

目标检测是在图片中对可变数量的目标进行查找和分类
传统目标检测算法


Viola-Jones(人脸检测)
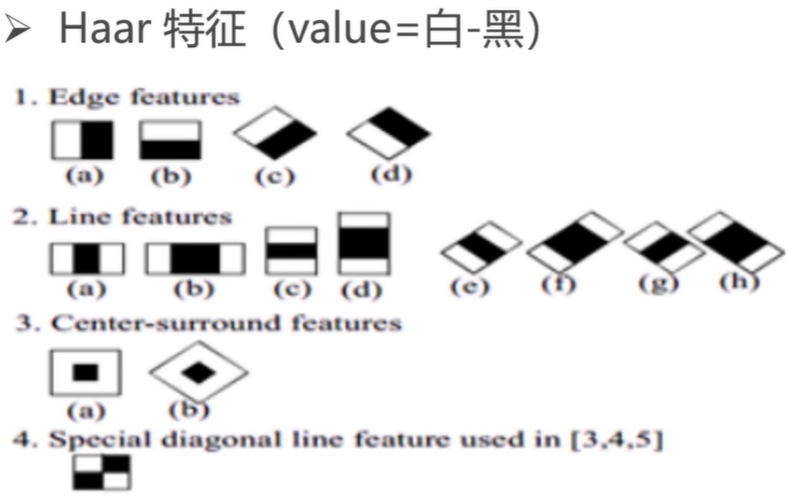
Haar特征抽取
训练人脸分类器(Adaboost算法等)
滑动窗口

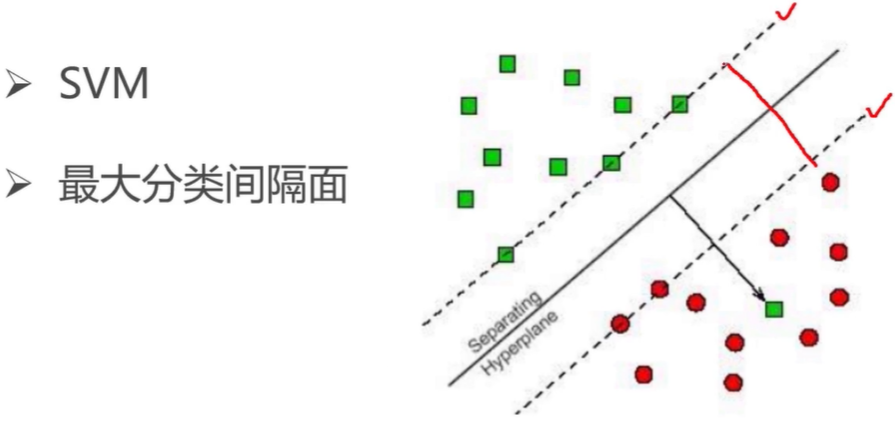
HOG+SVM(行人检测,Opencv实现)
提取HOG特征
训练SVM分类器
利用滑动窗口提取目标区域,进行分类判断
NMS
输出检测结果

DPM(物体检测)
HOG的扩展,利用SVM训练得到物体的梯度
计算DPM特征图
计算响应图(root filter 和part filter)
Latent SVM分类器训练
检测识别

NMS(非极大值抑制算法) 为了消除多余的框,找到最佳的物体检测的位置。选取邻域分数最高的窗口,抑制分数低的窗口。
Soft-NMS(非极大值抑制算法)相邻区域内的检测框的分数进行调整而非彻底抑制,提高了高检索率情况下的准确率,在低检索率时仍能对物体检测性能有明显提升。
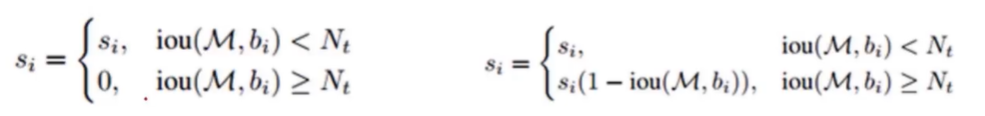
深度学习目标检测算法
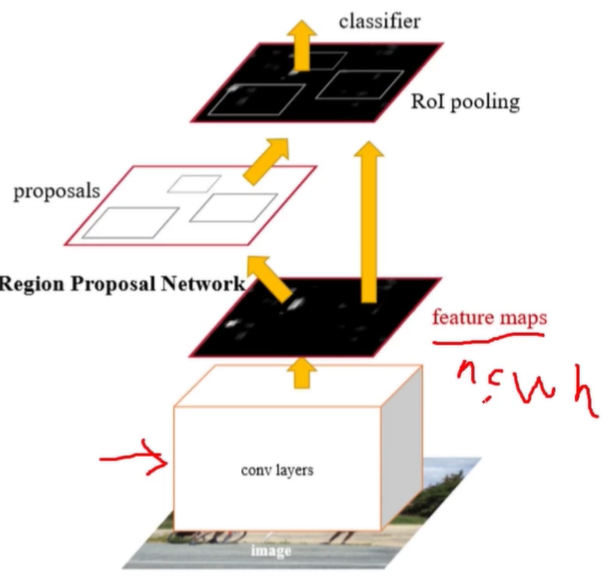
two-stage
CNN卷积特征,端到端的目标检测(RPN网络)准确度高,速度相对one-stage慢,核心组件CNN网络,RPN网络。
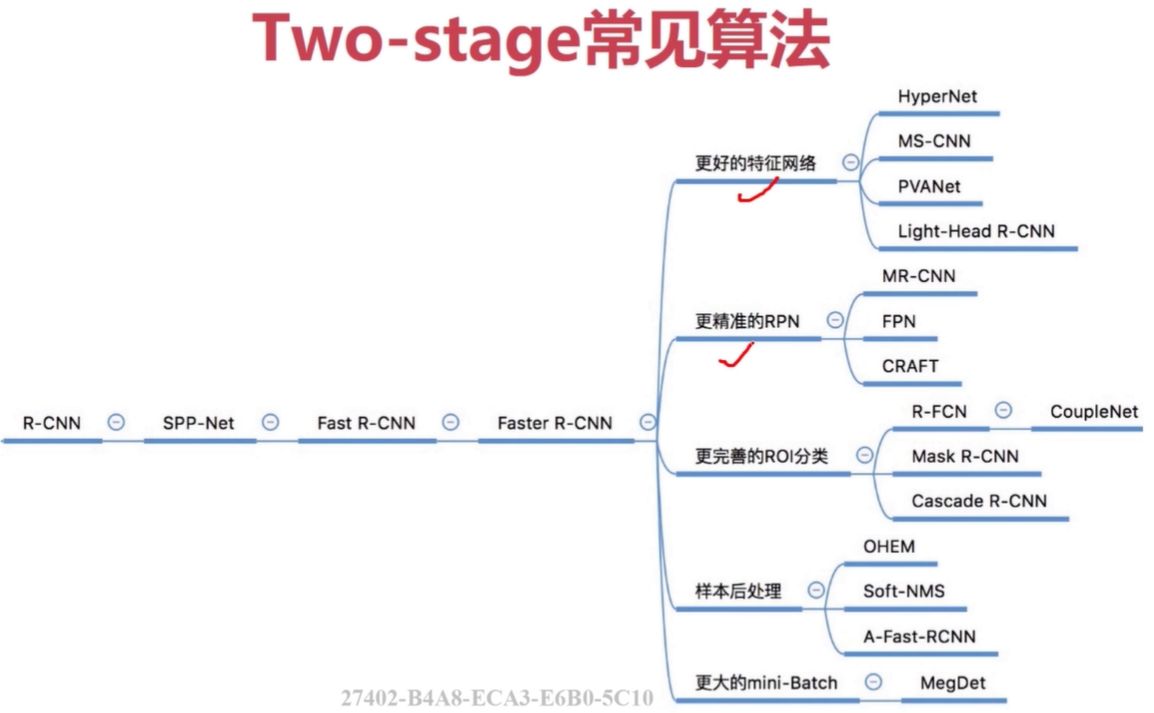
CNN网络设计原则:从简单到复杂再到简单的卷积神经网,多尺度特征融合的网络,更轻量级的CNN网络。
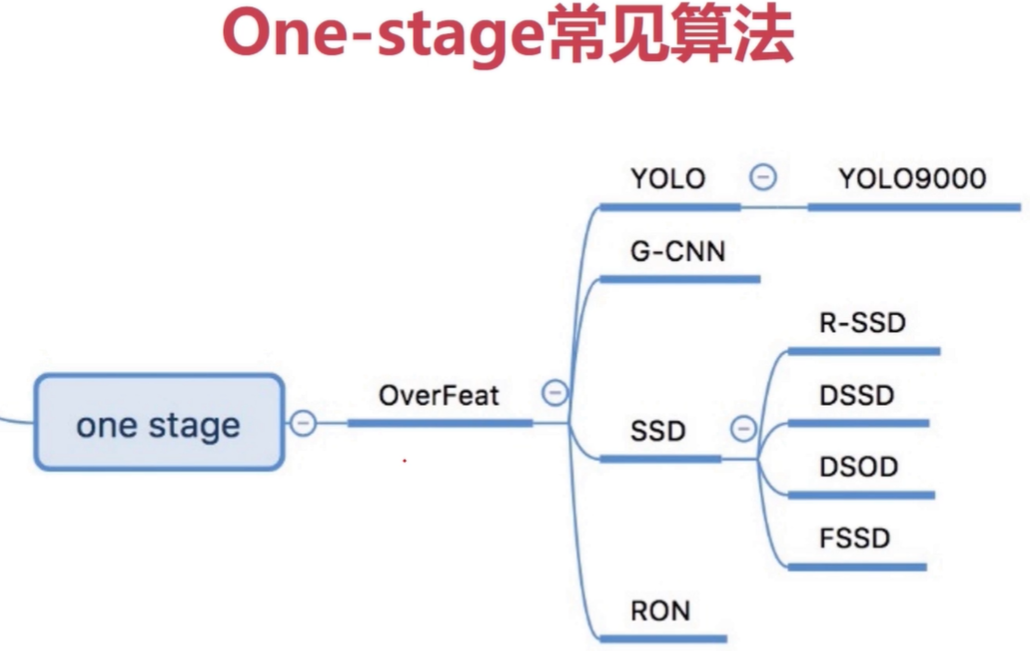
one-stage
使用CNN卷积特征,直接回归物体类别概论和位置坐标值(无region proposal),准确度低,速度相对two-stage快。核心组件:CNN网络,回归网络。


SSD算法
直接回归目标类别和位置,不同尺度的特征图上预测,端到端训练,图像分辨率比较低,也能保证检测精度。
R-CNN
* 步骤
* 1、找出可能存在的候选区域, 得出2000个候选区域,统一成大小
* 通过选择性搜索(SS)算法,进行筛选 * 大小统一:通过crop +warp
* 2、进行CNN提取特征,得出2000特征向量
* 使用AlexNet的结构,输入要去227 * 227 * 提取出的特征会会保存在磁盘当中
* [2000, 4096]
* 3、**20个SVM进行分类,得到 2000 * 20的得分矩阵**
* 20:代表你的目标检测当前数据集一共需要检测20种类别* 得出[2000, 20]的得分矩阵,打分
* 4、进行NMS,提出候选框
* 理解NMS的整个过程,* 假设现在滑动窗口有:A、B、C、D、E 5个候选框,
- 第一轮:假设B是得分最高的,与B的IoU>0.5删除。现在与B计算IoU,DE结果>0.5,剔除DE,B作为一个预测结果
- 第二轮:AC中,A的得分最高,与A计算IoU,C的结果>0.5,剔除C,A作为一个结果
* 5、修正bbox,对bbox做回归微调
* 通过线性回归,特征值是候选区域,目标是对应的GT. * 建立回归方程学习参数。
* R-CNN的训练过程
* 预训练+微调
* 当前我们业务的数据集(正负样本标记)
* 预训练:别人已经在大数据集上训练好的CNN网络参数模型,model1
* 微调:利用标记好的样本,输入到model1当中,继续训练,得出model2(CNN网络)
* 训练SVM分类器,每个类别训练一个分类器
* 特征M * 4096 , 一个SVM,4096 * 20
* 正负样本标记结果(100个猫,900个非猫)
* 总共得到4096 * 20的SVM权重
* 回归训练:
* 筛选候选框,只对那些跟ground truth的IoU超过某个阈值且IOU最大的region proposal回归
* 训练得到回归的参数
R-CNN的总结
* 缺点:
* 训练速度慢
* 占用磁盘空间大
* 训练阶段多
* 图片变形
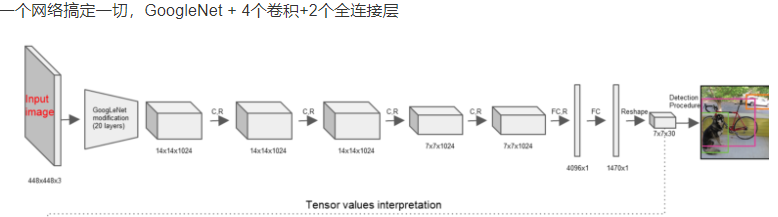
YOLO
-
改进速度:YOLO
-
448 * 448
- 一个网络解决
- 输出 7 * 7 * 30
- 7 * 7=49个 像素值,理解成49个单元格,49 * 2 = 98 个bbox框
- 30 = 两个bbox( 4 + 1 + 4 + 1) + 20(单元格的代表概率)
- 筛选一个bbox作为训练:
- 通过confidence进行筛选
- confidence由网络输出, (进行标记)
- 每一个单元格:输出一个confidence高的bbox位置,一个概率大的类别
- 训练过程:所以如何判断一个grid cell中是否包含object呢?如果一个object的ground truth的中心点坐标在一个grid cell中,那么这个grid cell就是包含这个object,也就是说这个object的预测就由该grid cell负责。
目标检测数据集
pascal voc 数据集介绍
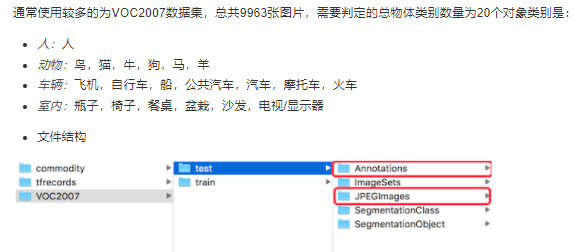
- 文件内容
- Annotations: 图像中的目标标注信息xml格式
- JPEGImages: *所有图片(VOC2007中总共有9963张,训练有5011张,测试有4952张)
以下是一个标准的物体检测标记结果格式,这就是用于训练的物体标记结果。其中有几个重点内容是后续在处理图像标记结果需要关注的。
- size:
- 图片尺寸大小,宽、高、通道数
- object:
- name:被标记物体的名称
- bndbox:标记物体的框大小
Original: https://blog.csdn.net/m0_64735594/article/details/123399886
Author: 艾卡西亚暴雨o
Title: 王越的目标检测学习笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/682718/
转载文章受原作者版权保护。转载请注明原作者出处!