



从V1-V5
深入解析YOLO系列模型
yolo相对于R_CNN系列论文,创新之处在于不再需要候选区域,直接端到端,利用回归的思想,直接回归出边框和类别,大大加快了速度,同时精度也挺高。
YOLO v1

主要思想
1、将图片划分为s×s的网格,待检测的目标中心点位于哪个网格中,就由哪个网格来负责检测他,论文中每个网格设定了2个框,也就是让2个框来同时拟合一个目标框,所以当网格中存在目标时,那么该网格中的预测框的目标值即为这个目标框的值(对比R_CNN系列论文,他们都是通过预测框与目标框的IOU来设定预测框的目标值);
2、所有的预测框由网络直接传播获得,每个网格预测5个框,每个框用5个预测值来表示,分别(x,y,w,h)和得分, x和y代 表 区域的中心点对于cell左上角 的偏移量,w 和h代表区域相对于全图的宽和高,它们都介于0 – 1之间。得分反映了区域内包含 一 个目标的置信度和预测区域的精确度。
IOU表示预测框与真实框的交并比,如果网格中有目标,Pr就等于1,否则为0,
实际这个公式是为了求训练时得分的目标值,修正网络预测的得分值;
3、每个网格无论有多少个框,都值预测一个类别值(与yolo v2不同,v2中每个anchorbox预测一组类别值),所以正向传播预测结果为s×s×(5×2+20)
YOLO v2
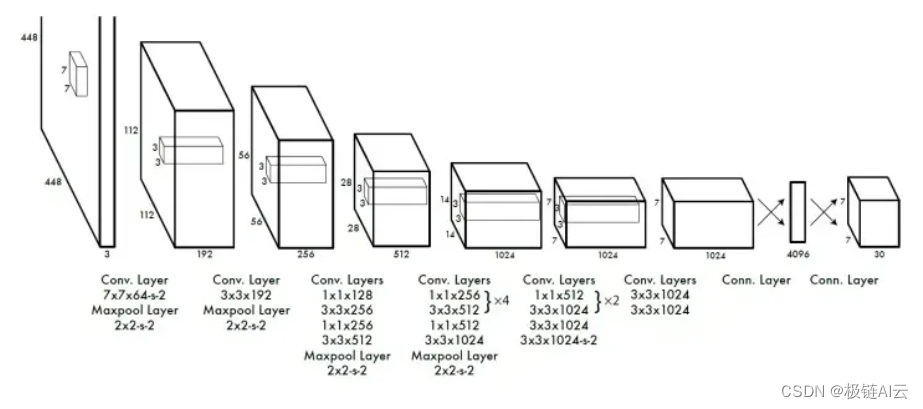
总体思路与一代相同,这里只说一下改进之处
1、联合训练算法
利用分类图像来学习分类,利用检测图像来学习定位
2、引入anchor box
相比较于一代yolo,一代yolo直接回归坐标,难度很大,引入anchor box,有了基准坐标,相对来说,预测难度降低;
但注意与faster R_CNN的区别,因为faster R_CNN是在feature map上,拿着anchor box进行滑动窗口的,实际就相当于一个框一个框的进行分类和回归,所以自然很容易检测到所有目标,但是yolo的类别和坐标都由回归产生,难度比faster-R-CNN要大:
(1)先验框的设置很重要。所以利用k-means来聚类,得到先验框的数量和大小(k=5),这样先验框更可靠
(2)直接预测相对于anchor box的偏移量,导致模型不稳定。所以不再预测偏移,而是预测相对于网格左上角的坐标
(3)如下,tx,ty,tw,th为网络预测值,所以在测试时,需要进一步计算获得预测边框,将相对于网格左上角坐标(tx,ty)转化为相对于图片左上角的坐标,宽度和高度需要依据anchor box的尺寸pw和ph来计算求得,具体公式如下,计算得到bx,by,bw,bh之后,在对他们进行过NMS。
(3)引入anchor box之后,每一个anchor box都需要进行单独的类别预测(一代中每个cell只预测一个类别),例如数据集类别为80类,那么每个anchor box需要预测一个85维的向量,如果每个cell有5个anchor box,网格为19×19,网络预测输出为:19×19×5×85.。
YOLO V3
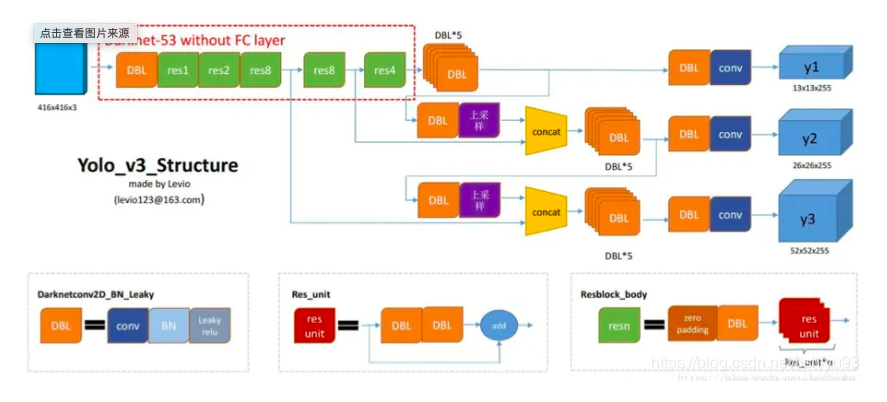
相比于 YOLOv2 的 骨干网络,YOLOv3 进行了较大的改进。借助残差网络的思想,YOLOv3 将原来的 darknet-19 改进为darknet-53。Darknet-53主要由1×1和3×3的卷积层组成,每个卷积层之后包含一个批量归一化层和一个Leaky ReLU,加入这两个部分的目的是为了防止过拟合。卷积层、批量归一化层以及Leaky ReLU共同组成Darknet-53中的基本卷积单元DBL。因为在Darknet-53中共包含53个这样的DBL,所以称其为Darknet-53。
yolo-v3在类别预测方面将yolo-v2的单标签分类改进为多标签分类,在网络结构中将yolo-v2中用于分类的softmax层修改为逻辑分类器。在yolo-v2中,算法认定一个目标只从属于一个类别,根据网络输出类别的得分最大值,将其归为某一类。然而在一些复杂的场景中,单一目标可能从属于多个类别。
比如在一个交通场景中,某目标的种类既属于汽车也属于卡车,如果用softmax进行分类,softmax会假设这个目标只属于一个类别,这个目标只会被认定为汽车或卡车,这种分类方法就称为单标签分类。如果网络输出认定这个目标既是汽车也是卡车,这就被称为多标签分类。
为实现多标签分类就需要用逻辑分类器来对每个类别都进行二分类。逻辑分类器主要用到了sigmoid函数,它可以把输出约束在0到1,如果某一特征图的输出经过该函数处理后的值大于设定阈值,那么就认定该目标框所对应的目标属于该类。
v3和v4两个版本的作者发生了变化。当时前三个版本的作者redmon在推特上发表了一个声明:大致是说因为yolo-v3已经被用在一些军事上,这是他不想看到的,因此他表示退出CV界。这也从侧面反映了yolo-v3性能的强大。2020年,Alexey Bochkovskiy等人接手了yolo系列,yolo-v4油然而生。
YOLOV4
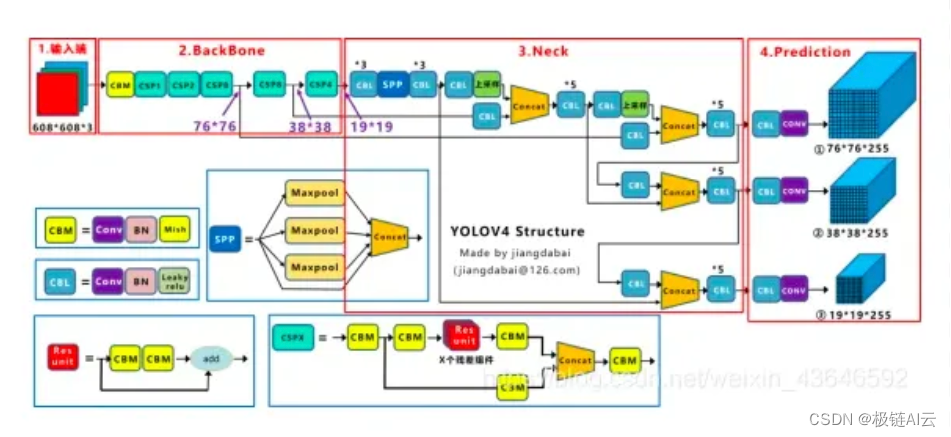
yolo-v4对深度学习中一些常用Tricks进行了大量的测试,最终选择了这些有用的Tricks:WRC、CSP、CmBN、SAT、 Mish activation、Mosaic data augmentation、CmBN、DropBlock regularization 和 CIoU loss。
Yolov4的结构图和Yolov3相比,因为多了CSP结构,PAN结构,如果单纯看可视化流程图,会觉得很绕,但是在绘制出上面的图形后,会觉得豁然开朗,其实整体架构和Yolov3是相同的,不过使用各种新的算法思想对各个子结构都进行了改进。
先整理下Yolov4的五个基本组件:
-
CBM:Yolov4网络结构中的最小组件,由Conv+Bn+Mish激活函数三者组成。
-
CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
-
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
-
CSPX:借鉴CSPNet网络结构,由卷积层和X个Res unint模块Concat组成。
-
SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
YOLOv5
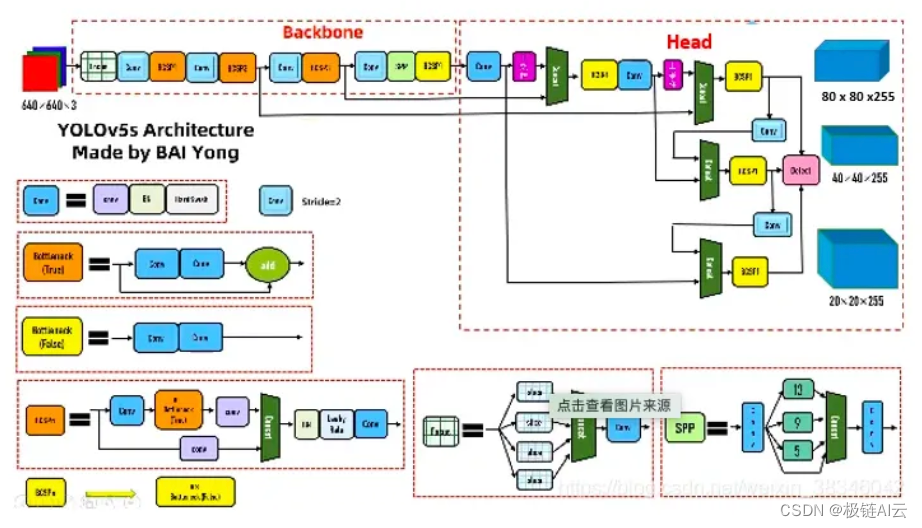
上图即YOLOv5的网络结构图,可以看出其分为输入端、Backbone、Neck、Prediction四个部分。
Backbone:主干网络,其大多时候指的是提取特征的网络。主干网络的作用就是提取图片中的信息,供后面的网络使用。经常使用的网络是resnet、VGG等(非自己设计),这些网络在分类等问题上的特征提取能力很强。
neck:其作用是更好地融合/提取backbone给出的feature,从而提高网络的性能。
基本组件:
CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
CSPX:借鉴CSPNet网络结构,由卷积层和X个Res unint模块Concate组成。
SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
其他基础操作:
Concat:张量拼接,会扩充两个张量的维度,例如2626256和2626512两个张量拼接,结果是2626768。
add:张量相加,张量直接相加,不会扩充维度,例如104104128和104104128相加,结果还是104104128。
YOLOv5s网络最小,速度最快,AP精度也最低。若检测的以大目标为主,追求速度,是个不错的选择。其他的三种网络,在YOLOv5基础上,不断加深加宽网络,AP精度也不断提升,但速度的消耗也在不断增加。
YOLOv4 与YOLOv5 在结构上基本相似,只是在细节上稍有差异。
(1) 增加 Focus 结构
Focus 结构的核心是对图片进行切片操作。以一个的简单的 3 x4 x4 输入图片为例。对于红色的区域,不论宽还是高,都从 0 开始,每隔两个步长取值;黄色的区域,不论宽还是高,都从 1 开始,每隔两个步长取值;依次类推,对三个通道都采取这样的切片操作。最后将所有的切片,按照通道 concat 在一起,得到一个12×2 x2的特征图。 YOLOv5s 以 3 x608 x608 的图片作为输入,经过切片操作后,变成12 x304x304的特征图,最后使用 32 个卷积核进行一次卷积,变成32 x304 x304 的特征图。
(2) CSP 结构
YOLOv4 中仅在 Backbone 中使用了 CSP 结构,而 YOLOv5 中在 Backbone 和 Neck中使用了两种不同的 CSP。
在 Backbone 中,使用带有残差结构的 CSP1_X,因为 Backbone 网络较深,残差结构的加入使得层和层之间进行反向传播时,梯度值得到增强,有效防止网络加深时所引起的梯度消失,得到的特征粒度更细。
在 Neck 中使用 CSP2_X,相对于单纯的 CBL 将主干网络的输出分成了两个分支,后将其 concat,使网络对特征的融合能力得到加强,保留了更丰富的特征信息。
YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x 按照其所含的残差结构的个数依次增多,网络的特征提取、融合能力不断加强,检测精度得到提高,但相应的时间花费也在增加。

Original: https://blog.csdn.net/m0_60673947/article/details/125152051
Author: 极链AI云
Title: 【模型解析】从V1-V5深入解析YOLO系列模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/682295/
转载文章受原作者版权保护。转载请注明原作者出处!