

目录
前言
贡献/特点:
- 端到端:去除NMS和anchor,没有那么多的超参,计算量也大大减少,整个网络变得很简单;
- 基于Transformer:首次将Transformer引入到目标检测任务当中;
- 提出一种全新的基于集合的损失函数:通过二分图匹配的方法强制模型输出一组独一无二的预测框,每个物体只会产生一个预测框,这样就将目标检测问题直接转换为集合预测的问题,所以才不用nms,达到端到端的效果;
- 而且在decoder输入一组可学习的object query和encoder输出的全局上下文特征,直接以并行方式强制输出最终的100个预测框,替代了anchor;
- 缺点:对大物体的检测效果很好,但是对小物体的检测效果不好;训练起来比较慢;
- 优点:在COCO数据集上速度和精度和Faster RCNN差不多;可以扩展到很多任务中,比如分割、追踪、多模态等;
一、整体架构


- 图片输入,首先经过一个CNN网络提取图片的局部特征;
- 再把特征拉直,输入Transformer Encoder中,进一步学习这个特征的全局信息。经过Encoder后就可以计算出没一个点或者没一个特征和这个图片的其他特征的相关性;
- 再把Encoder的输出送入Decoder中,并且这里还要输入Object Query,限制解码出100个框,这一步作用就是生成100个预测框;
- 预测出的100个框和gt框,通过二分图匹配的方式,确定其中哪些预测框是有物体的,哪些是没有物体的(背景),再把有物体的框和gt框一起计算分类损失和回归损失;推理的时候更简单,直接对decoder中生成的100个预测框设置一个置信度阈值(0.7),大于的保留,小于的抑制;
; 二、基于集合预测的损失函数
2.1、二分图匹配确定有效预测框
预测得到N(100)个预测框,gt为M个框,通常N>M,那么怎么计算损失呢?
这里呢,就先对这100个预测框和gt框进行一个二分图的匹配,先确定每个gt对应的是哪个预测框,最终再计算M个预测框和M个gt框的总损失。
其实很简单,假设现在有一个矩阵,横坐标就是我们预测的100个预测框,纵坐标就是gt框,再分别计算每个预测框和其他所有gt框的cost,这样就构成了一个cost matrix,再确定把如何把所有gt框分配给对应的预测框,才能使得最终的总cost最小。
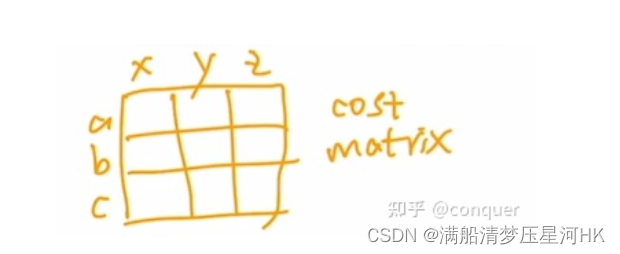
这里计算的方法就是很经典的匈牙利算法,通常是调用scipy包中的linear_sum_assignment函数来完成。这个函数的输入就是cost matrix,输出一组行索引和一个对应的列索引,给出最佳分配。
匈牙利算法通常用来解决二分图匹配问题,具体原理可以看这里: 二分图匈牙利算法的理解和代码 和 算法学习笔记(5):匈牙利算法
所以通过以上的步骤,就确定了最终100个预测框中哪些预测框会作为有效预测框,哪些预测框会称为背景。再将有效预测框和gt框计算最终损失(有效预测框个数等于gt框个数)。
; 2.2、损失函数
损失函数:分类损失+回归损失
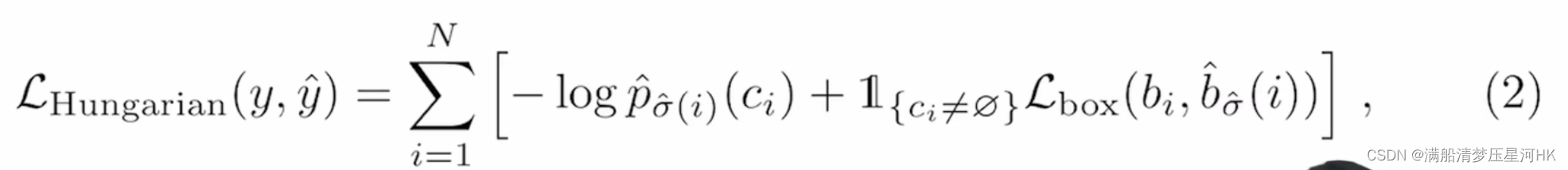
分类损失:交叉熵损失,去掉log
回归损失:GIOU Loss + L1 Loss
三、前向推理
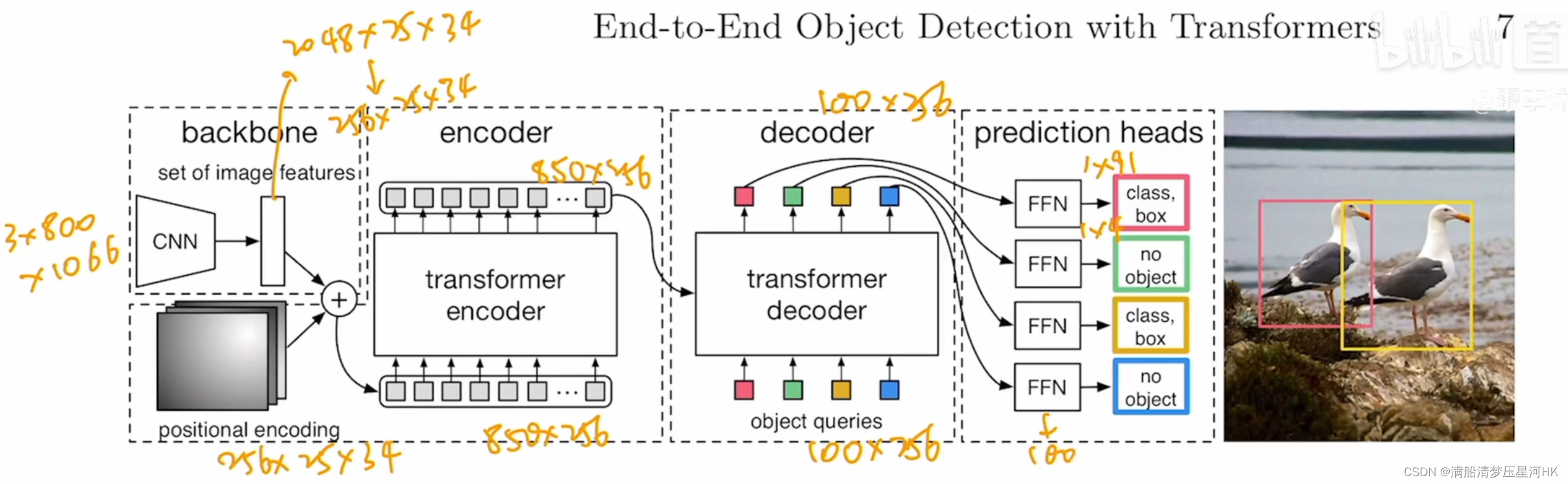
DETR前向传播流程:
- 假设输入图片:3x800x1066;
- 输入CNN网络(ResNet50)中,走到Conv5,此时对原图片下采样32倍,输出2048x25x34;
- 经过一个1×1卷积降为,输出256x25x34;
- 生成位置编码256x25x34,再和前面CNN输出的特征相加,输出256x25x34的特征;
- 再把特征拉直,变成850×256,输入transformer encoder中;
- 经过6个encoder模块,进行全局建模,输入同样850×256的特征;
- 生成一个可学习的object queries(positional embedding)100×256;
- 将encode输出的全局特征850×256和object queries 100×256一起输入6层decoder中,反复的做自注意力操作,最后得到一个100×256的特征;(细节:这里每个decoder都会做一次object query的自注意力操作,第一个decoder可以不做,这主要是为了移除冗余框;为了让模型训练的更快更稳定,所以在Decoder后面加了很多的auxiliary loss,不光在最后一层decoder中计算loss,在之前的decoder中也计算loss)
- 最后再接上两个feed forward network预测头(全连接层),一个FFN做物体类别的预测(类别个数),另一个FFN做box预测(4 xywh);
- 再用这100个预测框和gt框(N个)通过匈牙利算法做最优匹配,找到最终N个有效的预测框,其他的(100-N)框当作背景,舍去;
- 再用这N个预测框和N个GT框计算损失函数(交叉熵损失,去掉log + GIOU Loss + L1 Loss),梯度回传;
; 四、掉包版代码
论文原文给出的掉包版代码,mAP好像有40,虽然比源码低了2个点,但是代码很简单,只有40多行,方便我们了解整个detr的网络结构:
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads, num_encoder_layers, num_decoder_layers):
super().__init__()
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1), self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1066)
logits, bboxes = detr(inputs)
print(logits.shape)
print(bboxes.shape)
五、一些问题
1、为什么ViT只有Encoder,而DETR要用Encoder+Decoder?(从论文实验部分得出结论)
Encoder:Encoder自注意力主要进行全局建模,学习全局的特征,通过这一步其实已经基本可以把图片中的各个物体尽可能的分开;
Decoder:这个时候再使用Decoder自注意力,再做目标检测和分割任务,模型就可以进一步把物体的边界的极值点区域进行一个更进一步精确的划分,让边缘的识别更加精确;
2、object query有什么用?
object query是用来替换anchor的,通过引入可学习的object query,可以让模型自动的去学习图片当中哪些区域是可能有物体的,最终通过object query可以找到100个这种可能有物体的区域。再后面通过二分图匹配的方式找到100个预测框中有效的预测框,进而计算损失即可。
所以说object query就起到了替换anchor的作用,以可学习的方式找到可能有物体的区域,而不会因为使用anchor而造成大量的冗余框。
Reference
b站: DETR 论文精读【论文精读】
Original: https://blog.csdn.net/qq_38253797/article/details/127429466
Author: 满船清梦压星河HK
Title: 【DETR 论文解读】End-to-End Object Detection with Transformer
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/683079/
转载文章受原作者版权保护。转载请注明原作者出处!