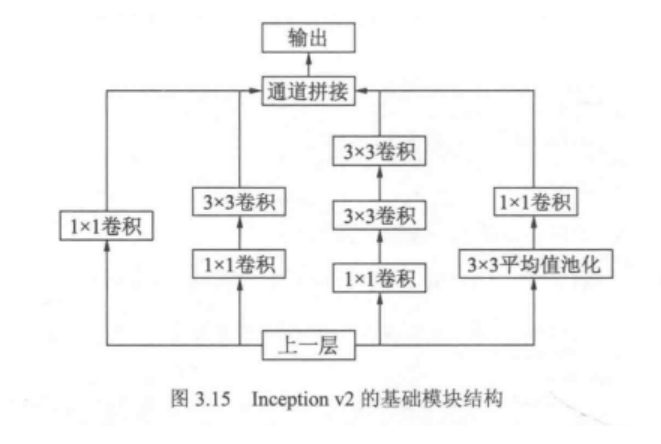
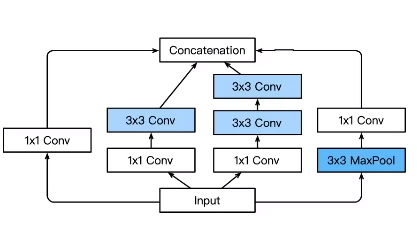
inception v2
改进:
- 卷积分解和正则化实现更高效的计算,增加BN层
- 使用两个3×3的卷积代替一个5 x 5卷积,减少参数,提高网络的非线性能力(学习能力)
默认的输入通道为192
Inceptionv3:
- 增加RMSProp优化器,在辅助的分类器部分增加了7*7卷积
- 使用了标签平滑技术
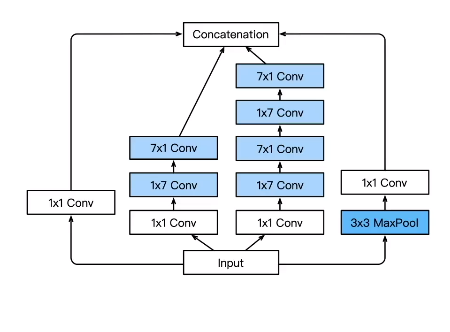
inceptionv4:
- 加入resnet
1 * 1的卷积模块
优点:
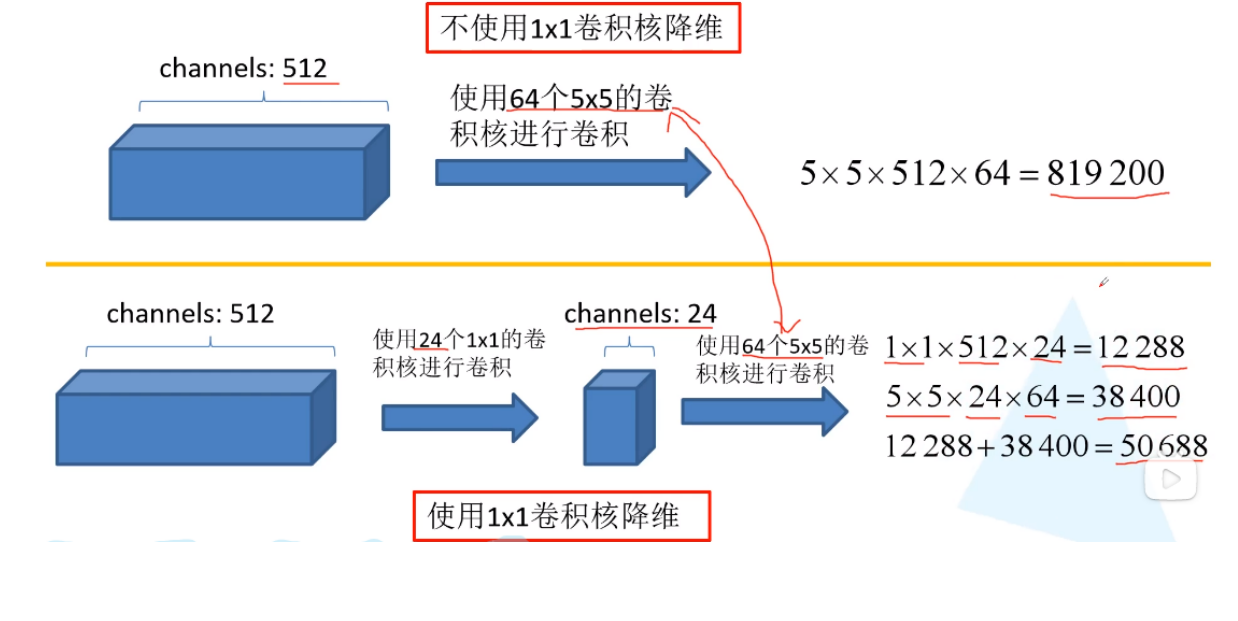
- 可以先将特征图降为,再传送给3 * 3 5 * 5 的大小卷积核,由于通道数降低,参数也有了较大的减少
- 实现了降维的思想
辅助分类器

作用:防止梯度消失
为了 避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度(辅助分类器)
辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益。而在实际测试的时候,这两个额外的softmax会被去掉。

网络模型
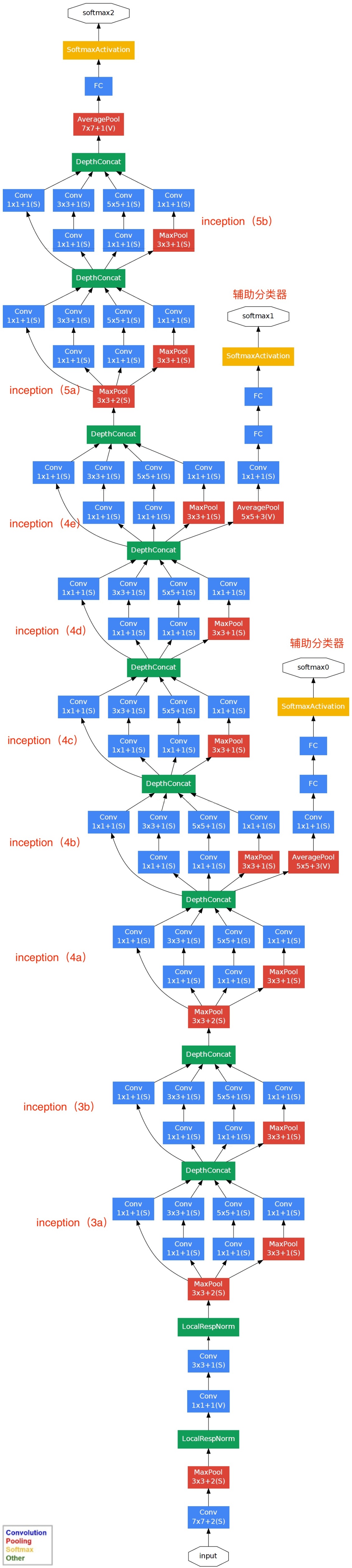
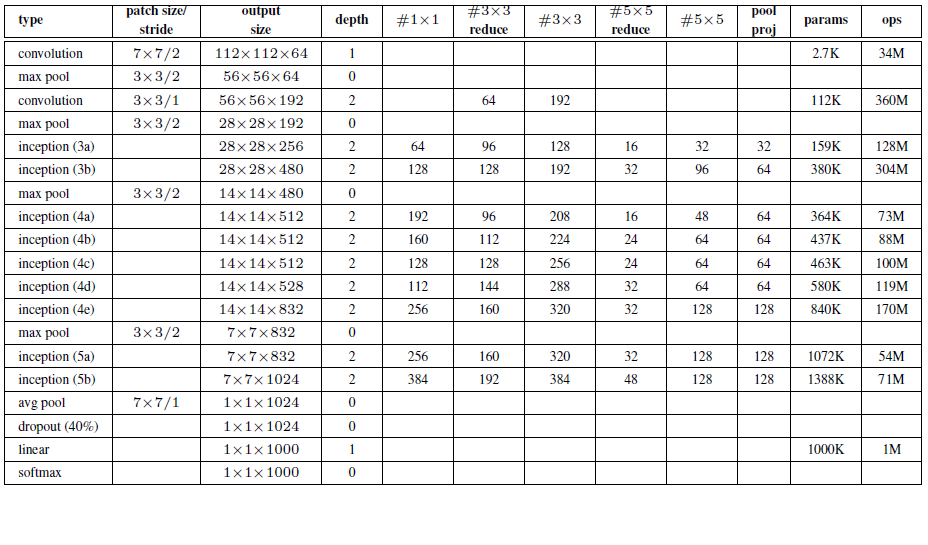
注:上表中的”#3×3 reduce”,”#5×5 reduce”表示在3×3,5×5卷积操作之前使用了1×1卷积的数量
代码实现
import torch
from torch import nn
from torch.nn.functional import relu
import torch.nn.functional as F
from inception_v1 import Inceptionv1 ,BasicConv2d
class GoogLeNet(nn.Module):
def __init__(self,aux_add = False,class_num =1000,init_weight = False):
super(GoolLeNet, self).__init__()
self.aux_add = aux_add
#input batch*3*244*244 output 112*112
self.conv1 = BasicConv2d(in_channels=3,out_channels=64,kernel_size=7,stride=2,padding=3) # (224-7+2*p)/2+1 = 112 向下取整
self.maxpool1 = nn.MaxPool2d(kernel_size=3,stride=2,ceil_mode=True)
self.conv2 = BasicConv2d(in_channels=64,out_channels=192,kernel_size=1) #output 56*56
self.conv3 = BasicConv2d(in_channels=64, out_channels=192, kernel_size=3, padding=1) # output 56*56
self.maxpool2 = nn.MaxPool2d(kernel_size=3,stride=2)
self.inception3a = Inceptionv1(in_dim = 192,hid_1_1=64 ,hid_2_1=96,hid_2_3=128,hid_3_1=16,out_3_5=32,out_4_1=32)
self.inception3b = Inceptionv1(in_dim = 256,hid_1_1=128 ,hid_2_1=128,hid_2_3=192,hid_3_1=32,out_3_5=96,out_4_1=64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3,stride=2)
self.inception4a = Inceptionv1(in_dim=480,hid_1_1=192 ,hid_2_1=96,hid_2_3=208,hid_3_1=16,out_3_5=48,out_4_1=64)
self.inception4b = Inceptionv1(in_dim=512, hid_1_1=160, hid_2_1=112, hid_2_3=244, hid_3_1=24, out_3_5=64,out_4_1=64)
self.inception4c = Inceptionv1(in_dim=512, hid_1_1=128, hid_2_1=128, hid_2_3=256, hid_3_1=24, out_3_5=64, out_4_1=64)
self.inception4d = Inceptionv1(in_dim=512, hid_1_1=256, hid_2_1=160, hid_2_3=320, hid_3_1=32, out_3_5=128,out_4_1=128)
self.inception4e = Inceptionv1(in_dim=528, hid_1_1= 256, hid_2_1=160, hid_2_3=320, hid_3_1=32, out_3_5=128, out_4_1=128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3,stride=2)
self.inception5a = Inceptionv1(in_dim=832,hid_1_1=256 ,hid_2_1=160,hid_2_3=320,hid_3_1=32,out_3_5=128,out_4_1=128)
self.inception5a = Inceptionv1(in_dim=832, hid_1_1=256, hid_2_1=160, hid_2_3=320, hid_3_1=32, out_3_5=128,out_4_1=128)
if self.aux_add:
self.aux1 = InceptionAux(512,class_num)
self.aux2 = InceptionAux(528,class_num)
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.dropout = nn.Dropout(p=0.4) #0.4的效果更好
self.fc = nn.Linear(1024,class_num)
if init_weight:
self._initialize_weights()
def forward(self,x):
#Nx3x244x244
x = self.conv1(x)
#Nx64x12x112
x = self.maxpool1(x)
#Nx64x56x56
x = self.conv2(x)
#Nx64x56x56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(X)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_add: # eval model lose this layer
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_add: # eval model lose this layer
return x, aux2, aux1
return
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
class InceptionAux(nn.Module):
def __init__(self,in_channel,class_num):
super(InceptionAux,self).__init__
self.averagePool = nn.AvgPool2d(kernel_size=5,stride=3)
# output[batch, 128, 4, 4]
self.conv1 = nn.Conv2d(in_channels=in_channel,out_channels=128,kernel_size=1,stride=1)
self.fc1 = nn.Linear(2048,1024)
self.fc2 = nn.Linear(1024,class_num)
def forward(self,x):
# inception_4a aux1: N x 512 x 14 x 14, inception_4b aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv1(x)
# N x 128 x 4 x 4
x = torch.flatten(x,1)
x = nn.Dropout(x, 0.5, training=self.training) #在训练时设为training,在测试时为False就是model.train()和model.eval()
# N*2048
x = relu(self.fc1(x),inplace=True)
x = nn.Dropout(x,0.5,training = self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
- (2)网络最后采用了average pooling(平均池化)来代替全连接层,该想法来自NIN(Network in Network),事实证明这样可以将准确率提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便对输出进行灵活调整;
- (3)虽然移除了全连接,但是网络中依然使用了Dropout ;
总结
沐:
- GoogLeNet一共使用 9个Inception块和 全局平均汇聚层的堆叠来生成其估计值
- Inception块之间的 最大汇聚层可降低维度
- 添加两个辅助分类器帮助训练
- Inception块的组合从VGG继承, 全局(平均池化层)避免了在最后使用全连接层。 大大减少模型参数
- Inception块相当于一个有4条路径的子网络。它通过 不同窗口形状的卷积层和最大汇聚层来并行抽取信息,并使用1×1卷积层减少每像素级别上的通道维数从而 降低模型复杂度。
- GoogLeNet将多个设计精细的Inception块与其他层(卷积层、全连接层)串联起来。其中Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得来的。
- GoogLeNet和它的后继者们一度是ImageNet上最有效的模型之一:它以较低的计算复杂度提供了类似的测试精度。
500问:
- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着 不同尺度特征的融合;
- 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
- 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3×3和5×5卷积的比例也要增加。但是,使用5×5的卷积核仍然会带来巨大的计算量。 为此,文章借鉴NIN2,采用1×1卷积核来进行降维。
参考链接:
https://blog.csdn.net/baidu_36913330/article/details/120017994
Original: https://blog.csdn.net/ADAS_CHEN/article/details/124234289
Author: Stephen-Chen
Title: 【pytorch图像分类】GoogLeNet网络结构
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/686377/
转载文章受原作者版权保护。转载请注明原作者出处!