

1、前言
这篇文章废话不多说了,主要史帅基于PV-RCNN上面进行的改进,本文不会从头构建网络并进行解析,对于PV-RCNN不了解的小伙伴可以先去看我之前的文章。
PV-RCNN++论文地址:https://arxiv.org/abs/2102.00463 ![]()
 https://arxiv.org/abs/2102.00463 ;
https://arxiv.org/abs/2102.00463 ;
PV-RCNN PCDet代码仓库:GitHub – sshaoshuai/OpenPCDet: OpenPCDet Toolbox for LiDAR-based 3D Object Detection.![]() https://github.com/sshaoshuai/OpenPCDet ;
https://github.com/sshaoshuai/OpenPCDet ;
2、网络结构解析

PV-RCNN++在PV-RCNN的基础上进行了主要的两点改进:
1、将原来的FPS(最远点采样)换成了sectorized proposal-centric keypoint sampling strategy(分区域的提议中心关键点采样 ?),使得有限的关键点可以更加的聚集在proposal区域范围内,来更多的编码有效前景点特征用于后面的proposal refinement。同时sectorized farthest point sampling在不同sectors(分块区域 )的关键点采样是平行进行的,这样不仅保证了分块区域中采样的关键点在该分块点集中的均匀分布,还相比于vailla FPS(普通的最远点采样)算法减少了两倍的复杂度。
2、提出了新颖的local feature aggregation module(局部特征聚合模块):VectorPool aggregation;该模块可以更有效的对稀疏和不规则的点云数据进行编码。
同时作者再次强调,局部位置中点与点之间的相对位置信息对于描述局部的空间几何信息是十分有效的。
PV-RCNN++中的8个模块(其中两个改进点都集中在了 VoxelSetAbstraction和二阶预测头中)
1、MeanVFE (voxel feature encoding)
2、VoxelBackBone8x (3D backbone)
3、HeightCompression (Z轴方向堆叠)
4、VoxelSetAbstraction (VSA模块)
5、BaseBEVBackbone (2D backbone for RPN)
6、AnchorHeadSingle (一阶预测头)
7、PointHeadSimple Predicted Keypoint Weighting (PKW模块)
8、PVRCNNHead (二阶预测头) (grid voxel中特征聚合也采用vector pool的方式)
注:由于作者在OpenPCDet仓库上并没有正式重新组织并发布PV-RCNN++在KITTI数据集上的的配置和预训练模型文件;此处为了方便解析,根据issue中作者提供的配置来进行,可参考:
PV-RCNN++在KITTI数据集上的配置文件:
CLASS_NAMES: ['Car', 'Pedestrian', 'Cyclist']
DATA_CONFIG:
_BASE_CONFIG_: cfgs/dataset_configs/kitti_dataset.yaml
MODEL:
NAME: PVRCNNPlusPlus
VFE:
NAME: MeanVFE
BACKBONE_3D:
NAME: VoxelBackBone8x
MAP_TO_BEV:
NAME: HeightCompression
NUM_BEV_FEATURES: 256
BACKBONE_2D:
NAME: BaseBEVBackbone
LAYER_NUMS: [5, 5]
LAYER_STRIDES: [1, 2]
NUM_FILTERS: [128, 256]
UPSAMPLE_STRIDES: [1, 2]
NUM_UPSAMPLE_FILTERS: [256, 256]
DENSE_HEAD:
NAME: AnchorHeadSingle
CLASS_AGNOSTIC: False
USE_DIRECTION_CLASSIFIER: True
DIR_OFFSET: 0.78539
DIR_LIMIT_OFFSET: 0.0
NUM_DIR_BINS: 2
ANCHOR_GENERATOR_CONFIG: [
{
'class_name': 'Car',
'anchor_sizes': [[3.9, 1.6, 1.56]],
'anchor_rotations': [0, 1.57],
'anchor_bottom_heights': [-1.78],
'align_center': False,
'feature_map_stride': 8,
'matched_threshold': 0.6,
'unmatched_threshold': 0.45
},
{
'class_name': 'Pedestrian',
'anchor_sizes': [[0.8, 0.6, 1.73]],
'anchor_rotations': [0, 1.57],
'anchor_bottom_heights': [-0.6],
'align_center': False,
'feature_map_stride': 8,
'matched_threshold': 0.5,
'unmatched_threshold': 0.35
},
{
'class_name': 'Cyclist',
'anchor_sizes': [[1.76, 0.6, 1.73]],
'anchor_rotations': [0, 1.57],
'anchor_bottom_heights': [-0.6],
'align_center': False,
'feature_map_stride': 8,
'matched_threshold': 0.5,
'unmatched_threshold': 0.35
}
]
TARGET_ASSIGNER_CONFIG:
NAME: AxisAlignedTargetAssigner
POS_FRACTION: -1.0
SAMPLE_SIZE: 512
NORM_BY_NUM_EXAMPLES: False
MATCH_HEIGHT: False
BOX_CODER: ResidualCoder
LOSS_CONFIG:
LOSS_WEIGHTS: {
'cls_weight': 1.0,
'loc_weight': 2.0,
'dir_weight': 0.2,
'code_weights': [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
}
PFE:
NAME: VoxelSetAbstraction
POINT_SOURCE: raw_points
NUM_KEYPOINTS: 2048
NUM_OUTPUT_FEATURES: 90
SAMPLE_METHOD: SPC
SPC_SAMPLING:
NUM_SECTORS: 6
SAMPLE_RADIUS_WITH_ROI: 1.6
FEATURES_SOURCE: ['bev', 'x_conv3', 'x_conv4', 'raw_points']
SA_LAYER:
raw_points:
NAME: VectorPoolAggregationModuleMSG
NUM_GROUPS: 2
LOCAL_AGGREGATION_TYPE: local_interpolation
NUM_REDUCED_CHANNELS: 1
NUM_CHANNELS_OF_LOCAL_AGGREGATION: 32
MSG_POST_MLPS: [ 32 ]
FILTER_NEIGHBOR_WITH_ROI: True
RADIUS_OF_NEIGHBOR_WITH_ROI: 2.4
GROUP_CFG_0:
NUM_LOCAL_VOXEL: [ 2, 2, 2 ]
MAX_NEIGHBOR_DISTANCE: 0.2
NEIGHBOR_NSAMPLE: -1
POST_MLPS: [ 32, 32 ]
GROUP_CFG_1:
NUM_LOCAL_VOXEL: [ 3, 3, 3 ]
MAX_NEIGHBOR_DISTANCE: 0.4
NEIGHBOR_NSAMPLE: -1
POST_MLPS: [ 32, 32 ]
x_conv3:
DOWNSAMPLE_FACTOR: 4
INPUT_CHANNELS: 64
NAME: VectorPoolAggregationModuleMSG
NUM_GROUPS: 2
LOCAL_AGGREGATION_TYPE: local_interpolation
NUM_REDUCED_CHANNELS: 32
NUM_CHANNELS_OF_LOCAL_AGGREGATION: 32
MSG_POST_MLPS: [128]
FILTER_NEIGHBOR_WITH_ROI: True
RADIUS_OF_NEIGHBOR_WITH_ROI: 4.0
GROUP_CFG_0:
NUM_LOCAL_VOXEL: [3, 3, 3]
MAX_NEIGHBOR_DISTANCE: 1.2
NEIGHBOR_NSAMPLE: -1
POST_MLPS: [64, 64]
GROUP_CFG_1:
NUM_LOCAL_VOXEL: [ 3, 3, 3 ]
MAX_NEIGHBOR_DISTANCE: 2.4
NEIGHBOR_NSAMPLE: -1
POST_MLPS: [ 64, 64 ]
x_conv4:
DOWNSAMPLE_FACTOR: 8
INPUT_CHANNELS: 64
NAME: VectorPoolAggregationModuleMSG
NUM_GROUPS: 2
LOCAL_AGGREGATION_TYPE: local_interpolation
NUM_REDUCED_CHANNELS: 32
NUM_CHANNELS_OF_LOCAL_AGGREGATION: 32
MSG_POST_MLPS: [ 128 ]
FILTER_NEIGHBOR_WITH_ROI: True
RADIUS_OF_NEIGHBOR_WITH_ROI: 6.4
GROUP_CFG_0:
NUM_LOCAL_VOXEL: [ 3, 3, 3 ]
MAX_NEIGHBOR_DISTANCE: 2.4
NEIGHBOR_NSAMPLE: -1
POST_MLPS: [ 64, 64 ]
GROUP_CFG_1:
NUM_LOCAL_VOXEL: [ 3, 3, 3 ]
MAX_NEIGHBOR_DISTANCE: 4.8
NEIGHBOR_NSAMPLE: -1
POST_MLPS: [ 64, 64 ]
POINT_HEAD:
NAME: PointHeadSimple
CLS_FC: [256, 256]
CLASS_AGNOSTIC: True
USE_POINT_FEATURES_BEFORE_FUSION: True
TARGET_CONFIG:
GT_EXTRA_WIDTH: [0.2, 0.2, 0.2]
LOSS_CONFIG:
LOSS_REG: smooth-l1
LOSS_WEIGHTS: {
'point_cls_weight': 1.0,
}
ROI_HEAD:
NAME: PVRCNNHead
CLASS_AGNOSTIC: True
SHARED_FC: [256, 256]
CLS_FC: [256, 256]
REG_FC: [256, 256]
DP_RATIO: 0.3
NMS_CONFIG:
TRAIN:
NMS_TYPE: nms_gpu
MULTI_CLASSES_NMS: False
NMS_PRE_MAXSIZE: 9000
NMS_POST_MAXSIZE: 512
NMS_THRESH: 0.8
TEST:
NMS_TYPE: nms_gpu
MULTI_CLASSES_NMS: False
NMS_PRE_MAXSIZE: 1024
NMS_POST_MAXSIZE: 100
NMS_THRESH: 0.7
SCORE_THRESH: 0.1
ROI_GRID_POOL:
GRID_SIZE: 6
NAME: VectorPoolAggregationModuleMSG
NUM_GROUPS: 2
LOCAL_AGGREGATION_TYPE: voxel_random_choice
NUM_REDUCED_CHANNELS: 30
NUM_CHANNELS_OF_LOCAL_AGGREGATION: 32
MSG_POST_MLPS: [ 128 ]
GROUP_CFG_0:
NUM_LOCAL_VOXEL: [ 3, 3, 3 ]
MAX_NEIGHBOR_DISTANCE: 0.8
NEIGHBOR_NSAMPLE: 32
POST_MLPS: [ 64, 64 ]
GROUP_CFG_1:
NUM_LOCAL_VOXEL: [ 3, 3, 3 ]
MAX_NEIGHBOR_DISTANCE: 1.6
NEIGHBOR_NSAMPLE: 32
POST_MLPS: [ 64, 64 ]
TARGET_CONFIG:
BOX_CODER: ResidualCoder
ROI_PER_IMAGE: 128
FG_RATIO: 0.5
SAMPLE_ROI_BY_EACH_CLASS: True
CLS_SCORE_TYPE: roi_iou
CLS_FG_THRESH: 0.75
CLS_BG_THRESH: 0.25
CLS_BG_THRESH_LO: 0.1
HARD_BG_RATIO: 0.8
REG_FG_THRESH: 0.55
LOSS_CONFIG:
CLS_LOSS: BinaryCrossEntropy
REG_LOSS: smooth-l1
CORNER_LOSS_REGULARIZATION: True
LOSS_WEIGHTS: {
'rcnn_cls_weight': 1.0,
'rcnn_reg_weight': 1.0,
'rcnn_corner_weight': 1.0,
'code_weights': [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
}
POST_PROCESSING:
RECALL_THRESH_LIST: [0.3, 0.5, 0.7]
SCORE_THRESH: 0.4
OUTPUT_RAW_SCORE: False
EVAL_METRIC: kitti
NMS_CONFIG:
MULTI_CLASSES_NMS: False
NMS_TYPE: nms_gpu
NMS_THRESH: 0.1
NMS_PRE_MAXSIZE: 4096
NMS_POST_MAXSIZE: 500
OPTIMIZATION:
BATCH_SIZE_PER_GPU: 4
NUM_EPOCHS: 80
OPTIMIZER: adam_onecycle
LR: 0.01
WEIGHT_DECAY: 0.001
MOMENTUM: 0.9
MOMS: [0.95, 0.85]
PCT_START: 0.4
DIV_FACTOR: 10
DECAY_STEP_LIST: [35, 45]
LR_DECAY: 0.1
LR_CLIP: 0.0000001
LR_WARMUP: False
WARMUP_EPOCH: 1
GRAD_NORM_CLIP: 10
3、sectorized proposal-centric keypoint sampling strategy
在PV-RCNN中关键点采样是非常重要的,使用聚合的关键点特征补齐了点的体素表达,提升了最终proposal refinement的效果。但是在之前PV-RCNN中的使用的关键点采样算法是FPS(Farthest Point Sampling),该算法有两个主要的缺陷
1:该算法的时间复杂度是O(n^2),这会严重拖慢网络的训练和推理的效率,尤其是在大场景的点云检测中。
2:该算法直接在大范围的点云中进行关键点采样,事实上只会有很小一部分采样得到的关键点属于前景点,大部分关键点属于背景点;然而在proposal refinement阶段中,背景点对优化是无意义的,因为在进行666 的ROI-grid Pooling的时候只会采用每个grid point周围的关键点进行融合。
所以作者为了解决这个问题,在PV-RCNN++中提出了更为有效的关键点采样策略–> Sectorized Proposal-Centric (SPC) Keypoint Sampling。
既然已经知道了问题所在,那么解决问题也会围绕这两个点出发(为了和论文中图片展示一致,这里先解决上述的第二个问题,再解决第一个问题)
2(Proposal-Centric):既然大部分背景点都是没有用的,那么不妨就直接在第一阶段提出的proposal中附近进行采样,对应下图的左边两张图片,具体实现的公式如下:

注1:原始点云为 P,每个3Dproposal的中心点和尺度大小分别为C和D;其中dxj , dyj , dzj为proposal的长宽高;r^(s)为proposal中心点向外扩张的最小半径(最小的原因是要先取(dxj , dyj , dzj)一半的最大值),实现中该超参数被设置为1.6米。 P’为经过选取后保留下来的在proposal附近的点。

1(Sectorized):同时为了解决FPS时间复杂度为O(n^2),致使对大场景采样慢的问题;最直接的想法就是将原始的点云分成多个子集,并在每个子集上分别进行采样,因此作者直接基于每帧点云的中心点,采用

将点云分成多个子集,如下图右边两张图片所示。

其中在每个子集点云中继续采用FPS算法进行关键点采样,因为FPS算法可以保证采样的关键点均匀的分布在原始点云场景中;同时由于得到的每个子集点云都是独立的,所以每个子集点云都可以并行运行在gpu上,进一步加速了点云的关键点采样过程。

代码在:pcdet/models/backbones_3d/pfe/voxel_set_abstraction.py
def sectorized_proposal_centric_sampling(self, roi_boxes, points):
"""
Args:
roi_boxes: (M, 7 + C) 该帧中的proposal,(128, 7)经过正负样本采样后
points: (N, 3) 该帧中原始点云数据
Returns:
sampled_points: (N_out, 3)
"""
# 采集每个proposal附近的点
sampled_points, _ = sample_points_with_roi(
# 经过正负样本选取的128个ROI
rois=roi_boxes,
# 原始点云
points=points,
# 采样的最小半径为1.6米
sample_radius_with_roi=self.model_cfg.SPC_SAMPLING.SAMPLE_RADIUS_WITH_ROI,
# 该参数用于计算距离矩阵时,防止内存爆炸
num_max_points_of_part=self.model_cfg.SPC_SAMPLING.get('NUM_POINTS_OF_EACH_SAMPLE_PART', 200000)
)
# 将场景分割成NUM_SECTORS个子集,NUM_SECTORS=6
sampled_points = sector_fps(
points=sampled_points,
# 点的数量,KITTI中为2048个点,Waymo中为4096个点
num_sampled_points=self.model_cfg.NUM_KEYPOINTS,
num_sectors=self.model_cfg.SPC_SAMPLING.NUM_SECTORS # 6
)
return sampled_points
proposal-centric采样
def sample_points_with_roi(rois, points, sample_radius_with_roi, num_max_points_of_part=200000):
"""
Args:
rois: (M, 7 + C)
points: (N, 3)
sample_radius_with_roi:
num_max_points_of_part:
Returns:
sampled_points: (N_out, 3)
"""
if points.shape[0] < num_max_points_of_part:
# 计算每个点到每个proposal重点的欧氏距离 shape : (num_of_raw_points, num_of_proposal)
distance = (points[:, None, :] - rois[None, :, 0:3]).norm(dim=-1)
# 找到每个raw point到距离自己最近proposal的点的距离和索引
min_dis, min_dis_roi_idx = distance.min(dim=-1)
# 计算得到每个点属于自己最近proposal的长宽高的一半,
# 并使用norm方法在最后一个维度求取L2范数,与原论文中直接取长宽高最大值的一半有出入
roi_max_dim = (rois[min_dis_roi_idx, 3:6] / 2).norm(dim=-1)
# 得到距离小于一半长宽高欧氏距离+最小半径1.6米的点的索引
point_mask = min_dis < roi_max_dim + sample_radius_with_roi
else: # 原始点的数量过大时使用,防止距离计算导致内存爆炸
start_idx = 0
point_mask_list = []
while start_idx < points.shape[0]:
distance = (points[start_idx:start_idx + num_max_points_of_part, None, :] - rois[None, :, 0:3]).norm(dim=-1)
min_dis, min_dis_roi_idx = distance.min(dim=-1)
roi_max_dim = (rois[min_dis_roi_idx, 3:6] / 2).norm(dim=-1)
cur_point_mask = min_dis < roi_max_dim + sample_radius_with_roi
point_mask_list.append(cur_point_mask)
start_idx += num_max_points_of_part
point_mask = torch.cat(point_mask_list, dim=0)
# 根据点point_mask索引出被选中的原始点 shape : (num_of_point_selected_by_dist, 3)
sampled_points = points[:1] if point_mask.sum() == 0 else points[point_mask, :]
return sampled_points, point_mask
sectored代码段:
def sector_fps(points, num_sampled_points, num_sectors):
"""
Args:
points: (N, 3)
num_sampled_points: int
num_sectors: int
Returns:
sampled_points: (N_out, 3)
"""
# 计算出每篇扇区的弧度大小 = 1.0472
sector_size = np.pi * 2 / num_sectors
# 根据点的坐标使用arctan反求点的角度,同时加np.pi将PCDet坐标系下的点转换到笛卡尔坐标系下
point_angles = torch.atan2(points[:, 1], points[:, 0]) + np.pi
# 得到每个点在属于哪个扇区
sector_idx = (point_angles / sector_size).floor().clamp(min=0, max=num_sectors)
xyz_points_list = []
xyz_batch_cnt = []
num_sampled_points_list = []
# 根据每个扇区中点的个数来采样,其中KITTI采样2048个点,Waymo采样4096个点
for k in range(num_sectors):
mask = (sector_idx == k)
cur_num_points = mask.sum().item()
if cur_num_points > 0:
xyz_points_list.append(points[mask])
xyz_batch_cnt.append(cur_num_points)
ratio = cur_num_points / points.shape[0]
num_sampled_points_list.append(
# 此处代码计算会多出一个点
min(cur_num_points, math.ceil(ratio * num_sampled_points))
)
if len(xyz_batch_cnt) == 0:
xyz_points_list.append(points)
xyz_batch_cnt.append(len(points))
num_sampled_points_list.append(num_sampled_points)
print(f'Warning: empty sector points detected in SectorFPS: points.shape={points.shape}')
xyz = torch.cat(xyz_points_list, dim=0)
xyz_batch_cnt = torch.tensor(xyz_batch_cnt, device=points.device).int()
sampled_points_batch_cnt = torch.tensor(num_sampled_points_list, device=points.device).int()
# 每个扇区并行执行最远点采样
sampled_pt_idxs = pointnet2_stack_utils.stack_farthest_point_sample(
xyz.contiguous(), xyz_batch_cnt, sampled_points_batch_cnt
).long()
# 根据点的ID选取出采样得到的点
sampled_points = xyz[sampled_pt_idxs]
return sampled_points
4、VectorPool aggregation
PV-RCNN中作何就提出了从局部聚合有用的特征来提升refinement的效果,所以在PV-RCNN中作者就采用了SA(Set Abstraction)操作来分别在每个关键点特征集合的特征和ROI grid pooling中进行使用。但是SA操作在大型的点云数据中消耗的资源和也是庞大的,这样使得网络难以在端侧运行,所以作者提出了 Local Vector Representaion for Structure-Preserved Local Feature Learning。这行专业术简单点说就是 带有空间结构信息的vector特征。
既然如此问题就找到了
1、进行特征融合的时候需要保留点云的空间结构信息(因为SA中直接使用max-pooling操作,这样就抛弃了这块局部点云区域的空间结构信息,阻碍了局部聚合特征的表达能力)
2、减小PV-RCNN中采用SA进行特征聚合的资源消耗
解决方案:
1、 根据spc中选取出来的关键点来生成一个nnn大小的grid-voxel,并采用pointnet++中的inverse distance weighted方式来从点的特征中插值生成每个grid-voxel的特征,这样就得到了一个关键点的grid特征了,对于如何保持空间结构信息,作者这里采用了对每个volume中使用独立的参数和通道进行学习,然后将nnn这个grid-voxel根据编号000->001->xxx->nnn的顺序拼接在一起,这样就保留了每个关键点中不同grid-voxel的空间尺度特征。
注1:实现中分别从raw point、四倍下采样、八倍下采样的特征层中进行关键点的特征聚合操作
注2:每层的grid-voxel的特征聚合均采用了MSG(Multi-Scale Grouping)的形式,分别在两个不同的半径上进行聚合操作后在拼接融合
注3:具体的代码实现中,顺序是直接通过插值生成grid voxel的特征,按照顺序拼接后,直接使用conv1d来实现文中所说的独立权重参数和独立的特征通道,与文中给的图片顺序稍有不同

2、为了减少计算量和参数的大小,作者根据Fishnet中的方法采用了channel summation的操作, 并放在特征插值逆距离差值之前来减少后续操作的计算量;实现也非常简单,只有一行代码;说白了就是将大维度分拆后直接对位相加。
features = features.view(N, -1, self.num_reduced_channels).sum(dim=1)
PV-RCNN中的聚合代码部分使用if中第一个分支:
代码在:pcdet/models/backbones_3d/pfe/voxel_set_abstraction.py
def aggregate_keypoint_features_from_one_source(
batch_size, aggregate_func, xyz, xyz_features, xyz_bs_idxs, new_xyz, new_xyz_batch_cnt,
filter_neighbors_with_roi=False, radius_of_neighbor=None, num_max_points_of_part=200000, rois=None
):
"""
Args:
aggregate_func: PV-RCNN:PointNet++的SA操作; PV-RCNN++:VectorPoolAggregationModuleMSG
xyz: (N, 3)
xyz_features: (N, C)
xyz_bs_idxs: (N)
new_xyz: (M, 3)
new_xyz_batch_cnt: (batch_size), [N1, N2, ...]
filter_neighbors_with_roi: True/False 用于判断PV-RCNN和PV-RCNN++
radius_of_neighbor: float
num_max_points_of_part: int
rois: (batch_size, num_rois, 7 + C)
Returns:
"""
# 用于存储一帧中,原始点云的总数
xyz_batch_cnt = xyz.new_zeros(batch_size).int()
if filter_neighbors_with_roi: # PVRCNN++条件下
point_features = torch.cat((xyz, xyz_features), dim=-1) if xyz_features is not None else xyz
point_features_list = []
for bs_idx in range(batch_size): # 每帧点云独立处理
bs_mask = (xyz_bs_idxs == bs_idx) # 选取当前帧点云的mask
_, valid_mask = sample_points_with_roi(#进行SPC采样
rois=rois[bs_idx], points=xyz[bs_mask],
sample_radius_with_roi=radius_of_neighbor, num_max_points_of_part=num_max_points_of_part,
)
point_features_list.append(point_features[bs_mask][valid_mask])
# 一批数据中每帧被保留下来的点云的个数
xyz_batch_cnt[bs_idx] = valid_mask.sum()
###########################################################################################################
# 经过SPC后每帧点云中被保留的在proposal附近的原始点云数据
valid_point_features = torch.cat(point_features_list, dim=0)
# 取出SPC选取出来的关键点的xyz坐标
xyz = valid_point_features[:, 0:3]
# 取出SPC选取出来的关键点的特征数据,在raw point特整层中是该点的雷达反射率
xyz_features = valid_point_features[:, 3:] if xyz_features is not None else None
else: # PV-RCNN条件下
# 用于计算一个batch中每帧的原始点云的个数 shape (N0, N1, N2, N3)
for bs_idx in range(batch_size):
xyz_batch_cnt[bs_idx] = (xyz_bs_idxs == bs_idx).sum()
# pooled_points : (2048*batch, 3) pooled_features : (2048*batch, 32)
pooled_points, pooled_features = aggregate_func(
xyz=xyz.contiguous(),
xyz_batch_cnt=xyz_batch_cnt,
new_xyz=new_xyz,
new_xyz_batch_cnt=new_xyz_batch_cnt,
features=xyz_features.contiguous(),
)
return pooled_features
vector pool操作代码在pcdet/ops/pointnet2/pointnet2_stack/pointnet2_modules.py:
class VectorPoolAggregationModule(nn.Module): # PV-RCNN++
def __init__(
self, input_channels, num_local_voxel=(3, 3, 3), local_aggregation_type='local_interpolation',
num_reduced_channels=30, num_channels_of_local_aggregation=32, post_mlps=(128,),
max_neighbor_distance=None, neighbor_nsample=-1, neighbor_type=0, neighbor_distance_multiplier=2.0):
super().__init__()
self.num_local_voxel = num_local_voxel
self.total_voxels = self.num_local_voxel[0] * self.num_local_voxel[1] * self.num_local_voxel[2]
self.local_aggregation_type = local_aggregation_type
assert self.local_aggregation_type in ['local_interpolation', 'voxel_avg_pool', 'voxel_random_choice']
self.input_channels = input_channels
self.num_reduced_channels = input_channels if num_reduced_channels is None else num_reduced_channels
self.num_channels_of_local_aggregation = num_channels_of_local_aggregation
self.max_neighbour_distance = max_neighbor_distance
self.neighbor_nsample = neighbor_nsample
self.neighbor_type = neighbor_type # 1: ball, others: cube
if self.local_aggregation_type == 'local_interpolation':
self.local_interpolate_module = VectorPoolLocalInterpolateModule(
mlp=None, num_voxels=self.num_local_voxel,
max_neighbour_distance=self.max_neighbour_distance,
nsample=self.neighbor_nsample,
neighbor_type=self.neighbor_type,
neighbour_distance_multiplier=neighbor_distance_multiplier,
)
num_c_in = (self.num_reduced_channels + 9) * self.total_voxels
else:
self.local_interpolate_module = None
num_c_in = (self.num_reduced_channels + 3) * self.total_voxels
num_c_out = self.total_voxels * self.num_channels_of_local_aggregation
self.separate_local_aggregation_layer = nn.Sequential(
nn.Conv1d(num_c_in, num_c_out, kernel_size=1, groups=self.total_voxels, bias=False),
nn.BatchNorm1d(num_c_out),
nn.ReLU()
)
post_mlp_list = []
c_in = num_c_out
for cur_num_c in post_mlps:
post_mlp_list.extend([
nn.Conv1d(c_in, cur_num_c, kernel_size=1, bias=False),
nn.BatchNorm1d(cur_num_c),
nn.ReLU()
])
c_in = cur_num_c
self.post_mlps = nn.Sequential(*post_mlp_list)
self.num_mean_points_per_grid = 20
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Conv1d):
nn.init.kaiming_normal_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if isinstance(m, nn.BatchNorm2d) or isinstance(m, nn.BatchNorm1d):
nn.init.constant_(m.weight, 1.0)
nn.init.constant_(m.bias, 0)
def extra_repr(self) -> str:
ret = f'radius={self.max_neighbour_distance}, local_voxels=({self.num_local_voxel}, ' \
f'local_aggregation_type={self.local_aggregation_type}, ' \
f'num_c_reduction={self.input_channels}->{self.num_reduced_channels}, ' \
f'num_c_local_aggregation={self.num_channels_of_local_aggregation}'
return ret
def vector_pool_with_voxel_query(self, xyz, xyz_batch_cnt, features, new_xyz, new_xyz_batch_cnt):
use_xyz = 1
pooling_type = 0 if self.local_aggregation_type == 'voxel_avg_pool' else 1
new_features, new_local_xyz, num_mean_points_per_grid, point_cnt_of_grid = pointnet2_utils.vector_pool_with_voxel_query_op(
xyz, xyz_batch_cnt, features, new_xyz, new_xyz_batch_cnt,
self.num_local_voxel[0], self.num_local_voxel[1], self.num_local_voxel[2],
self.max_neighbour_distance, self.num_reduced_channels, use_xyz,
self.num_mean_points_per_grid, self.neighbor_nsample, self.neighbor_type,
pooling_type
)
self.num_mean_points_per_grid = max(self.num_mean_points_per_grid, num_mean_points_per_grid.item())
num_new_pts = new_features.shape[0]
new_local_xyz = new_local_xyz.view(num_new_pts, -1, 3) # (N, num_voxel, 3)
new_features = new_features.view(num_new_pts, -1, self.num_reduced_channels) # (N, num_voxel, C)
new_features = torch.cat((new_local_xyz, new_features), dim=-1).view(num_new_pts, -1)
return new_features, point_cnt_of_grid
@staticmethod
def get_dense_voxels_by_center(point_centers, max_neighbour_distance, num_voxels):
"""
Args:
point_centers: (N, 3)
max_neighbour_distance: float
num_voxels: [num_x, num_y, num_z]
Returns:
voxel_centers: (N, total_voxels, 3)
"""
R = max_neighbour_distance
device = point_centers.device
x_grids = torch.arange(-R + R / num_voxels[0], R - R / num_voxels[0] + 1e-5, 2 * R / num_voxels[0],
device=device)
y_grids = torch.arange(-R + R / num_voxels[1], R - R / num_voxels[1] + 1e-5, 2 * R / num_voxels[1],
device=device)
z_grids = torch.arange(-R + R / num_voxels[2], R - R / num_voxels[2] + 1e-5, 2 * R / num_voxels[2],
device=device)
x_offset, y_offset, z_offset = torch.meshgrid(x_grids, y_grids, z_grids) # shape: [num_x, num_y, num_z]
xyz_offset = torch.cat((
x_offset.contiguous().view(-1, 1),
y_offset.contiguous().view(-1, 1),
z_offset.contiguous().view(-1, 1)), dim=-1
)
voxel_centers = point_centers[:, None, :] + xyz_offset[None, :, :]
return voxel_centers
def vector_pool_with_local_interpolate(self, xyz, xyz_batch_cnt, features, new_xyz, new_xyz_batch_cnt):
"""
Args:
xyz: (N, 3)
xyz_batch_cnt: (batch_size)
features: (N, C)
new_xyz: (M, 3)
new_xyz_batch_cnt: (batch_size)
Returns:
new_features: (M, total_voxels * C)
"""
# 得到每个关键点附近密集的sub-voxels,
# 在raw-point上领域距离为0.2米和0.4米,grid_size为[2, 2, 2]
# 在'x_conv3'上领域距离为1.2米和2.4米,grid_size为[3, 3, 3]
# 在'x_conv4'上领域距离为2.4米和4.8米,grid_size为[3, 3, 3]
# shape : (num_of_keypoints, grid_size^3)
voxel_centers = self.get_dense_voxels_by_center(
point_centers=new_xyz, max_neighbour_distance=self.max_neighbour_distance, num_voxels=self.num_local_voxel
) # (M1 + M2 + ..., total_voxels, 3)
# shape : (num_of_keypoints * grid_size^3, output_channel)
# 根据附近相邻点的特征基于逆距离权重的插值操作,与PointNet++分割分支的上采样操作中的一样
# 插值得到每个sub-voxel的特征值,
voxel_features = self.local_interpolate_module.forward(
support_xyz=xyz, support_features=features, xyz_batch_cnt=xyz_batch_cnt,
new_xyz=new_xyz, new_xyz_grid_centers=voxel_centers, new_xyz_batch_cnt=new_xyz_batch_cnt
) # ((M1 + M2 ...) * total_voxels, C)
# shape : (num_of_keypoints * grid_size^3, output_channel) -> (num_of_keypoints, grid_size^3 * output_channel)
voxel_features = voxel_features.contiguous().view(-1, self.total_voxels * voxel_features.shape[-1])
return voxel_features
def forward(self, xyz, xyz_batch_cnt, new_xyz, new_xyz_batch_cnt, features, **kwargs):
"""
:param xyz: (N1 + N2 ..., 3) tensor of the xyz coordinates of the features
:param xyz_batch_cnt: (batch_size), [N1, N2, ...]
:param new_xyz: (M1 + M2 ..., 3)
:param new_xyz_batch_cnt: (batch_size), [M1, M2, ...]
:param features: (N1 + N2 ..., C) tensor of the descriptors of the the features
:return:
new_xyz: (M1 + M2 ..., 3) tensor of the new features' xyz
new_features: (M1 + M2 ..., \sum_k(mlps[k][-1])) tensor of the new_features descriptors
"""
N, C = features.shape
assert C % self.num_reduced_channels == 0, \
f'the input channels ({C}) should be an integral multiple of num_reduced_channels({self.num_reduced_channels})'
# 论文中采用的channel summation 操作, 操作如下:
# (keypoints, channel)-> (keypoints, N ,num_reduced_channels)-> (keypoints, num_reduced_channels)
# 在raw point特整层不需要使用,没有这么多通道
features = features.view(N, -1, self.num_reduced_channels).sum(dim=1)
# 论文中提到的另外两种聚合方式,会产生太多的零元素,降低网络的精度;
# 其中voxel_avg_pool直接简单的对每个sub-voxel中所拥有的点进行相加再平均,
# voxel_random_choice直接随机选取一个在该sub-voxel中的点用来表示该sub-voxel
if self.local_aggregation_type in ['voxel_avg_pool', 'voxel_random_choice']:
vector_features, point_cnt_of_grid = self.vector_pool_with_voxel_query(
xyz=xyz, xyz_batch_cnt=xyz_batch_cnt, features=features,
new_xyz=new_xyz, new_xyz_batch_cnt=new_xyz_batch_cnt)
# PV-RCNN++中所采用了pointnet++中基于距离加权的方法进行插值
elif self.local_aggregation_type == 'local_interpolation':
# shape : (num_of_keypoint, C)
vector_features = self.vector_pool_with_local_interpolate(
xyz=xyz, xyz_batch_cnt=xyz_batch_cnt, features=features,
new_xyz=new_xyz, new_xyz_batch_cnt=new_xyz_batch_cnt
) # (M1 + M2 + ..., total_voxels * C)
else:
raise NotImplementedError
# shape : (num_of_keypoints, C) --> (1, C, num_of_keypoint) 通道维度放在中间,方便进行卷积操作
vector_features = vector_features.permute(1, 0)[None, :, :] # (1, num_voxels * C, M1 + M2 ...)
# 对每个grid的特征进行独立的参数,此处实现中使用了conv1d来完成, Conv1d->BN1d->Relu
new_features = self.separate_local_aggregation_layer(vector_features)
# 后处理后的两个MLP操作
new_features = self.post_mlps(new_features)
# shape : (num_of_keypoints, out_channel)
new_features = new_features.squeeze(dim=0).permute(1, 0)
return new_xyz, new_features
PV-RCNN++ MSG:Multi-scale Grouping MRG:Multi-resolution grouping
class VectorPoolAggregationModuleMSG(nn.Module):
def __init__(self, input_channels, config):
super().__init__()
self.model_cfg = config
self.num_groups = self.model_cfg.NUM_GROUPS
self.layers = []
c_in = 0
for k in range(self.num_groups):
cur_config = self.model_cfg[f'GROUP_CFG_{k}']
cur_vector_pool_module = VectorPoolAggregationModule(
input_channels=input_channels, num_local_voxel=cur_config.NUM_LOCAL_VOXEL,
post_mlps=cur_config.POST_MLPS,
max_neighbor_distance=cur_config.MAX_NEIGHBOR_DISTANCE,
neighbor_nsample=cur_config.NEIGHBOR_NSAMPLE,
local_aggregation_type=self.model_cfg.LOCAL_AGGREGATION_TYPE,
num_reduced_channels=self.model_cfg.get('NUM_REDUCED_CHANNELS', None),
num_channels_of_local_aggregation=self.model_cfg.NUM_CHANNELS_OF_LOCAL_AGGREGATION,
neighbor_distance_multiplier=2.0
)
self.__setattr__(f'layer_{k}', cur_vector_pool_module)
c_in += cur_config.POST_MLPS[-1]
c_in += 3 # use_xyz
shared_mlps = []
for cur_num_c in self.model_cfg.MSG_POST_MLPS:
shared_mlps.extend([
nn.Conv1d(c_in, cur_num_c, kernel_size=1, bias=False),
nn.BatchNorm1d(cur_num_c),
nn.ReLU()
])
c_in = cur_num_c
self.msg_post_mlps = nn.Sequential(*shared_mlps)
def forward(self, **kwargs):
features_list = []
for k in range(self.num_groups):
cur_xyz, cur_features = self.__getattr__(f'layer_{k}')(**kwargs)
features_list.append(cur_features)
# 讲两个不同尺度下得到的local vector representaion进行拼接操作
features = torch.cat(features_list, dim=-1)
# 将关键点的xyz坐标和对应的该层下获取的特征进行拼接后再进行融合操作
features = torch.cat((cur_xyz, features), dim=-1)
# (1, C, N) 维度置换,通道放中间,方便进行卷积操作
features = features.permute(1, 0)[None, :, :]
# 一个mlp层,用于将两个不同尺度的local vector representaion进行融合
new_features = self.msg_post_mlps(features)
new_features = new_features.squeeze(dim=0).permute(1, 0) # (N, C)
return cur_xyz, new_features
5、结果展示
由于作者并没有重新将PV-RCNN++在KITTI数据集上重新进行训练,所以这里采用Waymo数据集中的评估结果

注:以上结果均采用Waymo数据集中20%的数据,并在8张GTX 1080Ti GPUs进行训练,评估数据集使用waymo中所有的evalution数据且根据Waymo evaluation metrics 1.2版本进行评估测试。
6、消融实验
此处的消融实验均采用waymo数据集完成,同时所有的实验数据均在三个类别上进行训练且Waymo evaluation metrics是1.2版本。
作者这里进行了详细的消融实验,但是有很多是与PV-RCNN中大同小异的,这里描述几个我个人认为与PV-RCNN++关系紧密的几个。
1、proposal-centric && keypoint sampling

其中
PC-Filter为采用了proposal-centric的方法来过滤关键点
Random Sampling为直接从原始点云中随机选取关键点,不使用任何关键点选取方法
Voxelized-FPS-Voxel首先将原始关键点体素化(voxelize)来减少点(i.e. voxels)的数量,然后采用FPS算法从非空的voxel为中心来选取关键点
Voxelized-FPS-Point中的关键点则直接从被选中的voxel中随机进行选取
RandomParallel-FPS将原始点云分成几个不同的部分,并在这几个部分中采用FPS的方法来平行的筛选关键点
Sectorized-FPS就是PV-RCNN++中正式使用的关键点采样方法
1、根据结果可以看出,采用基于提议的(proposal-centric)关键点采样策略可以让采样得到的关键点更加聚集在物体上,同时减少了大部分无效关键点,加快了网络的速度。(133ms vs 27ms)
2、作者在这里也再次强调了筛选的关键点的均匀分布对于二阶段网络中的proposal refinement十分重要;一个好的关键点分布应该覆盖更多的原始点数据这样使得特征聚合得到的特征信息更加丰富。当然这里作者提出了一个覆盖率的计算公式,这里不做详细的介绍了,感兴趣的小伙伴可以自行查看原文章,覆盖率计算的结果已经展示在上图中,总的来说就是 Sectorized-FPS可以产生出均匀分布的且原始点覆盖率高的关键点。(27ms vs 9ms)
2、Effects of VectorPool Aggregation

其中
FPS代表最远点采样
SPC-FPS代表sectorized proposal-centric keypoint sampling
VSA代表voxel set abstraction
SA代表set abstraction
VP代表VectorPool aggregation
从结果中可以看出,vectorpool降低了在PV-RCNN中VSA模块的计算量和内存消耗,同时作者也进一步的分析了VP模块中起到关键作用的channel summation模块。
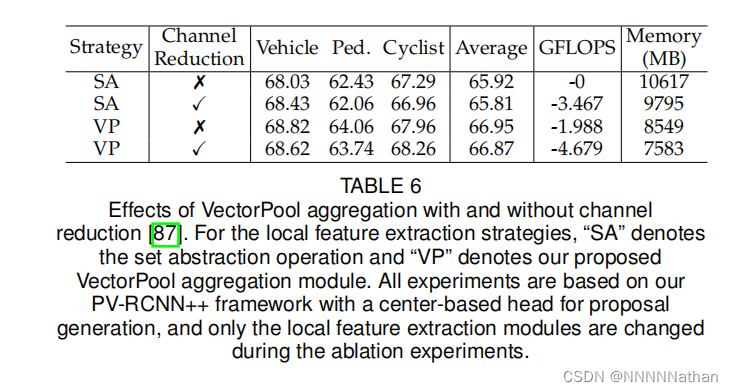
结果可以得出,使用channel summation 在两种不同的(VSA、VectorPool)操作中均可以在不影响结果的情况下减少显存和计算量。
3、Effects of Different Feature Aggregation Strategies for Local Voxels
在实现中作者也给出了另外两种方式来进行不同位置的特征编码,实现中作者使用的是Poin
net++中的inverse distance weighted的插值方式来对关键点生成的sub-voxel根据附近的点的特征进行插值生成每个sub-voxel的特征,但是作者也考虑过其他的两种方式,一种是直接将每个sub-voxel中的点进行平均,另外一种是随机选择一个在sub-voxel中的点的特征来代表这个sub-voxel,这两种方式均会使得哪些sub-voxel中没有点的部分变成0值,产生大量的0元素,这毫无意义,所以作者在这里选择了插值的方式。
基于插值的方式尤其是在对那些小物体(行车、cyclist)等对象的检测非常有帮助,因为这些对象本身点就是非稀疏,因此使用插值的方式可以让每个sub-voxel都从领域的原始点特征中产生有效的特征( 即使超出这个sub-voxel本身范围也是可以的,因为这里也设置了采样半径,同grid-size中的SA操作),具体的结果如下图所示。
4、Effects of Separate Local Kernel Weights in VectorPool Aggregation

Original: https://blog.csdn.net/qq_41366026/article/details/124254068
Author: NNNNNathan
Title: PV-RCNN++网络结构和代码解析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/682157/
转载文章受原作者版权保护。转载请注明原作者出处!