

Abstract
这里就是说在目标检测领域,很多工作都想提高检测头的性能,这篇文章提出了动态头,也就是Dynamic Head,来将检测头和注意力(Attention)结合。在尺度(scale-aware)、空间(spatial-aware)、任务(task-aware)三个维度添加自注意力(self-attention),显著提高了(significantly improves)检测头的表达能力,没有额外的计算开销(without any computational overhead)。
Introduction
如何提高目标检测头的性能已成为现有目标检测工作中的关键问题。所以这篇文章就是为了实现这样一个检测头。
实现这样一个检测头需要考虑三点:
- 不同尺度的不同物体通常共存(co-exist)于一张图片中,所以检测头应该是scale-aware的。
- 同一个物体会以不同形状存在,所以检测头应该是spatial-aware的。
- 物体会有多种被检测形式,比如点、框、角点,所以检测头应该是task-aware的。
我理解这三个维度,scale-aware是同一个物体在不同分辨率下的表现一致性。spatial-aware是同一个物体在同一分辨率内的位置、朝向。task-aware我觉得没必要,因为检测任务的结果是检测到,而检测结果的表现方式并不重要。task-aware也很重要,通过增加task来优化检测,比如focal loss。
还有个motivatioin是,如果把backbone所有输出的特征做自注意力,计算成本太高,所以只能拆成三个。文章说,这三种方式作用于特征图的不同维度,性能可以相互补充。并且说
It offers a great potential for learning a better representation that can be utilized to improve all kinds of object detection models with 1.2% ∼ 3.2% AP gains.
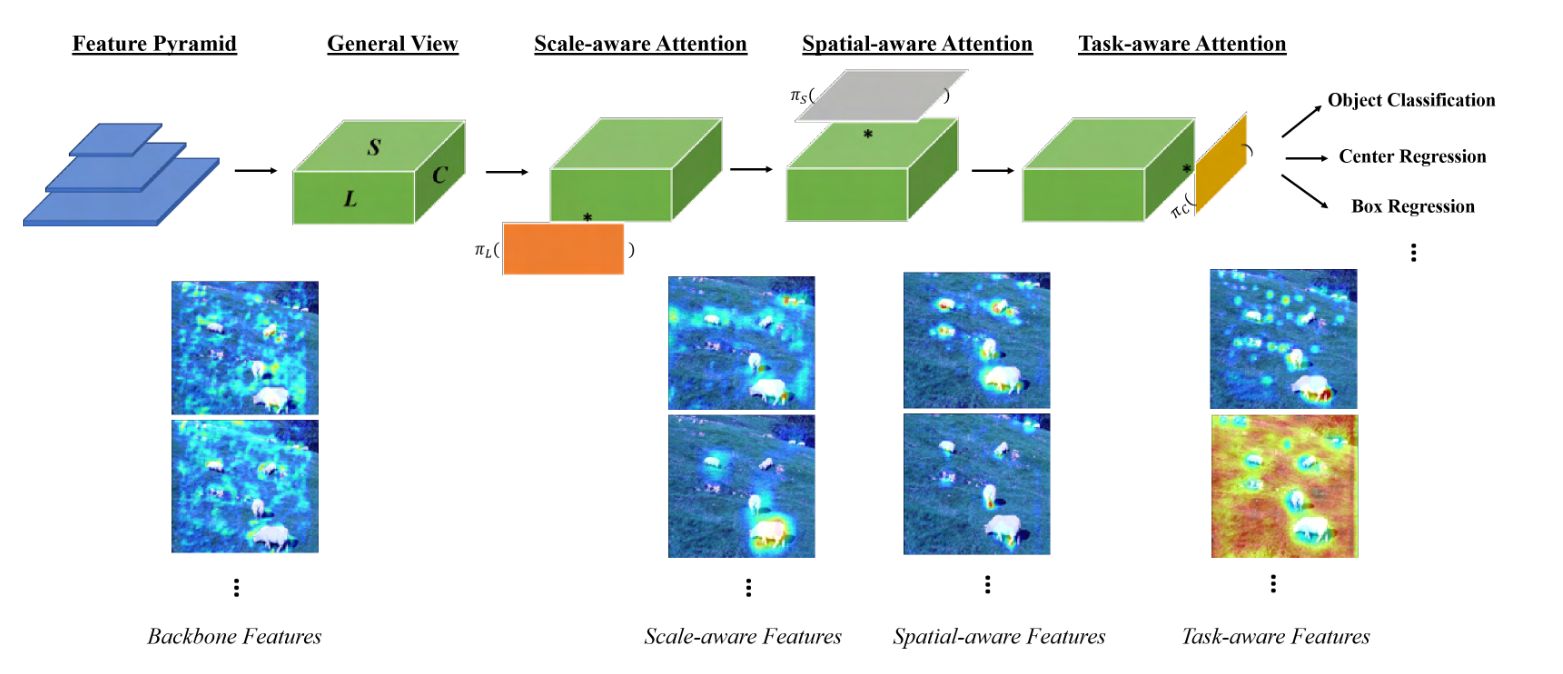

; Related Work
最近的研究集中在从各个角度改进目标检测器:scale-aware、spatial-aware和task-aware。
首先介绍scale-aware的相关工作 ,许多研究都强调scale-aware的重要性,早期工作出现了图像金字塔(R-fcn: Object detection via region-based fully convolutional networks、An analysis of scale invariance in object detection、Sniper: Efficient multi-scale training)。后续为了代替图像金字塔,出现了特征金字塔( Feature pyramid networks for object detection),通过连接下采样的convolution features map,目前是现代目标检测器的一个标准结构。但是,不同层次提取的特征会导致明显的语义差距(cause a noticeable semantics gap),为了解决这种差异(to solve this discrepancy),( Path aggregation network for instance segmentation)这篇文章通过特征金字塔自下而上的路径增强来增强较低层的特征。后面,(Libra r-cnn: Towards balanced learning for object detection)通过引入平衡采样和平衡金字塔对其进行改进(Non-Local)。 说到底还是为了解决这个问题:低层特征分辨率高往往学习到的是细节特征,高层特征分辨率低学习到语义特征,如何更有效地利用不同层的特征信息? 最近,(SEPC:Scale-equalizing pyramid convolution for object detection)提出了一种基于3d卷积的金字塔卷积,可以同时提取尺度和空间特征。
Spatial-awareness相关工作,之前的工作试图提高模型的空间感知力 。众所周知(=。=),CNN对图片空间变换学习能力be limited。一些工作就从模型本身入手,提高模型的capability(size),(这个容量我觉得是参数空间容量,可以提高模型表达力),例如(Deep
residual learning for image recognition, Aggregated residual transformations for deep neural networks),或进行昂贵的数据扩充(Imagenet classification with deep convolutional neural networks)导致了推理速度慢,计算成本昂贵。后来,有了新的卷积算子来提高卷积的空间变换学习能力。比如膨胀卷积(Multi-scale context aggregation by dilated convolutions),可以从指数级(exponentially )扩展的感受野中提取图片特征。可变形卷积( Deformable convolutional networks),在卷积前增减一层偏移权重,可以让模型自己学习卷积的偏移位置。 可变形卷积升级版(More deformable, better results)通过引入学习的特征幅度重新制定了偏移量,并进一步提高了它的表达能力。 本文提出的空间注意力,将注意力应用到每个空间位置,自适应将多个特征级别聚合在一起,以学习更具辨别力的表示。
Task-awareness相关工作,目标检测源自于两阶段范式(Edge boxes: Locating object proposals from edges, R-fcn: Object detection via region-based fully convolutional networks),后面这句不好翻译,看英文 which first generates object proposals and then classifies the proposals into different classes and background。Faster r-cnn提出了RPN网络,将两个阶段分别用各自的CNN网络完成,形成了现代的两阶段检测框架。后来,出现了一阶段目标检测框架(You only look once: Unified, real-time object detection),其因为高效而流行。(Focal loss for dense object detection)通过引入特定于任务的分支来进一步改进架构,以超越(surpass)两阶检测器的精度,同时保持之前的一阶检测器的速度。进来,很多工作发现,物体的多种表现形式(various representations)可以潜在提高其表现力。 Mask r-cnn证实了结合边界框和掩码可以提高性能(Mask R-CNN是在Faster R-CNN的基础上添加了一个预测分割mask的分支)。( Fcos: Fully convolutional one-stage object detection)提出使用中心表示以逐像素预测方式解决对象检测问题。(后续工作还有CornerNet、CenterNet、Center Point、CenterBased、PolorMask等还有一个忘了,挖坑)。( Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection)过根据对象的统计特征自动选择正样本和负样本,进一步提高了基于中心的方法的性能。后来,(Rep-points: Point set representation for object detection)将目标检测制定为具有代表性的关键点,以简化学习。(Centernet: Keypoint triplets for object detection)过将每个对象检测为三元组而不是一对关键点来进一步提高性能,以减少不正确的预测。最近,(Borderdet: Border feature for dense object detection)提出从每个边界的极值点提取边界特征,以增强点特征并归档最先进的性能。在本工作中,我们在检测头中present a task-aware attention,这允许将注意力部署在通道上,这可以自适应地支持各种任务,无论是单级/两级检测器,还是基于框/中心/关键点的检测器。(还得看看下文他是咋做的,这按理说输出都不一样,怎么自适应?)
最重要的,本文将上面所有属性都集成到了我们检测头的一个统一的注意力机制中。
Our Approach
Motivation
先来看先前对检测头的研究工作。
这里首先定义了金字塔特征,feature pyramid的尺寸为
R ( L ∗ H ∗ W ∗ C ) R^{(LHWC)}R (L ∗H ∗W ∗C )
令
S = H ∗ W S=HW S =H ∗W
那么R尺寸变为
R ( L ∗ S ∗ C ) R^{(LSC)}R (L ∗S ∗C )
目的就是为了弄成3维的而已,为什么弄成3维?看下面。
有如下几个结论:
- 物体尺度差异和特征所在金字塔的层级有关(related to features at various levels)。要benefit scale-aware,就要跨不同特征级别的学习特征。
- 各种物体形状的几何变换与不同空间位置的特征有关,要benefit spatial-aware,就要学习跨不同空间学习特征。
- 不同(Divergent ,分叉)的物体表达或任务(representations and tasks)和不同的通道有关,要benefit task-aware,就要跨通道学习特征。
在本文中,我们发现上述所有方向都可以统一在一个有效的注意力学习问题中。我们的工作是第一次尝试将所有三个维度上的多个注意力结合起来,形成一个统一的头部,以最大限度地提高它们的改进。
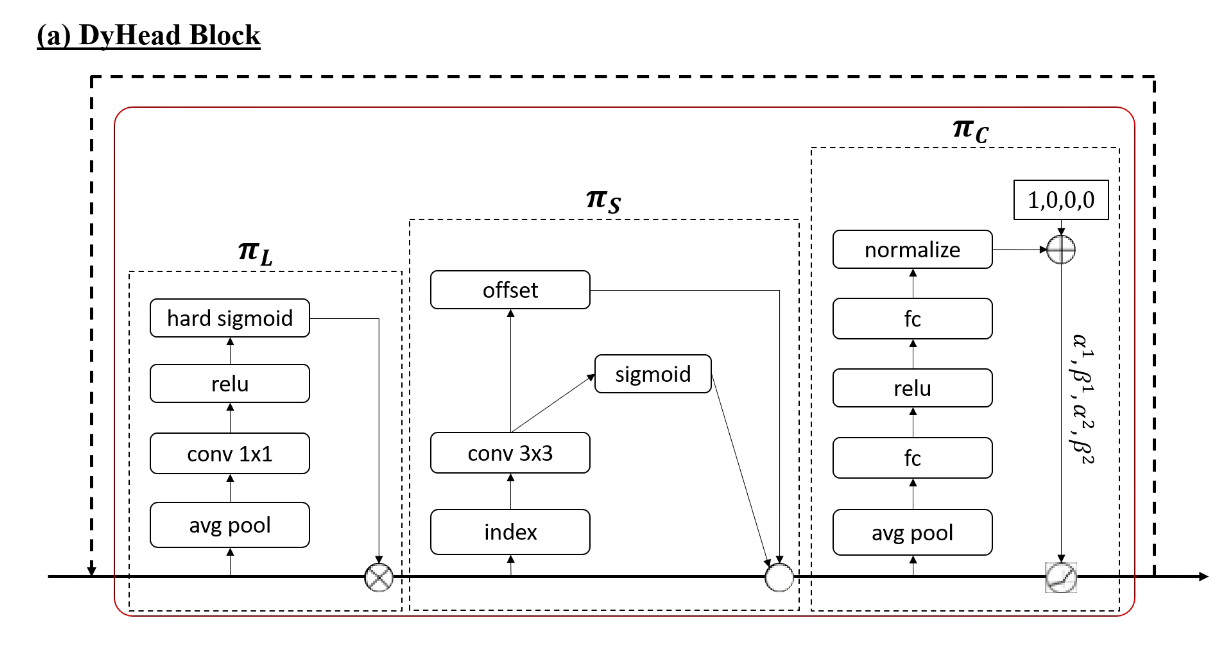
; Dynamic Head: Unifying with Attention
首先来看自注意力的公式:
W ( F ) = π ( F ) ⋅ F W (F) = π(F) · F W (F )=π(F )⋅F
F ∈ R L × S × C F ∈ R^{L×S×C}F ∈R L ×S ×C
π函数是一个注意力函数(attention function),最简单的π函数可以是一个MLP,但把所有特征同时做注意力,这个算力负担不起,所有就拆了。于是就拆成了
W ( F ) = π C ( π S ( π L ( F ) ⋅ F ) ⋅ F ) ⋅ F W (F) = π_C(π_S(π_L(F) · F)· F)· F W (F )=πC (πS (πL (F )⋅F )⋅F )⋅F
π C 、 π S 、 π L 分 别 ( r e s p e c t i v e l y ) 作 用 在 上 述 R ( L ∗ S ∗ C ) 中 的 三 个 维 度 π_C、π_S、π_L 分别(respectively)作用在上述R^{(LSC)}中的三个维度πC 、πS 、πL 分别(r e s p e c t i v e l y )作用在上述R (L ∗S ∗C )中的三个维度
在重复一次,C是channel,S是特征图(代表spatial),L是level(也就是不同尺度)。这其实有深刻含义,我们之前令S=H*W,那么S等于是一个完整的特征图,在S上做自注意力,相当于在spatial上做自注意力。
Scale-aware Attention
π L π_L πL
这个是尺度注意力,根据语义的重要性动态融合不同尺度的重要性。
π L ( F ) ⋅ F = σ ( f ( 1 S C ∑ S , C F ) ) ⋅ F π_L(F) · F = σ(f(\frac{1}{SC}\sum_{S,C}F))· F πL (F )⋅F =σ(f (S C 1 S ,C ∑F ))⋅F
f(·)是一个1*1的卷积层,做线性变化。 σ(x) = max(0, min(1, x+1/2))是一个hard-sigmoid函数。
Spatial-aware Attention
π S π_S πS
s现在维度还是很高,将该模块分为两个步骤:首先通过使用可变形卷积(deformable convolution)使注意力学习变得稀疏,然后在相同空间位置处跨级别聚合特征。
π S ( F ) ⋅ F = 1 L ∑ l = 1 L ∑ k = 1 K w l , k ⋅ F ( l ; p k + ∆ p k ; c ) ⋅ ∆ m k , π_S (F)·F = \frac{1}{L}\sum_{l=1}^{L}\sum_{k=1}^{K}w_{l,k}·F(l; p_k +∆p_k;c)·∆m_k,πS (F )⋅F =L 1 l =1 ∑L k =1 ∑K w l ,k ⋅F (l ;p k +∆p k ;c )⋅∆m k ,
K是稀疏采样位置,估计跟可变形卷积有关,p_k +∆p_k是可变形卷积自己学到的卷积核偏移量,Δm_k 是位置 p_k 的自学重要性标量。(就是卷积核权重)。(作者这里没说w_l,k是干啥的,估计是个卷积核?)
Task-aware Attention
π C π_C πC
为了实现联合学习和泛化对象的不同表示,我们在最后部署了任务感知注意力,它动态的在特征通道上切换 ON 和 OFF,以支持不同的任务。
π C ( F ) ⋅ F = m a x ( α 1 ( F ) ⋅ F c + β 1 ( F ) , α 2 ( F ) ⋅ F c + β 2 ( F ) π_C (F)·F = max(α^1(F)·F_c+β^1(F), α^2(F)·F_c+β^2(F)πC (F )⋅F =m a x (α1 (F )⋅F c +β1 (F ),α2 (F )⋅F c +β2 (F )
F_c是第c个通道的特征(feature slice),[α^1, α^2, β^1, β2]T = θ(·),是一个学习控制激活阈值的超函数。这个θ(·)有点像Dynamic relu。它首先在 L × S 维度上进行全局平均池化以降低维度,然后使用两个全连接层和一个归一化层,最后应用移位 sigmoid 函数将输出归一化为 [−1, 1]。
然后按顺序多次嵌套三个注意力,就完成了。总结:动态头部的输入是金字塔特征,输出可用于不同的任务和对象检测的表示,例如分类、中心/框回归等。
然后吹了吹牛,后面是将上面的模型应用到一阶和二阶检测器看效果。
Generalizing to Existing Detectors
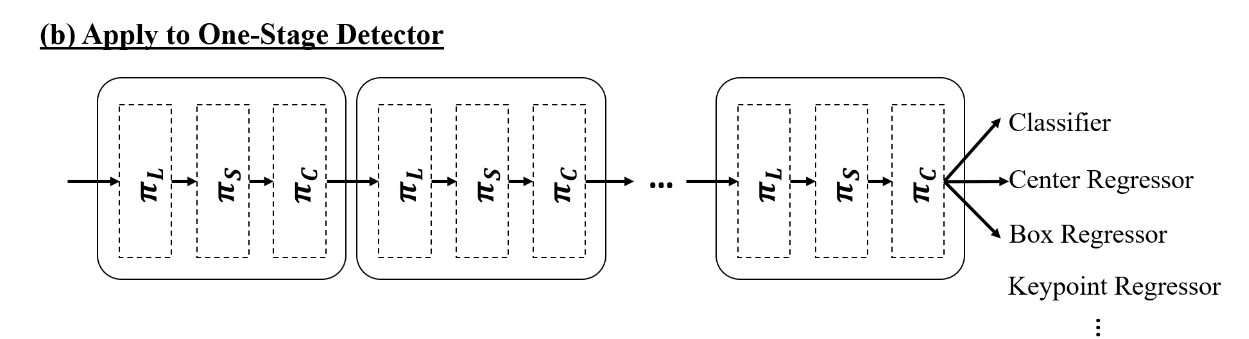
One-stage Detector
一级检测器通过从特征图中密集采样位置来预测对象位置,这简化了检测器设计。典型的一级检测器(例如,RetinaNet)由用于提取密集特征的主干网络和用于分别处理不同任务的多个特定于任务的子网络分支组成。在(Dynamic relu)工作中显示出,图片分类和目标检测中的bbox回归是非常不同的任务。我们的工作在backbone中,只用一个branch,替代了多branch(we only attach one unified branch instead of mul-tiple branches to the backbone),但得益于多重注意力机制,我们的工作可以在single branch中同时处理多任务(multiple tasks), 这样可以进一步简化效率。最近,一级检测器的anchor-free变体变得流行,例如,FCOS、ATSS和RepPoint,将对象重新定义为中心和关键点以提高性能。与 RetinaNet 相比,这些方法需要将中心预测或关键点预测附加到分类分支或回归分支,这使得特定任务分支的构建变得non-trivial(并不是小打小闹的)。相比,我们的工作只需要将各种类型的预测附加到头部的末尾。
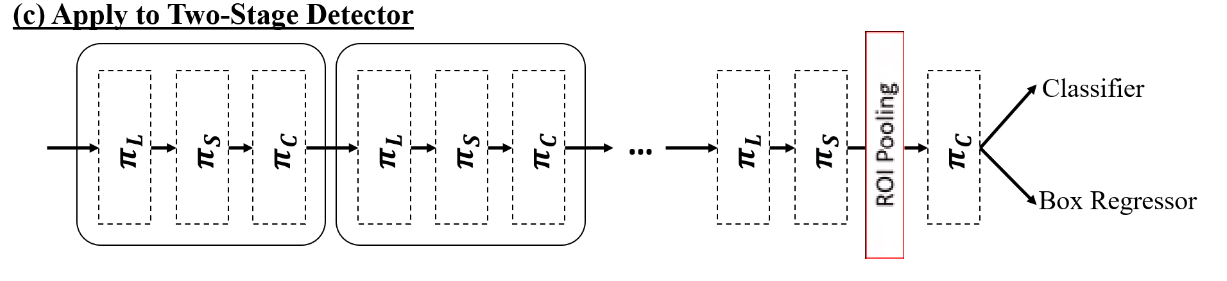
Two-stage Detector
两阶段检测器利用区域提议和RoI-pooling层(Faster r-cnn)从骨干网络的特征金字塔中提取中间表示。为了配合这一特性,我们首先在 RoI-pooling层之前的特征金字塔上应用我们的尺度感知注意力和空间感知注意力,然后使用我们的任务感知注意力来替换原来的全连接层。(是不是说π_C可以有特征容融合的作用?)
; Relation to Other Attention Mechanisms
Deformable
可变形卷积通过稀疏采样,显著改进了传统卷积层的变换学习,已经被广泛应用在目标检测的backbone中,用于增强特征表达。在我们工作中,相当于对S维特征进行建模(modeling the S sub-dimension),我们发现在backbone中使用的可变形模块可以和我们提出的动态头部互补(complementary ),通过ResNet-101-64x4d的deformable变体,使本文的dynamic head达到了SOTA。对应Spatial-aware。
Non-local
Non-Local Networks是利用注意力模块提高目标检测性能的开创性工作。然而,它使用简单的点积公式通过融合来自不同空间位置的其他像素特征来增强像素特征。这种行为可以被视为仅对我们表示中的 L×S 子维度进行建模。对应Task-aware Attention。
Transformer
最近有种趋势是将Transformer用于目标检测,例如End-to-end object detection with transformers,Deformable detr: Deformable transformers for end-to-end object detection,Relationnet++: Bridging visual representations for object detection via transformer decoder,Transformer通过应用多头全连接层来学习 交叉注意对应关系并融合来自不同模式的特征。这种行为可以被视为仅对我们表示中的 S × C 子维度进行建模。对应Scale-aware Attention。
Experiment
这里Dynamic Head是一个插件(plugin),使用ATSS训练(Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection)
本篇文章启发
如何使全注意力模型易于学习和高效计算,以及如何系统地考虑更多的注意力模态到头部设计中以获得更好的表现。
Original: https://blog.csdn.net/bless2015/article/details/122537036
Author: 番茄发烧了
Title: Dynamic Head: Unifying Object Detection Heads with Attentions 阅读
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/682913/
转载文章受原作者版权保护。转载请注明原作者出处!