

Libra R-CNN: Towards Balanced Learning for Object Detection
*
– Abstract
– Introduction
–
+ Sample level imbalance
+ Feature level imbalance
+ Objective level imbalance
– Related work
–
+ Sample level imbalance
+ Feature level imbalance
+ Objective level imbalance
– Methodology
–
+ IoU-balanced Sampling
+ Balanced Feature Pyramid
+ Balanced L1 Loss
– Experiments
–
+ Dataset and Evaluation Metrics
+ Implement Details
+ Main Results
+ Ablation Experiments
+
* Overall Ablation Studies(整体消融研究)
* IoU-balanced Sampling
* Balanced Feature Pyramid
* Balanced L1 Loss
* Ablation Studies on IoU-balanced Sampling.
* Ablation Studies on Balanced Feature Pyramid.
* Ablation Studies on Balanced L1 Loss.
– Conclusion
作者:Jiangmiao Pang,Kai Chen, Jianping Shi,Huajun Feng, Wanli Ouyang, Dahua Lin,Zhejiang University,The Chinese University of Hong Kong ,SenseTime Research , The University of Sydney
发表:该文章发表在CVPR 2019,IJCV采纳了其扩展版本
算法代码:https://github.com/OceanPang/
mmdetection:一个基于 PyTorch 的目标检测开源工具箱。它是 OpenMMLab 项目的一部分。
论文自译,有参考机翻(仅供学习交流用,侵删)。
Abstract
Compared with model architectures, the training process, which is also crucial to the success of detectors, has received relatively less attention in object detection.
与模型结构相比,实际的训练过程对于检测的准确率也是有相当大的作用,但在目标检测的研究中,训练过程受到的关注却相对较少。
In this work, we carefully revisit the standard training practice of detectors, and find that the detection performance is often limited by the imbalance during the training process, which generally consists in three levels – sample level, feature level, and objective level.
在这次的工作中,我们仔细回顾了目标检测的标准实践过程,然后发现目标检测的效果常常受到训练过程的imbalance(在此译为失衡)的限制。而训练过程的失衡主要体现在三个方面:样本方面,特征方面,以及目标方面。
To mitigate the adverse effects caused thereby, we propose Libra R-CNN, a simple but effective framework towards balanced learning for object detection.
为了缓和训练过程的失衡造成的消极影响,我们提出了一种简单却高效的关注于平衡的训练的目标检测模型,也即Libra R-CNN。
It integrates three novel components: IoU-balanced sampling, balanced feature pyramid, and balanced L1 loss, respectively for reducing the imbalance at sample, feature, and objective level. Benefitted from the overall balanced design, Libra R-CNN significantly improves the detection performance.
它融合了三个新元素:IoU-balanced sampling(IoU平衡抽样),balanced feature pyramid(平衡特征金字塔),balanced L1 loss(L1平衡损失函数),分别用于缓和样本,特征,目标层面的不平衡性。因着Libra R-CNN的平衡性设计,这个算法使得检测的效果得到了较大的提升。
Without bells and whistles, it achieves 2.5 points and 2.0 points higher Average Precision (AP) than FPN Faster R-CNN and RetinaNet respectively on MSCOCO.
它在MSCOCO数据集上的结果,在平均精度上比FPN Faster RCNN 与 RetinaNet 分别高2.5与2.0。
Introduction
Along with the advances in deep convolutional networks, recent years have seen remarkable progress in object detection.
随着深度卷积网络研究的不断发展,近年来目标检测方面也取得了显著进步。
A number of detection frameworks such as Faster R-CNN , RetinaNet [20], and Cascaded R-CNN [3] have been developed, which have substantially pushed forward the state of the art.
很多目标检测方法,比如Faster R-CNN , RetinaNet , and Cascaded R-CNN,相继出现,进一步推动了目标检测技术的进步。
Despite the apparent differences in the pipeline architectures, e.g. single-stage vs. two-stage, modern detection frameworks mostly follow a common training paradigm, namely, sampling regions, extracting features therefrom, and then jointly recognizing the categories and refining the locations under the guidance of a standard multi-task objective function
虽然这些算法彼此之间有着明显的不同,现代的目标检测算法大部分遵循一个共同的训练范式,即区域采样,特征提取,与在一个标准的多任务目标函数中检测出目标类别与其位置。
Based on this paradigm, the success of the object detector training depends on three key aspects:
基于这个范式,我们可以得出目标检测训练的成功取决于以下三个主要方面:
(1) whether the selected region samples are representative,
采样的所选区域是否具有代表性;
(2) whether the extracted visual features are fully utilized, and
所提取的特征是否被充分应用;
(3) whether the designed objective function is optimal.
所采用的目标函数(或者称评价函数)是否是最优的;
However, our study reveals that the typical training process is significantly imbalanced in all these aspects.
然而,我们的研究揭示了一般的训练过程在以上三个方面的处理中均表现出明显的失衡。
This imbalance issue prevents the power of well-designed model architectures from being fully exploited, thus limiting the overall performance,
这种失衡使得即使设计得非常好的算法也无法充分发挥其作用,从而限制了它的训练效果,如图一所示。
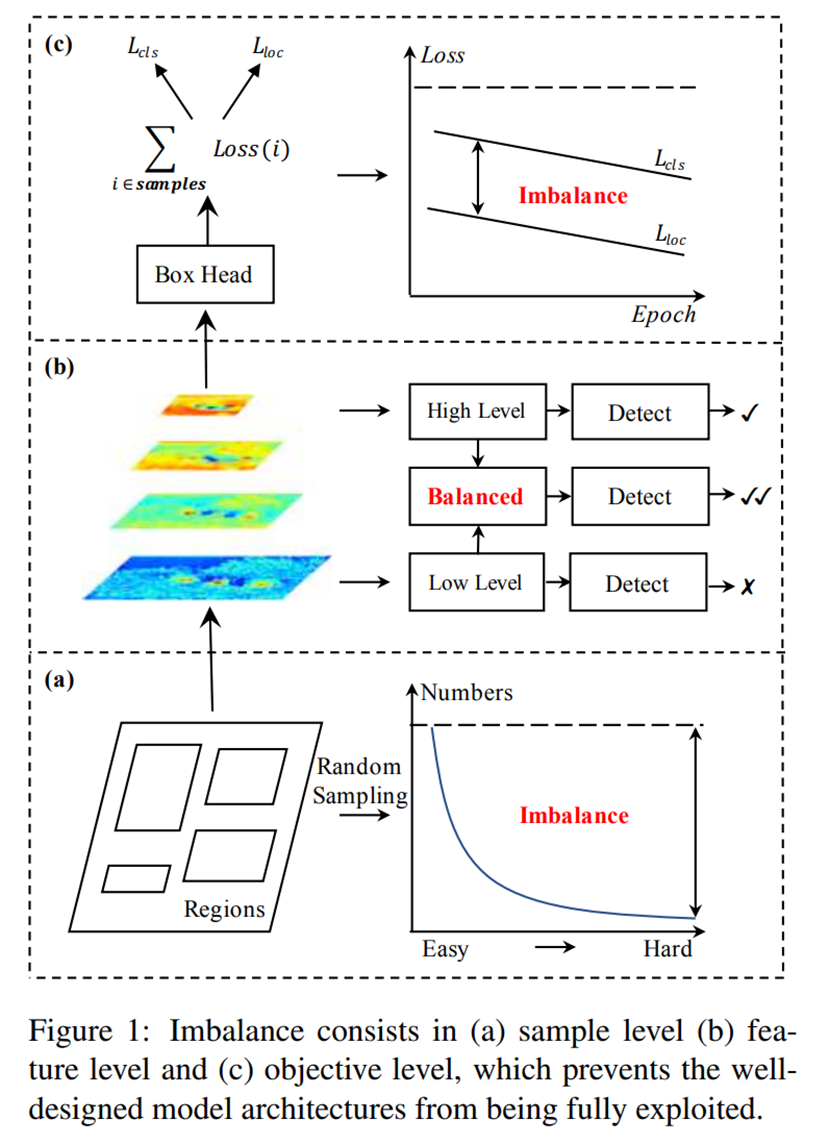

我们将分别介绍一下上面三个方面:
; Sample level imbalance
其一是采样层面的失衡。
When training an object detector, hard samples are particularly valuable as they are more effective to improve the detection performance.
当我们训练一个目标检测器的时候,困难样本对我们非常重要,因为他们对于提升目标检测的效果比简单样本更加重要。
However, the random sampling scheme usually results in the selected samples dominated by easy ones.
但是,随机采样常常招致所选样本中充斥着大量的简单样本。
The popularized hard mining methods, e.g. OHEM [29], can help driving the focus towards hard samples. However, they are often sensitive to noise labels and incurring considerable memory and computing costs.
比较流行的困难样本挖掘方法,比如OHEM,可以使采样的注意力更集中于困难样本。但是,这些方法往往对于噪声点敏感,而且会招致相当的存储与计算成本。
Focal loss also alleviates this problem in single-stage detectors, but is found little improvement when extended to R-CNN as the majority easy negatives are filtered by the two-stage procedure.
Focal loss也能够在single stage的目标检测器中缓和这个问题,但是当将其应用到R-CNN算法的时候,因为在two-stage中充斥着简单样本,使得效果的提升并不明显。
Hence, this issue needs to be solved more elegantly
Feature level imbalance
其二是特征方面的失衡
Deep high-level features in backbones are with more semantic meanings while the shallow low-level features are more content descriptive.
主干中的深层高层次特征具有更多的语义意义,而浅层低层次特征具有更多的内容描述意义
Recently, feature integration via lateral connections in FPN [19] and PANet [22] have advanced the development of object detection.
近来,FPN与PANet中的特征整合与横向连接方法推进了目标检测的发展
These methods inspire us that the low-level and high-level information are complementary for object detection.
这些方式揭示出低层次信息与高层次信息在目标检测中是互为补充的
The approach that how them are utilized to integrate the pyramidal representations determines the detection performance.
这揭示了如何将他们集成到金字塔表示法中决定了目标检测的效果。
However, what is the best approach to integrate them together? Our study reveals that the integrated features should possess balanced information from each resolution.
不过,特征整合的最优策略是什么呢?
我们的研究表明集成的特征应当在每个像素包涵平衡的信息。
But the sequential manner in aforementioned methods will make integrated features focus more on adjacent resolution but less on others.
但是以上的方法中的顺序方式使得集成的特征更关注于邻接的像素而对于其他的像素关注较少。
The semantic information contained in non-adjacent levels would be diluted once per fusion during the information flow.
在非邻接层的语义信息因此就会在信息流的每次融合中被冲淡一次。
Objective level imbalance
其三是目标层面的不平衡。
A detector needs to carry out two tasks, i.e. classification and localization.
一个目标检测器需要执行两个任务:分类与定位。
Thus two different goals are incorporated in the training objective.
于是训练中包含了这两个不同的目标
If they are not properly balanced, one goal may be compromised, leading to suboptimal performance overall.
如果没有适当平衡这两个目标,其中一个目标可能会因此受影响而使得总体的表现不佳。
The case is the same for the involved samples during the training process.
在训练过程中涉及的样本情况也是如此。
If they are not properly balanced, the small gradients produced by the easy samples may be drowned into the large gradients produced by the hard ones, thus limiting further refinement.
如果他们没有被适当的平衡,简单样本产生的小梯度可能会淹没在困难样本产生的大梯度中,从而限制了效果的进一步提升。
Hence, we need to rebalance the involved tasks and samples towards the optimal convergence
于是,我们需要重新平衡任务与样本以使得他们向最优化收敛。
To mitigate the adverse effects caused by these issues, we propose Libra R-CNN, a simple but effective framework for object detection that explicitly enforces the balance at all three levels discussed above.
为了缓和这些失衡造成的消极影响,我们提出了Libra R-CNN,一个简单却高效的有效提升上述三个层面的平衡性的目标检测结构
This framework integrates three novel components:
这个框架融合了三个新的元素:
(1) IoU-balanced sampling, which mines hard samples according to their IoU with assigned ground-truth.
IoU-balanced sampling,基于指定的ground-truth,使用IoU挖掘困难样本
(2) balanced feature pyramid, which strengthens the multi-level features using the same deeply integrated balanced semantic features.
平衡特征金字塔,使用相同的深层语义特征集成技术加强多层的特征
(3) balanced L1 loss, which promotes crucial gradients, to rebalance the involved classification, overall localization and accurate localization.
平衡L1损失函数,提升关键梯度来重新平衡所涉及的分类,整体的定位与精准定位。
Without bells and whistles, Libra R-CNN achieves 2.5 points and 2.0 points higher Average Precision (AP) than FPN Faster R-CNN and RetinaNet respectively on MS COCO [21].
它在MSCOCO数据集上的结果,在平均精度上比FPN Faster RCNN 与 RetinaNet 分别高2.5与2.0。
With the 1× schedule in [9], Libra R-CNN can obtain 38.7 and 43.0 AP with FPN Faster R-CNN based on ResNet-50 and ResNeXt-101-64x4d respectively.
?Libra R-CNN结合FPN Faster R-CNN算法,分别在基于ResNet-50与ResNeXt-101-64x4d的情况下取得38.7与43.0AP的结果。
Here, we summarize our main contributions:
综上所述,我们所做出的成果有:
(1) We systematically revisit the training process of detectors. Our study reveals the imbalance problems at three levels that limit the detection performance.
我们系统地回顾了目标检测器的训练过程,我们的研究依照三个层面揭示了限制检测性能的失衡问题
(2) We propose Libra R-CNN, a framework that rebalances the training process by combining three new components: IoU-balanced sampling, balanced feature pyramid, and balanced L1 loss.
(3) 我们提出了Libra R-CNN,一个可以重新平衡训练过程的算法,它通过集成三种新的元素来实现:IoU平衡采样、平衡特征金字塔和平衡L1损失。
(4) We test the proposed framework on MS COCO, consistently obtaining significant improvements over state-of-the-art detectors, including both single-stage and two-stage ones.
我们使用MS-COCO上检测所提出的网络,相对于当前的包括single-stage与two-stage的最先进的算法,效果得到了显著提升。
Related work
Model architectures for object detection.
Recently, object detection are popularized by both two-stage and single-stage detectors. Two-stage detectors were first introduced by R-CNN [8]. Gradually derived SPP [11], Fast RCNN [7] and Faster R-CNN [28] promoted the developments furthermore. Faster R-CNN proposed region proposal network to improve the efficiency of detectors and allow the detectors to be trained end-to-end. After this meaningful milestone, lots of methods were introduced to enhance Faster R-CNN from different points. For example, FPN [19] tackled the scale variance via pyramidal predictions. Cascade R-CNN [3] extended Faster R-CNN to a multi-stage detector through the classic yet powerful cascade architecture. Mask R-CNN [10] extended Faster R-CNN by adding a mask branch that refines the detection results under the help of multi-task learning. HTC [4] further improved the mask information flow in Mask R-CNN through a new cascade architecture. On the other hand, single-stage detectors are popularized by YOLO [26, 27] and SSD [23]. They are simpler and faster than two-stage detectors but have trailed the accuracy until the introduction of RetinaNet [20]. CornerNet [18] introduced an insight that the bounding boxes can be predicted as a pair of key points. Other methods focus on cascade procedures [24], duplicate removal [14, 13], multi-scales [2, 1, 31, 30], adversarial learning [37] and more contextual [36]. All of them made significant progress from different concerns
目标检测的模型架构。近年来,两级和单级探测器都在普及目标检测。R-CNN首次引入了两级探测器[8]。逐步衍生的SPP[11]、快速R-CNN[7]和快速R-CNN[28]进一步促进了发展。更快的R-CNN提出了区域建议网络,以提高检测器的效率,并降低待端到端训练的检测器。在这个有意义的里程碑之后,许多方法被引入,从不同的角度提高了R-CNN的速度。例如,FPN[19]通过金字塔预测解决了尺度差异问题。Cascade R-CNN[3]通过经典但功能强大的Cascade架构,将更快的R-CNN扩展到多级探测器。Mask R-CNN[10]通过添加一个Mask分支来扩展更快的R-CNN,该分支在多任务学习的帮助下细化检测结果。HTC[4]通过一种新的级联结构进一步改进了mask R-CNN中的mask信息流。另一方面,YOLO[26,27]和SSD[23]推广了单级探测器。它们比两级探测器更简单、速度更快,但在引入视网膜网之前,其精度一直落后于两级探测器[20]。CornerNet[18]提出了一个观点,即边界框可以作为一对关键点进行预测。其他方法侧重于级联程序[24]、重复消除[14,13]、多尺度[2,1,31,30]、对抗性学习[37]和更多上下文[36]。他们都从不同的方面取得了重大进展。
Balanced learning for object detection.
Alleviating imbalance in the training process of object detection is crucial to achieve an optimal training and fully exploit the potential of model architectures.
Sample level imbalance
OHEM [29] and focal loss [20] are primary existing solutions for sample level imbalance in object detection. The commonly used OHEM automatically selects hard samples according to their confidences. However, this procedure causes extra memory and speed costs, making the training process bloated. Moreover, the OHEM also suffers from noise labels so that it cannot work well in all cases. Focal loss solved the extra foregroundbackground class imbalance in single-stage detectors with an elegant loss formulation, but it generally brings little or no gain to two-stage detectors because of the different imbalanced situation. Compared with these methods, our method is substantially lower cost, and tackles the problem elegantly.
OHEM[29]和focal loss[20]是目标检测中样本水平不平衡的主要现有解决方案。常用的OHEM会根据样本的可信度自动选择困难样本。然而,这个过程会导致额外的内存和速度成本,使训练过程变得臃肿。此外,OHEM还受到噪音标签的影响,因此无法在所有情况下都正常工作。Focal loss以一种优雅的损耗公式解决了单级探测器中的额外前场背景类不平衡问题,但由于不同的不平衡情况,focal loss通常给两级探测器带来很少或没有增益。
与他们相比,我们的方式大大降低了成本,并且能更好地解决问题。
Feature level imbalance
Utilizing multi-level features to generate discriminative pyramidal representations is crucial to detection performance. FPN [19] proposed lateral connections to enrich the semantic information of shallow layers through a top-down pathway. After that, PANet [22] brought in a bottom-up pathway to further increase the low-level information in deep layers. Kong et al. [17] proposed a novel efficient pyramid based on SSD that integrates the features in a highly-nonlinear yet efficient way. Different from these methods, our approach relies on integrated balanced semantic features to strengthen original features. In this manner, each resolution in the pyramid obtains equal information from others, thus balancing the information flow and leading the features more discriminative.
利用多级特征生成有判别力的金字塔表示对检测性能至关重要。FPN[19]提出了横向连接,通过自上而下的途径来丰富浅层的语义信息。之后,PANet[22]引入了一种自下而上的途径,以进一步增加深层的低级信息。Kong等人[17]提出了一种基于SSD的新型高效金字塔,该金字塔以高度非线性但高效的方式集成了这些功能。与这些方法不同,我们的方法依赖于集成的平衡语义特征来增强原始特征。通过这种方式,金字塔中的每个分辨率从其他分辨率获得相同的信息,从而能够平衡信息流,并使特征更具区分性。
Objective level imbalance
Kendall et al. [16] had proved that the performance of models based on multi-task learning is strongly dependent on the relative weight between the loss of each task. But previous approaches [28, 19, 20] mainly focus on how to enhance the recognition ability of model architectures. Recently, UnitBox [34] and IoU-Net [15] introduced some new objective functions related to IoU, to promote the localization accuracy. Different to them, our method rebalances the involved tasks and samples to achieve a better convergence.
Kendall等人[16]已经证明,基于多任务学习的模型的性能强烈依赖于每个任务中的损失函数中的相对权重(?。但是过去的算法主要关注于如何提升模型的识别能力。
近来,UnitBox与IoU-Net介绍了一些新的与IoU相关的目标(评价)函数来提升定位的准确性。与它们不同地,我们的方式重新平衡了相关的任务与样本来取得一个更好的融合模型(?)。
Methodology
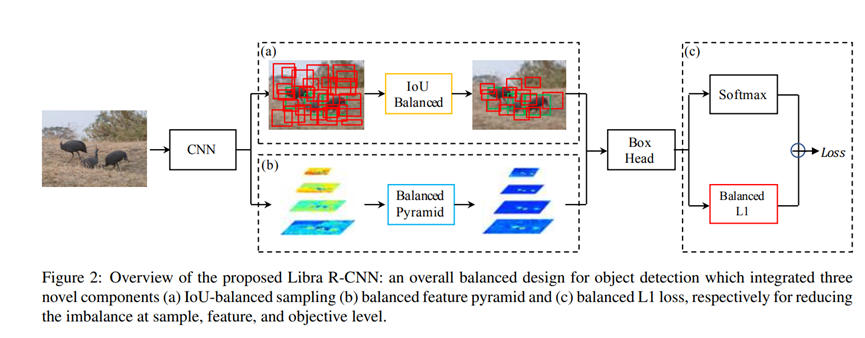
The overall pipeline of Libra R-CNN is shown in Figure 2. Our goal is to alleviate the imbalance exists in the training process of detectors using an overall balanced design, thus exploiting the potential of model architectures as much as possible.
图二展示出了Libra R-CNN的整体架构。我们的目标是使用整体平衡的结构来缓和训练过程中现存的失衡问题,从而充分发挥模型架构的潜力。
; IoU-balanced Sampling
Let us start with the basic question: is the overlap between a training sample and its corresponding ground truth associated with its difficulty? To answer this question, we conduct experiments to find the truth behind. Results are shown in Figure 3. We mainly consider hard negative samples, which are known to be the main problem. We find that more than 60% hard negatives have an overlap greater than 0.05, but random sampling only provides us 30% training samples that are greater than the same threshold. This extreme sample imbalance buries many hard samples into thousands of easy samples。
首先让我们来看一个基本问题:训练样本中的交集与它们的ground truth与其训练的困难程度是否存在联系呢?为了回答这个问题,我们做了一个实验,结果显示在下图(figure 3):
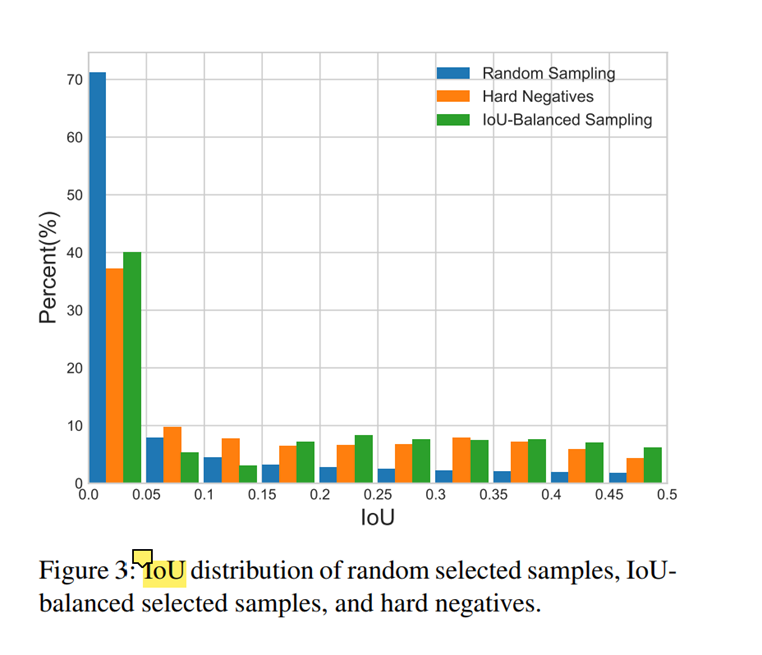
我们主要关注困难负(hard negative)样本。我们发现超过60%的困难负样本有大于0.05的交集占比,但是随机采样只给我们提供了大约30%的超过上面的0.05的样本量。
这个采样的极度不均衡将许多的困难样本掩埋在了成千的简单样本中。
Motivated by this observation, we propose IoU-balanced sampling: a simple but effective hard mining method without extra cost. Suppose we need to sample N negative samples from M corresponding candidates. The selected probability for each sample under random sampling is
根据上面的观测,我们提出了IoU-balanced采样方法:一个简单却高效,附加成本相对较低的的困难样本挖掘策略。
假设我们的M条候选数据中有N条负样本,那么在随机采样中,从中选出负样本的概率就是:

To raise the selected probability of hard negatives, we evenly split the sampling interval into K bins according to IoU.
为了提升我们选出困难负样本的概率,我们将抽样区间依照IoU分为K个区域:
N demanded negative samples are equally distributed to each bin. Then we select samples from them uniformly. Therefore, we get the selected probability under IoU-balanced sampling
N个负样本将会被等分到每个区域中。然后我们分别从中选取样本,之后我们得到IoU-balanced采样方法中,选出困难负样本的概率:
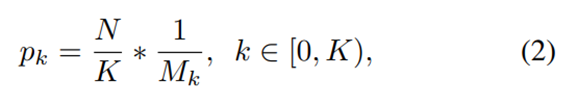
where Mk is the number of sampling candidates in the corresponding interval denoted by k. K is set to 3 by default in our experiments.
Mk是第K个采样区间对应的候选样本的数量。在我们的实验中,默认设定K为3.
The sampled histogram with IoU-balanced sampling is shown by green color in Figure 3.
图三中的绿色条形表征了此方法的采样情况。
It can be seen that our IoU-balanced sampling can guide the distribution of training samples close to the one of hard negatives.
能够发现我们的IoU-balanced采样方式可以使得训练样本的分布更接近困难负样本。
Experiments also show that the performance is not sensitive to K, as long as the samples with higher IoU are more likely selected.
实验验证得出,采样的表现对K的取值不敏感,只要具有较高的IoU的样本有更大的可能被筛选出来。
Besides, it is also worth noting that the method is also suitable for hard positive samples. However, in most cases, there are not enough sampling candidates to extend this procedure into positive samples. To make the balanced sampling procedure more comprehensive, we sample equal positive samples for each ground truth as an alternative method
另外,需要注意的是这个方法也适用于困难正样本。不过,在大多数情况下,没有足够的候选样本将这个方法扩展到正样本中。为了使平衡抽样程序更全面,我们为每个基本事实抽取相等的阳性样本作为替代方法
; Balanced Feature Pyramid
Different from former approaches[19, 22] that integrate multi-level features using lateral connections, our key idea is to strengthen the multi-level features using the same deeply integrated balanced semantic features.
与之前的采用横向连接集成多层特征的方式不同,我们的方法关键点在于运用相同的深层平衡语义特征来加强多层的特征?
The pipeline is shown in Figure 4. It consists of four steps, rescaling, integrating, refining and strengthening
图4显示了该方法的基本流程,扩展、整合、提纯(提炼)和强化
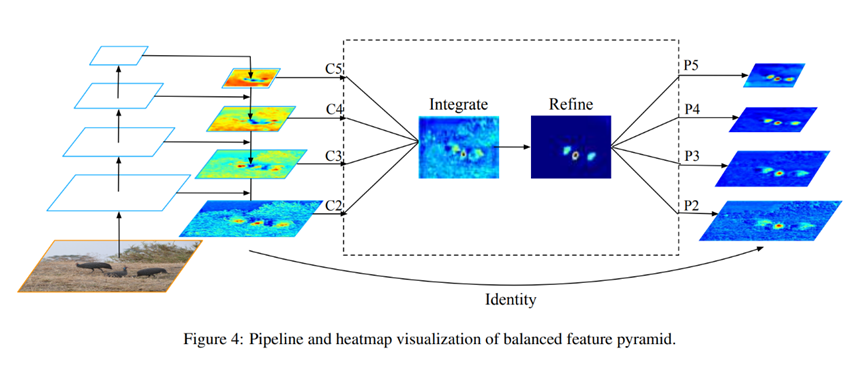
Obtaining balanced semantic features
Features at resolution level l are denoted as Cl .
L分辨率层l的特征记作Cl。
The number of multi-level features is denoted as L.
多层特征的数量记作L
The indexes of involved lowest and highest levels are denoted as lmin and lmax.
最低层与最高层的值(指标?)分别记作lmin与lmax。
In Figure 4, C2 has the highest resolution.
在图四中,C2有最高的分辨率
To integrate multi-level features and preserve their semantic hierarchy at the same time, we first resize the multi-level features {C2, C3, C4, C5} to an intermediate size, i.e., the same size as C4, with interpolation and max-pooling respectively.
为了集成多层的特征并同时保留其语义层次,我们首先将此多层特征{C2, C3, C4, C5}的size使用插值与最大池化等方式调整为一个中级的大小,比如调整成C4的大小,
Once the features are rescaled, the balanced semantic features are obtained by simple averaging as
在特征的大小被调节之后,平衡语义特征(the balanced semantic features)可以很容易地通过平均得出:
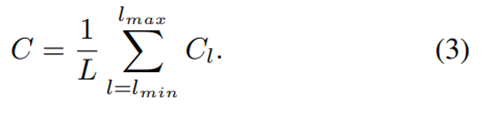
The obtained features are then rescaled using the same but reverse procedure to strengthen the original features.
所取得的特征在之后被使用相同但相反步骤的重新调节大小,以增强初始特征。
Each resolution obtains equal information from others in this procedure.
在这个过程中,每个分辨率从其他分辨率那里取得了等量的信息
Note that this procedure does not contain any parameter.
需要注意的是,这一步中不包含任何参数。
We observe improvement with this nonparametric method, proving the effectiveness of the information flow.
在应用无参数的这种方式情况下,效果提升了,这证明了这个信息流程的有效性。
Refining balanced semantic features
The balanced semantic features can be further refined to be more discriminative.
平衡语义特征可以被进一步改进以提升其区分能力。
We found both the refinements with convolutions directly and the non-local module [32] work well. But the non-local module works more stable.
我们发现无论是基于卷积的改进还是非局部模块的改进都能取得效果,但是在非局部模块的表现更加稳定。
Therefore, we use the embedded Gaussian non-local attention as default in this paper. The refining step helps us enhance the integrated features and further improve the results.
于是,在这篇论文中,我们默认使用the embedded Gaussian non-local attention(嵌入高斯非局部注意力机制)。Refining这一步帮助我们增强集成的特征从而进一步提升检测的效果。
With this method, features from low-level to high-level are aggregated at the same time.
在这种方法中,低层到高层的特征同时被统合了。
The outputs {P2, P3, P4, P5} are used for object detection following the same pipeline in FPN.
使用输出{P2, P3, P4, P5}进行目标检测的过程与FPN的流程是一样的。
It is also worth mentioning that our balanced feature pyramid can work as complementary with recent solutions such as FPN and PAFPN without any conflict.
值得提到的是,我们的平衡特征金字塔可以与最近的算法比如FPN与PAFPN等一起使用以互为补充,而不会产生冲突。
Balanced L1 Loss
Classification and localization problems are solved simultaneously under the guidance of a multi-task loss since Fast R-CNN [7], which is defined as
自Fast R-CNN以来,分类(识别)与定位问题常常同时得到解决,所使用的联合多任务损失函数如下:
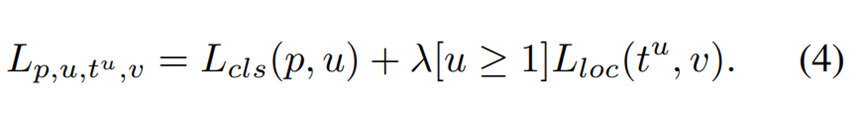
Lcls and Lloc are objective functions corresponding to recognition and localization respectively. Predictions and targets in Lcls are denoted as p and u.
Lcls和Lloc分别对应识别与定位问题。
Lcls中的预测与目标(对象?)表示为p和u
t u is the corresponding regression results with class u.
tu是u类对应的回归结果
v is the regression target.
V是回归对象。
λ is used for tuning the loss weight under multi-task learning.
λ是在多任务训练中调整损失权重的超参数
We call samples with a loss greater than or equal to 1.0 outliers. The other samples are called inliers.
我们将损失大于等于1.0的样本称为异常值。其余的称为正常值。
A natural solution for balancing the involved tasks is to tune the loss weights of them. However, owing to the unbounded regression targets, directly raising the weight of localization loss will make the model more sensitive to outliers.
一个自然的解法是调整损失权重来平衡这两个任务。但是,鉴于无限的回归对象,直接提升定位损失函数的权重将使模型对于异常值更加敏感。
These outliers, which can be regarded as hard samples, will produce excessively large gradients that are harmful to the training process.
这些异常值(我们将它们称作困难样本)将会产生相当大的梯度值,从而对训练过程产生不利影响。
The inliers, which can be regarded as the easy samples, contribute little gradient to the overall gradients compared with the outliers.
而正常值(我们将它们称作简单样本),相对于异常值,对整体的梯度产生的影响就相当小了。
To be more specific, inliers only contribute 30% gradients average per sample compared with outliers. Considering these issues, we propose balanced L1 loss, which is denoted as Lb.
更加具体地讲,相对于异常值,正常值在每个样本中产生的平均梯度影响只占30%。
考虑到这种情况,我们提出平衡L1损失函数,记作Lb。
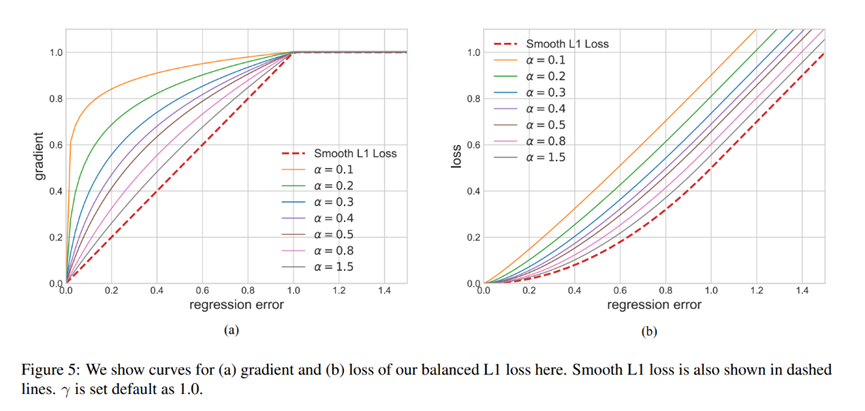
Balanced L1 loss is derived from the conventional smooth L1 loss, in which an inflection point is set to separate inliers from outliners, and clip the large gradients produced by outliers with a maximum value of 1.0, as shown by the dashed lines in Figure 5-(a).
平衡L1损失函数从惯例的平滑L1损失函数中演化而来,在此平滑损失函数中,我们设置一个拐点来区分正常值与异常值,修剪掉最大值为1.0的异常值造成的大梯度,表现为a图中的直线。
The key idea of balanced L1 loss is promoting the crucial regression gradients, i.e. gradients from inliers (accurate samples), to rebalance the involved samples and tasks, thus achieving a more balanced training within classification, overall localization and accurate localization.
平衡L1损失函数的关键点在于提升关键回归梯度,比如正常值(正确样本)的梯度,来重新平衡所涉及的样本与任务,于是能够得到一个分类,整体定位与精准定位更平衡的训练过程。
Localization loss Lloc uses balanced L1 loss is defined as
使用平衡L1损失函数的定位损失函数Lloc定义成
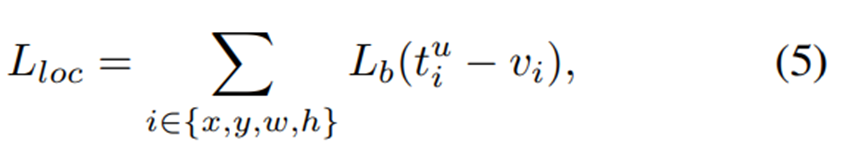
and its corresponding formulation of gradients follows
相应的梯度公式定义如下:
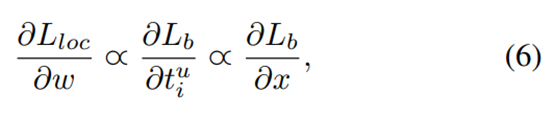
在上述公式的基础上,我们改进了梯度公式,如下:
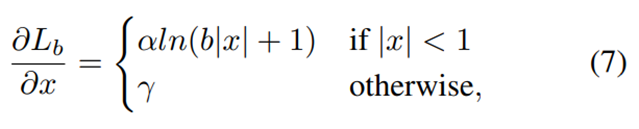
Figure 5-(a) shows that our balanced L1 loss increases the gradients of inliers under the control of a factor denoted as α.
图5(a)我们的平衡L1损失函数在α参数的控制下提升了正常值的梯度
A small α increases more gradient for inliers, but the gradients of outliers are not influenced.
Α较小时,对于正常值的梯度提升作用更强,但异常值的梯度不受影响。
Besides, an overall promotion magnification controlled by γ is also brought in for tuning the upper bound of regression errors, which can help the objective function better balancing involved tasks.
另外,一个作用于整体的放大倍数γ也可以调整回归误差的上限,这可以使得评价函数更好地平衡多个任务。
The two factors that control different aspects are mutually enhanced to reach a more balanced training. b is used to ensure Lb(x = 1) has the same value for both formulations in Eq. (8).
控制不同层面的两个参数相辅相成,可以使得训练达到更加平衡的状态。b是用来保证Lb(x=1)与等式8的值相同。
By integrating the gradient formulation above, we can get the balanced L1 loss
集成上面所说的梯度式,我们可以得到平衡L1损失函数:
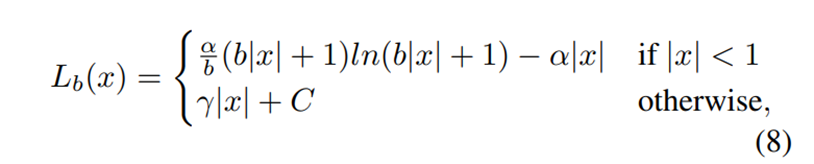
in which the parameters γ, α, and b are constrained by
其中参数γ, α和 b满足如下的限制条件:
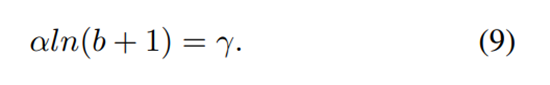
The default parameters are set as α = 0.5 and γ = 1.5 in our experiments
在我们的实验中,默认设置α = 0.5,γ = 1.5。
; Experiments
Dataset and Evaluation Metrics
All experiments are implemented on the challenging MS-COCO dataset. It consists of 115k images for training (train-2017) and 5k images for validation (val-2017). There are also 20k images in test-dev that have no disclosed labels. We train models on train-2017, and report ablation studies and final results on val-2017 and test-dev respectively. All reported results follow standard COCO-style Average Precision (AP) metrics that include AP (averaged over IoU thresholds), AP50 (AP for IoU threshold 50%), AP75 (AP for IoU threshold 75%). We also include APS, APM, APL, which correspond to the results on small, medium and large scales respectively. The COCO-style Average Recall (AR) with AR100, AR300, AR1000 correspond to the average recall when there are 100, 300 and 1000 proposals per image respectively.
所有实验都是在具有挑战性的MS-COCO数据集上进行的。它由115k培训图像(train-2017)和5k验证图像(val-2017)组成。test dev中还有20k个没有公开标签的图像。我们在train-2017上训练模型,并分别在val-2017和test dev上报告消融研究和最终结果。所有报告的结果都遵循标准COCO风格的平均精度(AP)指标,包括AP(在IoU阈值上的平均值)、AP50(AP代表IoU阈值50%)、AP75(AP代表IoU阈值75%)。我们还包括APS、APM、APL,它们分别对应于小规模、中规模和大规模的结果。带有AR100、AR300和AR1000的COCO式平均精度(AR)对应于每幅图像分别有100、300和1000个提议时的平均精度。
Implement Details
For fair comparisons, all experiments are implemented on PyTorch [25] and mmdetection [5]. The backbones used in our experiments are publicly available. We train detectors with 8 GPUs (2 images per GPU) for 12 epochs with an initial learning rate of 0.02, and decrease it by 0.1 after 8 and 11 epochs respectively if not specifically noted. All other hyper-parameters follow the settings in mmdetection [5] if not specifically noted.
为了进行公平比较,所有实验均在Pytorch和mmdetection上进行。我们实验中使用的主干网络(backbones)是公开的。我们用8个GPU(每个GPU 2个图像)对探测器进行12个阶段的训练,初始学习率为0.02,如果没有特别说明,则在8个阶段和11个阶段后分别降低0.1。如果没有特别说明,所有其他超参数都遵循mmdetection[5]中的设置。
Main Results
We compare Libra R-CNN with the state-of-the-art object detection approaches on the COCO test-dev in Tabel 1. For fair comparisons with corresponding baselines, we report our re-implemented results of them, which are generally higher than that were reported in papers. Through the overall balanced design, Libra R-CNN achieves 38.7 AP with ResNet-50 [12], which is 2.5 points higher AP than FPN Faster R-CNN. With ResNeXt-101-64x4d [33], a much more powerful feature extractor, Libra R-CNN achieves 43.0 AP.
我们将Libra R-CNN与表1中COCO测试开发的最新目标检测方法进行了比较。为了与相应的基线进行公平比较,我们报告了它们的重新实施结果,这些结果通常高于论文中报告的结果。通过整体平衡设计,Libra R-CNN与ResNet-50[12]的结合得到了38.7 AP的结果,比FPN Faster R-CNN的结果高2.5个AP。Libra R-CNN通过使用一个更强大的功能提取器ResNeXt-101-64x4d[33]得到了43.0 AP的结果。
Apart from the two-stage frameworks, we further extend our Libra R-CNN to single-stage detectors and report the results of Libra RetinaNet. Considering that there is no sampling procedure in RetinaNet [20], Libra RetinaNet only integrates balanced feature pyramid and balanced L1 loss. Without bells and whistles, Libra RetinaNet brings 2.0 points higher AP with ResNet-50 and achieves 37.8 AP.
除了two-stage算法之外,我们还将Libra R-CNN扩展到single-stage算法,并得出了Libra RetinaNet的结果。考虑到RetinaNet中没有采样程序,Libra RetinaNet只集成了平衡特征金字塔和平衡L1损耗。Libra RetinaNet通过ResNet-50提高2.0点AP,并达到了37.8 AP。
Our method can also enhance the average recall of proposal generation. As shown in Table 3, Libra RPN brings 9.2 points higher AR100 , 6.9 points higher AR300 and 5.4 points higher AR1000 compared with RPN with ResNet-50 respectively. Note that larger backbones only bring little gain to RPN. Libra RPN can achieve 4.3 points higher AR100 than ResNeXt-101-64x4d only with a ResNet-50 backbone. The significant improvements from Libra RPN validate that the potential of RPN is much more exploited with the effective balanced training
我们的方法还可以提高提案生成的平均召回率。如表3所示,与使用ResNet-50的RPN相比,Libra RPN的AR100、AR300和AR1000分别高出9.2、6.9和5.4个百分点。请注意,主干网络越大,RPN所获得的效益反而会较小。Libra RPN仅在使用ResNet-50主干网的情况下,AR100比ResNeXt-101-64x4d高4.3个百分点。Libra RPN的显著改进证明了RPN的潜力在有效的平衡训练中得到了更大的发挥。
Ablation Experiments
Overall Ablation Studies(整体消融研究)
To analyze the importance of each proposed component, we report the overall ablation studies in Table 2. We gradually add IoU-balanced sampling, balanced feature pyramid and balanced L1 loss on ResNet-50 FPN Faster R-CNN baseline. Experiments for ablation studies are implemented with the same precomputed proposals for fair comparisons.
为了分析我们所提出的每个组件的重要性,我们在表2中提供了整体对照研究的结果。我们逐步在ResNet-50 FPN faster R-CNN基线上添加IoU平衡采样、平衡特征金字塔和平衡L1损失。对照研究的实验采用相同的预计算方案,以进行公平比较。
IoU-balanced Sampling
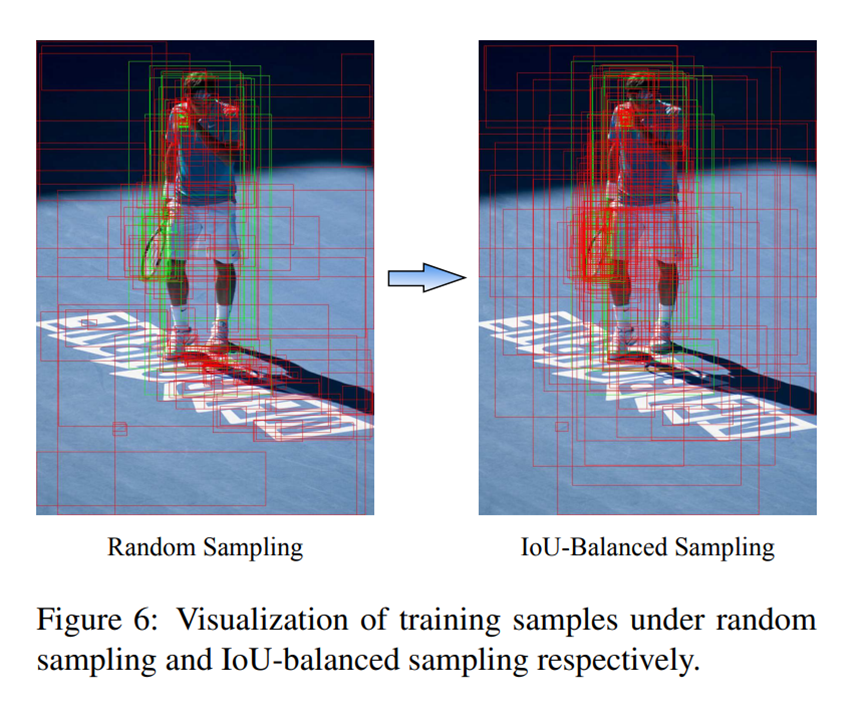
IoU-balanced sampling brings 0.9 points higher box AP than the ResNet-50 FPN Faster R-CNN baseline, validating the effectiveness of this cheap hard mining method. We also visualize the training samples under random sampling and IoU-balanced sampling in Figure 6. It can be seen that the selected samples are gathered to the regions where we are more interested in instead of randomly appearing around the target.
IoU平衡采样使box AP比ResNet-50 FPN高0.9个百分点,比R-CNN基线更快,证明了这种低成本困难挖掘方法的有效性。我们还在图6中展示了随机抽样和IoU平衡抽样下的训练样本。可以看出,所选样本被聚集到我们更感兴趣的区域,而不是随机出现在目标周围。
; Balanced Feature Pyramid
Balanced feature pyramid improves the box AP from 36.8 to 37.7. Results in small, medium and large scales are consistently improved, which validate that the balanced semantic features balanced low-level and high-level information in each level and yield consistent improvements.
平衡功能金字塔将长方体AP从36.8提高到37.7。小、中、大尺度的结果都得到了一致的改进,这验证了平衡语义特征平衡了各个层次的低层和高层信息,进而产生了一致的改进。
Balanced L1 Loss
Balanced L1 loss improves the box AP from 37.7 to 38.5. To be more specific, most of the improvements are from AP75, which yields 1.1 points higher AP compared with corresponding baseline. This result validates that the localization accuracy is much improved.
平衡L1损耗将box AP从37.7提高到38.5。更具体地说,大多数改进来自于AP75,与相应的基线相比,AP75产生的AP高出1.1个点。这一结果证明了定位的准确度得到大幅度提高。
Ablation Studies on IoU-balanced Sampling.
Experimental results with different implementations of IoU-balanced sampling are shown in Table 4. We first verify the effectiveness of the complementary part, i.e. sampling equal number of positive samples for each ground truth, which is stated in Section 3.1 and denoted by Pos Balance in Table 4. Since there are too little positive samples to explore the potential of this method, this sampling method provides only small improvements (0.2 points higher AP) compared to ResNet-50 FPN Faster R-CNN baseline
不同IoU平衡采样实现的实验结果如表4所示。我们首先验证互补部分的有效性,即为每个ground truth取样相等数量的正样本,并在表4中用Pos Balance表示。由于正样本太少,以至于无法探索该方法的所带来的潜力,与ResNet-50 FPN faster R-CNN基线相比,该抽样方法只提供了很小的改进(AP高0.2点)
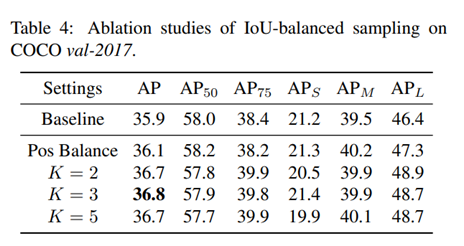
Then we evaluate the effectiveness of IoU-balanced sampling for negative samples with different hyper-parameters K, which denotes the number of intervals. Experiments in Table 4 show that the results are very close to each other when the parameter K is set as 2, 3 or 5. Therefore, the number of sampling interval is not much crucial in our IoU-balanced sampling, as long as the hard negatives are more likely selected.
然后,我们评估了IoU平衡抽样对不同超参数K(表示区间数)的负样本的有效性。表4中的实验表明,当参数K设置为2、3或5时,结果非常接近。因此,采样间隔的数量在我们的IoU平衡采样中并不是很关键,只要选择困难负样本的概率更高。
; Ablation Studies on Balanced Feature Pyramid.
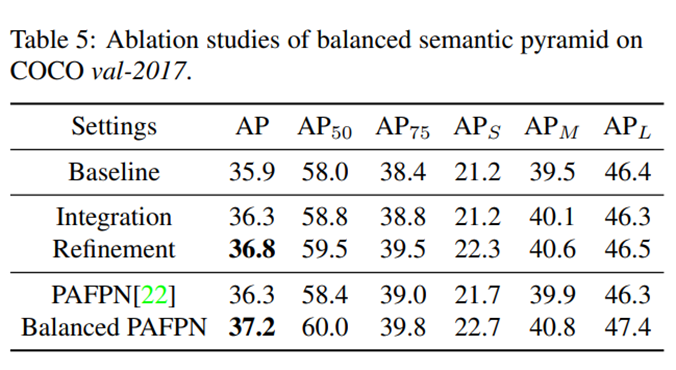
Ablation studies of balanced feature pyramid are shown in Table 5. We also report the experiments with PAFPN [22]. We first implement balanced feature pyramid only with integration. Results show that the naive feature integration brings 0.4 points higher box AP than the corresponding baseline. Note there is no refinement and no parameter added in this procedure. With this simple method, each resolution obtains equal information from others. Although this result is comparable with the one of PAFPN [22], we reach the feature level balance without extra convolutions, validating the effectiveness of this simple method.
平衡特征金字塔的对照研究如表5所示。我们还报告了PAFPN的实验结果[22]。我们首先只通过集成实现平衡的特征金字塔。结果表明,朴素的特征整合比相应的基线高0.4分。注:本程序中未添加任何细化和参数。通过这种简单的方法,每个分辨率从其他分辨率获得相同的信息。虽然这个结果与PAFPN[22]的结果相当,但我们在没有额外卷积的情况下达到了特征级平衡,证明了这个简单方法的有效性。
Along with the embedded Gaussian non-local attention [32], balanced feature pyramid can be further enhanced and improve the final results. Our balanced feature pyramid is able to achieve 36.8 AP on COCO dataset, which is 0.9 points higher AP than ResNet-50 FPN Faster R-CNN baseline. More importantly, the balanced semantic features have no conflict with PAFPN. Based on the PAFPN, we include our feature balancing scheme and denote this implementation by Balanced PAFPN in Table 5. Results show that the Balanced PAFPN is able to achieve 37.2 box AP on COCO dataset, with 0.9 points higher AP compared with the PAFPN.
随着嵌入高斯非局部注意力机制,平衡特征金字塔可以进一步增强,并改善最终结果。我们的平衡特征金字塔能够在COCO数据集上实现36.8 AP,比ResNet-50 FPN Faster R-CNN基线高出0.9点AP。更重要的是,平衡的语义特征与PAFPN没有冲突。故而在PAFPN的基础上,我们加入了我们的特征平衡方案,并在表5中用平衡的PAFPN来表示这个实现。结果表明,在COCO数据集上,平衡PAFPN能够实现37.2 box AP,比原PAFPN高0.9个百分点。
Ablation Studies on Balanced L1 Loss.
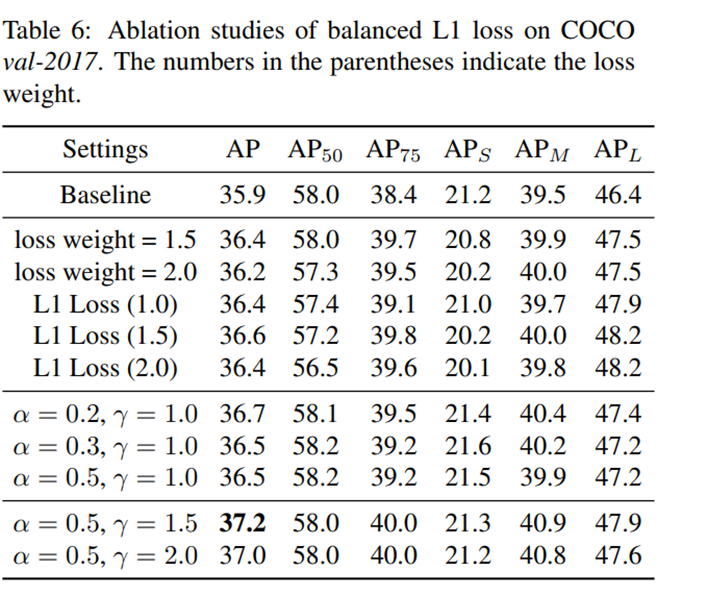
Ablation studies of balanced L1 loss are shown in Table 6. We observe that the localization loss is mostly half of the recognition loss. Therefore, we first verify the performance when raising loss weight directly. Results show that tuning loss weight only improves the result by 0.5 points. And the result with a loss weight of 2.0 starts to drop down. These results show that the outliers bring negative influence on the training process, and leave the potential of model architecture from being fully exploited. We also conduct experiments with L1 loss for comparisons. Experiments show that the results are inferior to ours. Although the overall results are improved, the AP50 and APS drop obviously.
平衡L1损耗的对照研究如表6所示。我们观察到,定位损失大部分是识别损失的一半。因此,我们首先验证了直接增加loss权重时的结果。结果表明,调整loss权重函数的效果仅提高了0.5个百分点。Loss 权重为2.0的结果开始下降。这些结果表明,异常值给训练过程带来了负面影响,并使模型体系结构的潜力没有得到充分利用。我们还进行了L1损失函数的实验以进行比较。实验表明,结果不如我们的。虽然总体结果有所改善,但AP50和APS明显下降。
In order to compare with tuning loss weight directly, we first validate the effectiveness of balanced L1 loss when γ = 1. Balanced L1 loss is able to bring 0.8 points higher AP than baseline. With our best setting, balanced L1 loss finally achieves 37.2 AP, which is 1.3 points higher than the ResNet-50 FPN Faster R-CNN baseline. These experimental results validate that our balanced L1 achieves a more balanced training and makes the model better converged.
为了与直接调整损失权重进行比较,我们首先验证了γ=1时使用平衡L1损失函数的有效性。平衡的L1缺失能使AP比基线提高0.8点。在我们的最优设置下,平衡L1损失的结果最终达到37.2 AP,比ResNet-50 FPN Faster R-CNN基线高1.3个点。这些实验结果证明了我们的平衡L1方法使得训练更平衡,并使模型更好地收敛。
; Conclusion
In this paper, we systematically revisit the training process of detectors, and find the potential of model architectures is not fully exploited due to the imbalance issues existing in the training process. Based on the observation, we propose Libra R-CNN to balance the imbalance through an overall balanced design. With the help of the simple but effective components, i.e. IoU-balanced sampling, balanced feature pyramid and balanced L1 loss, Libra R-CNN brings significant improvements on the challenging MS-COCO dataset. Extensive experiments show that Libra R-CNN well generalizes to various backbones for both two-stage detectors and single-stage detectors
在本文中,我们系统地回顾了检测器的训练过程,发现由于训练过程中存在的不平衡问题,模型架构的潜力没有得到充分利用。基于观察,我们提出了Libra R-CNN通过整体平衡设计来平衡训练过程中的不平衡。借助于我们提出的简单但有效的元素,即IoU平衡采样、平衡特征金字塔和平衡L1损失,Libra R-CNN对具有挑战性的MS-COCO数据集进行了重大改进。大量实验表明,Libra R-CNN可以很好地推广到两级探测器和单级探测器的各种主干网络。
Original: https://blog.csdn.net/today__present/article/details/123553179
Author: today__present
Title: 目标检测平衡训练:Libra R-CNN: Towards Balanced Learning for Object Detection 论文翻译解读
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/681965/
转载文章受原作者版权保护。转载请注明原作者出处!